你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
训练专业声音模型
本文介绍如何通过 Speech Studio 门户训练神经网络定制声音。
训练持续时间因使用的数据量而异。 训练神经网络定制声音平均需要约 40 个计算小时。 标准订阅 (S0) 用户可以同时训练四个声音。 如果达到限制,请先等待,直至至少其中一种声音模型训练完毕,然后再试。
注意
尽管每种训练方法所需的总小时数不同,但每种训练方法的单价是相同的。 有关详细信息,请参阅神经网络定制训练定价详细信息。
选择训练方法
验证数据文件后,可使用它们生成神经网络定制声音模型。 创建神经网络定制声音时,可以选择使用以下方法之一对其进行训练:
神经网络:使用与训练数据所使用相同的语言来创建声音。
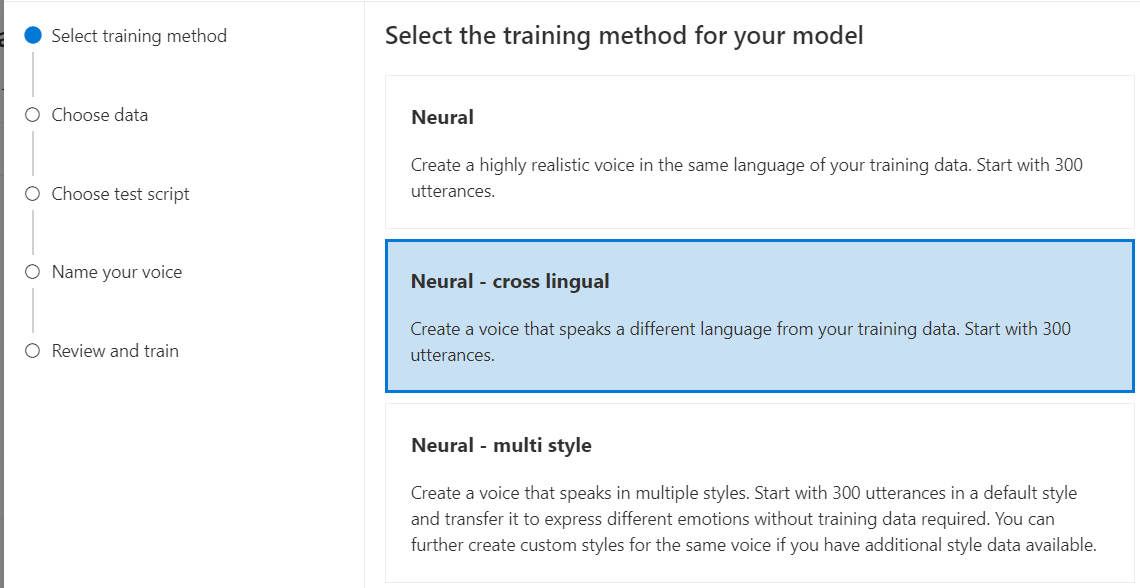
神经网络 - 跨语言:创建与训练数据不同语言的声音。 例如,使用
zh-CN训练数据,可以创建讲述en-US语言的声音。训练数据的语言和目标语言都必须是跨语言语音训练支持的语言之一。 无需准备目标语言的训练数据,但测试脚本必须采用目标语言。
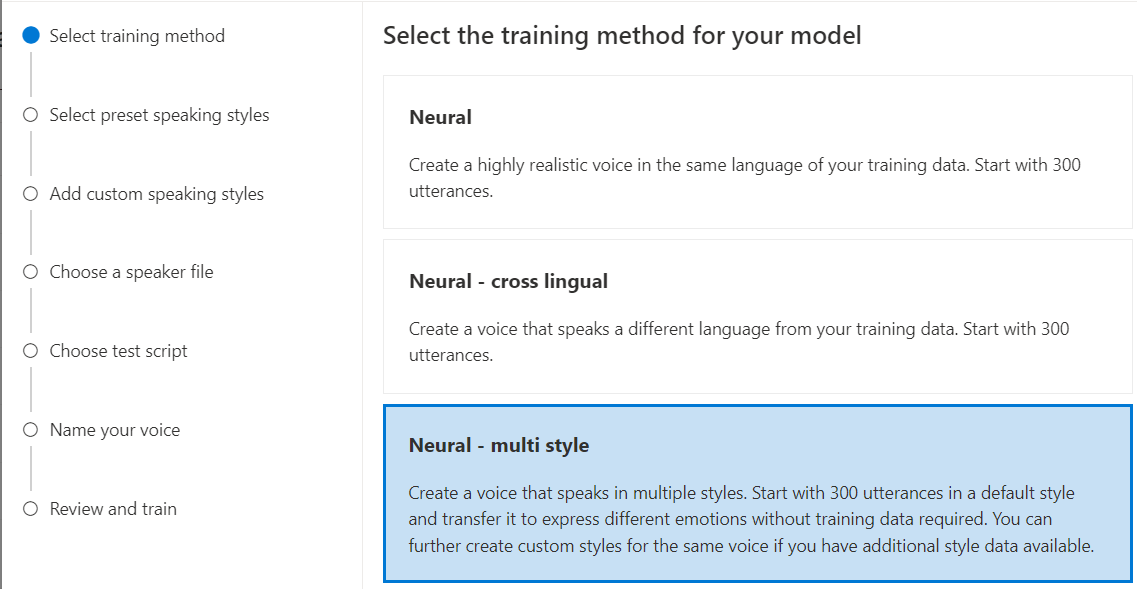
神经网络 - 多风格:创建以多种风格和情绪讲述的神经网络定制声音,而无需添加新的训练数据。 多风格声音对于视频游戏角色、对话聊天机器人、有声读物和内容阅读器等非常有用。
要创建多风格声音,需要准备至少 300 个语句的一组常规训练数据。 选择一个或多个预设目标说话风格。 还可以通过提供风格示例(每种风格至少 100 个语句)作为同一声音的额外训练数据来创建多种自定义风格。 支持的预设风格因语言而异。 请参阅跨不同语言的可用预设风格。
训练数据的语言必须是神经网络定制声音、跨语言或多风格训练支持的语言之一。
训练自定义神经语音模型
若要在 Speech Studio 中创建神经网络定制声音,请根据以下方法之一执行相应的步骤:
登录 Speech Studio。
选择“定制声音”> <你的项目名称> >“训练模型”>“训练新模型”。
选择“神经网络”作为模型的训练方法,然后选择“下一步”。 若要使用其他训练方法,请参阅神经网络 - 跨语言或神经网络 - 多风格。
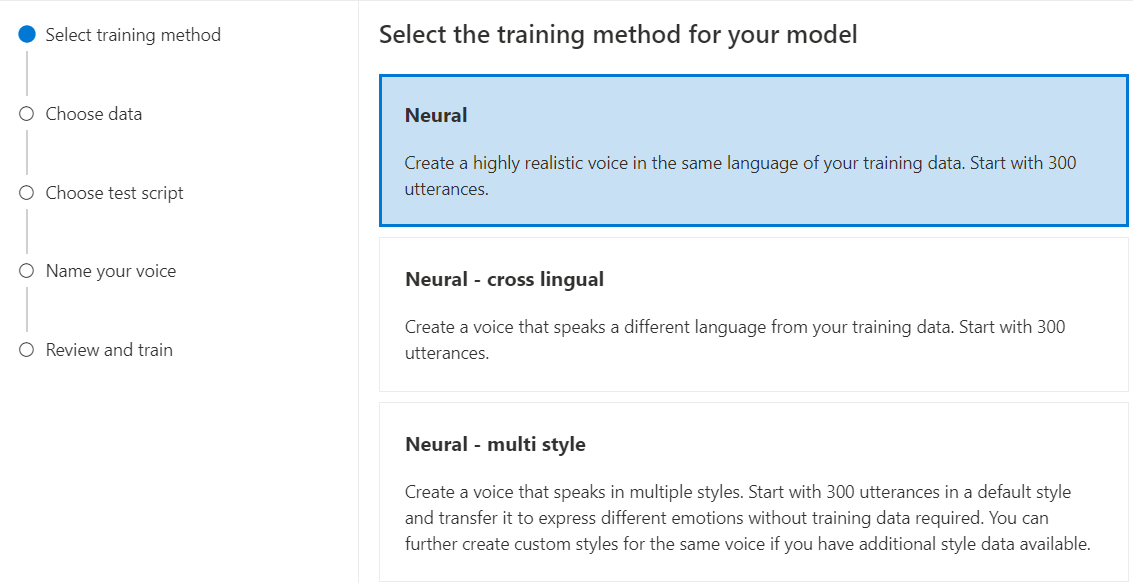
为模型选择一个训练配方版本。 默认情况下会选择最新版本。 支持的功能和训练时间因版本而异。 通常,我们建议使用最新版本。 在某些情况下,可以选择旧版本来减少训练时间。 有关双语训练和不同区域设置之间的差异的详细信息,请参阅双语训练。
注意
模型版本
