你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
入门:文档智能工作室
此内容适用于:![]() v4.0(预览版) | 先前版本:
v4.0(预览版) | 先前版本:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
文档智能工作室是一种联机工具,用于在应用程序中通过文档智能服务直观地浏览、了解和集成功能。 若要开始使用,你可以使用示例或你自己的文档来探索预先训练过的模型。 你还可以通过 Python SDK 和其他快速入门,创建项目来生成自定义模板模型,并在应用程序中引用这些模型。
适用于新用户的先决条件
若要使用文档智能工作室,需要以下资产和设置:
提示
如果计划通过一个终结点/密钥访问多个 Azure AI 服务,请创建 Azure AI 服务资源。 请创建仅供文档智能访问的文档智能资源。 请注意,如果你打算使用 Microsoft Entra 身份验证,则需要单一服务资源。
文档智能现在支持在访问文档智能资源和存储帐户时进行本地(基于密钥)身份验证的 AAD 令牌身份验证。 请务必按照以下说明设置正确的访问角色,尤其是在使用 DisableLocalAuth 策略应用资源时。
正确限定范围的 Azure 角色分配对于文档分析和预生成模型,需要针对不同的方案执行以下角色分配。
基础✔️ 认知服务用户:需要此角色来访问文档智能或 Azure AI 服务资源以进入分析页面。
