你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用动态管理视图监视 Azure SQL 数据库的性能
适用于: ![]() Azure SQL 数据库
Azure SQL 数据库
可以使用动态管理视图 (DMV) 来监视工作负载性能和诊断性能问题,这些问题可能由查询受阻或长时间运行、资源瓶颈、不良查询计划等原因造成。
本文介绍有关如何通过使用 T-SQL 查询动态管理视图来检测常见性能问题。 可使用任何查询工具,例如:
权限
在 Azure SQL 数据库中,根据计算大小、部署选项和 DMV 中的数据,查询 DMV 可能需要 VIEW DATABASE STATE、VIEW SERVER PERFORMANCE STATE 或 VIEW SERVER SECURITY STATE 权限。 后两个权限包含在 VIEW SERVER STATE 权限中。 通过相应的服务器角色中的成员身份授予查看服务器状态权限。 若要确定查询特定 DMV 所需的权限,请参阅动态管理视图并找到描述 DMV 的文章。
若要向数据库用户授予 VIEW DATABASE STATE 权限,请运行以下查询,将 database_user 替换为数据库中用户主体的名称:
GRANT VIEW DATABASE STATE TO [database_user];
若要将 ##MS_ServerStateReader## 服务器角色的成员身份授予逻辑服务器上名为 login_name 的登录名,需要连接到 master 数据库,然后运行如下查询:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
授予的权限可能需要几分钟才能生效。 有关详细信息,请参阅服务器级别角色的限制。
监视资源使用情况
可以使用以下视图在数据库级别监视资源使用状况。 这些视图适用于独立数据库和弹性池中的数据库。
可以使用以下视图在弹性池级别监视资源使用状况。
可以使用 Azure 门户中的 SQL 数据库查询性能见解或通过查询存储,在查询级别监视资源使用状况。
sys.dm_db_resource_stats
可以在每个数据库中使用 sys.dm_db_resource_stats 视图。 sys.dm_db_resource_stats 视图显示相对于计算大小限制的最新的资源使用情况数据。 每 15 秒间隔记录一次 CPU、数据 I/O、日志写入、工作线程和内存使用量相对于限制的百分比,持续记录约一小时。
由于此视图提供了更精细的资源使用状况数据,因此首先将 sys.dm_db_resource_stats 用于任何当前状态分析或故障排除。 例如,此查询显示过去一小时的当前数据库平均和最大资源使用情况:
SELECT
database_name = DB_NAME(),
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats
有关其他查询,请参阅 sys.dm_db_resource_stats 中的示例。
sys.resource_stats
master 数据库中的 sys.resource_stats 视图包含的信息可帮助监视数据库在特定服务层级和计算大小的性能。 每 5 分钟收集一次数据,并且会保留大约 14 天。 此视图可用于数据库使用资源的方式的长期历史分析。
下图显示一周内每小时的 P2 计算大小高级数据库的 CPU 资源使用情况。 此图从星期一开始显示,先显示 5 个工作日,然后显示周末,应用程序在周末使用的资源要少得多。
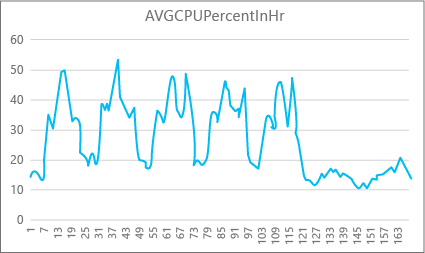
从数据而言,此数据库当前有一个峰值 CPU 负载刚好超过相对于 P2 计算大小的 50% CPU 使用率(星期二中午)。 如果 CPU 是应用程序资源配置文件的决定因素,可以决定 P2 是适当的计算大小以保证工作负荷始终适合。 如果预期应用程序的资源使用会随时间而增长,则最好是设置额外的资源缓冲,使应用程序不会达到性能级别限制。 如果增加计算大小,则有助于避免当数据库没有足够能力有效处理请求(尤其是在易受延迟影响的环境中)时向客户显示错误。
对于其他应用程序类型,同一图形可能有不同的解释。 例如,如果某个应用程序尝试每天处理工资数据并使用相同的图表,则在 P1 计算大小也许就能让此类“批处理作业”模型正常工作。 P1 计算大小有 100 个 DTU,P2 计算大小有 200 个 DTU。 P1 计算大小提供的性能是 P2 计算大小的一半。 因此,P2 级别 50% 的 CPU 使用率相当于 P1 级别 100% 的 CPU 使用率。 如果应用程序没有设置超时,则即使有作业耗时 2 小时或 2.5 小时才完成也无关紧要,只要今天完成即可。 此类别中的应用程序可能使用 P1 计算大小。 一个事实是,白天有几个时段的资源使用率较低,因此可充分利用这一点,将“大高峰”作业分配一部分到当天晚些时候的某个资源使用低谷。 只要作业可以每天按时完成,P1 计算大小就适用于该类型的应用程序(且节省费用)。