V2.2021.07、V4.2021.10、V5.2022.05、V6.2022.11、V9.2023.10将于 2024 年 10 月 1 日停用。 在这些已停用版本上创建的语音模型不会受到影响。选择用于训练的数据。 在训练中将会删除重复的音频名称。 确保所选数据在多个 .zip 文件中不包含相同的音频名称。
只能选择已成功处理的数据集进行训练。 如果在列表中未看到你的训练集,请检查数据处理状态。
选择与训练数据中的说话人对应的、包含发音人声明的说话人文件。
选择“下一步” 。
每次训练会自动生成 100 个示例音频文件,以帮助你使用默认脚本来测试模型。
(可选)还可选择“添加自己的测试脚本”,并为自己的测试脚本提供最多 100 个语句来测试模型,而无需额外付费。 生成的音频文件是自动测试脚本与自定义测试脚本的组合。 有关详细信息,请参阅测试脚本要求。
输入名称以帮助识别模型。 请谨慎选择名称。 模型名称将通过 SDK 和 SSML 输入用作语音合成请求中的声音名称。 只允许字母、数字以及一些标点字符。 请对不同的神经声音模型使用不同名称。
(可选)输入说明以帮助识别模型。 通常使用说明来记录用于创建模型的数据的名称。
选择下一步。
查看设置并选中接受使用条款的复选框。
选择“提交”以开始训练模型。
双语训练
如果你选择“神经网络”训练类型,则可以训练语音来以多种语言说话。 zh-CN、zh-HK 和 zh-TW 区域设置支持对语音进行双语训练,使其能够讲中文和英语。 合成语音可以讲带有英语母语口音的英语,也可以讲与训练数据具有相同口音的英语,这在一定程度上取决于你的训练数据。
注意
若要在 zh-CN 区域设置中使语音能够以与样本数据相同的口音讲英语,则应在创建项目时选择 Chinese (Mandarin, Simplified), English bilingual,或通过 REST API 为训练集数据指定 zh-CN (English bilingual) 区域设置。
下表显示了区域设置之间的差异:
| Speech Studio 区域设置 | REST API 区域设置 | 双语支持 |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
如果你的样本数据包括英语,则无论英语数据的数量有多少,合成语音讲的英语都带有英语母语口音,而不是与样本数据相同的口音。 |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
如果你希望合成语音的英语口音与样本数据相同,我们建议你在训练集中包括 10% 以上的英语数据。 否则,英语口音可能不理想。 |
Chinese (Cantonese, Simplified) |