高级✔️ 参与者:需要此角色来创建资源组、文档智能服务或 Azure AI 服务资源。
有关授权的详细信息,请参阅 文档智能工作室授权策略。
注意
如果对文档智能服务资源禁用本地(基于密钥)身份验证,请确保获取认知服务用户角色,并且 AAD 令牌将用于对 Document Intelligence Studio 上的请求进行身份验证。 参与者角色仅允许列出密钥,但不允许在禁用密钥访问时使用资源。
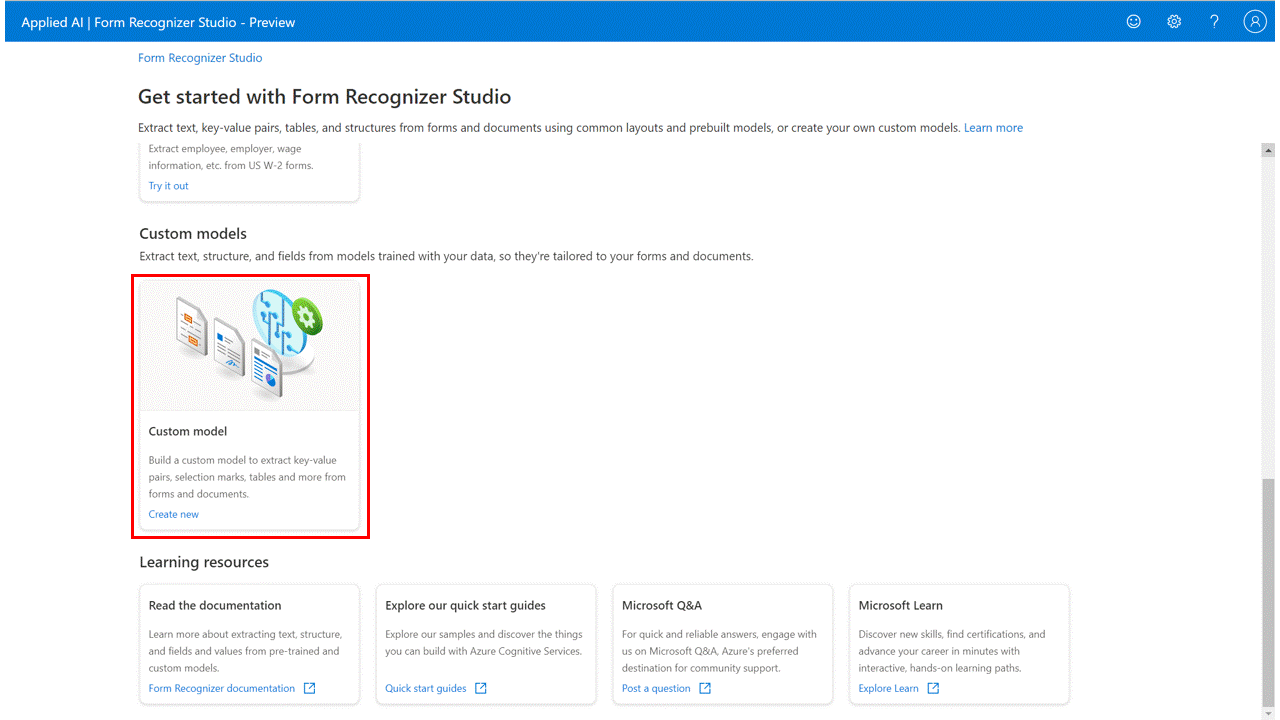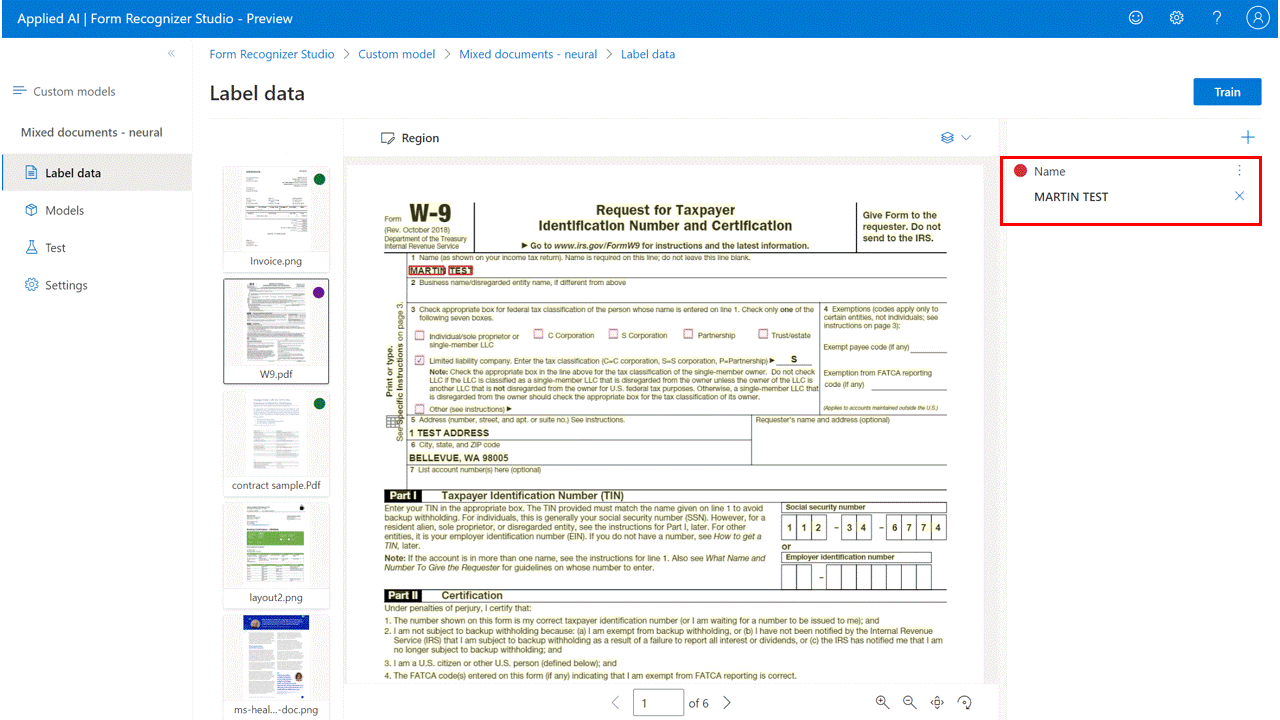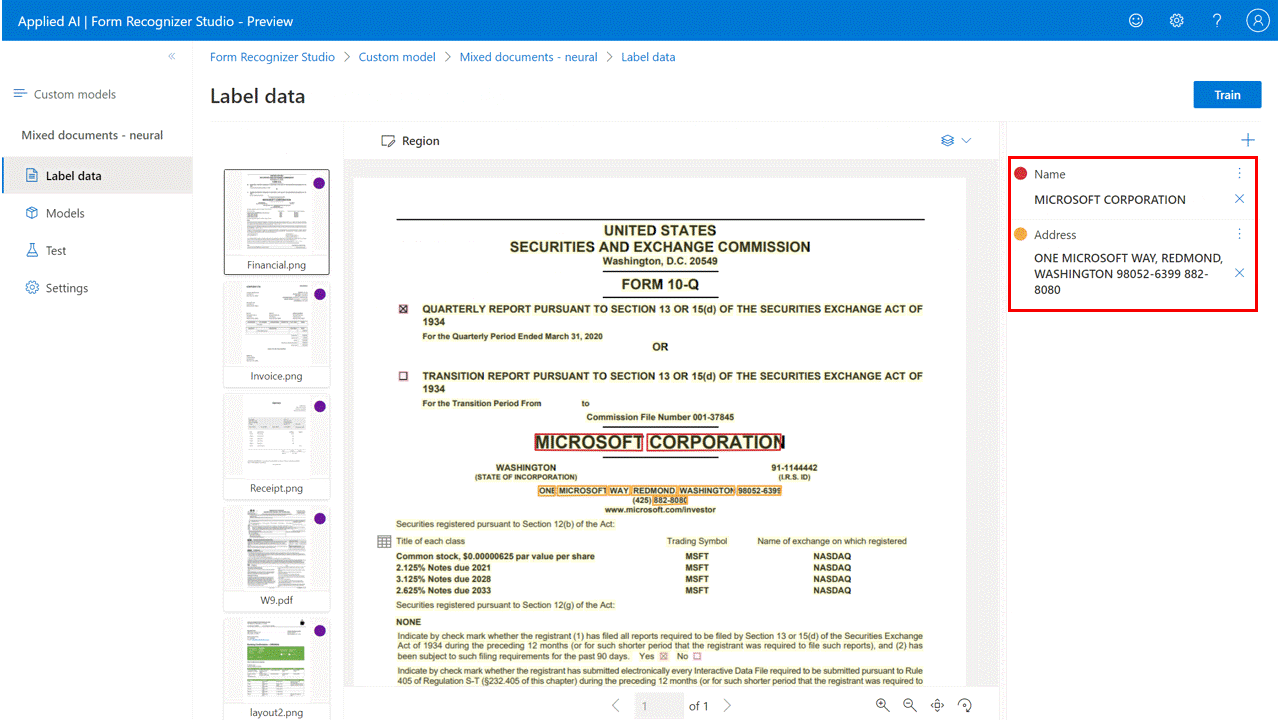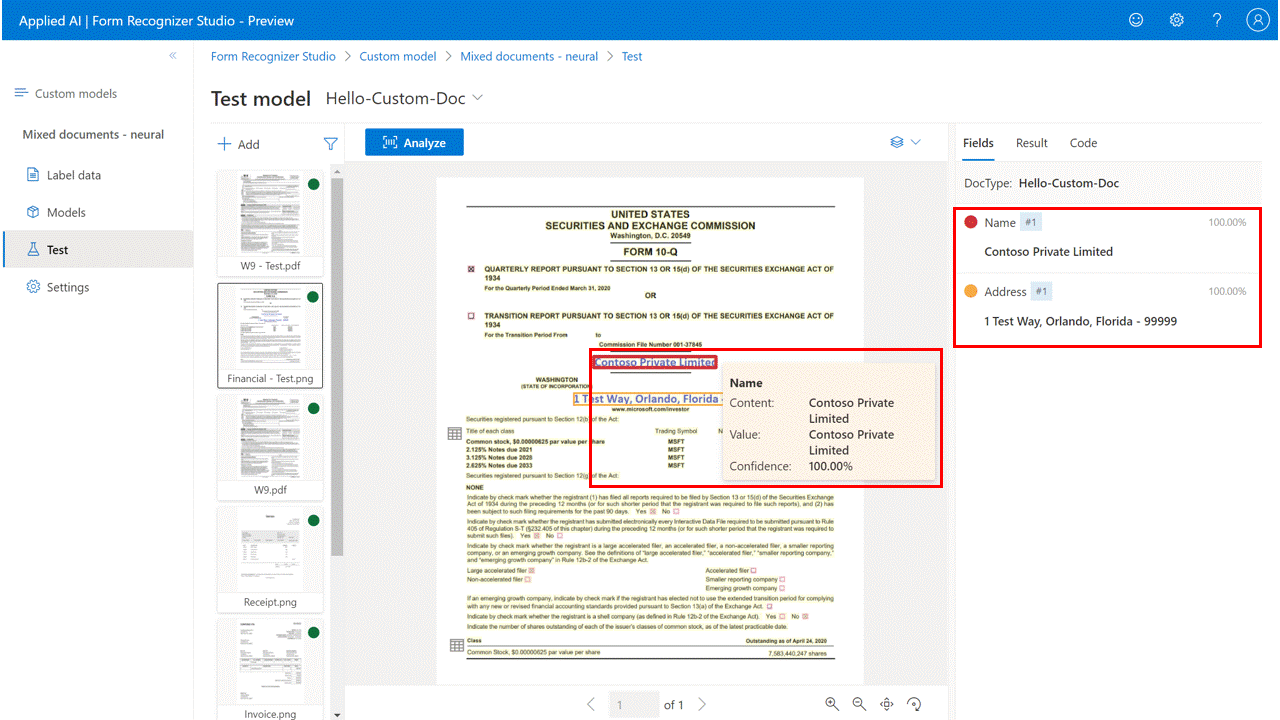
完成资源配置后,可以试用文档智能工作室提供的不同模型。 在首页中选择任何文档智能模型以尝试使用无代码方法。
要测试任何文档分析或预生成模型,请选择模型并使用一个示例文档或上传自己的文档进行分析。 分析结果显示在“内容”-“结果”-“代码”窗口的右侧。
需要在文档中训练自定义模型。 有关自定义模型的概述,请参阅自定义模型概述。
身份验证
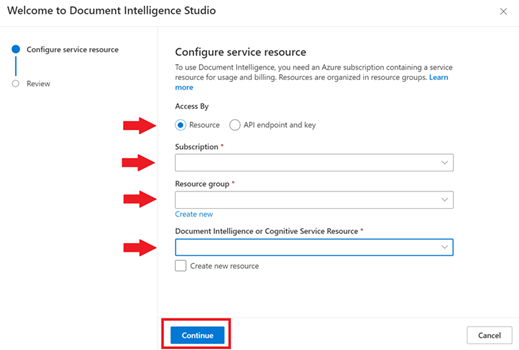
导航到“文档智能工作室”。 如果是首次登录,将显示一个弹出窗口,提示你配置服务资源。 根据组织的策略,可以使用一个或两个选项:
Microsoft Entra 身份验证:按资源授予访问权限(建议)。
选择现有订阅。
