此参考体系结构演示如何使用 Azure Batch 对 R 模型执行批处理评分。 Azure Batch 适用于本质上并行的工作负载,包括作业调度和计算管理。 批量推理(评分)广泛用于细分客户、预测销售、预测客户行为、预测维护或改进网络安全。
下载此体系结构的 Visio 文件。
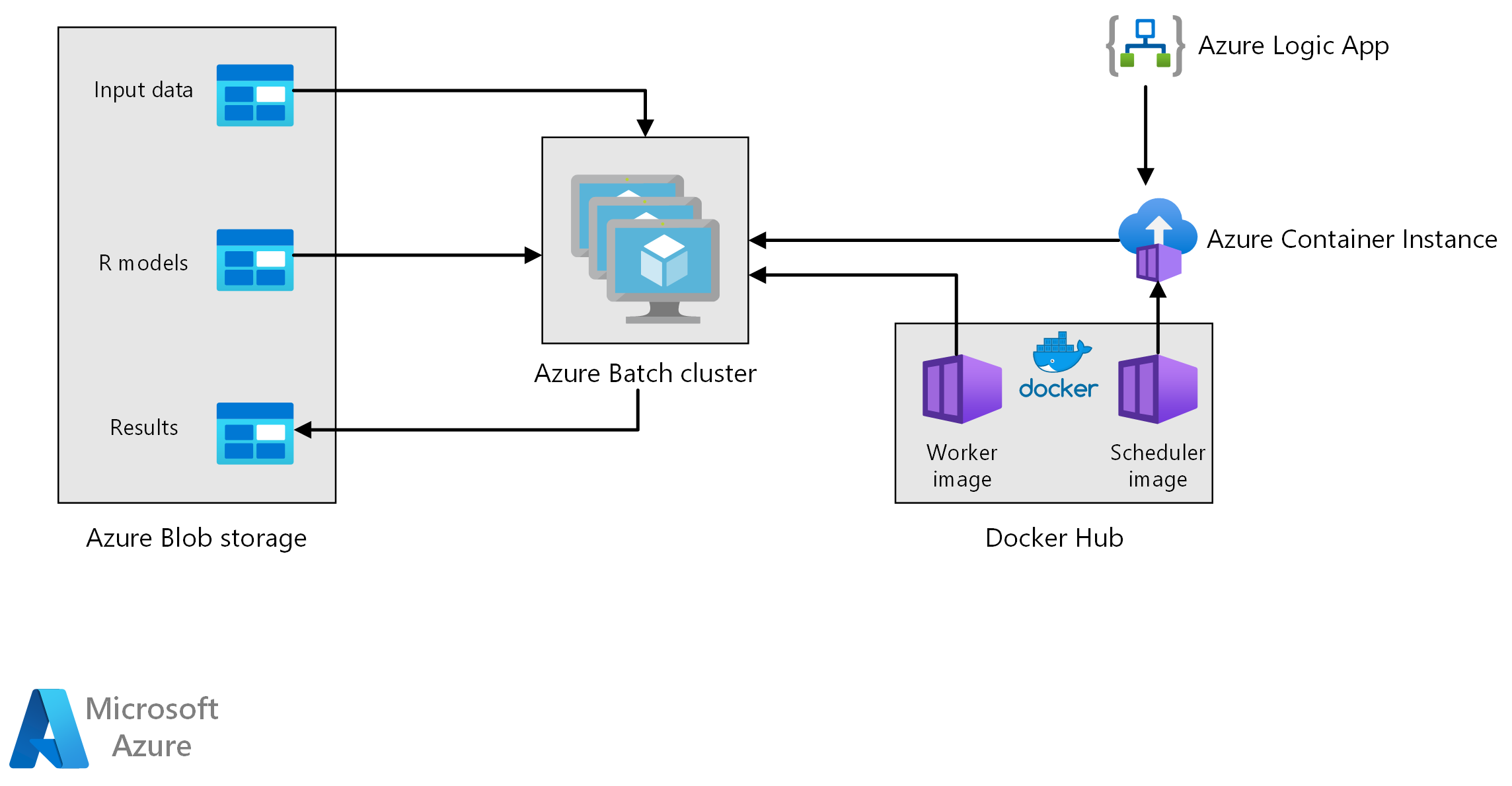
工作流
该体系结构包括以下组件。
Azure Batch 在虚拟机群集上并行运行预测生成作业。 使用 R 中实现的预先训练的机器学习模型进行预测。Azure Batch 可以根据提交到群集的作业数自动缩放 VM 数。 在每个节点上,R 脚本在 Docker 容器中运行,以对数据进行评分并生成预测。
Azure Blob 存储存储输入数据、预先训练的机器学习模型和预测结果。 它为此工作负载所需的性能提供经济高效的存储。
Azure 容器实例按需提供无服务器计算。 在这种情况下,容器实例会按计划部署,以触发生成预测的批处理作业。 批处理作业使用 doAzureParallel 包从 R 脚本触发。 作业完成后,容器实例会自动关闭。
Azure 逻辑应用通过按计划部署容器实例来触发整个工作流。 逻辑应用中的 Azure 容器实例连接器允许在一系列触发器事件上部署实例。
组件
解决方案详细信息
尽管以下方案基于零售店销售预测,但其体系结构可以通用于需要使用 R 模型大规模生成预测的所有方案。 GitHub 中提供了本体系结构的参考实现。
可能的用例
超市连锁店需要预测未来季度产品销售额。 预测让公司更好地管理其供应链,并确保可以满足其每个商店的产品需求。 公司每周会随着前一周新销售数据的发布以及下一季度产品营销策略的制定来更新预测。 生成分位数预测以估计各个销售预测的不确定性。
包括以下处理步骤:
Azure 逻辑应用每周触发一次预测生成过程。
逻辑应用启动运行计划程序 Docker 容器的 Azure 容器实例,这会触发 Batch 群集上的评分作业。
评分作业在 Batch 群集的节点之间并行运行。 每个节点:
拉取辅助角色 Docker 映像并启动容器。
从 Azure Blob 存储读取输入数据和预先训练的 R 模型。
