你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
繁忙数据库对立模式
将处理工作量卸载到数据库服务器可能会导致将绝大部分时间花费在运行代码上,而不是花费在响应存储和检索数据的请求上。
问题描述
许多数据库系统可以运行代码。 示例包括存储过程和触发器。 通常,更有效的做法是在靠近数据的位置执行这种处理,而不是将数据传输到客户端应用程序进行处理。 但是,过度使用这些功能可能会损害性能,原因有多种:
- 数据库服务器可能花费过多的时间用于处理,而不是接受新客户端请求和提取数据。
- 数据库通常是共享的资源,因此,在使用高峰期可能成为瓶颈。
- 如果要计量数据存储,运行时成本可能非常高昂。 托管数据库服务尤其如此。 例如,Azure SQL 数据库按照数据库事务单位 (DTU) 计费。
- 数据库的纵向扩展容量有限,而横向扩展数据库却不是一个简单的过程。 因此,有时最好是将处理工作量转移到可轻松横向扩展的计算资源,例如 VM 或应用服务应用。
出现此反模式的原因通常是:
- 将服务器视为服务而不是存储库。 应用程序可能使用了数据库服务器来设置数据的格式(例如,转换为 XML)、处理字符串数据或执行复杂计算。
- 开发人员尝试编写可直接向用户显示其结果的查询。 例如,某个查询可能合并了字段,或根据区域设置使用日期、时间和货币的格式。
- 开发人员正在尝试通过将计算推送到数据库来更正过量提取对立模式。
- 使用了存储过程来封装业务逻辑,原因也许是开发人员认为存储过程更容易维护和更新。
以下示例检索指定销售区域的 20 份最有价值的订单,并将结果设置为 XML 格式。 它使用 Transact-SQL 函数来分析数据,并将结果转换为 XML。 可在此处找到完整示例。
SELECT TOP 20
soh.[SalesOrderNumber] AS '@OrderNumber',
soh.[Status] AS '@Status',
soh.[ShipDate] AS '@ShipDate',
YEAR(soh.[OrderDate]) AS '@OrderDateYear',
MONTH(soh.[OrderDate]) AS '@OrderDateMonth',
soh.[DueDate] AS '@DueDate',
FORMAT(ROUND(soh.[SubTotal],2),'C')
AS '@SubTotal',
FORMAT(ROUND(soh.[TaxAmt],2),'C')
AS '@TaxAmt',
FORMAT(ROUND(soh.[TotalDue],2),'C')
AS '@TotalDue',
CASE WHEN soh.[TotalDue] > 5000 THEN 'Y' ELSE 'N' END
AS '@ReviewRequired',
(
SELECT
c.[AccountNumber] AS '@AccountNumber',
UPPER(LTRIM(RTRIM(REPLACE(
CONCAT( p.[Title], ' ', p.[FirstName], ' ', p.[MiddleName], ' ', p.[LastName], ' ', p.[Suffix]),
' ', ' ')))) AS '@FullName'
FROM [Sales].[Customer] c
INNER JOIN [Person].[Person] p
ON c.[PersonID] = p.[BusinessEntityID]
WHERE c.[CustomerID] = soh.[CustomerID]
FOR XML PATH ('Customer'), TYPE
),
(
SELECT
sod.[OrderQty] AS '@Quantity',
FORMAT(sod.[UnitPrice],'C')
AS '@UnitPrice',
FORMAT(ROUND(sod.[LineTotal],2),'C')
AS '@LineTotal',
sod.[ProductID] AS '@ProductId',
CASE WHEN (sod.[ProductID] >= 710) AND (sod.[ProductID] <= 720) AND (sod.[OrderQty] >= 5) THEN 'Y' ELSE 'N' END
AS '@InventoryCheckRequired'
FROM [Sales].[SalesOrderDetail] sod
WHERE sod.[SalesOrderID] = soh.[SalesOrderID]
ORDER BY sod.[SalesOrderDetailID]
FOR XML PATH ('LineItem'), TYPE, ROOT('OrderLineItems')
)
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC
FOR XML PATH ('Order'), ROOT('Orders')
显然,此查询非常复杂。 稍后我们会看到,它使用了数据库服务器上的大量处理资源。
如何解决问题
将处理工作从数据库服务器转移到其他应用程序层。 理想情况下,应该将数据库限制为执行数据访问操作,并只使用针对数据库优化的功能,例如 RDBMS 中的聚合。
