本文中所述的体系结构演示了如何将 Teradata VantageCloud Enterprise 与 Azure 数据工厂结合使用,以低代码或无代码方法开发数据集成管道。 它演示如何使用数据工厂通过增强的安全连接快速引入或提取 Vantage 数据。
Apache®、Hadoop 和火焰徽标是 Apache Software Foundation 在美国和/或其他国家/地区的商标或注册商标。 使用这些标记并不暗示获得 Apache Software Foundation 的认可。
体系结构
下图演示了使用虚拟网络对等互连的体系结构的一个版本。 它使用自承载集成运行时 (IR) 连接到分析数据库。 Teradata 的 VM 仅通过专用 IP 地址部署。

下载此体系结构的 Visio 文件。
下图演示了使用 Azure 专用链接连接的体系结构的一个版本。

下载此体系结构的 Visio 文件。
Azure 上的 VantageCloud Enterprise 是一项完全托管的服务,部署在 Teradata 拥有的 Azure 订阅中。 在自己的 Azure 订阅中部署云服务,然后通过其中一个批准的连接选项连接到 Teradata 托管订阅。 Teradata 支持你的 Azure 订阅与 Azure 上的 VantageCloud Enterprise 之间的以下连接类型:
- 虚拟网络对等互连
- 专用链接
- Azure 虚拟 WAN
如果计划使用虚拟网络对等互连,请与 Teradata 支持人员或 Teradata 帐户团队协作,确保所需的安全组设置已到位,以便通过虚拟网络对等互连链接启动从自承载 IR 到数据库的流量。
组件
要实现此体系结构,需要熟悉数据工厂、Azure Blob 存储、Teradata VantageCloud Enterprise 和 Teradata 工具和实用工具 (TTU)。
这些组件和版本用于集成方案:
- Azure 上托管的 Teradata VantageCloud Enterprise 17.20
- Azure 数据工厂
- Azure Blob 存储
- TTU 17.20
- Teradata ODBC 驱动程序 17.20.12
- Teradata Studio 17.20
Teradata Vantage
Vantage 提供 Teradata 所谓的“普适性数据智能”。 组织中的用户可以使用它来获取其问题的实时智能解答。 在此体系结构中,Azure 上的 Vantage 用作数据集成任务的源或目标。 Vantage 本机对象存储 (NOS) 用于与 Blob 存储中的数据集成。
数据工厂
数据工厂是一种无服务器云提取、转换、加载 (ETL) 服务。 可将其用于协调和自动化数据移动和转换。 它提供无代码用户界面,用于数据引入和直观创作,并提供单一视图的监视和管理。
可以使用数据工厂创建和计划数据驱动型工作流(称为管道),以便从各种数据存储引入数据。 可以使用在 Spark 或计算服务(如 Azure Batch、Azure 机器学习、Apache Spark、SQL、Azure HDInsight with Hadoop 和 Azure Databricks)上运行的数据流创建以直观方式转换数据的复杂 ETL 进程。 使用数据工厂涉及以下层,按最抽象到最接近数据的软件列出。
- 管道是包含活动和数据路径的图形接口。
- 活动对数据执行操作。
- 源和接收器是指定数据来源和去向的活动。
- 数据集是数据工厂引入、加载和转换的定义明确的数据集。
- 链接服务使数据工厂能够访问特定外部数据源的连接信息。
- 集成运行时 (IR) 提供数据工厂与数据或计算资源之间的网关。
自承载 IR
自承载 IR 可以在云数据存储和专用网络数据存储之间执行复制操作。 也可以在本地网络或 Azure 虚拟网络中转换你的计算资源。 需要专用网络上的本地计算机或虚拟机才能安装自承载 IR。 有关详细信息,请参阅使用自承载 IR 的注意事项。 本文介绍如何使用自承载 IR 连接到 VantageCloud 并提取数据以载入 Azure Data Lake Storage。
Teradata 连接器
在此体系结构中,数据工厂使用 Teradata 连接器连接到 Vantage。 Teradata 连接器支持:
- Teradata 版本 14.10、15.0、15.10、16.0、16.10、16.20。
- 使用“基本”、“Windows”或“LDAP”身份验证复制数据。
- 从 Teradata 源进行并行复制。 有关详细信息,请参阅从 Teradata 并行复制。
本文介绍如何为数据工厂复制数据活动设置链接服务和数据集,该活动从 Vantage 引入数据并将其载入 Data Lake Storage。
方案详细信息
本文介绍了三个方案:
- 数据工厂从 VantageCloud Enterprise 拉取数据并将其载入 Blob 存储
- 数据工厂将数据从 Blob 存储载入 VantageCloud Enterprise
- 使用 Vantage NOS 功能访问由数据工厂转换并载入 Blob 存储的数据
方案 1:将数据从 VantageCloud 载入 Blob 存储
此方案介绍如何使用数据工厂从 VantageCloud Enterprise 中提取数据、执行一些基本转换,然后将数据载入 Blob 存储容器。
此方案重点介绍了数据工厂和 Vantage 之间的原生集成,以及构建企业 ETL 管道以在 Vantage 中集成数据的简单方法。
要完成此过程,需要在订阅中具有 Blob 存储容器,如体系结构关系图所示。
要创建到 Vantage 的原生连接器,请在数据工厂中选择“管理”选项卡,选择“链接服务”,然后选择“新建”:

搜索 Teradata 然后选择 Teradata 连接器。 然后选择“继续”:

配置链接服务以连接到 Vantage 数据库。 此过程演示如何通过用户 ID 和密码使用基本身份验证机制。 或者,根据你的安全需求,可以选择不同的身份验证机制并相应地设置其他参数。 有关详细信息,请参阅 Teradata 连接器链接服务属性。 你将使用自承载 IR。 有关详细信息,请参阅部署自承载 IR 的说明。 将其部署在你的数据工厂所在的虚拟网络中。
使用以下值配置链接服务:
- 名称:输入链接服务连接的名称。
- 通过集成运行时连接:选择 SelfHostedIR。
- 服务器名称:
- 如果通过虚拟网络对等互连进行连接,请在 Teradata 群集中提供 VM 的 IP 地址。 可以连接到群集中任何 VM 的 IP 地址。
- 如果要通过专用链接进行连接,请提供在虚拟网络中创建的专用终结点的 IP 地址,以通过专用链接连接到 Teradata 群集。
- 身份验证类型:选择身份验证类型。 此过程显示如何使用基本身份验证。
- 用户名和密码:提供凭据。
- 选择测试连接,然后选择创建。 请确保为 IR 启用交互式创作,以便测试连接功能正常工作。

对于测试,可以在 Vantage 中使用名为
NYCTaxiADFIntegration的测试数据库。 此数据库有一个名为Green_Taxi_Trip_Data的单一表。 从 NYC OpenData 下载该数据库。 以下 CREATE TABLE 语句可帮助你了解该表的架构。CREATE MULTISET TABLE NYCTaxiADFIntegration.Green_Taxi_Trip_Data, FALLBACK , NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO, MAP = TD_MAP1 ( VendorID BYTEINT, lpep_pickup_datetime DATE FORMAT ‘YY/MM/DD’, lpep_dropoff_datetime DATE FORMAT ‘YY/MM/DD’, store_and_fwd_flag VARCHAR(1) CHARACTER SET LATIN CASESPECIFIC, RatecodeID BYTEINT, PULocationID SMALLINT, DOLocationID SMALLINT, passenger_count BYTEINT, trip_distance FLOAT, fare_amount FLOAT, extra DECIMAL(18,16), mta_tax DECIMAL(4,2), tip_amount FLOAT, tolls_amount DECIMAL(18,16), ehail_fee BYTEINT, improvement_surcharge DECIMAL(3,1), total_amount DECIMAL(21,17), payment_type BYTEINT, trip_type BYTEINT, congestion_surcharge DECIMAL(4,2)) NO PRIMARY INDEX ;接下来,创建一个简单的管道以从表复制数据,执行一些基本转换,然后将数据载入 Blob 存储容器。 如此过程开始时所述,你应该已在订阅中创建了 Blob 存储容器。 首先,创建一个链接服务以连接到容器,容器是将数据复制到其中的接收器。
在数据工厂中选择“管理”选项卡,选择“链接服务”,然后选择“新建”:

搜索 Azure Blob,选择 Azure Blob 存储连接器,然后选择“继续”:

配置链接服务以连接到 Blob 存储帐户:
- 名称:输入链接服务连接的名称。
- 通过集成运行时连接:选择 AutoResolveIntegrationRuntime。
- 身份验证类型:选择“账户密钥”。
- Azure 订阅:输入 Azure 订阅 ID。
- 存储帐户名称:输入 Azure 存储帐户名。
选择“测试连接”以验证连接,然后选择“创建”。

创建数据工厂管道:
- 选择“创作”选项卡。
- 选择 + 按钮。
- 选择管道。
- 输入管道的名称。

创建两个数据集:
- 选择“创作”选项卡。
- 选择 + 按钮。
- 选择数据集。
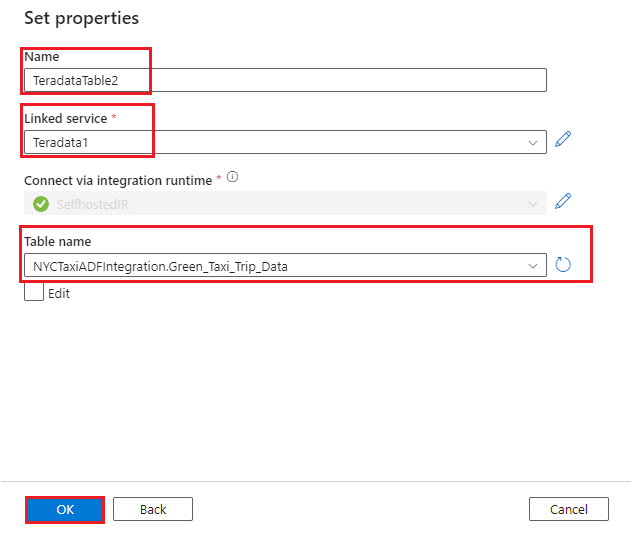
- 为
Green_Taxi_Trip_DataTeradata 表创建数据集:
- 选择“Teradata”作为“数据存储”。
- 名称:输入数据集的名称。
- 链接服务:选择在步骤 2 和步骤 3 中为 Teradata 创建的链接服务。
- 表名:从列表中选择表。
- 选择确定。
- 创建 Azure Blob 数据集:
- 选择“Azure Blob”作为“数据存储”。
- 选择数据的格式。 本演示使用了 Parquet。
- 链接服务:选择在步骤 6 中创建的链接服务。
- 文件路径:输入 Blob 文件的文件路径。
- 导入架构:选择“无”。
- 选择确定。

将“复制数据”活动拖到管道上。
注意
Teradata 连接器当前不支持数据工厂中的数据流活动。 如果要对数据执行转换,建议在复制活动后添加数据流活动。
配置复制数据活动:
在“源”选项卡上的“源数据集”下,选择在上一步中创建的 Teradata 表数据集。
对于“使用查询”,选择“表”。
对其他选项使用默认值。