数据库引擎在每个逻辑服务器的 master 数据库的 sys.resource_stats 视图中,公开每个活动数据库的资源耗用信息。 视图中的数据以 5 分钟为间隔收集而得。 可能需要再耗费几分钟时间这些数据才会出现在视图中,以使 sys.resource_stats 更有利于历史分析而非接近实时的分析。 查询 sys.resource_stats 视图,以查看数据库的最近历史记录和验证你选择的计算大小是否提供了所需的性能。
注意
必须连接到 master 数据库,才能查询下面示例中的 sys.resource_stats。
此示例显示 sys.resource_stats 中的数据:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
下面的示例演示可以用不同方式使用 sys.resource_stats 目录视图,以获取有关数据库如何使用资源的信息:
要查看用户数据库
userdb1过去一周的资源使用情况,可以运行此查询,并替换你自己的数据库名称:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;若要评估工作负荷与计算大小的适合程度,需要向下钻取资源指标的每个方面:CPU、数据 I/O、日志写入、辅助角色数和会话数。 下面是一个经过修订的查询,使用
sys.resource_stats为已配置数据库的每个计算大小报告这些资源指标的平均值和最大值:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;使用每个资源指标的平均值和最大值信息,可以评估工作负荷与所选计算大小的适合程度。 通常情况下,
sys.resource_stats中的平均值可提供一个用于目标大小的良好基准。对于“DTU 购买模型”数据库:
例如,你可能正在使用 S2 计算大小的“标准”服务层级。 CPU 平均使用率和 I/O 读写百分比低于 40%,平均辅助进程数低于 50,平均会话数低于 200。 工作负荷可能适合 S1 计算大小。 很轻松就能判断数据库是否在辅助进程和会话限制范围内。 若要查看数据库是否适合更小的计算大小,请将更小计算大小的 DTU 数除以当前计算大小的 DTU 数,并将结果乘以 100:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40结果是以百分比表示的两个计算大小之间的相对性能差异。 如果资源使用不超出此百分比,则工作负荷可能适合更低的计算大小。 但是,需要查看资源用量值的所有范围,并按百分比确定数据库工作负荷适合更小计算大小的频率。 以下查询会根据以上示例计算得出的阈值 40%,输出每个资源维度的适合性百分比:
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;可以根据数据库服务层级的情况来确定工作负荷是否适合更小的计算大小。 如果数据库工作负荷目标为 99.9%,而上述查询针对所有三个资源维度返回的值大于 99.9%,则工作负荷可能适合更小的计算大小。
查看适合性百分比还可以深入分析是否应转到下一个更大的计算大小以满足目标。 例如,过去一周示例数据库的 CPU 使用率:
平均 CPU 百分比 最大 CPU 百分比 24.5 100.00 平均 CPU 大约是计算大小限制的四分之一,这意味着它很适合数据库的计算大小限制。
对于“DTU 购买模型”和“vCore 购买模型”数据库:
最大值显示该数据库达到了计算大小的限制。 在这种情况下,是否需要转到下一个更大的计算大小? 查看工作负荷达到 100% 的次数,并将这种情况与数据库工作负荷目标进行比较。
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;这些百分比是工作负载适合小于当前计算大小的样本数。 如果对于三个资源维度中的任何一个,此查询返回的值小于 99.9%,则表示采样的平均工作负载超出了限制。 请考虑转到下一个更大的计算大小,或使用应用程序优化技术减少数据库上的负载。
sys.dm_elastic_pool_resource_stats
与 sys.dm_db_resource_stats 类似,sys.dm_elastic_pool_resource_stats 为弹性池提供最新且精细的资源使用状况数据。 可以在弹性池中的任何数据库中查询该视图,以提供整个池的资源使用状况数据,而不是任何特定数据库的资源使用状况数据。 此 DMV 报告的百分比值接近弹性池的限制,该限制可能高于池中数据库的限制。
此示例显示当前弹性池在过去 15 分钟内的资源使用状况汇总数据:
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
如果发现任何资源使用率在相当长的一段时间内都接近 100%,则可能需要查看同一弹性池中各个数据库的资源使用状况,以确定每个数据库对池级资源使用状况的贡献量。
sys.elastic_pool_resource_stats