zh-HK |
如果你想训练能够用与你的样本数据相同的口音讲英语的合成语音,请确保在你的训练集中提供超过 10% 的英语数据。 否则,它默认为英语母语口音。 10% 这个阈值是根据成功上传后接受的数据计算的,而不是根据上传前的数据。 如果某些上传的英语数据由于缺陷而被拒绝,并且不满足 10% 这个阈值,则合成语音默认为英语母语口音。 |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
如果你想训练能够用与你的样本数据相同的口音讲英语的合成语音,请确保在你的训练集中提供超过 10% 的英语数据。 否则,它默认为英语母语口音。 10% 这个阈值是根据成功上传后接受的数据计算的,而不是根据上传前的数据。 如果某些上传的英语数据由于缺陷而被拒绝,并且不满足 10% 这个阈值,则合成语音默认为英语母语口音。 |
跨不同语言的可用预设样式
下表根据不同的语言汇总了不同的预设风格。
| 说话风格 | 语言(区域设置) |
|---|---|
| 生气 | 英语(美国)(en-US)日语(日本)( ja-JP) 1中文(普通话,简体)( zh-CN) 1 |
| 平静 | 中文(普通话,简体)(zh-CN) 1 |
| 聊天 | 中文(普通话,简体)(zh-CN) 1 |
| 开心 | 英语(美国)(en-US)日语(日本)( ja-JP) 1中文(普通话,简体)( zh-CN) 1 |
| 不满 | 中文(普通话,简体)(zh-CN) 1 |
| 兴奋 | 英语(美国)(en-US) |
| 害怕 | 中文(普通话,简体)(zh-CN) 1 |
| 友好 | 英语(美国)(en-US) |
| 乐观 | 英语(美国)(en-US) |
| 悲伤 | 英语(美国)(en-US)日语(日本)( ja-JP) 1中文(普通话,简体)( zh-CN) 1 |
| 大喊大叫 | 英语(美国)(en-US) |
| 严肃 | 中文(普通话,简体)(zh-CN) 1 |
| 害怕 | 英语(美国)(en-US) |
| 不友好 | 英语(美国)(en-US) |
| 窃窃私语 | 英语(美国)(en-US) |
1神经网络声音风格以公共预览版提供。 公共预览版中的声音风格只在美国东部、西欧和东南亚这三个服务区域提供。
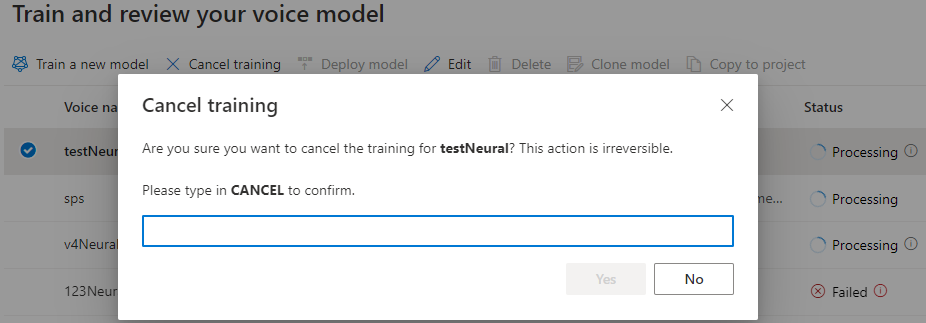
“训练模型”表会显示与新建模型相对应的新条目。 状态反映了将数据转换为声音模型的过程,如下表中所述:
| 状态 | 含义 |
|---|---|
| 正在处理 | 正在创建声音模型。 |
| 已成功 | 声音模型已创建并可部署。 |
