你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
多租户解决方案中面向 AI 和 ML 的体系结构方法
越来越多的多租户解决方案围绕人工智能 (AI) 和机器学习 (ML) 而构建。 多租户 AI/ML 解决方案可向任意数量的租户提供基于 ML 的类似功能。 租户通常无法看到或共享任何其他租户的数据,但在某些情况下,租户可能会使用与其他租户相同的模型。
多租户 AI/ML 体系结构需要考虑数据和模型的要求,以及训练模型和基于模型执行推理所需的计算资源。 请务必考虑多租户 AI/ML 模型如何部署、分布和协调,以及如何确保解决方案准确、可靠且可扩展。
随着由大语言模型和小型语言模型提供支持的生成 AI 技术越来越受欢迎,通过采用机器学习运营 (MLOps) 和 GenAIOps(有时称为 LLMOps)在生产环境中建立有效的操作实践和策略来管理这些模型至关重要。
关键考虑因素和要求
使用 AI 和 ML 时,请务必分别针对训练和推理考虑你的要求。 训练的目的是生成基于一组数据的预测模型。 你在使用模型预测应用程序中的内容时执行推理。 其中每个过程都有不同的要求。 在多租户解决方案中,应考虑租户模型如何影响每个过程。 通过考虑上述每个要求,可以确保解决方案提供准确的结果,在负载下表现良好,并且经济高效,可以进行扩展来应对未来的增长。
租户隔离
确保租户无法对其他租户的数据或模型进行未经授权或不必要的访问。 以与训练模型的原始数据类似的敏感度处理模型。 确保租户了解其数据如何用于训练模型,以及基于其他租户数据训练的模型如何可能用来针对其工作负载进行推理。
在多租户解决方案中使用 ML 模型有三种常见方法:特定于租户的模型、共享模型和优化的共享模型。
特定于租户的模型
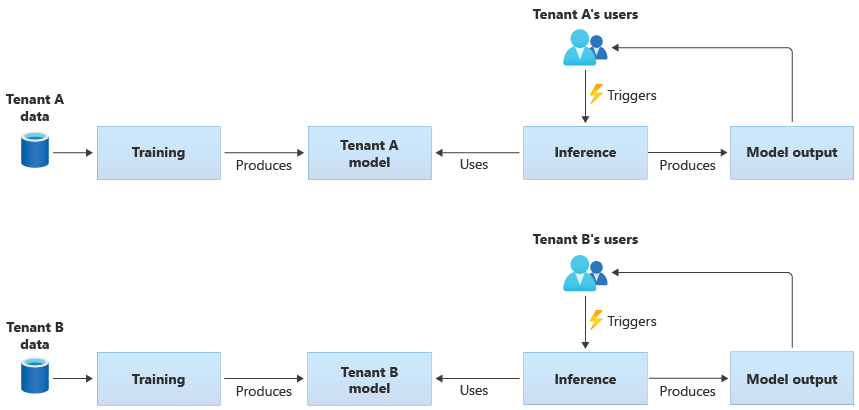
特定于租户的模型仅基于单个租户的数据进行训练,然后会应用于该单个租户。 当租户的数据很敏感时,或者当一个租户提供的数据可供学习的范围很小并且你将模型应用于另一个租户时,租户特定的模型是适用的。 下图演示了如何为两个租户生成具有特定于租户的模型的解决方案:
共享模型
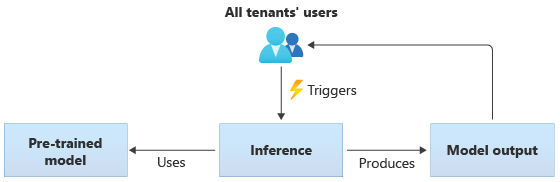
在使用共享模型的解决方案中,所有租户都基于同一共享模型执行推理。 共享模型可能是你从社区源获取的预训练模型。 下图说明了所有租户如何使用单个预训练模型进行推理:
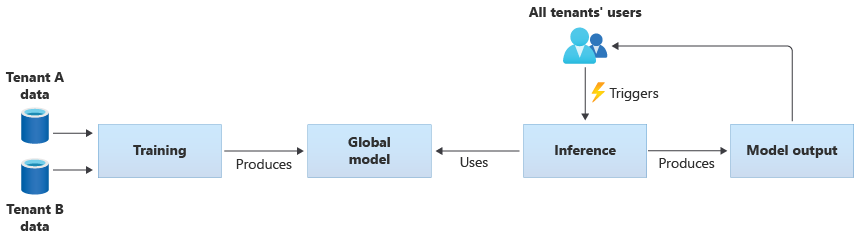
还可以生成你自己的共享模型,具体方式是基于所有租户提供的数据训练这些模型。 下图演示了单个共享模型,该模型基于来自所有租户的数据进行训练:
重要
如果基于租户的数据训练共享模型,请确保租户了解并同意对其数据的使用。 请确保从租户数据中删除标识信息。
请考虑在租户反对将其数据用于训练要应用于另一个租户的模型时该怎么做。 例如,能否从训练数据集内排除特定租户的数据?