与 sys.resource_stats 类似,master 数据库中的 sys.elastic_pool_resource_stats 提供逻辑服务器上所有弹性池的资源使用状况历史数据。 sys.elastic_pool_resource_stats 可用于过去 14 天内的历史监视,包括使用情况趋势分析。
此示例显示当前逻辑服务器上的所有弹性池在过去七天内汇总的资源使用状况数据。 在 master 数据库中执行查询。
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
并发请求
要查看当前并发请求数,请对用户数据库运行以下查询:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
这只是某一时刻的快照。 若要更好地了解工作负荷和并发请求需求,需在一定时间内收集多个样本。
平均请求速率
此示例演示如何查找数据库或弹性池中的数据库在一段时间内的平均请求率。 在此示例中,时间段设置为 30 秒。 可以通过修改 WAITFOR DELAY 语句来调整。 在用户数据库中执行此查询。 如果数据库位于弹性池中并且你拥有足够的权限,则结果将包括弹性池中的其他数据库。
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
当前会话
要查看当前的活动会话数,请在数据库中运行以下查询:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
此查询会返回时间点计数。 如果在一段时间内收集多个样本,则可更好地了解会话使用情况。
请求、会话和辅助角色的最近历史记录
此示例返回数据库或弹性池中的数据库的请求、会话和工作线程的最近历史使用情况。 每行代表数据库在某个时间点的资源使用状况的快照。 requests_per_second 列是在 snapshot_time 结束的时间间隔内的平均请求速率。 如果数据库位于弹性池中并且你拥有足够的权限,则结果将包括弹性池中的其他数据库。
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST(wg.delta_request_count AS decimal) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
计算数据库和对象大小
下面的查询将返回数据库的数据大小(以 MB 为单位):
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
下面的查询将返回数据库中各个对象的大小(以 MB 为单位):
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
识别 CPU 性能问题
本部分可帮助你识别消耗 CPU 最多的查询。
如果长时间的 CPU 消耗超过 80%,请考虑以下故障排除步骤,无论是正在发生 CPU 问题还是过去发生了 CPU 问题。 还可以按照本部分中的步骤主动识别消耗 CPU 最多的查询并对其进行优化。 在某些情况下,降低 CPU 消耗可能会缩小数据库和弹性池的规模并节省成本。
对于独立数据库和弹性池中的数据库,故障排除步骤是相同的。 在用户数据库中执行所有查询。
目前正在发生 CPU 问题
如果目前已出现问题,则可能存在两种情况:
存在许多单独的查询,它们共同消耗了很多的 CPU 资源
使用以下查询,通过查询哈希来识别消耗 CPU 较高的查询:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() runtime, *
FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
消耗 CPU 的长时间运行的查询仍在运行
使用以下查询来识别这些查询:
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
过去发生了 CPU 问题
如果问题是在过去发生的,你想要执行根本原因分析,请使用查询存储。 拥有数据库访问权限的用户可以使用 T-SQL 对查询存储数据执行查询。 默认情况下,查询存储捕获一小时间隔内的聚合查询统计信息。
使用以下查询来查看 CPU 消耗量较高的查询的活动。 此查询将返回 CPU 消耗量最高的 15 个查询。 请记得更改
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE(),以查看过去两个小时以外的时间段的 CPU 消耗量:-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;识别出有问题的查询后,可以优化这些查询,以降低 CPU 利用率。 或者,可以选择增加数据库或弹性池的计算大小,以解决此问题。
有关在 Azure SQL 数据库中处理 CPU 性能问题的更多信息,请参阅诊断和排查 Azure SQL 数据库上 CPU 使用率过高的问题。
识别 I/O 性能问题