| 已失败 | 训练声音模型时失败。 失败的原因可能是未发现的数据问题或网络问题等。 |
| 已取消 | 已取消声音模型的训练。 |
当模型状态为“正在处理”时,可以选择“取消训练”来取消声音模型。 对于这个取消的训练,系统不会向你收费。
成功完成模型训练后,可以查看模型详细信息并测试声音模型。
可以使用 Speech Studio 中的有声内容创作工具来创建音频并微调部署的声音。 如果可用于你的声音,则可以选择多种风格之一。
重命名模型
如果要重命名生成的模型,可以选择“克隆模型”,以在当前项目中使用新名称创建模型克隆。
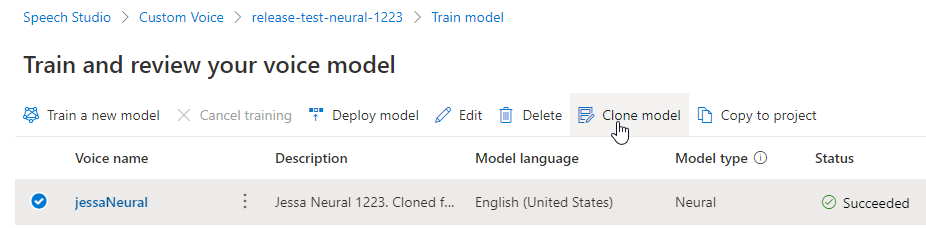
在“克隆声音模型”窗口中输入新名称,然后选择“提交”。 文本“神经网络”将自动添加为新模型名称的后缀。
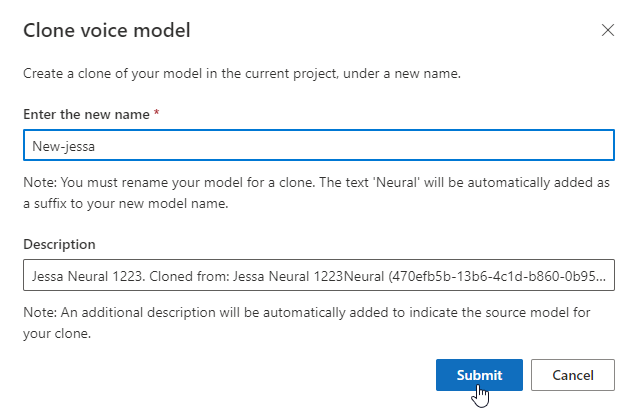
测试声音模型
成功生成语音模型以后,可以先使用生成的示例音频文件对其进行测试,然后再部署模型。
声音的质量取决于许多因素,例如:
- 训练数据的大小。
- 录制内容的质量。
- 脚本文件的准确性。
- 训练数据中录制的声音与为目标用例设计的声音个性的匹配程度。
选择“测试”下的“DefaultTests”以收听示例音频文件。 默认测试示例包括训练期间自动生成的 100 个示例音频文件,可帮助测试模型。 除了默认情况下提供的这 100 个音频之外,系统还会将你自己的测试脚本语句添加到 DefaultTests 集。 此添加操作最多可添加 100 个语句。 对于使用 DefaultTests 进行的测试,不收取费用。
如果要上传自己的测试脚本以进一步测试模型,请选择“添加测试脚本”以上传自己的测试脚本。
上传测试脚本之前,请查看测试脚本要求。 系统会根据可计费字符数,对使用批量合成进行的额外测试收取费用。 请参阅 Azure AI 语音定价。
在“添加测试脚本”下,选择“浏览文件”以选择自己的脚本,然后选择“添加”以上传它。
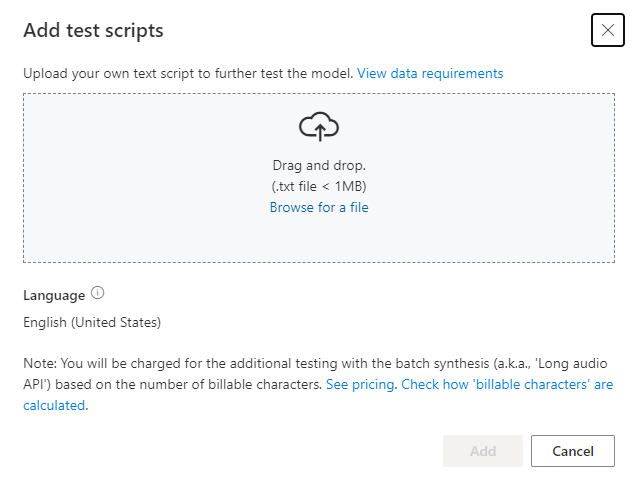
测试脚本要求
测试脚本必须是小于 1 MB 的 .txt 文件。 支持的编码格式包括 ANSI/ASCII、UTF-8、UTF-8-BOM、UTF-16-LE 或 UTF-16-BE。
与训练听录文件不同,测试脚本应排除语句 ID(即每个语句的文件名)。 否则,会朗读这些 ID。
下面是一个 .txt 文件中的一组示例语句:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
每个语句段落都生成一个单独的音频。 如果要将所有句子合并为一个音频,请将它们放在一个段落中。
备注