优化的共享模型
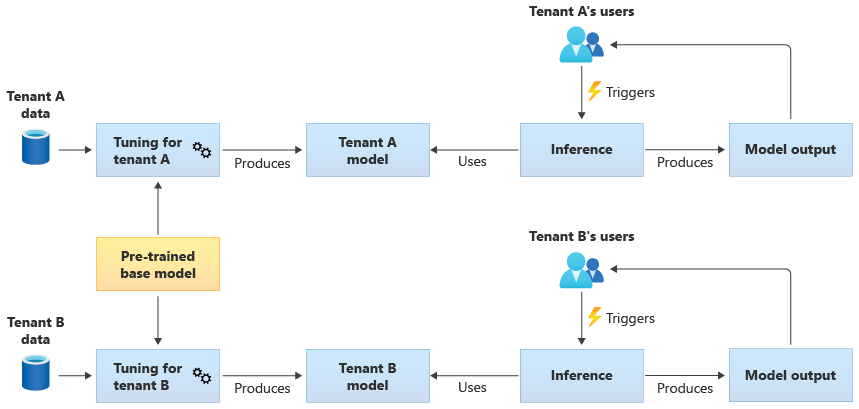
还可以选择获取预训练的基础模型,然后基于每个租户自己的数据执行进一步的模型优化,使其适用于各个租户。 下图演示了此方法:
可伸缩性
考虑解决方案的增长如何影响你对 AI 和 ML 组件的使用。 增长可以指租户数、为每个租户存储的数据量、用户数和解决方案请求量的增加。
训练:有几个因素会影响训练模型所需的资源。 这些因素包括需要训练的模型数、用于训练模型的数据量以及训练或重新训练模型的频率。 如果创建特定于租户的模型,则随着租户数量的增长,所需的计算资源和存储量也可能会增长。 如果创建共享模型并基于来自所有租户的数据训练它们,则用于训练的资源的扩展速度不太可能与租户数的增长速度相同。 但是,训练数据总量的增加会影响为了训练共享模型和特定于租户的模型而消耗的资源。
推理:推理所需的资源通常与为了进行推理而访问模型的请求数成正比。 随着租户数的增加,请求数可能也会增加。
使用可恰当缩放的 Azure 服务是一种很好的常规做法。 由于 AI/ML 工作负载倾向于使用容器,因此 Azure Kubernetes 服务 (AKS) 和 Azure 容器实例 (ACI) 往往对于 AI/ML 工作负载而言是常见的选择。 AKS 通常是用于实现高扩展性并根据需求动态缩放计算资源的不错选择。 对于小型工作负载,ACI 可以是一个可配置的简单计算平台,尽管它不像 AKS 那样容易缩放。
性能
针对训练和推理来考虑解决方案的 AI/ML 组件的性能要求。 必须阐明每个过程的延迟和性能要求,以便根据需要进行度量和改进。
训练:训练通常作为批处理过程执行,这意味着它可能不像工作负载的其他部分那样对性能敏感。 但是,需要确保预配足够的资源以高效执行模型训练,包括在进行缩放时。
推理:推理是一个对延迟敏感的过程,通常需要快速甚至实时响应。 即使不需要实时执行推理,也要确保监视解决方案的性能,并使用相应的服务来优化工作负载。
请考虑对 AI 和 ML 工作负载使用 Azure 的高性能计算功能。 Azure 提供了许多不同类型的虚拟机和其他硬件实例。 请考虑解决方案是否会受益于使用 CPU、GPU、FPGA 或其他硬件加速环境。 Azure 还通过 NVIDIA GPU 提供实时推理,包括 NVIDIA Triton 推理服务器。 对于低优先级计算要求,请考虑使用 AKS 现成节点池。 若要详细了解如何在多租户解决方案中优化计算服务,请参阅多租户解决方案中的计算体系结构方法。
模型训练通常需要与数据存储进行大量交互,因此,考虑数据策略和数据层提供的性能也十分重要。 有关多租户和数据服务的详细信息,请参阅多租户解决方案中存储和数据的体系结构方法。
请考虑分析解决方案的性能。 例如,Azure 机器学习提供了你可以在开发和检测解决方案时使用的分析功能。
实施复杂性
生成解决方案以使用 AI 和 ML 时,可以选择使用预生成的组件,或选择生成自定义组件。 你需要做出两个关键决策。 第一个是用于 AI 和 ML 的平台或服务。 第二个是使用预训练的模型还是生成自己的自定义模型。
平台:有许多可用于 AI 和 ML 工作负载的 Azure 服务。 例如,Azure AI 服务和 Azure OpenAI 服务提供了 API 以针对预生成模型执行推理,并且 Microsoft 会管理基础资源。 Azure AI 服务使你能够快速部署新解决方案,但在如何执行训练和推理方面,它提供给你的控制较少,并且它可能并非适合每种类型的工作负载。 而 Azure 机器学习是一个可用于生成、训练和使用自己的 ML 模型的平台。 Azure 机器学习提供控制和灵活性,但它增加了设计和实施的复杂性。 请查看 Microsoft 提供的机器学习产品和技术,以在选择方法时做出明智的决策。
