你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
将 Azure AI 视觉容器与 Kubernetes 和 Helm 配合使用
在本地管理 Azure AI 视觉容器的一种方法是使用 Kubernetes 和 Helm。 我们将通过使用 Kubernetes 和 Helm 定义Azure AI 视觉容器映像,以创建一个 Kubernetes 包。 此包将部署到本地 Kubernetes 群集。 最后,我们将了解如何测试已部署的服务。 有关在不使用 Kubernetes 业务流程的情况下运行 Docker 容器的详细信息,请参阅安装和运行 Azure AI 视觉容器。
先决条件
在本地使用 Azure AI 视觉容器之前,必须满足以下先决条件:
| 必需 | 目的 |
|---|---|
| Azure 帐户 | 如果没有 Azure 订阅,请在开始之前创建一个免费帐户。 |
| Kubernetes CLI | 需要使用 Kubernetes CLI 来管理容器注册表中的共享凭据。 在安装 Helm(Kubernetes 包管理器)之前,也需要有 Kubernetes。 |
| Helm CLI | 安装 Helm CLI,它可用于安装 Helm 图表(容器包定义)。 |
| 计算机视觉资源 | 若要使用容器,必须具有: 计算机视觉资源和关联的 API 密钥及终结点 URI。 这两个值都可以在资源的“概述”和“密钥”页上找到,并且是启动容器所必需的。 {API_KEY} :“密钥”页上提供的两个可用资源密钥中的一个 {ENDPOINT_URI} :“概述”页上提供的终结点 |
收集必需的参数
所有 Azure AI 容器都需要三个主要参数。 Microsoft 软件许可条款的值必须为 “accept”。 还需要终结点 URI 和 API 密钥。
终结点 URI
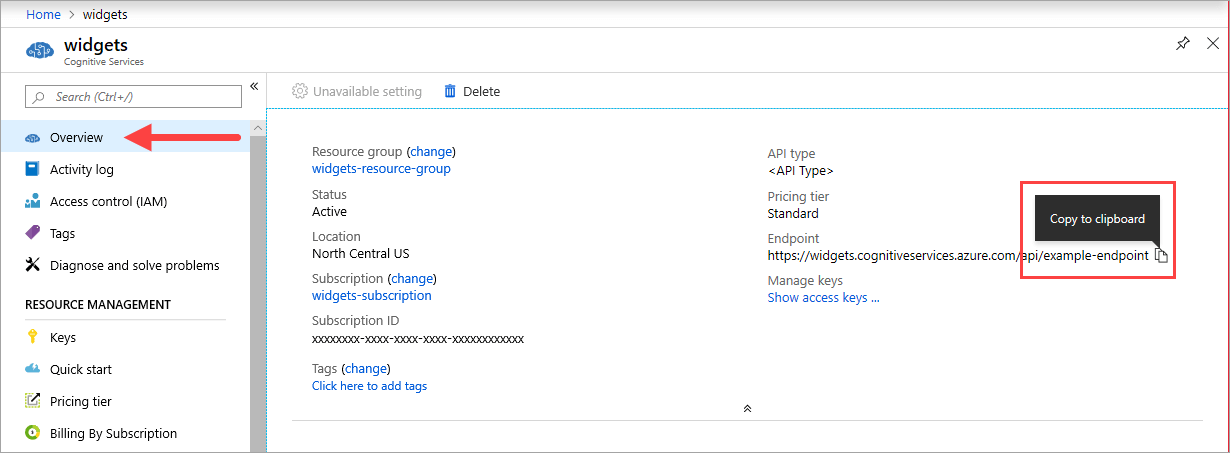
可在 Azure 门户中相应 Azure AI 服务资源的“概览”页上找到 {ENDPOINT_URI} 值。 转到“概述”页,将鼠标悬停在终结点上就会显示一个“复制到剪贴板”图标。 在需要的地方复制并使用终结点。
键
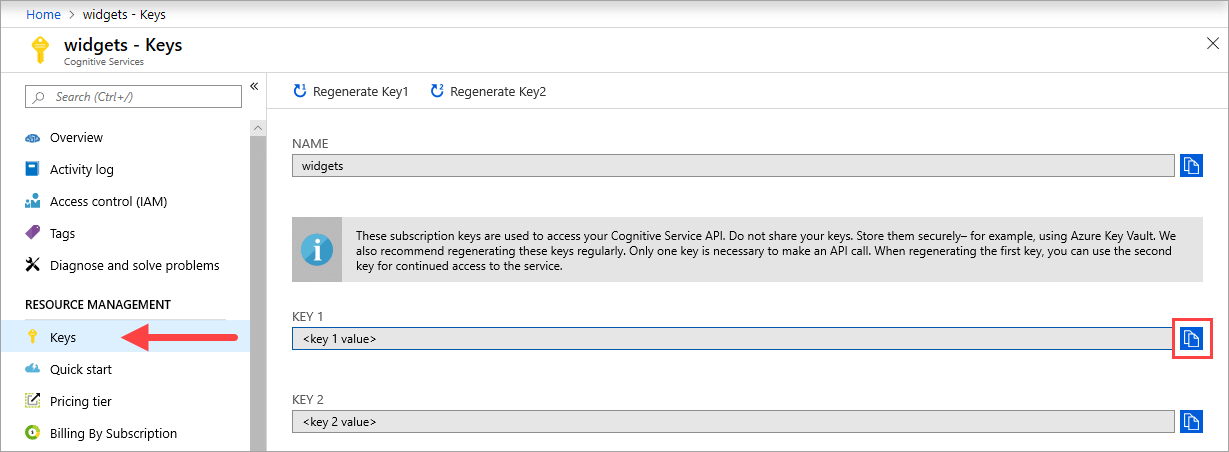
{API_KEY} 值用于启动容器,可在 Azure 门户中相应 Azure AI 服务资源的“密钥”页上找到。 转到“密钥”页,选择“复制到剪贴板” 图标。
重要
这些订阅密钥用于访问 Azure AI 服务 API。 请勿共享密钥。 安全地存储它们。 例如,使用 Azure Key Vault。 此外,建议定期重新生成这些密钥。 发出 API 调用只需一个密钥。 重新生成第一个密钥时,可以使用第二个密钥继续访问服务。
主计算机
主机是运行 Docker 容器且基于 x64 的计算机。 它可以是本地计算机或 Azure 中的 Docker 托管服务,例如:
- Azure Kubernetes 服务。
- Azure 容器实例。
- 部署到 Azure Stack 的 Kubernetes 群集。 有关详细信息,请参阅将 Kubernetes 部署到 Azure Stack。
容器要求和建议
注意
这些要求和建议基于这样的基准:每秒一个请求,使用包含 29 行和总共 803 个字符的经过扫描的业务信函的 523-KB 映像。 与最低配置相比,建议配置使响应速度提高了大约 2 倍。
下表显示了每个 Read OCR 容器的最小和建议资源分配。
| 容器 | 最小值 | 建议 |
|---|---|---|
| 读取 3.2 2022-04-30 | 4 个内核,8 GB 内存 | 8 个内核,16 GB 内存 |