生成的音频文件是自动测试脚本与自定义测试脚本的组合。
更新声音模型的引擎版本
Azure 文本转语音引擎会不时更新,以捕获定义语言发音的最新语言模型。 在训练声音后,可以通过更新到最新引擎版本将你的声音应用于新的语言模型。
当有新引擎可用时,系统会提示你更新神经声音模型。

转到模型详细信息页并按照屏幕上的说明安装最新引擎。
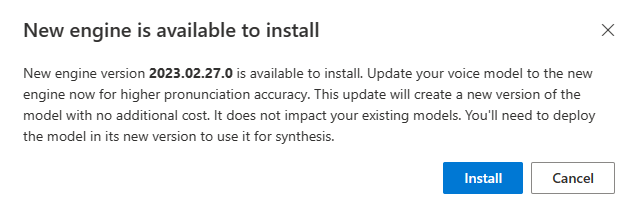
也可以稍后选择“安装最新引擎”来将模型更新为最新的引擎版本。
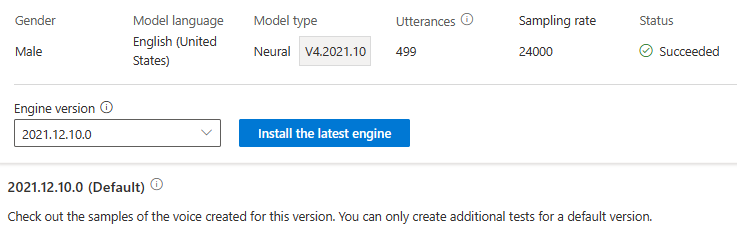
引擎更新不收费。 以前的版本仍然保留。
可以在“引擎版本”下拉列表中检查模型的所有引擎版本,或移除不再需要的版本。
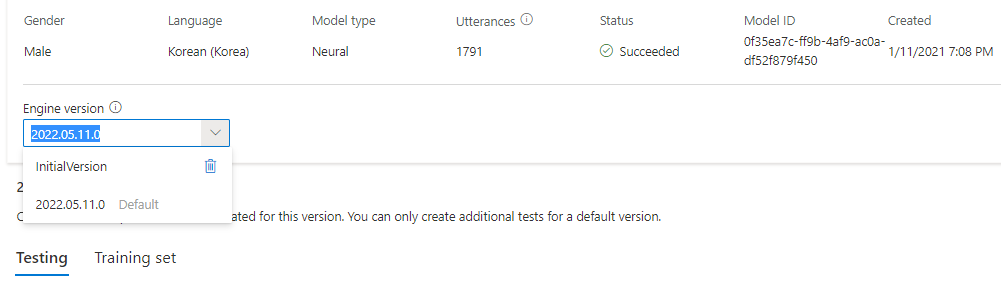
更新的版本会自动设置为默认值。 但是,你可以通过从下拉列表中选择某个版本并选择“设置为默认值”来更改默认版本。
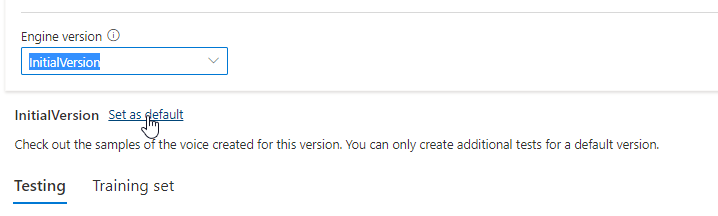

如果要测试声音模型的每个引擎版本,则可以从下拉列表中选择某个版本,然后选择“测试”下的“DefaultTests”来收听示例音频文件。 如果要上传自己的测试脚本来进一步测试当前引擎版本,请先确保将该版本设置为默认版本,然后按照测试声音模型中的步骤进行操作。
更新引擎将创建新版本的模型,且无需额外付费。 更新声音模型的引擎版本后,需要部署新版本以创建新终结点。 只能部署默认版本。
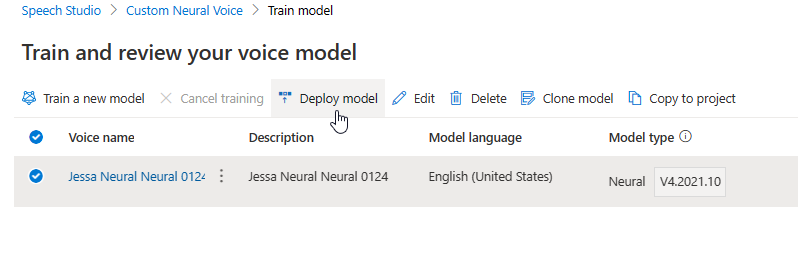
创建新终结点后,需要将流量转移到产品中的新终结点。
要详细了解此功能的功能和限制,以及提高模型质量的最佳做法,请参阅使用神经网络定制声音的特征和限制。
将声音模型复制到另一个项目
可以将声音模型复制到同一区域或另一区域的另一个项目。 例如,可以将在一个区域训练的神经声音模型复制到另一区域的项目。
备注
神经网络定制声音训练目前仅在部分区域可用。 可以将神经网络声音模型从这些区域复制到其他区域。 有关详细信息,请参阅自定义神经语音的区域。
若要将神经网络定制声音模型复制到另一个项目:
在“训练模型”选项卡上,选择要复制的声音模型,然后选择“复制到项目”。
选择要复制模型的“订阅”、“区域”、“语音资源”和“项目”。 必须在目标区域具有语音资源和项目,否则需要先创建它们。
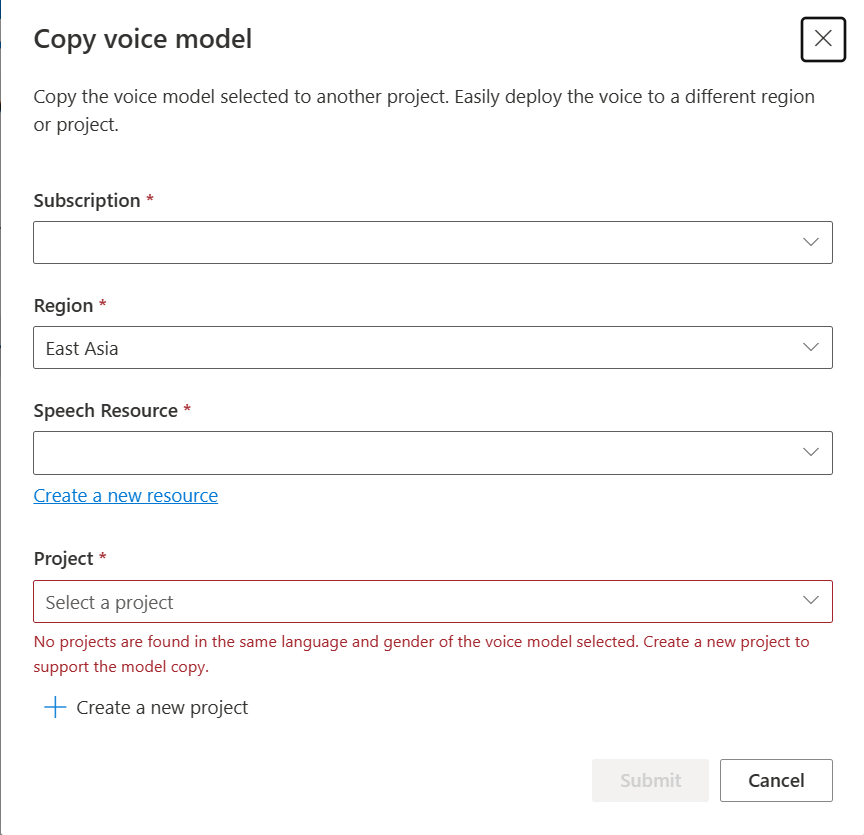
选择“提交”以复制模型。
在成功复制的通知消息下选择“查看模型”。
导航到在其中复制了模型的项目以部署模型副本。
后续步骤
本文介绍如何通过定制声音 API 训练神经网络定制声音。
重要