选择订阅中的现有资源组或创建新资源组。
选择现有的文档智能或 Azure AI 服务资源。
本地身份验证:按 API 终结点和密钥授予访问权限。
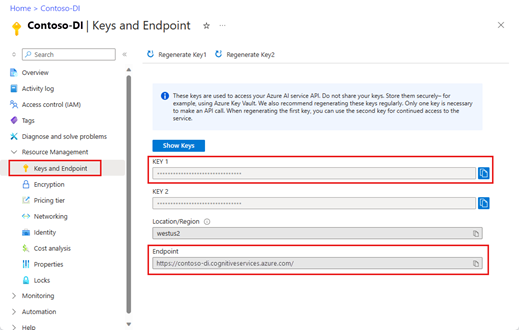
从 Azure 门户检索终结点和密钥。
转到资源的概述页,从左侧导航栏中选择“密钥和终结点”。
在适当的字段中输入值。
在文档智能工作室中验证方案之后,请使用 C#、Java、JavaScript 或 Python 客户端库或 REST API 开始将文档智能模型合并到自己的应用程序中。
若要详细了解每种模型,请参阅概念页面。
查看资源详细信息
要查看资源详细信息(如名称和定价层),请选择文档智能工作室主页右上角的“设置”图标,然后选择“资源”选项卡。如果有权访问其他资源,也可以切换资源。
模型
预生成模型有助于将文档智能功能添加到应用,而无需生成、训练和发布自己的模型。 可从多个预生成模型进行选择,每个模型都有其自己的受支持数据字段集。 要用于 analyze 操作的模型选择取决于要分析的文档类型。 文档智能当前支持以下预生成模型:
文档分析
- 布局:从文档(PDF 和 TIFF)和图像(JPG、PNG 和 BMP)提取文本、表、选择标记和结构信息。
- 读取:提取文本行、字词、其位置、检测到的语言和手写样式(如果从文档(PDF、TIFF)和图像(JPG、PNG、BMP)中检测到)。
预生成
- 发票:从发票中提取文本、选择标记、表、键值对和关键信息。
- 收据:从收据中提取文本和关键信息。