例如,可将前面的 Transact-SQL 代码替换为一个只是检索待处理数据的语句。
SELECT
soh.[SalesOrderNumber] AS [OrderNumber],
soh.[Status] AS [Status],
soh.[OrderDate] AS [OrderDate],
soh.[DueDate] AS [DueDate],
soh.[ShipDate] AS [ShipDate],
soh.[SubTotal] AS [SubTotal],
soh.[TaxAmt] AS [TaxAmt],
soh.[TotalDue] AS [TotalDue],
c.[AccountNumber] AS [AccountNumber],
p.[Title] AS [CustomerTitle],
p.[FirstName] AS [CustomerFirstName],
p.[MiddleName] AS [CustomerMiddleName],
p.[LastName] AS [CustomerLastName],
p.[Suffix] AS [CustomerSuffix],
sod.[OrderQty] AS [Quantity],
sod.[UnitPrice] AS [UnitPrice],
sod.[LineTotal] AS [LineTotal],
sod.[ProductID] AS [ProductId]
FROM [Sales].[SalesOrderHeader] soh
INNER JOIN [Sales].[Customer] c ON soh.[CustomerID] = c.[CustomerID]
INNER JOIN [Person].[Person] p ON c.[PersonID] = p.[BusinessEntityID]
INNER JOIN [Sales].[SalesOrderDetail] sod ON soh.[SalesOrderID] = sod.[SalesOrderID]
WHERE soh.[TerritoryId] = @TerritoryId
AND soh.[SalesOrderId] IN (
SELECT TOP 20 SalesOrderId
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC)
ORDER BY soh.[TotalDue] DESC, sod.[SalesOrderDetailID]
然后,应用程序使用 .NET Framework System.Xml.Linq API 将结果设置为 XML 格式。
// Create a new SqlCommand to run the Transact-SQL query
using (var command = new SqlCommand(...))
{
command.Parameters.AddWithValue("@TerritoryId", id);
// Run the query and create the initial XML document
using (var reader = await command.ExecuteReaderAsync())
{
var lastOrderNumber = string.Empty;
var doc = new XDocument();
var orders = new XElement("Orders");
doc.Add(orders);
XElement lineItems = null;
// Fetch each row in turn, format the results as XML, and add them to the XML document
while (await reader.ReadAsync())
{
var orderNumber = reader["OrderNumber"].ToString();
if (orderNumber != lastOrderNumber)
{
lastOrderNumber = orderNumber;
var order = new XElement("Order");
orders.Add(order);
var customer = new XElement("Customer");
lineItems = new XElement("OrderLineItems");
order.Add(customer, lineItems);
var orderDate = (DateTime)reader["OrderDate"];
var totalDue = (Decimal)reader["TotalDue"];
var reviewRequired = totalDue > 5000 ? 'Y' : 'N';
order.Add(
new XAttribute("OrderNumber", orderNumber),
new XAttribute("Status", reader["Status"]),
new XAttribute("ShipDate", reader["ShipDate"]),
... // More attributes, not shown.