神经网络定制声音训练目前仅在部分区域可用。 在受支持区域中训练声音模型后,可以根据需要将其复制到另一个区域中的语音资源。 有关详细信息,请参阅语音服务表的脚注。
训练持续时间因使用的数据量而异。 训练神经网络定制声音平均需要约 40 个计算小时。 标准订阅 (S0) 用户可以同时训练四个声音。 如果达到限制,请先等待,直至至少其中一种声音模型训练完毕,然后再试。
注意
尽管每种训练方法所需的总小时数不同,但每种训练方法的单价是相同的。 有关详细信息,请参阅神经网络定制训练定价详细信息。
选择训练方法
验证数据文件后,可使用它们生成神经网络定制声音模型。 创建神经网络定制声音时,可以选择使用以下方法之一对其进行训练:
神经网络:使用与训练数据所使用相同的语言来创建声音。
神经网络 - 跨语言:创建与训练数据不同语言的声音。 例如,使用
fr-FR训练数据,可以创建讲述en-US语言的声音。训练数据的语言和目标语言都必须是跨语言语音训练支持的语言之一。 无需准备目标语言的训练数据,但测试脚本必须采用目标语言。
神经网络 - 多风格:创建以多种风格和情绪讲述的神经网络定制声音,而无需添加新的训练数据。 多风格声音对于视频游戏角色、对话聊天机器人、有声读物和内容阅读器等非常有用。
要创建多风格声音,需要准备至少 300 个语句的一组常规训练数据。 选择一个或多个预设目标说话风格。 还可以通过提供风格示例(每种风格至少 100 个语句)作为同一声音的额外训练数据来创建多种自定义风格。 支持的预设风格因语言而异。 请参阅跨不同语言的可用预设风格。
训练数据的语言必须是神经网络定制声音、跨语言或多风格训练支持的语言之一。
创建声音模型
若要创建神经网络声音,请使用定制声音 API 的 Models_Create 操作。 根据以下说明构造请求正文:
- 设置所需的
projectId属性。 请参阅创建项目。 - 设置所需的
consentId属性。 请参阅添加发音人同意。 - 设置所需的
trainingSetId属性。 请参阅创建训练集。 - 将神经网络声音训练必需的方案
kind属性设置为Default。 方案类型指示训练方法,无法更改。 若要使用其他训练方法,请参阅神经网络 - 跨语言或神经网络 - 多风格。 有关双语训练和不同区域设置之间的差异的详细信息,请参阅双语训练。 - 设置所需的
voiceName属性。 声音名称必须以“神经网络”结尾,无法更改。 请谨慎选择名称。 声音名称将通过 SDK 和 SSML 输入在语音合成请求中使用。 只允许字母、数字以及一些标点字符。 请对不同的神经声音模型使用不同名称。 - (可选)设置声音说明的
description属性。 此声音说明可以更改。