为生成预测的数据评分。
将预测结果写入 Blob 存储。
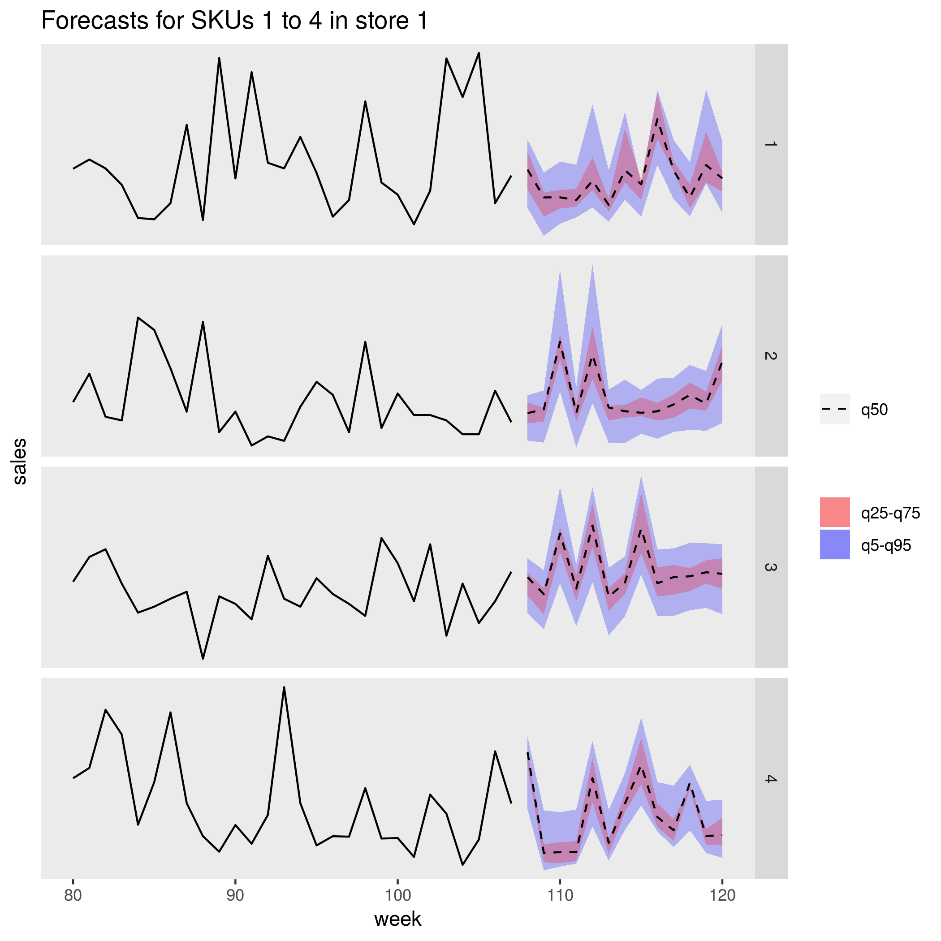
下图显示了一家商店中四个产品 (SKU) 的预测销售额。 黑线是销售历史记录,虚线是预测的中值 (q50),粉红色带代表第 25 和第 75 百分位,蓝色带代表第 50 和第 95 百分位。
注意事项
这些注意事项实施 Azure 架构良好的框架的支柱原则,即一套可用于改善工作负载质量的指导原则。 有关详细信息,请参阅 Microsoft Azure 架构良好的框架。
性能
容器化部署
使用此体系结构,所有 R 脚本都在 Docker 容器中运行。 使用容器可确保脚本每次都以相同的 R 版本和包版本在一致环境中运行。 单独的 Docker 映像用于计划程序容器和辅助角色容器,因为每个映像都有一组不同的 R 包依赖项。
Azure 容器实例为运行计划程序容器提供无服务器环境。 计划程序容器运行一个 R 脚本,该脚本触发在 Azure Batch 群集上运行的各个评分作业。
Batch 群集的每个节点运行辅助角色容器,该容器执行评分脚本。
并行化工作负载
使用 R 模型对数据进行批处理评分时,请考虑如何并行化工作负载。 必须对输入数据进行分区,以便评分操作可以分布在群集节点中。 尝试不同的方法来发现分布工作负载的最佳选择。 根据具体情况,考虑:
- 可以在单个节点的内存中加载和处理多少数据。
- 启动每个批处理作业的开销。
- 加载 R 模型的开销。
在此示例使用的方案中,模型对象很大,只需几秒钟即可生成各个产品的预测。 因此,可以为每个节点对产品进行分组并执行单个批处理作业。 每个作业中的循环按顺序生成产品的预测。 此方法是并行化此特定工作负载的最有效方法。 它避免了启动许多较小批处理作业并重复加载 R 模型的开销。
另一种方法是为每个产品触发一个批处理作业。 Azure Batch 自动形成作业队列,并在节点可用时提交要在群集上执行的作业队列。 使用自动缩放根据作业数调整群集中的节点数。 如果完成每个评分操作所需的时间相对较长,此方法非常有用,这可以证明启动作业和重新加载模型对象的开销。 此方法也更易于实现,并让你灵活地使用自动缩放,如果事先不知道总工作负载大小,这一方法则是重要考虑因素。
