你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
排查 Azure Databricks 中的性能瓶颈问题
注意
本文依赖于 GitHub 上托管的开放源代码库:https://github.com/mspnp/spark-monitoring。
原始库支持 Azure Databricks Runtimes 10.x (Spark 3.2.x) 和更低版本。
Databricks 在 l4jv2 分支(参见 https://github.com/mspnp/spark-monitoring/tree/l4jv2)上贡献了一个更新版本来支持 Azure Databricks Runtimes 11.0 (Spark 3.3.x) 及更高版本。
请注意,由于 Databricks Runtimes 中使用的日志记录系统不同,11.0 版本不向后兼容。 请确保为 Databricks Runtime 使用正确的版本。 库和 GitHub 存储库处于维护模式。 没有进一步发布的计划,问题支持部门只会尽力而为。 如果对于此库或 Azure Databricks 环境的监视和日志记录路线图有任何其他问题,请联系 azure-spark-monitoring-help@databricks.com。
本文介绍如何使用监视仪表板查找 Azure Databricks 上 Spark 作业中的性能瓶颈。
Azure Databricks 是一个基于 Apache Spark 的分析服务,可以轻松快速地开发和部署大数据分析。 在操作生产 Azure Databricks 工作负载时,监视和排查性能问题是很关键的。 为了确定常见的性能问题,使用基于遥测数据的监视可视化效果十分有用。
先决条件
设置本文中所示的 Grafana 仪表板的步骤:
使用 Azure Databricks 监视库,将 Databricks 群集配置为将遥测数据发送到 Log Analytics 工作区。 有关详细信息,请参阅 GitHub 自述文件。
在虚拟机中部署 Grafana。 请参阅使用仪表板将 Azure Databricks 指标可视化。
部署的 Grafana 仪表板包含一组时序可视化效果。 每个图都是与 Apache Spark 作业、作业的各个阶段,以及构成每个阶段的任务相关的指标的时序图。
Azure Databricks 性能概述
Azure Databricks 基于通用分布式计算系统 Apache Spark。 应用程序代码(称为“作业”)在 Apache Spark 群集上执行,由群集管理器进行协调。 作业通常是最高级别的计算单元。 作业表示由 Spark 应用程序执行的完整操作。 典型的操作包括从源读取数据、应用数据转换以及将结果写入存储或其他目标。
作业分为几个阶段。 作业按顺序推进到各个阶段,这意味着后面的阶段必须等待前面的阶段完成。 阶段包含可在 Spark 群集的多个节点上并行执行的相同任务组。 任务是在发生在数据子集上的最细化的执行单位。
接下来的各节将介绍一些仪表板可视化效果,对于性能故障排除很有用。