使用 URI 发出 HTTP PUT 请求,如以下 Models_Create 示例所示。
- 将
YourResourceKey替换为语音资源密钥。 - 将
YourResourceRegion替换为语音资源区域。 - 将
JessicaModelId替换为所选的模型 ID。 模型的 URI 中将使用区分大小写的 ID 并且此 ID 以后无法更改。
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
你应该会收到以下格式的响应正文:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
双语训练
如果你选择“神经网络”训练类型,则可以训练语音来以多种语言说话。 zh-CN、zh-HK 和 zh-TW 区域设置支持对语音进行双语训练,使其能够讲中文和英语。 合成语音可以讲带有英语母语口音的英语,也可以讲与训练数据具有相同口音的英语,这在一定程度上取决于你的训练数据。
注意
若要在 zh-CN 区域设置中使语音能够以与样本数据相同的口音讲英语,则应在创建项目时选择 Chinese (Mandarin, Simplified), English bilingual,或通过 REST API 为训练集数据指定 zh-CN (English bilingual) 区域设置。
下表显示了区域设置之间的差异:
| Speech Studio 区域设置 | REST API 区域设置 | 双语支持 |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
如果你的样本数据包括英语,则无论英语数据的数量有多少,合成语音讲的英语都带有英语母语口音,而不是与样本数据相同的口音。 |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
如果你希望合成语音的英语口音与样本数据相同,我们建议你在训练集中包括 10% 以上的英语数据。 否则,英语口音可能不理想。 |
Chinese (Cantonese, Simplified) |
zh-HK |
如果你想训练能够用与你的样本数据相同的口音讲英语的合成语音,请确保在你的训练集中提供超过 10% 的英语数据。 否则,它默认为英语母语口音。 10% 这个阈值是根据成功上传后接受的数据计算的,而不是根据上传前的数据。 如果某些上传的英语数据由于缺陷而被拒绝,并且不满足 10% 这个阈值,则合成语音默认为英语母语口音。 |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