模型:即使不使用 Azure AI 服务等服务提供的完整模型,也仍然可以使用预训练的模型来加速开发。 如果预训练的模型无法精准地满足你的需求,请考虑通过应用一种称为转移学习或微调的技术来扩展预训练的模型。 通过转移学习,可以扩展现有模型并将其应用于其他领域。 例如,如果要构建多租户音乐建议服务,则可以考虑基于预训练的音乐建议模型来构建,并使用转移学习来针对特定用户的音乐首选项训练该模型。
通过使用预生成的 ML 平台(如 Azure AI 服务或 Azure OpenAI 服务)或预训练的模型,可以显著降低初始研发成本。 使用预生成平台可能会节省你数月的研究时间,并且无需招募高素质的数据科学家来训练、设计和优化模型。
成本优化
通常,AI 和 ML 工作负载的大部分成本来自模型训练和推理所需的计算资源。 请查看多租户解决方案中的计算体系结构方法,了解如何根据需求优化计算工作负载的成本。
在计划 AI 和 ML 成本时,请考虑以下要求:
- 确定用于训练的计算 SKU。 例如,请参阅有关如何使用 Azure 机器学习执行此操作的指南。
- 确定用于推理的计算 SKU。 有关用于推理的示例成本估算,请参阅 Azure 机器学习指南。
- 监视利用率。 通过观察计算资源的利用率,可以确定是应该通过部署不同的 SKU 来减少或增加其容量,还是根据需求的变化来缩放计算资源。 请参阅 Azure 机器学习监视。
- 优化计算群集环境。 使用计算群集时,监视群集利用率或配置自动缩放以纵向缩减计算节点。
- 共享计算资源。 请考虑是否可以通过跨多个租户共享计算资源来优化计算资源的成本。
- 考虑预算。 了解是否具有固定预算,并相应地监视消耗量。 可以设置预算,从而防止超支并根据租户优先级分配配额。
要考虑的方法和模式
Azure 提供了一组服务,用来启用 AI 和 ML 工作负载。 多租户解决方案中使用了几种常见的体系结构方法:使用预生成的 AI/ML 解决方案、使用 Azure 机器学习构建自定义 AI/ML 架构,以及使用 Azure 分析平台之一。
使用预生成的 AI/ML 服务
在可能的情况下尝试使用预生成的 AI/ML 服务是一种很好的做法。 例如,组织可能开始查看 AI/ML,并希望快速与有用的服务集成。 或者,你可能有不需要自定义 ML 模型训练和开发的基本要求。 预生成的 ML 服务使你无需生成和训练自己的模型即可使用推理。
Azure 提供多个服务,这些服务跨多种领域(包括语言理解、语音识别、知识、文档和表单识别以及计算机视觉)提供 AI 和 ML 技术。 Azure 预生成的 AI/ML 服务包括 Azure AI 服务、Azure OpenAI 服务、 Azure AI 搜索和 Azure AI 文档智能。 每个服务都提供一个用于集成的简单接口,以及一个经过预先训练和测试的模型集合。 作为托管服务,它们提供服务级别协议,所需的配置或持续管理很少。 无需开发或测试自己的模型即可使用这些服务。
许多托管 ML 服务不要求模型训练或数据,因此通常没有租户数据隔离问题。 但是,在多租户解决方案中使用 AI 搜索时,请查看多租户 SaaS 应用程序与 Azure AI 搜索的设计模式。
请考虑解决方案中组件的缩放要求。 例如,Azure AI 服务中的许多 API 支持一个每秒最大请求数。 如果部署单个要在租户之间共享的 AI 服务资源,则随着租户数的增加,便可能需要扩展到多个资源。
注意
某些托管服务使你能够使用自己的数据进行训练,包括自定义视觉服务、人脸 API 和文档智能自定义模型,以及某些支持自定义和微调的 OpenAI 模型。 使用这些服务时,请务必考虑租户数据的隔离要求。
自定义 AI/ML 体系结构