作业和阶段延迟
作业延迟是指从作业执行开始到完成的持续时间。 它显示为每个群集和应用程序 ID 的作业执行百分位数,以使异常值可视化。 下图显示了一个作业历史记录,其中在第 90 百分位数达到了 50 秒,尽管第 50 百分位数一直在 10 秒左右。
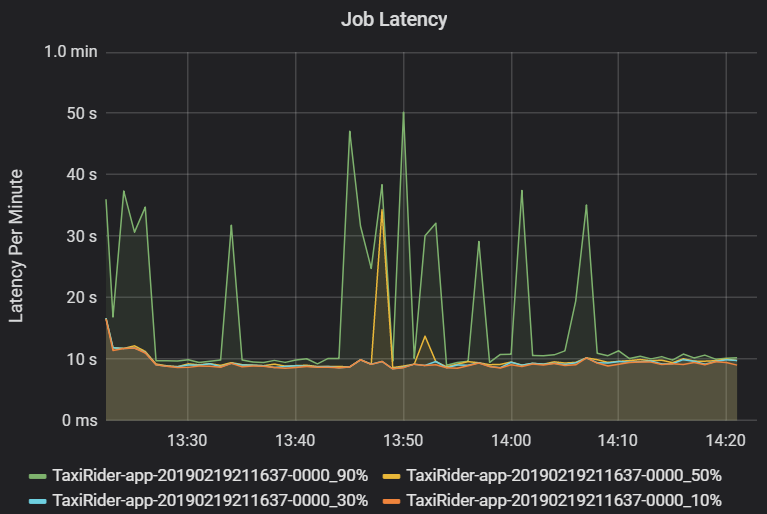
按群集和应用程序调查作业执行情况,查找延迟峰值。 确定具有高延迟的群集和应用程序后,继续调查阶段延迟。
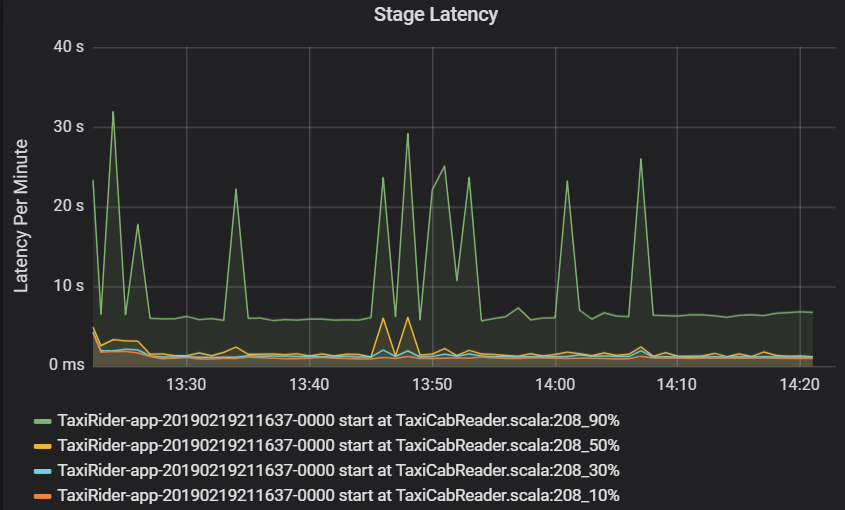
阶段延迟也显示为百分位数,以使离群值可视化。 阶段延迟按群集、应用程序和阶段名称划分。 确定图中任务延迟的峰值,以确定哪些任务阻碍了该阶段的完成。
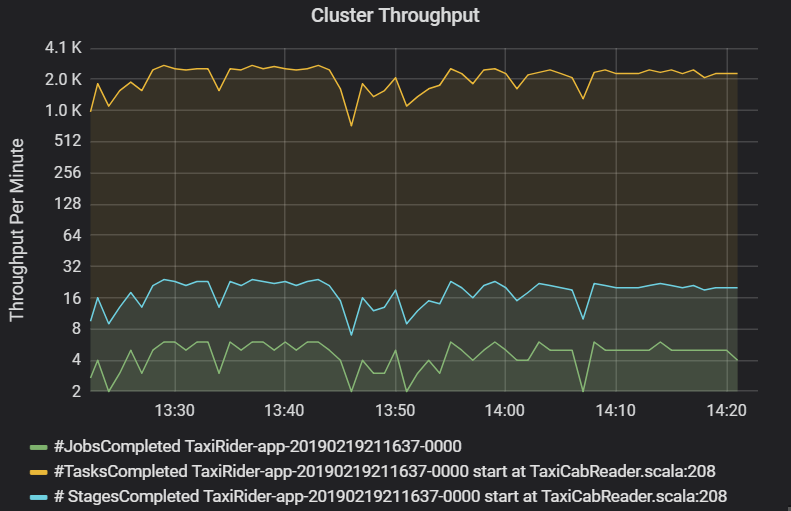
“群集吞吐量”图中显示了每分钟完成的作业、阶段和任务的数量。 这可以帮助你根据每个作业的相对阶段和任务数来了解工作负载。 在这里可以看到,每分钟的作业数范围为 2 到 6,而每分钟的阶段数约为 12 到 24。
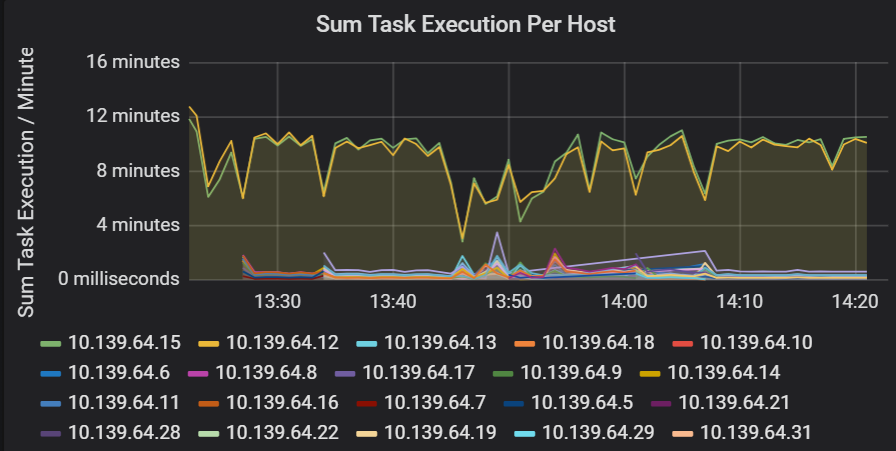
任务执行延迟的总和
此可视化效果显示了群集上运行的每个主机的任务执行延迟总和。 使用此图可检测由于群集上主机变慢而导致运行缓慢的任务,或每个执行程序的任务分配错误。 在下图中,大部分主机的总和约 30 秒。 不过,其中两个主机的总和在 10 分钟左右徘徊。 要么是主机运行缓慢,要么是每个执行程序的任务数分配错误。