var fullName = string.Join(" ",
reader["CustomerTitle"],
reader["CustomerFirstName"],
reader["CustomerMiddleName"],
reader["CustomerLastName"],
reader["CustomerSuffix"]
)
.Replace(" ", " ") //remove double spaces
.Trim()
.ToUpper();
customer.Add(
new XAttribute("AccountNumber", reader["AccountNumber"]),
new XAttribute("FullName", fullName));
}
var productId = (int)reader["ProductID"];
var quantity = (short)reader["Quantity"];
var inventoryCheckRequired = (productId >= 710 && productId <= 720 && quantity >= 5) ? 'Y' : 'N';
lineItems.Add(
new XElement("LineItem",
new XAttribute("Quantity", quantity),
new XAttribute("UnitPrice", ((Decimal)reader["UnitPrice"]).ToString("C")),
new XAttribute("LineTotal", RoundAndFormat(reader["LineTotal"])),
new XAttribute("ProductId", productId),
new XAttribute("InventoryCheckRequired", inventoryCheckRequired)
));
}
// Match the exact formatting of the XML returned from SQL
var xml = doc
.ToString(SaveOptions.DisableFormatting)
.Replace(" />", "/>");
}
}
注意
此代码有点复杂。 对于新应用程序,有时最好是使用序列化库。 但是,此处的假设是开发团队正在重构现有的应用程序,因此,该方法需要返回与原始代码完全相同的格式。
注意事项
许多数据库系统经过高度优化,可执行特定类型的数据处理,例如,基于大型数据集计算聚合值。 请不要将这些类型的处理移出数据库。
如果重定位处理会导致数据库通过网络传输多得多的数据,请不要这样做。 请参阅超量提取对立模式。
如果将处理工作转移到应用程序层,该层可能需要横向扩展以处理额外的工作。
如何检测问题
繁忙数据库的症状包括,在访问数据库的操作中,吞吐量和响应时间不成比例下降。
可执行以下步骤来帮助识别此问题:
使用性能监视来识别生产系统花费了多少时间执行数据库活动。
检查在这些时段内数据库执行的工作。
如果怀疑特定的操作导致数据库活动过多,请在受控环境中执行负载测试。 每项测试应该在施加可变用户负载的情况下,混合运行可疑的操作。 检查负载测试返回的遥测数据,以观察数据库的使用方式。
如果数据库活动表现为处理量极大,但数据流量很小,请检查源代码,确定是否在其他位置执行处理可能会更好。
如果数据库活动量较低或响应时间相对较快,则性能问题不太可能是繁忙的数据库造成的。
示例诊断
以下部分将这些步骤应用到前面所述的示例应用程序。
监视数据库活动量
下图显示了使用包含多达 50 个并发用户的阶跃负载,对示例应用程序运行的负载测试的结果。 请求数量很快达到限制并保持该水平,同时,平均响应时间稳步增加。 这两个指标使用了对数刻度。