监视 Azure 批处理作业
在 Azure 门户中的 Batch 帐户的“作业”窗格中监视和终止批处理作业。 从“池”窗格中监视批处理群集,包括单个节点的状态。
使用 doAzureParallel 进行日志记录
doAzureParallel 包会自动收集 Azure Batch 上提交的每个作业的所有 stdout/stderr 日志。 可以在设置时创建的存储帐户中找到这些日志。 若要轻松查看日志文件,请使用 Azure 存储资源管理器或 Azure 门户等存储导航工具。
若要在开发过程中快速调试批处理作业,请在本地 R 会话中查看日志。 有关详细信息,请参阅使用配置和提交训练运行。
成本优化
成本优化是关于寻找减少不必要的费用和提高运营效率的方法。 有关详细信息,请参阅成本优化支柱概述。
计算资源是此体系结构中使用的最昂贵组件。 对于此方案,每当触发作业时,就会创建一个固定大小的群集,然后在作业完成后关闭。 只有当群集节点正在启动、正在运行或正在关闭时,会产生费用。 此方法适用于生成预测所需的计算资源在不同作业之间保持相对恒定的情况。
如果事先不知道完成作业所需的计算量,则更适合使用自动缩放。 使用此方法时,群集的大小会根据作业的大小进行纵向扩展或缩减。 Azure Batch 支持一系列自动缩放公式,可以在使用 doAzureParallel API 定义群集时设置该公式。
在某些方案,作业之间的时间可能太短,无法关闭并启动群集。 在这些情况下,如果合适,请保持群集在作业之间运行。
Azure Batch 和 doAzureParallel 支持使用低优先级 VM。 这些 VM 折扣很高,但可能会受到其他优先级较高的工作负载侵占的风险。 因此,不建议对关键生产工作负载使用低优先级 VM。 但是,它们对于实验性或开发工作负载非常有用。
部署此方案
若要部署此参考体系结构,请按照 GitHub 存储库中所述的步骤进行操作。
作者
本文由 Microsoft 维护, 它最初是由以下贡献者撰写的。
首席作者:
- Angus Taylor | 高级数据科学家
若要查看非公开的 LinkedIn 个人资料,请登录到 LinkedIn。