如果你的解决方案需要自定义模型,或者某个托管 ML 服务未涵盖你的工作领域,请考虑构建自己的 AI/ML 体系结构。 Azure 机器学习提供了一套功能来协调 ML 模型的训练和部署。 Azure 机器学习支持许多开源机器学习库,包括 PyTorch、Tensorflow、Scikit 和 Keras。 可以持续监视模型的性能指标、检测数据偏移并触发重新训练,从而提高模型性能。 在 ML 模型的整个生命周期中,Azure 机器学习通过内置跟踪和世系对所有 ML 项目实现可审计性和治理。
在多租户解决方案中工作时,请务必在训练阶段和推理阶段均考虑租户的隔离要求。 还需要确定模型训练和部署过程。 Azure 机器学习提供了一个管道,用来训练模型并将其部署到要用于推理的环境。 在多租户上下文中,请考虑模型是应部署到共享计算资源,还是每个租户都有专用资源。 根据隔离模型和租户部署过程设计你的模型部署管道。
使用开源模型时,可能需要使用转移学习或优化重新训练这些模型。 请考虑如何管理每个租户的不同模型和训练数据,以及模型的版本。
下图演示了一个使用 Azure 机器学习的示例体系结构。 此示例使用特定于租户的模型隔离方法。
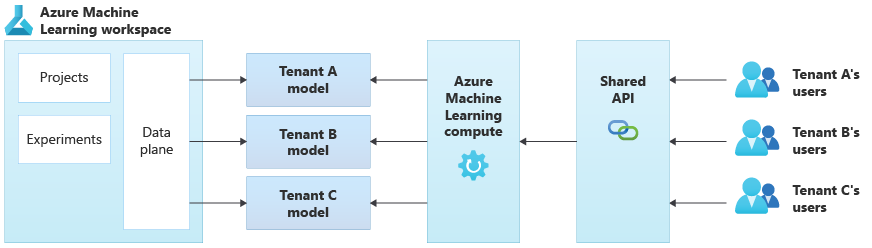
集成 AI/ML 解决方案
Azure 提供了多个功能强大的、可用于多种用途的分析平台。 这些平台包括 Azure Synapse Analytics、Databricks 和 Apache Spark。
在需要将 ML 功能扩展到海量租户时,以及在需要大规模计算和业务流程时,可以考虑将这些平台用于 AI/ML。 当需要为解决方案的其他部分提供广泛的分析平台(例如,用于通过 Microsoft Power BI 进行数据分析以及与报告进行集成)时,也可以考虑将这些平台用于 AI/ML。 可以部署涵盖所有分析和 AI/ML 需求的单个平台。 在多租户解决方案中实现数据平台时,请查看多租户解决方案中存储和数据的体系结构方法。
ML 操作模型
采用 AI 和机器学习(包括生成式 AI 实践)时,不断改进和评估组织管理能力是一种很好的做法。 MLOps 和 GenAIOps 的引入客观上提供了一个框架,可以不断扩展组织中 AI 和 ML 实践的功能。 请查看 MLOps 成熟度模型和 LLMOps 成熟度模型文档,以获取进一步指导。
要避免的反模式
- 未能考虑隔离要求。 请务必针对训练和推理仔细考虑如何隔离租户的数据和模型。 未能这样做可能会违反法律或合同要求。 这还可能会降低要基于多个租户的数据进行训练的模型的准确性(如果这些数据存在显著差异)。
- 近邻干扰。 考虑你的训练或推理过程是否可能受到“近邻干扰”问题的影响。 例如,如果有多个大型租户和单个小型租户,请确保大型租户的模型训练不会在无意中消耗所有计算资源并使较小的租户没有资源可用。 使用资源治理和监视措施,以缓解受其他租户活动影响的租户计算工作负载的风险。
作者
本文由 Microsoft 维护, 它最初是由以下贡献者撰写的。
首席作者:
- Kevin Ashley | FastTrack for Azure 高级客户工程师
其他参与者:
- Paul Burpo | FastTrack for Azure 首席客户工程师
- John Downs | 首席软件工程师
- 丹尼尔·斯科特-伦斯福德|高级合作伙伴技术解决方案顾问
- 阿森·弗拉基米尔斯基|首席工程师,FastTrack for Azure
- Vic Perdana | ISV 合作伙伴解决方案架构师
后续步骤
- 查看多租户解决方案中的计算体系结构方法。
- 若要详细了解如何设计 Azure 机器学习管道以支持多个租户,请参阅采用多租户方式的 ML 管道解决方案。