如果你想训练能够用与你的样本数据相同的口音讲英语的合成语音,请确保在你的训练集中提供超过 10% 的英语数据。 否则,它默认为英语母语口音。 10% 这个阈值是根据成功上传后接受的数据计算的,而不是根据上传前的数据。 如果某些上传的英语数据由于缺陷而被拒绝,并且不满足 10% 这个阈值,则合成语音默认为英语母语口音。 |
跨不同语言的可用预设样式
下表根据不同的语言汇总了不同的预设风格。
| 说话风格 | 语言(区域设置) |
|---|---|
| 生气 | 英语(美国)(en-US)日语(日本)( ja-JP) 1中文(普通话,简体)( zh-CN) 1 |
| 平静 | 中文(普通话,简体)(zh-CN) 1 |
| 聊天 | 中文(普通话,简体)(zh-CN) 1 |
| 开心 | 英语(美国)(en-US)日语(日本)( ja-JP) 1中文(普通话,简体)( zh-CN) 1 |
| 不满 | 中文(普通话,简体)(zh-CN) 1 |
| 兴奋 | 英语(美国)(en-US) |
| 害怕 | 中文(普通话,简体)(zh-CN) 1 |
| 友好 | 英语(美国)(en-US) |
| 乐观 | 英语(美国)(en-US) |
| 悲伤 | 英语(美国)(en-US)日语(日本)( ja-JP) 1中文(普通话,简体)( zh-CN) 1 |
| 大喊大叫 | 英语(美国)(en-US) |
| 严肃 | 中文(普通话,简体)(zh-CN) 1 |
| 害怕 | 英语(美国)(en-US) |
| 不友好 | 英语(美国)(en-US) |
| 窃窃私语 | 英语(美国)(en-US) |
1神经网络声音风格以公共预览版提供。 公共预览版中的声音风格只在美国东部、西欧和东南亚这三个服务区域提供。
获取训练状态
若要获取声音模型的训练状态,请使用定制声音 API 的 Models_Get 操作。 根据以下说明构造请求 URI:
使用 URI 提出 HTTP GET 请求,如以下 Models_Get 示例所示。
- 将
YourResourceKey替换为语音资源密钥。 - 将
YourResourceRegion替换为语音资源区域。 - 如果在上一步中指定了其他模型 ID,请替换
JessicaModelId。
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
你应该会收到以下格式的响应正文。
注意
方案 kind 和其他属性取决于你如何训练声音。 在此示例中,神经网络声音训练的方案类型为 Default。
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
可能需要等待几分钟才能完成训练。 最终,状态将更改为 Succeeded 或 Failed。