- 医疗保险卡:从美国医疗保险卡中提取保险公司、成员、处方、组号和其他关键信息。
- W-2:从 W-2 税务表单中提取文本和关键信息。
- ID 文档:从驾照和国际护照中提取文本和关键信息。
自定义
- 自定义提取模型:使用自定义提取模型从表单和文档中提取信息。 通过标记五个示例文档来快速训练模型。
- 自定义分类模型:训练自定义分类器以区分应用程序中的不同文档类型。 使用两个类和每个类的五个示例快速训练模型。
完成先决条件后,导航到 Document Intelligence Studio。
从工作室主页中,选择文档智能服务功能。 此步骤是一次性过程,除非你已从之前使用中选择了服务资源。 选择你的 Azure 订阅、资源组和资源。 (可以随时在顶部菜单的“设置”中更改资源。)查看和确认你选择。
选择“分析”按钮来对示例文档运行分析,或者使用“添加”命令来尝试处理你的文档。
放大和缩小,旋转文档视图,并使用屏幕底部的控件。
观察文档视图中突出显示的提取内容。 若要查看详细信息,请将鼠标悬停在键和值上。
设置输出部分的结果选项卡的格式,并浏览 JSON 输出,以便更好地了解服务响应。
选择“代码”选项卡并浏览示例代码进行集成。 复制并下载,以便开始使用。
适用于自定义项目的附加先决条件
除了 Azure 帐户和文档智能或 Azure AI 服务资源外,还需要:
Azure Blob 存储容器
标准性能 Azure Blob 存储帐户。 你将创建容器用于存储和组织存储帐户中的训练文档。 如果不知道如何使用容器创建 Azure 存储帐户,请按照以下快速入门中的说明操作:
- 创建存储帐户。 创建存储帐户时,请确保在“实例详细信息”→“性能”字段中选择“标准”性能 。
- 创建容器。 创建容器时,在“新建容器”窗口中将“公共访问级别”字段设置为“容器”(对容器和 Blob 进行匿名读取访问) 。
Azure 角色分配
对于自定义项目,不同方案需要以下角色分配。
基本
- 认知服务用户:需要在文档智能或 Azure AI 服务资源中具有此角色,来训练自定义模型或使用训练的模型进行分析。
- 存储 Blob 数据参与者:需要在存储帐户中具有此角色,来创建项目和标记数据。
高级
- 存储帐户参与者:存储帐户需要此角色才能设置 CORS 设置(如果重复使用同一存储帐户,此操作是一次性的工作量)。
- 参与者:需要此角色来创建资源组和资源。
注意
如果为文档智能服务资源和存储帐户禁用了本地(基于密钥)身份验证,请务必分别获取“认知服务用户”和“存储 Blob 数据参与者”角色,以便拥有足够的权限来使用文档智能工作室。 “存储帐户参与者”和“参与者”角色仅允许列出密钥,但在禁用密钥访问的情况下,不会向你授予使用资源的权限。
配置 CORS
需要在 Azure 存储帐户上配置 CORS(跨源资源共享),以便可以从文档智能工作室进行访问。 若要在 Azure 门户中配置 CORS,需要访问存储帐户的 CORS 选项卡。
选择存储帐户的 CORS 选项卡。
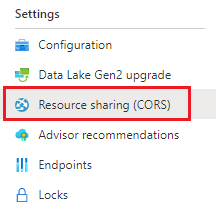