在“接收器”选项卡上的“接收器数据集”下,选择在上一步中创建的 Azure Blob 数据集。
对其他选项使用默认值。

选择调试。 管道会将数据从 Teradata 表复制到 Blob 存储中的 Parquet 文件。











方案 2:将数据从 Blob 存储载入 VantageCloud
此方案介绍如何使用 ODBC 连接器通过自承载 IR VM 连接到 Vantage 以加载数据。 由于 IR 需要使用 Teradata ODBC 驱动程序进行安装和配置,因此此选项仅适用于数据工厂自承载 IR。
还可以使用 TTU、数据工厂自定义活动和 Azure Batch 将数据加载到 Vantage 中并对其进行转换。 有关详细信息,请参阅使用自定义活动功能将 Teradata Vantage 连接到 Azure 数据工厂。 建议评估这两个选项的性能、成本和管理注意事项,并选择最适合你的要求的选项。
首先准备在上一方案中创建的自承载 IR。 需要在其上安装 Teradata ODBC 驱动程序。 此方案将 Windows 11 VM 用于自承载 IR。
- 使用 RDP 连接到 VM。
- 下载并安装 Teradata ODBC 驱动程序。
- 如果 VM 上还没有 JAVA JRE,请下载并安装它。
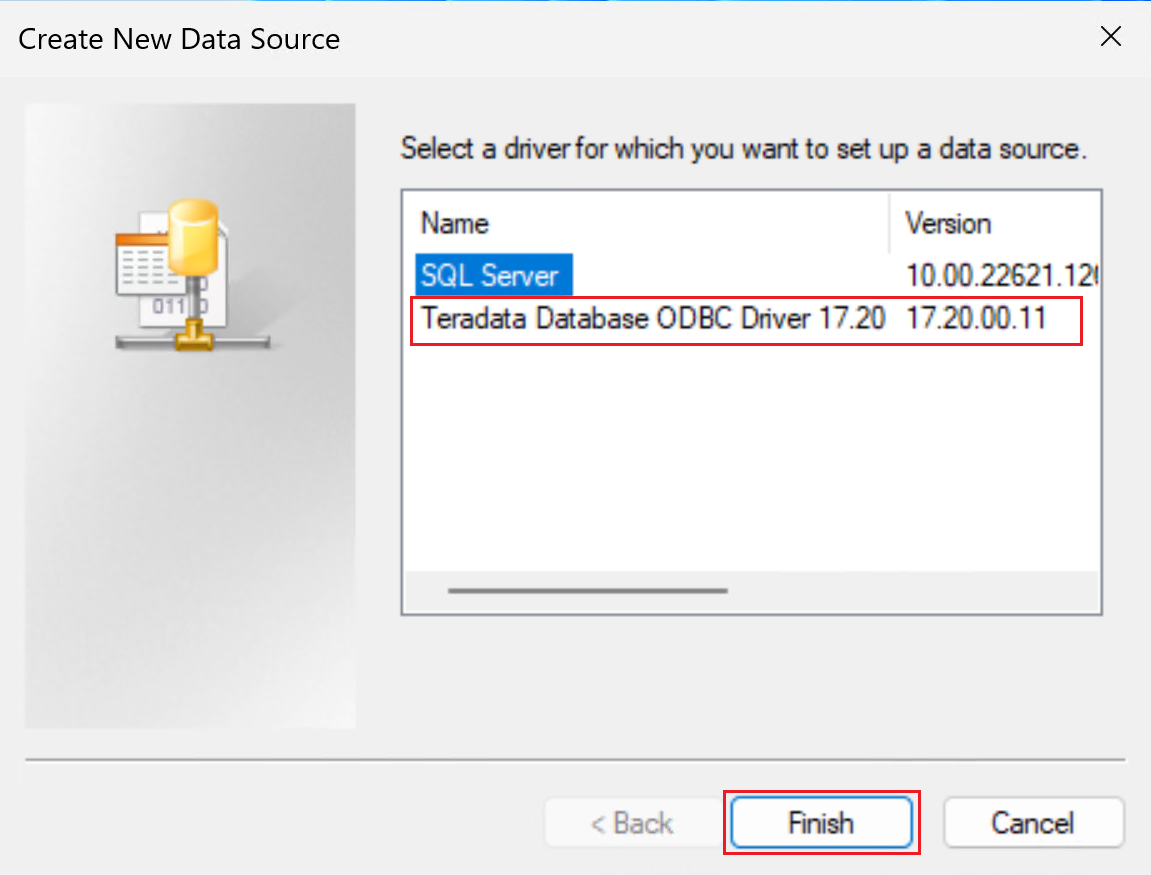
通过添加 ODBC 数据源,为 Teradata 数据库创建 64 位系统 DSN。
请务必使用 64 位 DSN 窗口。
选择 Teradata 数据库 ODBC 驱动程序,如以下屏幕截图所示。
选择“完成”以打开驱动程序设置窗口。
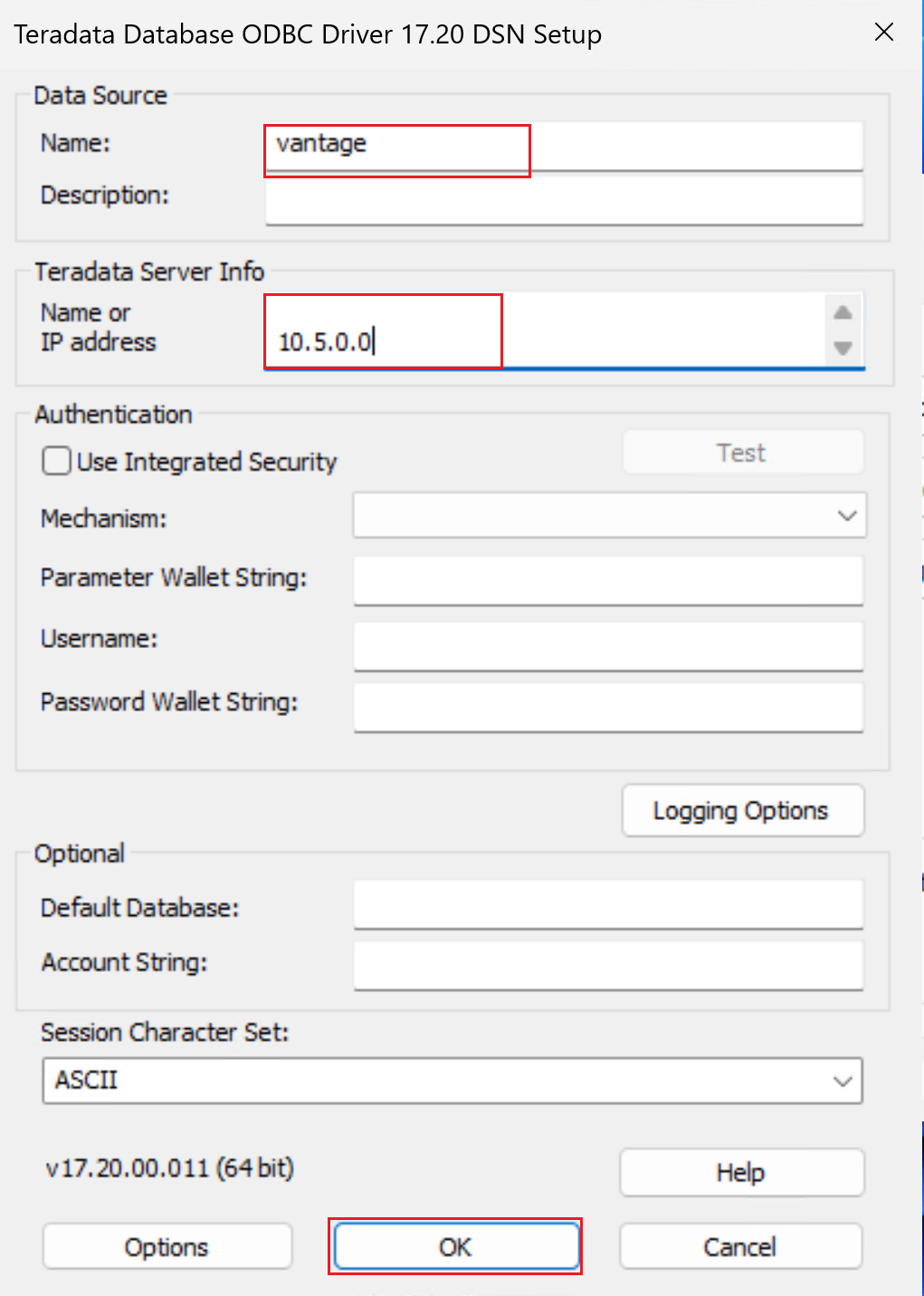
配置 DSN 属性。
名称:输入 DSN 的名称。
在“Teradata 服务器信息”下,在“名称或 IP 地址”中:
- 如果通过虚拟网络对等互连进行连接,请在 Teradata 群集中提供 VM 的 IP 地址。 可以连接到群集中任何 VM 的 IP 地址。
- 如果要通过专用链接进行连接,请提供在虚拟网络中创建的专用终结点的 IP 地址,以通过专用链接连接到 Teradata 群集。
(可选)提供“用户名”并选择“测试”。 系统会提示输入凭据。 选择“确定”,并确保连接成功。 请注意,创建用于从数据工厂连接到 Teradata 数据库的 ODBC 链接服务时,你将在数据工厂中提供用户名和密码。
将其他字段留空。
选择确定。
ODBC 数据源管理员窗口将类似于以下屏幕截图中所示。 选择应用。 现在可以关闭窗口。 你的自承载 IR 现已准备好使用 ODBC 连接到 Vantage。