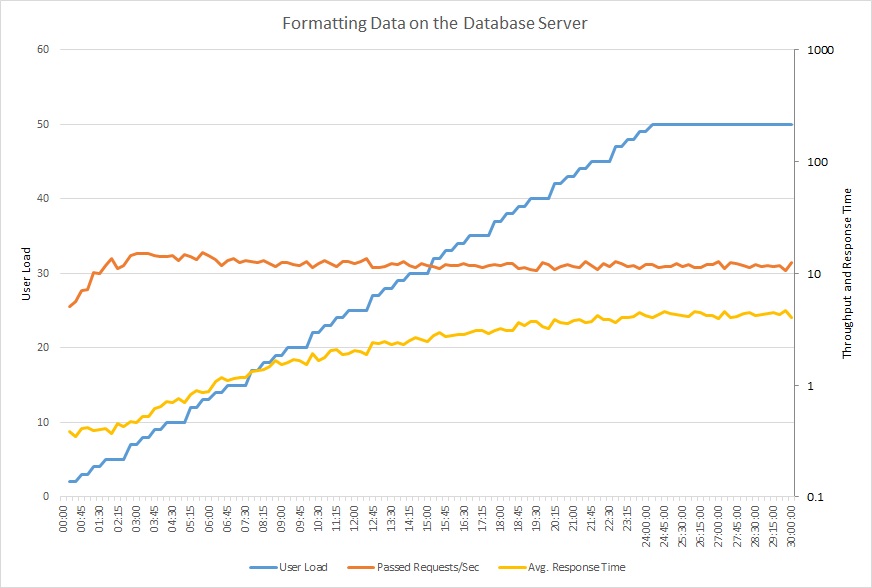
此折线图显示用户负载、每秒请求数和平均响应时间。 此图显示响应时间随负载增加而增加。
下图以服务配额百分比的形式显示了 CPU 利用率和 DTU。 DTU 度量数据库执行的处理工作量。 该图显示 CPU 和 DTU 利用率都很快达到 100%。
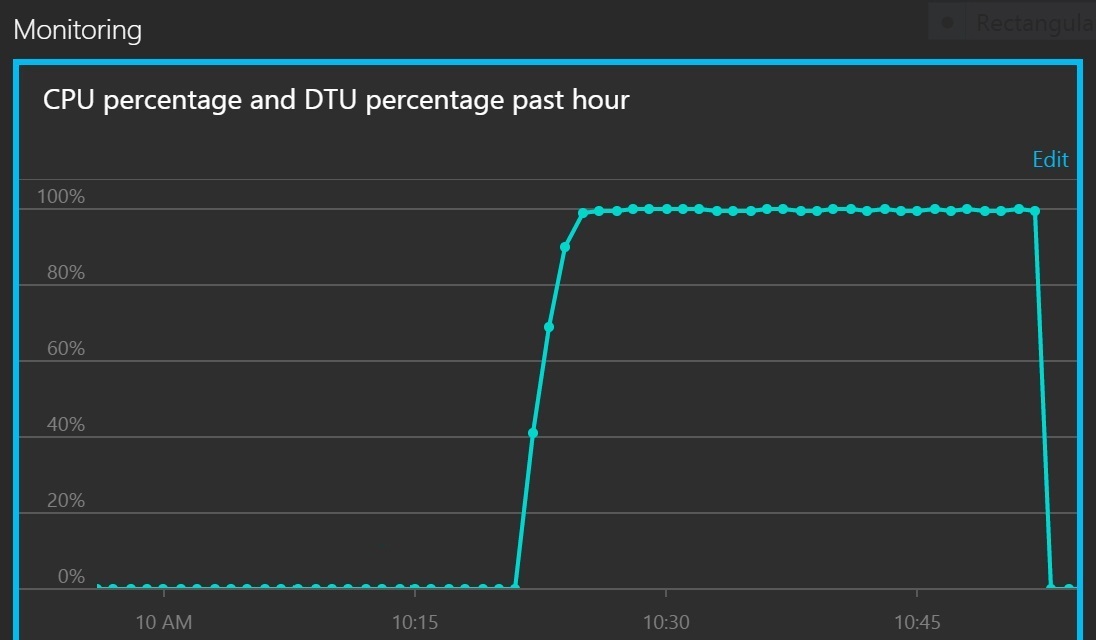
此折线图显示一段时间内的 CPU 百分比和 DTU 百分比。 此图显示二者很快达到 100%。
检查数据库执行的工作
有可能数据库执行的任务是真正的数据访问操作而不是处理,因此,必须了解数据库繁忙时运行的 SQL 语句。 监视系统,以捕获 SQL 流量并将 SQL 操作与应用程序请求相关联。
如果数据库操作是单纯的数据访问操作且没有执行大量的处理,则问题可能在于超量提取。
实施解决方案并验证结果
下图显示了使用更新的代码执行的负载测试。 吞吐量明显提高,每秒超过了 400 个请求,而前次测试中为 12 个。 平均响应时间也大大降低,略微超过 0.1 秒,而前次测试中为 4 秒。
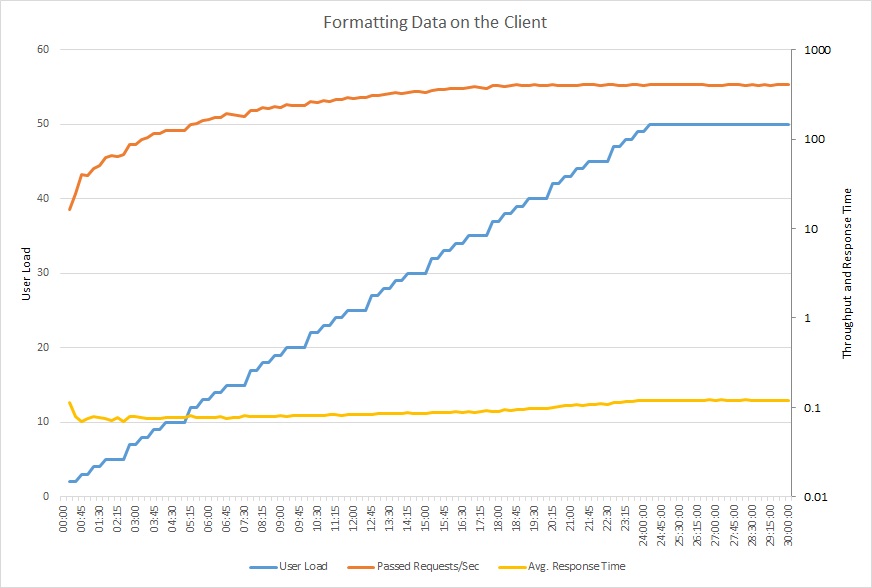
此折线图显示用户负载、每秒请求数和平均响应时间。 此图显示响应时间在整个负载测试期间大致保持不变。
CPU 和 DTU 利用率显示,尽管吞吐量已提高,但系统花费了较长的时间才达到饱和。
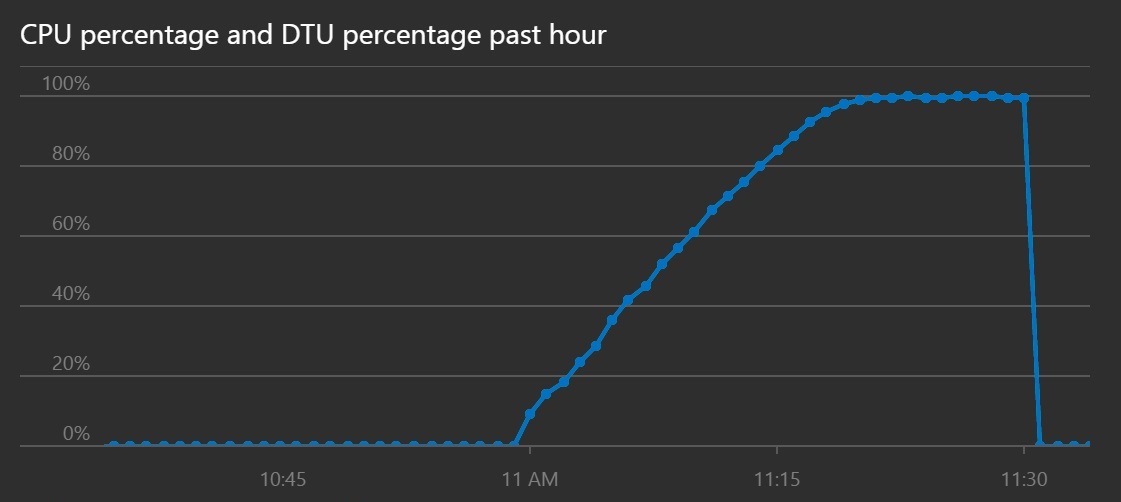
此折线图显示一段时间内的 CPU 百分比和 DTU 百分比。 此图显示 CPU 和 DTU 达到 100% 的时间比以前要长。
相关资源
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