每个执行程序的任务数显示,两个执行程序被分配了不成比例的任务数,由此导致瓶颈。
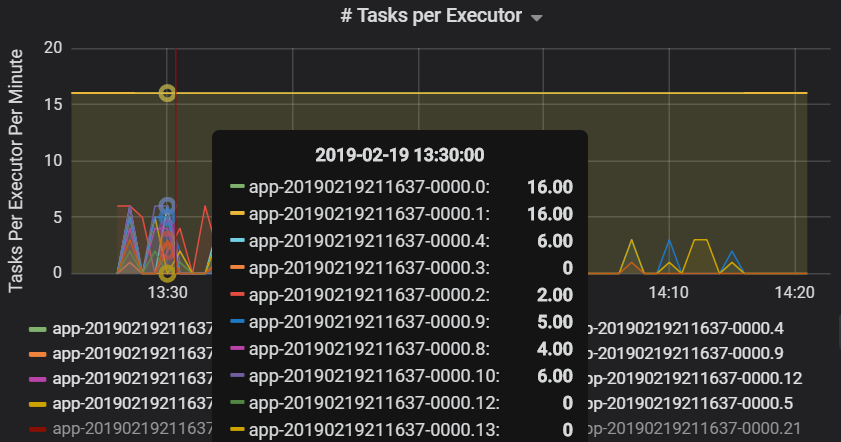
每个阶段的任务指标
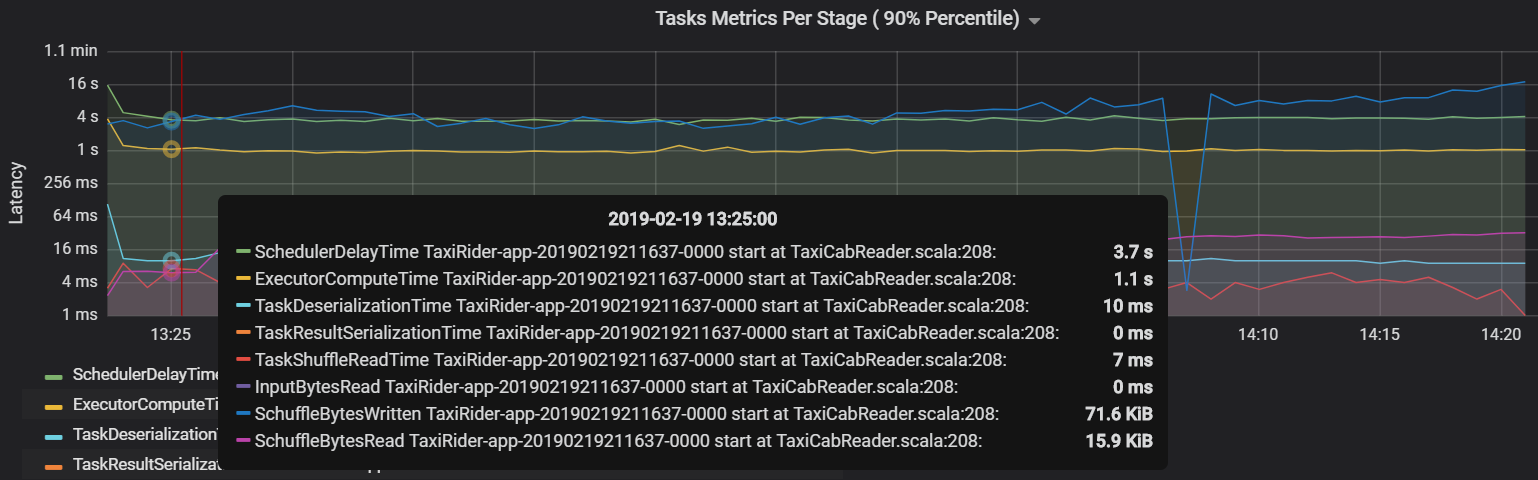
任务指标可视化效果提供任务执行的成本细分。 可用它查看花费在序列化和反序列化等任务上的相对时间。 此数据可能会显示优化的机会,例如,使用广播变量来避免发送数据。 任务指标还显示任务的随机数据大小,以及随机读取和写入时间。 如果这些值很高,就意味着有大量的数据在网络上移动。
另一个任务指标是计划程序延迟,用于衡量计划任务所用的时间。 理想情况下,与执行程序计算时间相比,此值应较低,这是执行任务的实际用时。
下图显示了超过执行程序计算时间(1.1 秒)的计划程序延迟时间(3.7 秒)。 这意味着等待计划任务的时间比实际工作时间要长。
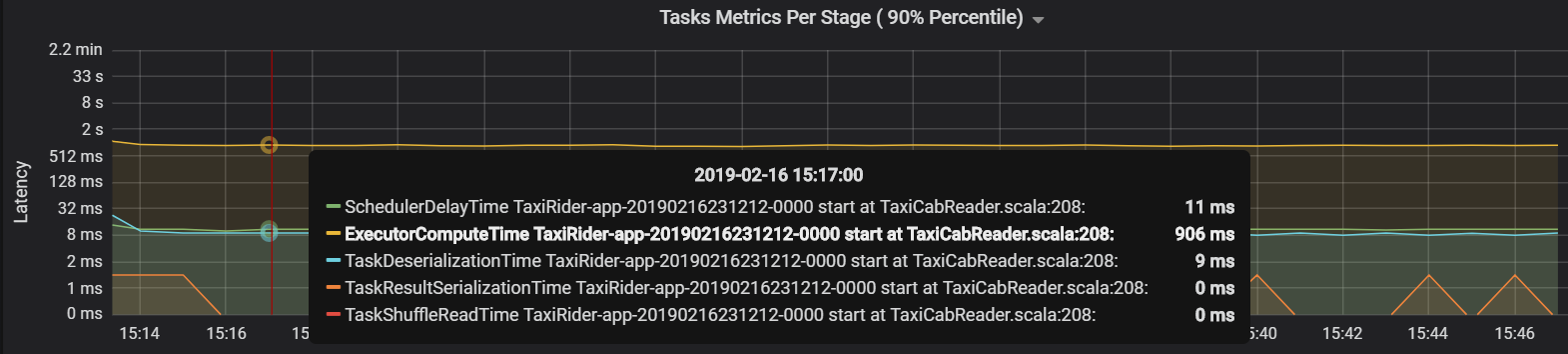
在这种情况下,问题是由于分区过多而导致的,这产生了大量开销。 减少分区数缩短了计划程序延迟时间。 下图显示了大部分时间都是在执行任务。
流式处理吞吐量和延迟
流式处理吞吐量与结构化流式处理直接相关。 有两个与流式处理吞吐量关联的重要指标:每秒输入行数和每秒处理的行数。 如果每秒输入的行数超过每秒处理的行数,意味着流式处理系统落后了。 此外,如果输入数据来自事件中心或 Kafka,则每秒输入行数应与前端的数据引入速率保持同步。