首先,在 Blob 服务中创建一个新的 CORS 条目。
将“允许的源”设置为“
https://documentintelligence.ai.azure.com”。
提示
可以使用通配符“*”(而不是指定域)允许所有源域通过 CORS 发出请求。
为“允许的方法”选择所有可用的 8 个选项。
通过在每个字段中输入 * 来批准所有“允许的标头”和“公开的标头” 。
将“最长时间”设置为 120 秒或任何可接受的值。
若要保存更改,选择页面顶部的“保存”按钮。
现在,CORS 应已配置为使用文档智能工作室中的存储帐户。
示例文档集
登录到 Azure 门户,然后导航到“存储帐户”>“数据存储”>“容器”。
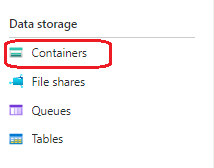
从列表中选择一个容器。
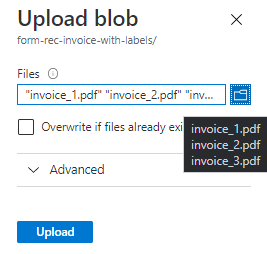
从页面顶部的菜单中选择“上传”。

此时会显示“上传 Blob”窗口。
选择要上传的文件。
注意
默认情况下,工作室将使用容器根目录下的文档。 但是,可以通过在自定义表单项目创建步骤中指定文件夹路径,来使用在文件夹中组织的数据。 请参阅在子文件夹中整理数据
自定义模式
若要创建自定义模型,请先配置项目:
在工作室主页中,选择“自定义模型”卡打开“自定义模型”页。
使用“创建项目”命令并启动“新建项目配置”向导。
输入项目详细信息,选择 Azure 订阅和资源,并选择包含你的数据的 Azure Blob 存储容器。
查看设置、提交并创建项目。