在数据工厂中,创建链接服务连接。 选择 ODBC 作为数据存储:

使用前面步骤中配置的 IR 配置链接服务:
名称:为链接服务提供一个名称。
通过集成运行时连接:选择 SelfhostedIR。
连接字符串:输入 DSN 连接字符串,其中包含在前面步骤中创建的 DSN 的名称。
身份验证类型:选择“基本”。
输入 Teradata ODBC 连接的用户名和密码。
选择测试连接,然后选择创建。

完成以下步骤以使用 ODBC 创建数据集作为数据存储。 使用之前创建的链接服务。
- 选择“创作”选项卡。
- 选择 + 按钮。
- 选择数据集。
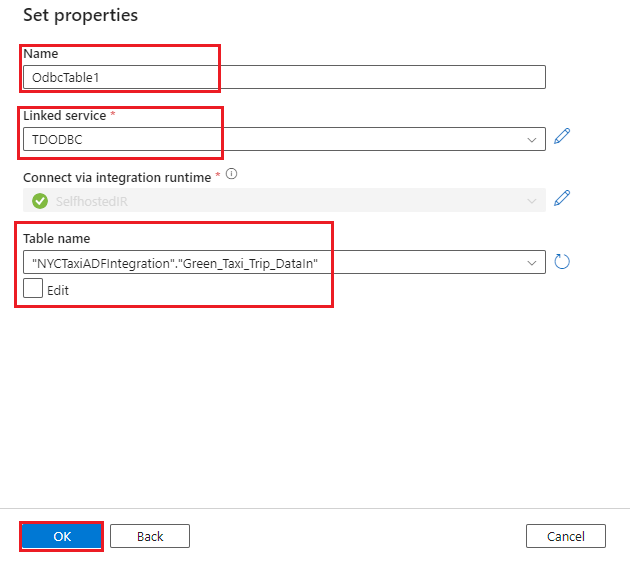
- 为
Green_Taxi_Trip_DataInTeradata 表创建数据集:
- 选择“ODBC”作为数据存储,然后选择“继续”。
- 名称:提供数据集的名称。
- 链接服务:选择在前面的步骤中创建的 ODBC 链接服务。
- 表名:从列表中选择表。
- 选择确定。
提示
加载数据时,使用具有泛型数据类型的临时表,以避免数据类型不匹配错误。 例如,对列使用 Varchar 数据类型,而不是 Decimal。 然后,可以在 Vantage 数据库中执行数据类型转换。
按照第一个方案中的步骤 4 到 6 和步骤 8 创建与要载入 Vantage 的源文件的 Azure Blob 连接。 请注意,你要为源文件创建此连接,所以文件的路径会有所不同。
创建包含复制数据活动的管道,如方案 1 中所述。
将“复制数据”活动拖到管道上。
注意
Teradata ODBC 连接器当前不支持数据工厂中的数据流活动。 如果要对数据执行转换,建议在“复制数据”活动之前创建数据流活动。
配置复制数据活动:
在“源”选项卡上,选择要载入 Teradata 的文件数据集。
对其他选项使用默认值。