| 读取 3.2 2021-04-12 | 4 个内核,16 GB 内存 | 8 个内核,24 GB 内存 |
- 每个核心必须至少为 2.6 千兆赫 (GHz) 或更快。
核心和内存对应于 --cpus 和 --memory 设置,用作 docker run 命令的一部分。
连接到 Kubernetes 群集
主机预期有一个可用的 Kubernetes 群集。 请参阅这篇有关部署 Kubernetes 群集的教程,对如何将 Kubernetes 群集部署到主机有一个概念性的了解。 有关部署的详细信息,请参阅 Kubernetes 文档。
配置用于部署的 Helm 图表值
首先,创建一个名为 read 的文件夹。 然后,将以下 YAML 内容粘贴到名为 chart.yaml 的新文件中:
apiVersion: v2
name: read
version: 1.0.0
description: A Helm chart to deploy the Read OCR container to a Kubernetes cluster
dependencies:
- name: rabbitmq
condition: read.image.args.rabbitmq.enabled
version: ^6.12.0
repository: https://kubernetes-charts.storage.googleapis.com/
- name: redis
condition: read.image.args.redis.enabled
version: ^6.0.0
repository: https://kubernetes-charts.storage.googleapis.com/
若要配置 Helm 图表默认值,请将以下 YAML 复制并粘贴到名为 values.yaml 的文件中。 请将 # {ENDPOINT_URI} 和 # {API_KEY} 注释替换为自己的值。 如果需要,请配置 resultExpirationPeriod、Redis 和 RabbitMQ。
# These settings are deployment specific and users can provide customizations
read:
enabled: true
image:
name: cognitive-services-read
registry: mcr.microsoft.com/
repository: azure-cognitive-services/vision/read
tag: 3.2-preview.1
args:
eula: accept
billing: # {ENDPOINT_URI}
apikey: # {API_KEY}
# Result expiration period setting. Specify when the system should clean up recognition results.
# For example, resultExpirationPeriod=1, the system will clear the recognition result 1hr after the process.
# resultExpirationPeriod=0, the system will clear the recognition result after result retrieval.
resultExpirationPeriod: 1
# Redis storage, if configured, will be used by read OCR container to store result records.
# A cache is required if multiple read OCR containers are placed behind load balancer.
redis:
enabled: false # {true/false}
password: password
# RabbitMQ is used for dispatching tasks. This can be useful when multiple read OCR containers are
# placed behind load balancer.
rabbitmq:
enabled: false # {true/false}
rabbitmq:
username: user
password: password
重要
如果未提供
billing和apikey值,服务将在 15 分钟后过期。 同样,验证也会因服务不可用而失败。如果将多个 Read OCR 容器部署在负载均衡器之后(例如,在 Docker Compose 或 Kubernetes 下面),则必须有外部缓存。 由于进行处理的容器和 GET 请求容器可能不是同一个容器,因此外部缓存会存储结果并在容器之间共享这些结果。 有关缓存设置的详细信息,请参阅配置 Azure AI 视觉 Docker 容器。
在 read 目录下创建 templates 文件夹。 将以下 YAML 复制并粘贴到名为 deployment.yaml 的文件。 deployment.yaml 文件将充当 Helm 模板。
模板生成清单文件,这些文件是 Kubernetes 可以理解的 YAML 格式的资源描述。 - Helm 图表模板指南
apiVersion: apps/v1
kind: Deployment
metadata:
name: read
labels:
app: read-deployment
spec:
selector:
matchLabels:
app: read-app
template:
metadata:
labels:
app: read-app
spec:
containers:
- name: {{.Values.read.image.name}}
image: {{.Values.read.image.registry}}{{.Values.read.image.repository}}
ports:
- containerPort: 5000
env:
- name: EULA
value: {{.Values.read.image.args.eula}}
- name: billing
value: {{.Values.read.image.args.billing}}
- name: apikey
value: {{.Values.read.image.args.apikey}}
args:
- ReadEngineConfig:ResultExpirationPeriod={{ .Values.read.image.args.resultExpirationPeriod }}
{{- if .Values.read.image.args.rabbitmq.enabled }}
- Queue:RabbitMQ:HostName={{ include "rabbitmq.hostname" . }}
- Queue:RabbitMQ:Username={{ .Values.read.image.args.rabbitmq.rabbitmq.username }}
- Queue:RabbitMQ:Password={{ .Values.read.image.args.rabbitmq.rabbitmq.password }}
{{- end }}
{{- if .Values.read.image.args.redis.enabled }}