使用自动标签功能使用已训练的模型或预生成的模型之一进行标记。
使用手动标记定义用于提取的标签及其类型。
选择文档中的文本,然后从下拉列表或标签窗格中选择标签。
标记 4 个以上的文档,以至少标记 5 个文档。
选择“训练”命令并输入模型名称,选择你想要神经网络(推荐)还是模板模型以开始训练你的自定义模型。
模型准备就绪后,使用“Test”命令,对测试文档进行验证并观察结果。
标记为表
备注
使用“删除”命令删除不需要的模型。
下载模型详细信息供脱机查看。
选择多个模型,并将其组合到一个新模型中,以便在应用程序中使用。
使用表作为视觉对象模式:
对于自定义表单模型,在创建自定义模型时,可能需要从文档中提取数据集合。 数据收集可能会以几种格式出现。 使用表作为视觉对象模式:
给定一组字段(列)的值(行)的动态或变量计数
给定一组字段(列和/或行)的值的特定集合
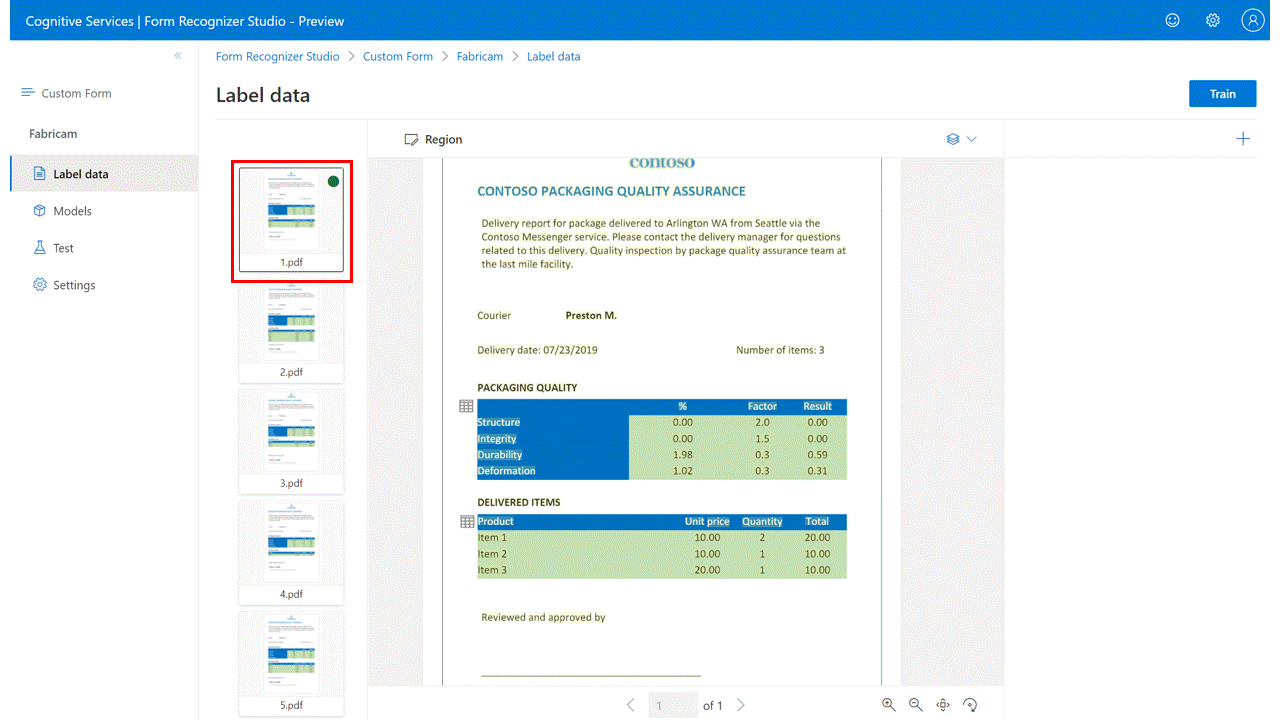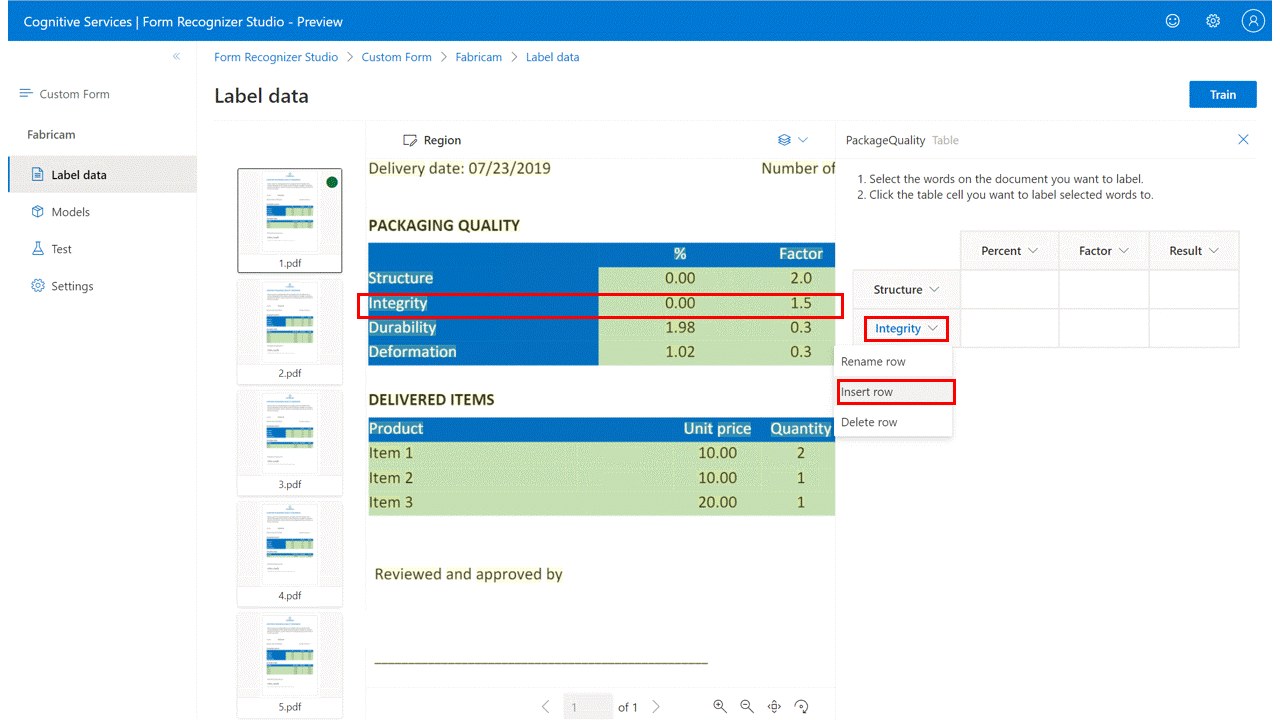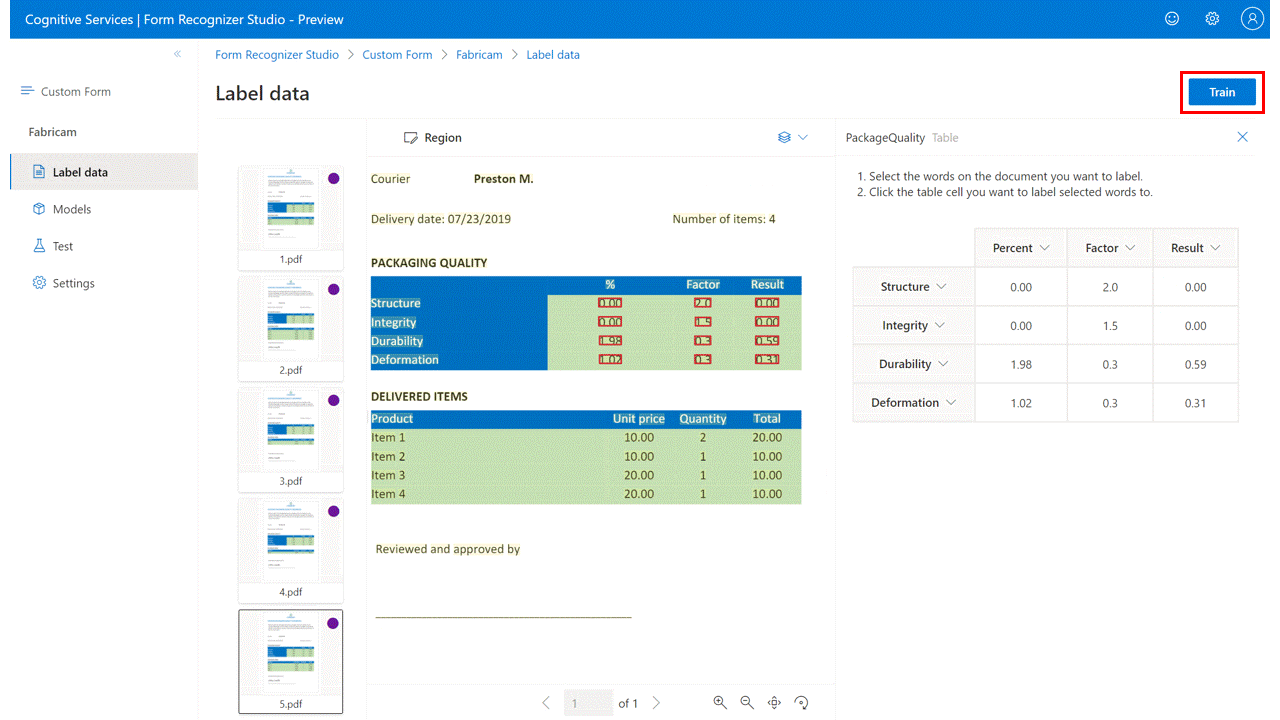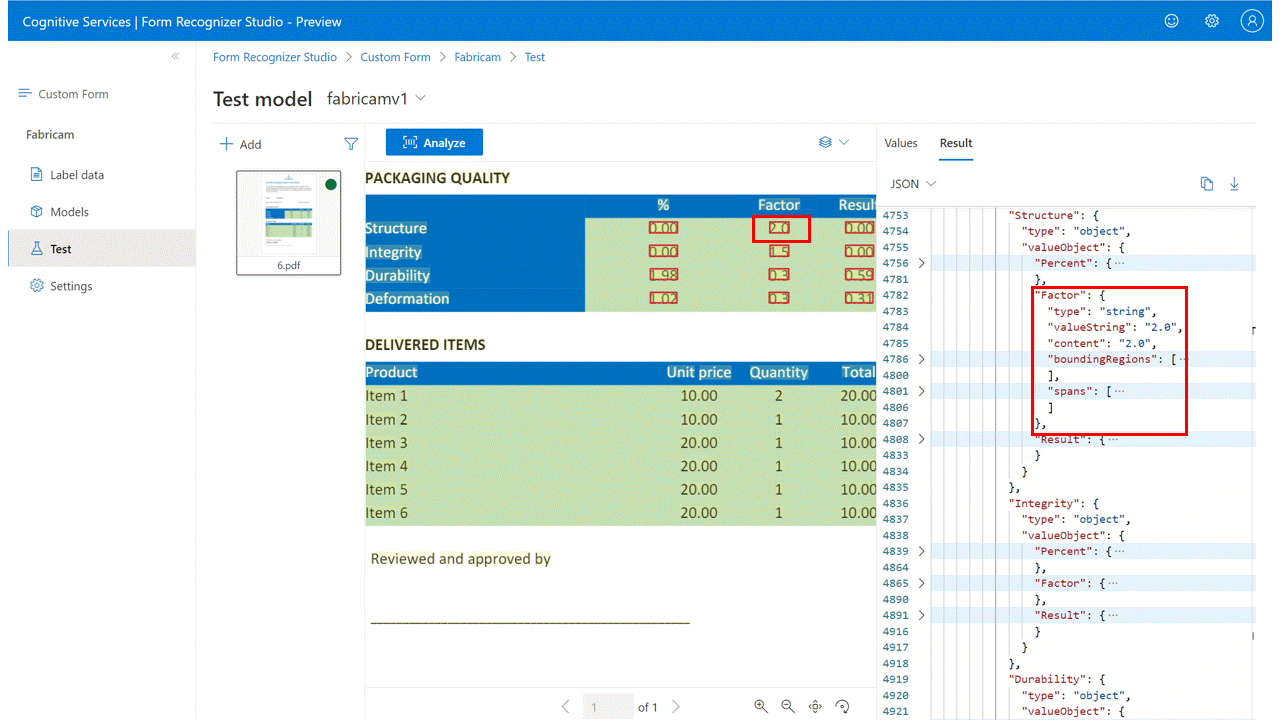
标记为动态表
使用动态表提取给定一组字段(列)的值(行)的变量计数:
添加新的“表”类型标签,选择“动态表”类型,并为标签命名。
添加所需的列(字段)数和行(数据)数。
选择页面中的文本,然后选择单元格并将其分配到文本。 对所有文档的所有页中的所有行和列重复此操作。