两个作业可以具有相似的群集吞吐量,但流式处理指标有很大的不同。 以下屏幕截图显示了两个不同的工作负载。 它们在群集吞吐量(每分钟的作业、阶段和任务数量)方面相似。 但与 4000 行/秒相比,第二个运行的处理速率为 12000 行/秒。
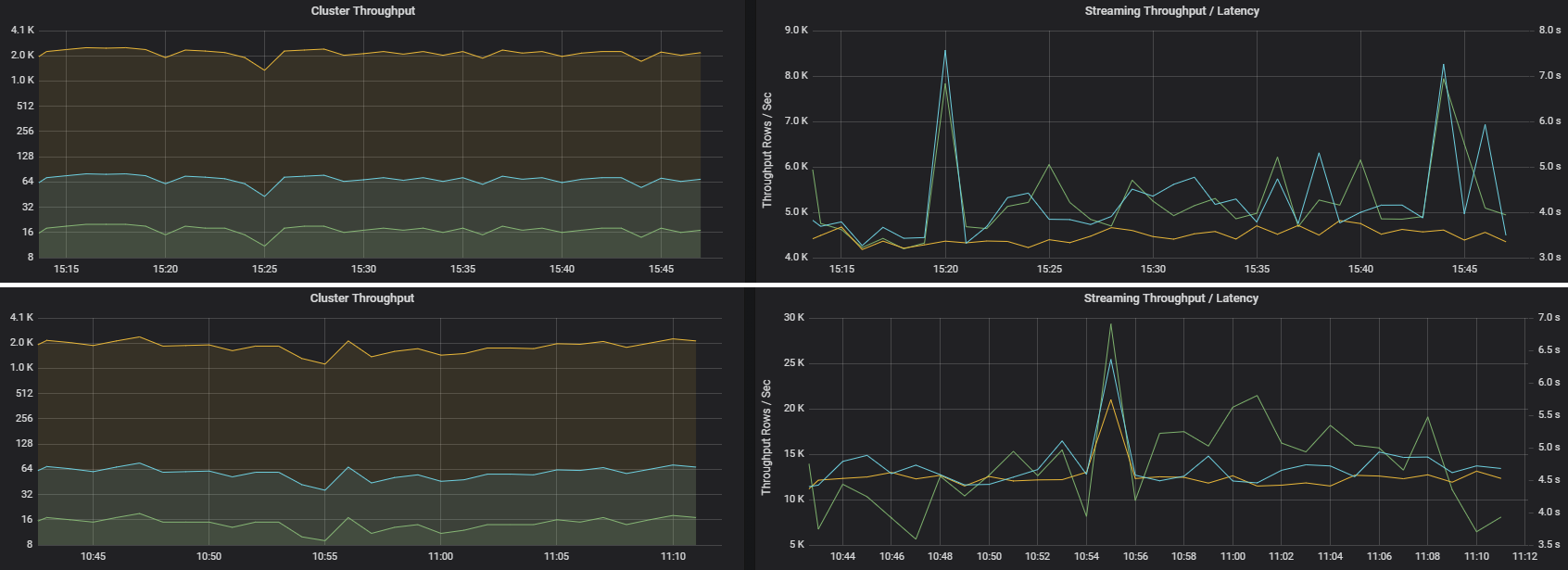
流式处理吞吐量通常是比群集吞吐量更好的业务指标,因为它可以衡量已处理的数据记录数。
每个执行程序的资源消耗
以下指标有助于了解每个执行程序执行的工作。
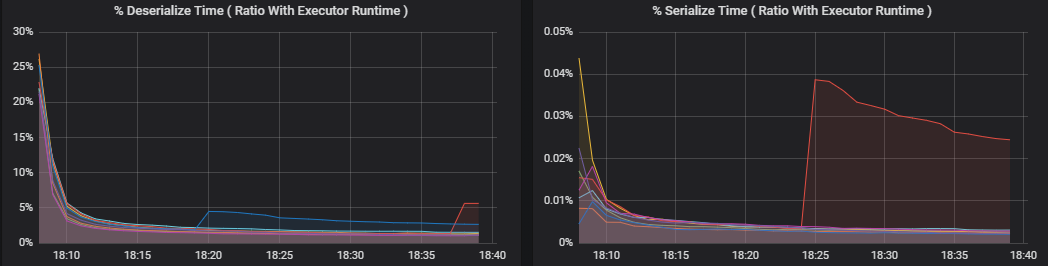
百分比指标衡量执行程序在各个事项上花费的时间,以花费的时间与执行程序总体计算时间的比率来表示。 这些指标包括:
- 序列化时间百分比
- 反序列化时间百分比
- CPU 执行程序时间百分比
- JVM 时间百分比
这些可视化效果显示了每个指标对执行程序整体处理的影响程度。
随机指标是与跨执行程序的数据随机排列相关的指标。
- 随机 I/O
- 随机内存
- 文件系统使用情况
- 磁盘使用
常见性能瓶颈
Spark 中的两个常见性能瓶颈是“任务散乱”和“非最优的随机分区计数”。
任务散乱
作业中的各个阶段按顺序执行,前面的阶段会阻断后面的阶段。 如果一项任务执行随机分区的速度比其他任务慢,则群集中的所有任务都必须等待缓慢任务赶上进度才能结束该阶段。 这可能是由以下原因引起的:
主机或主机组运行缓慢。 症状:任务、阶段或作业延迟高,群集吞吐量低。 每个主机的任务延迟总和不会均匀分布。 但是,资源消耗将均匀地分布在各个执行程序上。