- Cache:Redis:Configuration={{ include "redis.connStr" . }}
{{- end }}
imagePullSecrets:
- name: {{.Values.read.image.pullSecret}}
---
apiVersion: v1
kind: Service
metadata:
name: read-service
spec:
type: LoadBalancer
ports:
- port: 5000
selector:
app: read-app
还是在该模板文件夹中,将以下帮助程序函数复制粘贴到 helpers.tpl 中。 helpers.tpl 定义了一些实用函数,可帮助生成 Helm 模板。
{{- define "rabbitmq.hostname" -}}
{{- printf "%s-rabbitmq" .Release.Name -}}
{{- end -}}
{{- define "redis.connStr" -}}
{{- $hostMain := printf "%s-redis-master:6379" .Release.Name }}
{{- $hostReplica := printf "%s-redis-replica:6379" .Release.Name -}}
{{- $passWord := printf "password=%s" .Values.read.image.args.redis.password -}}
{{- $connTail := "ssl=False,abortConnect=False" -}}
{{- printf "%s,%s,%s,%s" $hostMain $hostReplica $passWord $connTail -}}
{{- end -}}
模板指定负载均衡器服务以及要读取的容器/映像的部署。
Kubernetes 包(Helm 图表)
Helm 图表包含要从 mcr.microsoft.com 容器注册表提取的 Docker 映像的配置。
Helm 图表是描述一组相关 Kubernetes 资源的文件集合。 单个图表既可用于部署简单的资源(例如 Memcached Pod),也可用于部署复杂的资源(例如,包含 HTTP 服务器、数据库、缓存等的完整 Web 应用堆栈)。
提供的 Helm 图表将从 mcr.microsoft.com 容器注册表中拉取 Azure AI 视觉服务的 Docker 映像以及相应的服务。
在 Kubernetes 群集上安装 Helm 图表
若要安装 Helm 图表,我们需要执行 helm install 命令。 确保从 read 文件夹上方的目录中执行 install 命令。
helm install read ./read
下面是成功执行安装命令后预期会看到的示例输出:
NAME: read
LAST DEPLOYED: Thu Sep 04 13:24:06 2019
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
read-57cb76bcf7-45sdh 0/1 ContainerCreating 0 0s
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
read LoadBalancer 10.110.44.86 localhost 5000:31301/TCP 0s
==> v1beta1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
read 0/1 1 0 0s
Kubernetes 部署可能需要几分钟才能完成。 若要确认 Pod 和服务是否已正确部署且可用,请执行以下命令:
kubectl get all
预期会看到类似于以下输出的内容:
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/read-57cb76bcf7-45sdh 1/1 Running 0 17s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 45h
service/read LoadBalancer 10.110.44.86 localhost 5000:31301/TCP 17s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/read 1/1 1 1 17s
NAME DESIRED CURRENT READY AGE
replicaset.apps/read-57cb76bcf7 1 1 1 17s
在 Kubernetes 群集上部署多个 v3 容器
从 v3 容器开始,可以在任务和页面级并行使用容器。
经设计,每个 v3 容器都有一个调度程序和一个识别工作线程。 调度程序负责将多页任务拆分为多个单页子任务。 识别工作线程为识别单个页面文档进行了优化。 若要实现页面级并行,请在负载均衡器后面部署多个 v3 容器,并让容器共用一个通用存储和队列。
注意
目前仅支持 Azure 存储和 Azure 队列。
接收请求的容器可以将任务拆分为单页子任务,并将它们添加到通用队列中。 不太繁忙的容器中的任何识别工作线程都可以使用队列中的单页子任务,执行识别,并将结果上传到存储。 吞吐量可以提高 n 倍,具体取决于所部署的容器的数量。
v3 容器在 /ContainerLiveness 路径下公开运行情况探测 API。 使用以下部署示例为 Kubernetes 配置运行情况探测。
将以下 YAML 复制并粘贴到名为 deployment.yaml 的文件。 请将 # {ENDPOINT_URI} 和 # {API_KEY} 注释替换为自己的值。 将 # {AZURE_STORAGE_CONNECTION_STRING} 注释替换为 Azure 存储连接字符串。 将 replicas 配置为你需要的数字,以下示例中将其设置为 3。
apiVersion: apps/v1
kind: Deployment
metadata:
name: read
labels:
app: read-deployment
spec:
selector:
matchLabels:
app: read-app
replicas: # {NUMBER_OF_READ_CONTAINERS}
template:
metadata:
labels:
app: read-app
spec:
containers:
- name: cognitive-services-read
image: mcr.microsoft.com/azure-cognitive-services/vision/read
ports:
- containerPort: 5000
env:
- name: EULA
value: accept
- name: billing
value: # {ENDPOINT_URI}
- name: apikey
value: # {API_KEY}
- name: Storage__ObjectStore__AzureBlob__ConnectionString
value: # {AZURE_STORAGE_CONNECTION_STRING}
- name: Queue__Azure__ConnectionString
value: # {AZURE_STORAGE_CONNECTION_STRING}
livenessProbe:
httpGet:
path: /ContainerLiveness
port: 5000
initialDelaySeconds: 60