标记为固定表
使用固定表提取给定一组字段(列和/或行)的值的特定集合:
创建新的“表”类型标签,选择“固定表”类型,并为其命名。
添加需要对应于两组字段的列数和行数。
选择页面中的文本,然后选择单元格并将其分配到文本。 对其他文档重复上述步骤。
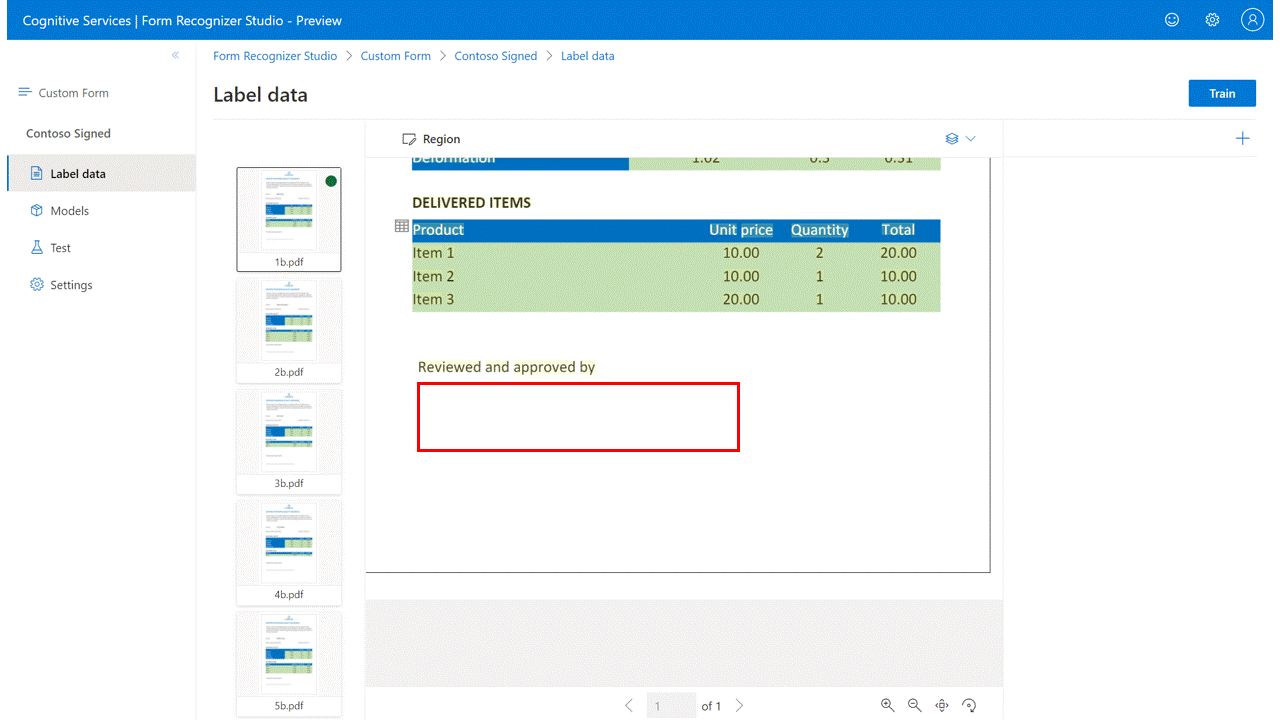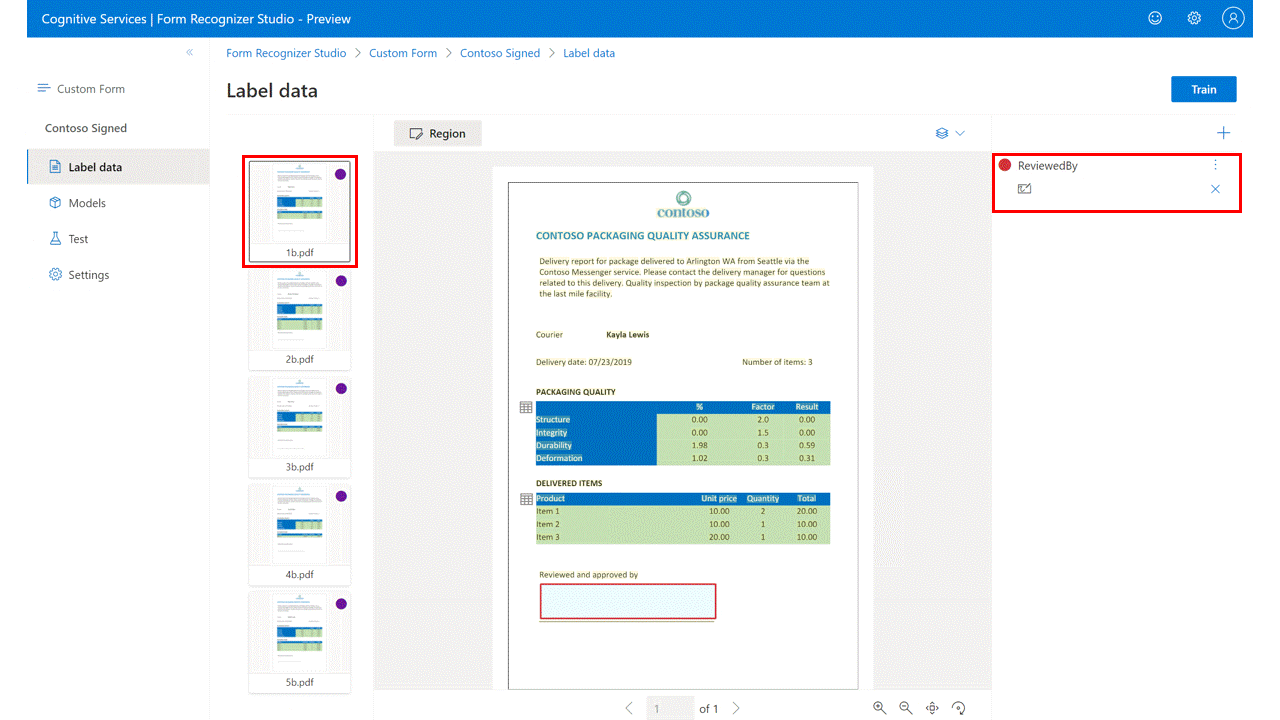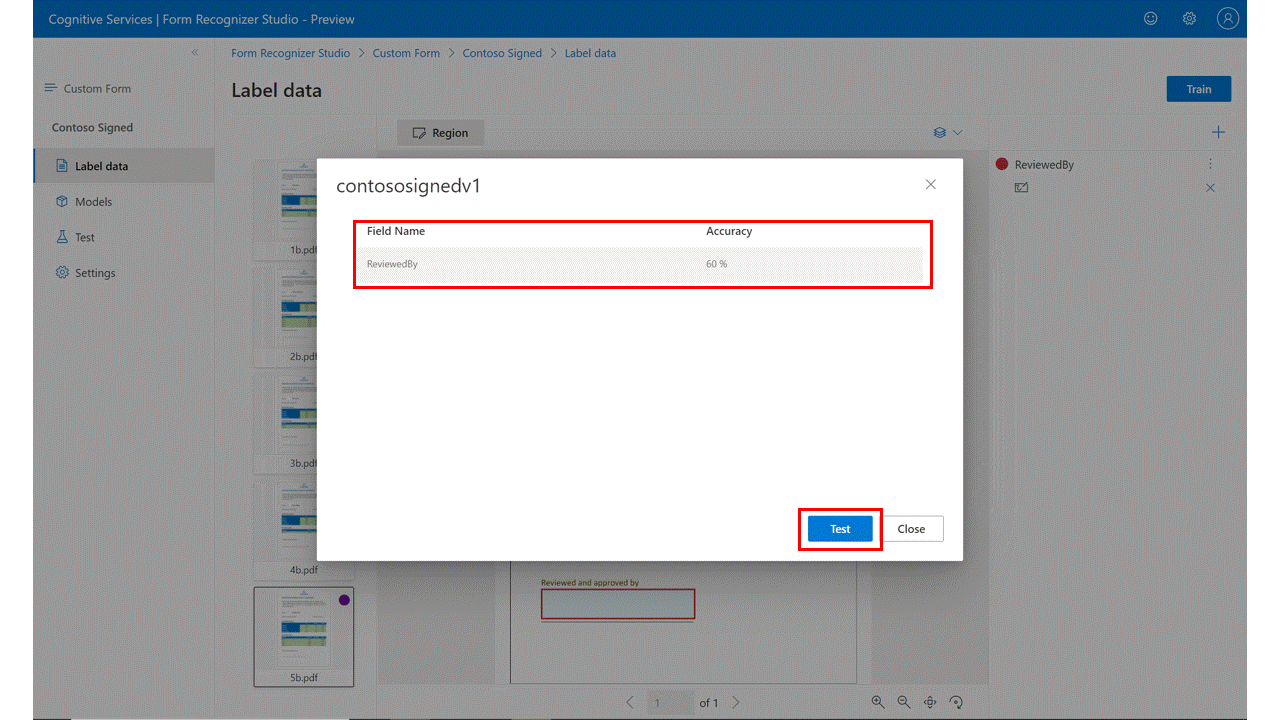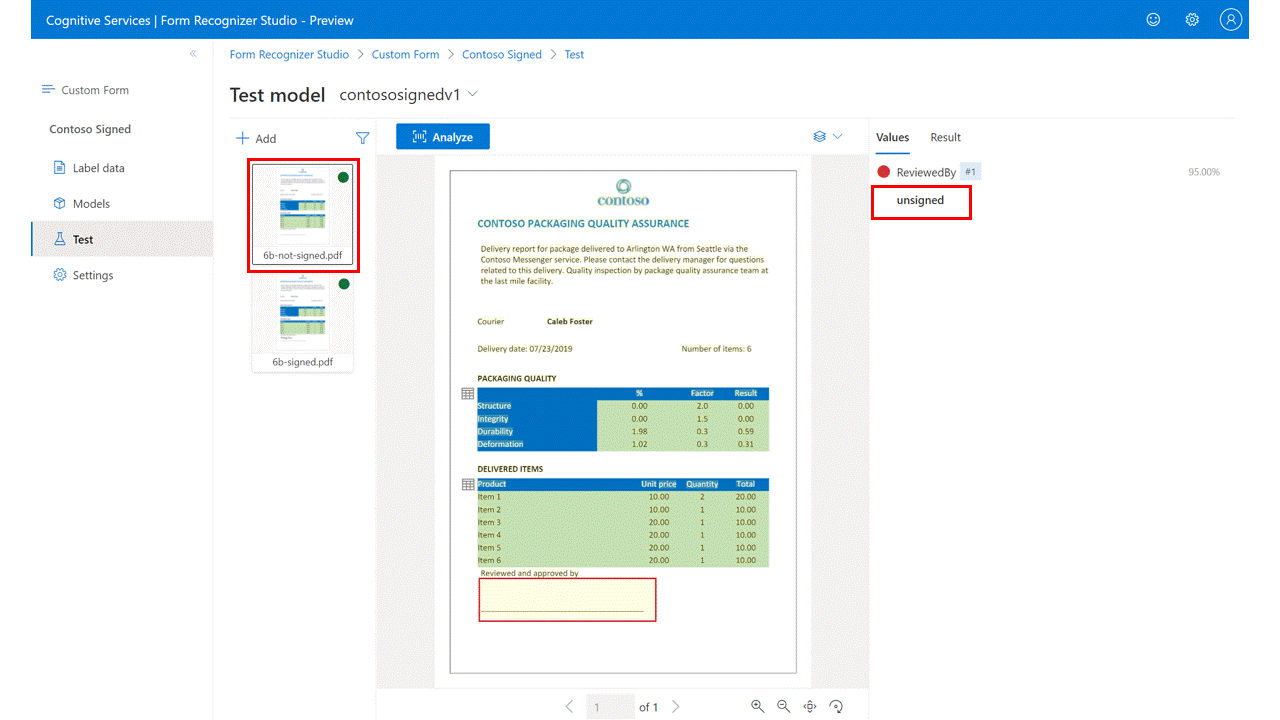
签名检测
备注
目前只有自定义模板模型支持签名字段。 训练自定义神经模型时,将忽略标记的签名字段。
为签名检测提供标记:(仅限自定义表单)
在标记视图中,创建新的“签名”类型标签并为其命名。
使用“区域”命令在签名的预期位置创建一个矩形区域。
选择绘制区域,然后选择“签名”类型标签,并将其分配到你的绘制区域。 对其他文档重复上述步骤。
后续步骤
- 请遵循文档智能 v3.1 迁移指南,了解与 REST API 先前版本的区别。
- 浏览 v3.0 SDK 快速入门,以使用新的客户端库尝试应用程序中的 v3.0 功能。
- 请参阅 v3.0 REST API 快速入门,以使用新的 REST API 试用 v3.0 功能。
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