执行任务的代价高昂(数据倾斜)。 症状:任务、阶段和作业延迟高,或群集吞吐量低,但每个主机的延迟总和分布均布。 资源消耗将均匀地分布在各个执行程序上。
如果分区大小不等,较大的分区可能会导致任务执行不平衡(分区倾斜)。 症状:与群集上运行的其他执行程序相比,执行程序资源消耗较高。 在该执行程序上运行的所有任务都将缓慢运行,并在管道中保持阶段执行。 这些阶段被称为“阶段障碍”。
非最优的随机分区计数
在结构化流式处理查询期间,将任务分配给执行程序是群集的一个资源密集型操作。 如果随机数据不是最佳大小,任务的延迟量会对吞吐量和延迟产生负面影响。 如果分区太少,则无法充分利用群集中的核心,从而导致处理效率低下。 相反,如果分区太多,那么少量的任务就会导致大量的管理开销。
使用资源消耗指标排查群集上执行程序分区倾斜和错误分配的问题。 如果分区是倾斜的,则与群集上运行的其他执行程序相比,执行程序资源将有所提升。
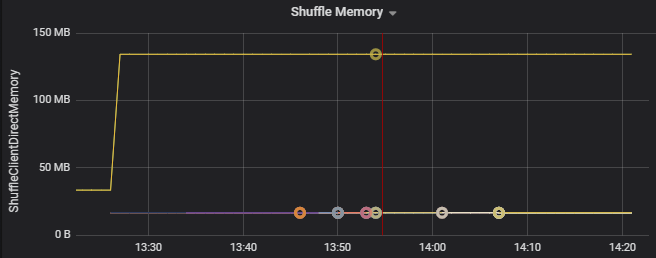
例如,下图显示了前两个执行程序上的随机排列使用的内存比其他执行程序大 90 倍:
后续步骤
- 监视 Azure Log Analytics 工作区中的 Azure Databricks
- 学习路径:通过 Azure Databricks 构建和运行机器学习解决方案
- Azure Databricks 文档
- Azure Monitor 概述
相关资源
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