periodSeconds: 60
timeoutSeconds: 20
---
apiVersion: v1
kind: Service
metadata:
name: azure-cognitive-service-read
spec:
type: LoadBalancer
ports:
- port: 5000
targetPort: 5000
selector:
app: read-app
运行以下命令。
kubectl apply -f deployment.yaml
下面是成功执行部署时可能看到的示例输出:
deployment.apps/read created
service/azure-cognitive-service-read created
Kubernetes 部署可能需要几分钟才能完成。 若要确认 Pod 和服务是否都已正确部署并可用,请执行以下命令:
kubectl get all
应该会看到类似以下的控制台输出:
kubectl get all
NAME READY STATUS RESTARTS AGE
pod/read-6cbbb6678-58s9t 1/1 Running 0 3s
pod/read-6cbbb6678-kz7v4 1/1 Running 0 3s
pod/read-6cbbb6678-s2pct 1/1 Running 0 3s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/azure-cognitive-service-read LoadBalancer 10.0.134.0 <none> 5000:30846/TCP 17h
service/kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 78d
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/read 3/3 3 3 3s
NAME DESIRED CURRENT READY AGE
replicaset.apps/read-6cbbb6678 3 3 3 3s
验证容器是否正在运行
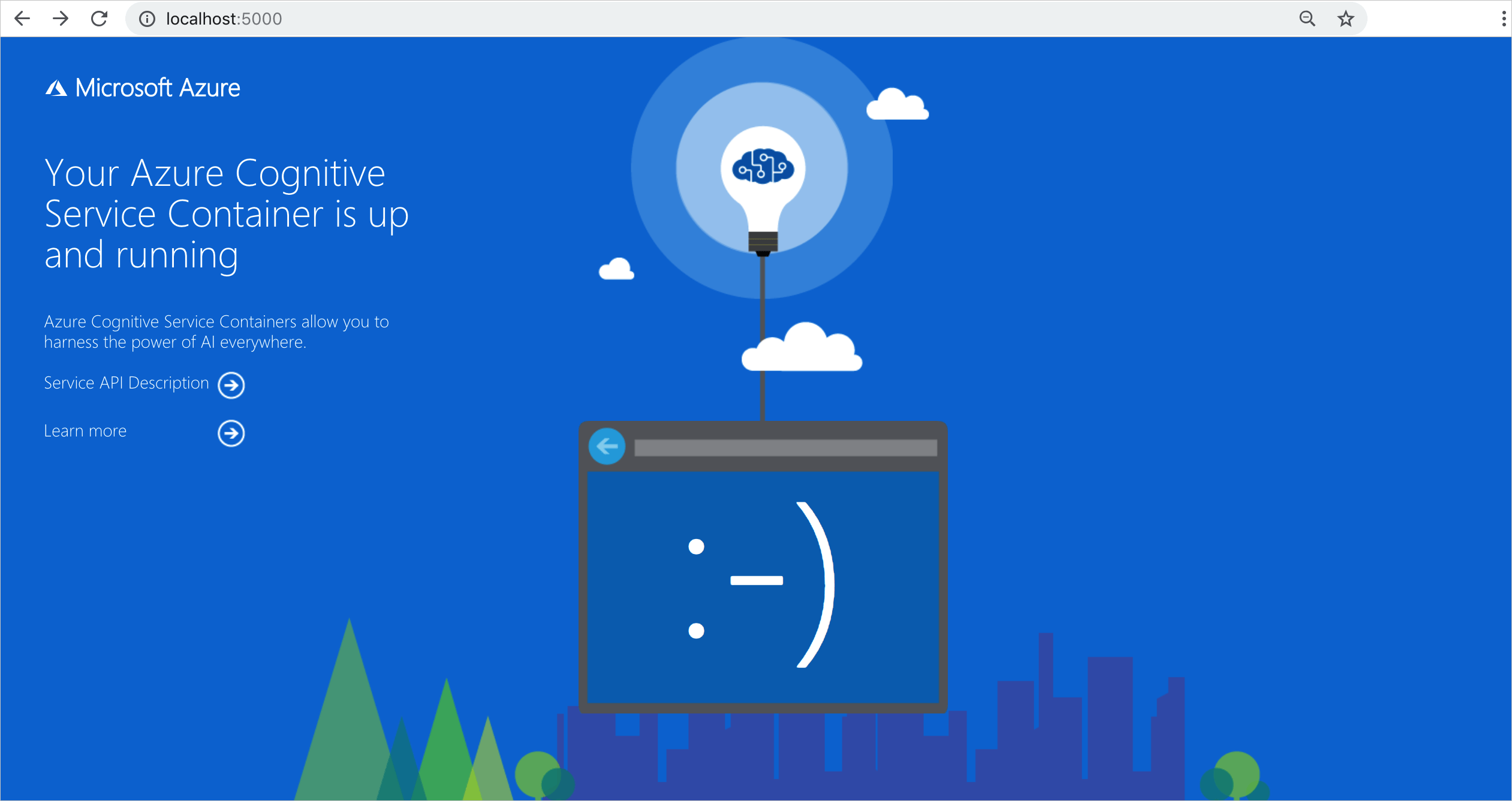
有几种方法可用于验证容器是否正在运行。 找到相关容器的外部 IP 地址和公开端口,并打开你常用的 Web 浏览器。 使用以下各种请求 URL 验证容器是否正在运行。 此处列出的示例请求 URL 是 http://localhost:5000,但是你的特定容器可能会有所不同。 请确保依赖容器的外部 IP 地址和公开端口。
| 请求 URL | 用途 |
|---|---|
http://localhost:5000/ |
容器提供主页。 |
http://localhost:5000/ready |
使用 GET 对此 URL 进行请求,可以验证容器是否已准备好接受针对模型的查询。 此请求可用于 Kubernetes 运行情况和就绪情况探测。 |
http://localhost:5000/status |
同样使用 GET 对此 URL 进行请求,可以验证用于启动容器的 api-key 是否有效,而不会导致终结点查询。 此请求可用于 Kubernetes 运行情况和就绪情况探测。 |
http://localhost:5000/swagger |
容器为终结点提供一组完整的文档以及“尝试”功能。 使用此功能可以将设置输入到基于 Web 的 HTML 表单并进行查询,而无需编写任何代码。 查询返回后,将提供示例 CURL 命令,用于演示所需的 HTTP 标头和正文格式。 |
后续步骤
有关在 Azure Kubernetes 服务 (AKS) 中使用 Helm 安装应用程序的更多详细信息,请访问此页。