在“接收器”选项卡上的“接收器数据集”下,选择通过 ODBC 连接创建的 Teradata 表数据集。
对其他选项使用默认值。

选择调试。 管道将数据从 Parquet 文件复制到 Vantage。







方案 3:从 VantageCloud 访问 Blob 存储中的数据
此方案介绍如何使用 Vantage 本机对象存储 (NOS) 功能访问 Blob 存储中的数据。 如果想要将数据连续或有计划地载入 Vantage,前面的方案是理想方案。 此方案介绍如何一次性从 Blob 存储访问数据,无论是否将数据加载到 Vantage 中。
注意
还可以使用 NOS 将数据导出到 Blob 存储。
可以使用以下查询从 Vantage 读取通过数据工厂转换并载入 Blob 存储的数据,而无需将数据载入 Vantage。 可以使用 Teradata SQL 编辑器来运行查询。 要访问 Blob 中的数据,请在
Access_ID和Access_Key字段中提供存储帐户名称和访问密钥。 查询还会返回一个名为Location的字段,它指定从中读取记录的文件的路径。FROM ( LOCATION='/AZ/yourstorageaccount.blob.core.windows.net/vantageadfdatain/NYCGreenTaxi/' AUTHORIZATION='{"ACCESS_ID":"yourstorageaccountname","ACCESS_KEY":"yourstorageaccesskey"}' ) as GreenTaxiData;
下面是就地查询数据的另一个示例。 它使用
READ_NOS表运算符。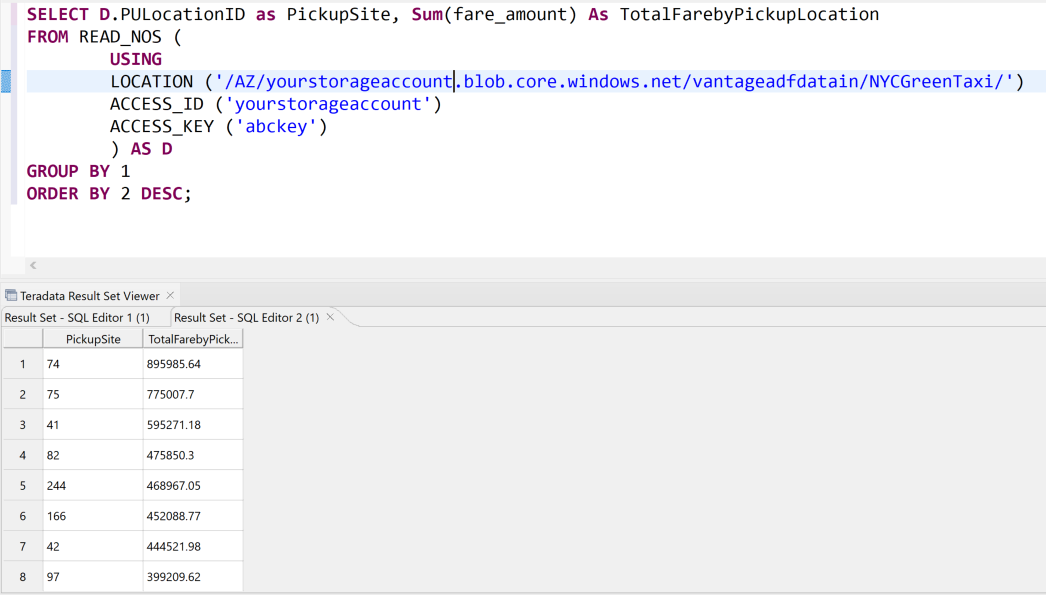
还可以通过在对象存储中创建外表来就地查询数据或将数据载入 Vantage 数据库。 首先需要创建一个授权对象,它分别在
USER和PASSWORD字段中使用存储帐户名和访问密钥,如以下语法所示。 可以使用此对象创建外表,以便在创建表时无需提供键。USER 'YOUR-STORAGE-ACCOUNT-NAME' PASSWORD 'YOUR-ACCESS-KEY';现在可以创建外表来访问数据。 以下查询为绿色出租车数据创建表。 它使用授权对象。
注意
加载 Parquet 文件时,请确保正确映射数据类型。 有关匹配数据类型的帮助,可以使用 READ_NOS 命令预览 Parquet 架构。
Create Foreign Table NYCTaxiADFIntegration.GreenTaxiForeignTable , External security definer trusted DefAuth3 ( VendorID INT, lpep_pickup_datetime TIMESTAMP, lpep_dropoff_datetime TIMESTAMP, store_and_fwd_flag VARCHAR(40) CHARACTER SET UNICODE CASESPECIFIC, RatecodeID INT, PULocationID INT, DOLocationID INT, passenger_count INT, trip_distance FLOAT, fare_amount FLOAT, extra DECIMAL(38,18), mta_tax DECIMAL(38,18), tip_amount FLOAT, tolls_amount DECIMAL(38,18), ehail_fee INT, improvement_surcharge DECIMAL(38,18), total_amount DECIMAL(38,18), payment_type INT, trip_type INT, congestion_surcharge DECIMAL(38,18) ) USING ( LOCATION('/AZ/adfvantagestorageaccount.blob.core.windows.net/vantageadfdatain/NYCGreenTaxi') STOREDAS ('PARQUET')) NO PRIMARY INDEX , PARTITION BY COLUMN;现在可以从外表查询数据,就像查询任何其他表一样:

你已了解如何就地查询对象存储中的数据。 但是,你可能需要将数据永久载入数据库中的表,以提高查询性能。 可以使用以下语句将数据从 Blob 存储载入永久表。 某些选项可能仅适用于某些数据文件格式。 有关详细信息,请参阅 Teradata 文档。 有关示例代码,请参阅将外部数据载入数据库。
方法 说明 CREATE TABLE AS...WITH DATA 访问现有外表的表定义和数据,并在数据库中创建新的永久表 CREATE TABLE AS...FROM READ_NOS 直接从对象存储访问数据并在数据库中创建永久表 INSERT SELECT 将外部数据中的值存储在持久性数据库表中 以下示例演示如何从
GreenTaxiData创建永久表:CREATE Multiset table NYCTaxiADFIntegration.GreenTaxiNosPermanent As ( SELECT D.PULocationID as PickupSite, Sum(fare_amount) AS TotalFarebyPickuploation FROM NYCTaxiADFIntegration.GreenTaxiForeignTable AS D GROUP BY 1 ) with Data No Primary Index;INSERT INTO NYCTaxiADFIntegration.GreenTaxiNosPermanent SELECT D.PULocationID as PickupSite, Sum(fare_amount) AS TotalFarebyPickuploation FROM NYCTaxiADFIntegration.GreenTaxiForeignTable AS D GROUP BY 1;



最佳做法
- 遵循 Teradata 作为源中所述的连接器性能提示和最佳做法。
- 确保为你的数据量正确调整自承载 IR 的大小。 可能需要横向扩展 IR 以获得更好的性能。 有关详细信息,请参阅此自承载 IR 性能指南。
- 使用复制活动性能和可伸缩性指南微调数据工厂管道,以提高性能。
- 使用数据工厂复制数据工具快速设置管道并按计划运行它。
- 请考虑使用具有自承载 IR 的 Azure VM 来管理运行管道的成本。 如果想要每天运行管道两次,可以启动 VM 两次,然后将其关闭。
- 考虑在数据工厂中使用 CI/CD 来实现已启用 Git 的持续集成和开发做法。
- 优化管道活动计数。 不必要的活动会增加成本,并使管道变得复杂。
- 考虑使用映射数据流通过无代码和低代码流程直观地转换 Blob 存储数据,准备 Vantage 数据以用于 Power BI 报表等用途。
- 除了使用计划触发器外,还可以考虑混合使用翻转窗口和事件触发器将 Vantage 数据载入目标位置。 减少不必要的触发器以降低成本。
- 使用 Vantage NOS 进行即席查询,轻松为上游应用程序提供数据。
作者
本文由 Microsoft 维护, 它最初是由以下贡献者撰写的。
主要作者:
- Sunil Sabat | 首席项目经理
- Divyesh Sah | 全球云体系结构总监
- Jianlei Shen | 高级项目经理
其他参与者:
- Mick Alberts | 技术文档撰写人
- Emily Chen | 首席项目经理
- Wee Hyong Tok | 合作伙伴项目管理总监
- Bunty Ranu | 全球云体系结构高级总监
要查看非公开领英个人资料,请登录领英。
后续步骤
- Azure 上的 Teradata Vantage
- Teradata 工具和实用工具 17.20
- 数据工厂
- Azure 虚拟网络对等互连
- 专用链接服务
- 数据工厂 Teradata 连接器
- 自承载 IR
- Blob 存储文档