识别存储输入/输出 (I/O) 性能问题时,排名靠前的等待类型为:
PAGEIOLATCH_*数据文件 I/O 问题(包括
PAGEIOLATCH_SH、PAGEIOLATCH_EX、PAGEIOLATCH_UP。 如果等待类型名称中包含 IO,则此类型与某个 I/O 问题相关。 如果页面闩锁等待名称中不包含 IO,则表明存在与存储性能无关的不同类型的问题(例如tempdb争用)。WRITE_LOG事务日志 I/O 问题。
如果目前已经出现了 I/O 问题
使用 sys.dm_exec_requests 或 sys.dm_os_waiting_tasks 查看 wait_type 和 wait_time。
识别数据和日志 I/O 用量
使用以下查询来识别数据和日志 I/O 用量。
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
有关使用 sys.dm_db_resource_stats 的更多示例,请参阅本文后面的监视资源使用情况部分。
如果已达到 I/O 限制,可使用两种选项:
- 升级计算大小或服务层级
- 识别并优化 I/O 消耗量最大的查询。
使用查询存储查看缓冲区相关的 I/O
要通过 I/O 相关等待来识别消耗量较大的查询,可以使用以下查询存储查询来查看过去两个小时的跟踪活动:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
还可以使用 sys.query_store_runtime_stats 视图,重点关注 avg_physical_io_reads 和 avg_num_physical_io_reads 列中包含较大值的查询。
查看 WRITELOG 等待类型的日志 I/O 总计
如果等待类型为 WRITELOG,请使用以下查询按语句查看日志 I/O 总计:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
识别 tempdb 性能问题
与 tempdb 问题相关的常见等待类型是 PAGELATCH_*(不是 PAGEIOLATCH_*)。 但是,出现 PAGELATCH_* 等待并不总是意味着发生了 tempdb 争用。 这种等待可能还意味着,由于并发请求面向相同的数据页面,发生了用户对象数据页面争用。 若要进一步确认 tempdb 争用,请使用 sys.dm_exec_requests 确认 wait_resource 值是否以 2:x:y 开头,其中 2 tempdb 是数据库 ID,x 是文件 ID,y 是页面 ID。
对于 tempdb 争用,常用的方法是减少或重写依赖于 tempdb 的应用程序代码。 常见的 tempdb 使用区域包括:
- 临时表
- 表变量
- 表值参数
- 包含使用排序、哈希联接和 spool 的查询计划的查询
有关详细信息,请参阅 Azure SQL 中的 tempdb。
弹性池中的所有数据库共享同一个 tempdb 数据库。 一个数据库的 tempdb 空间利用率较高,可能会影响同一弹性池中的其他数据库。
使用表变量和临时表的最相关查询
使用以下查询来识别使用表变量和临时表的最相关查询:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
识别长时间运行的事务
使用以下查询来识别长时间运行的事务。 长时间运行的事务会阻止持久版本存储 (PVS) 的清理。 有关详细信息,请参阅排查加速数据库恢复问题。
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
识别内存授予等待性能问题
如果排名靠前的等待类型是 RESOURCE_SEMAPHORE,则可能有内存授予等待问题,即查询在获得足够大的内存授予之前无法开始执行。
确定 RESOURCE_SEMAPHORE 等待是否为排名靠前的等待
使用以下查询来确定 RESOURCE_SEMAPHORE 等待是否为排名靠前的等待。 也表明在最近的历史记录中,RESOURCE_SEMAPHORE 的等待时间排名在上升。 有关排查内存授予等待问题的详细信息,请参阅排查 SQL Server 中内存授予导致的性能缓慢或内存不足问题。
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
识别内存消耗量较高的语句
如果在 Azure SQL 数据库中遇到内存不足错误,请查看 sys.dm_os_out_of_memory_events。 有关详细信息,请参阅排查 Azure SQL 数据库的内存不足错误。
首先,修改以下脚本以更新 start_time 和 end_time 的相关值。 然后,运行以下查询以识别内存消耗量较高的语句:
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
识别最活跃的 10 个内存授予
使用以下查询来识别最活跃的 10 个内存授予:
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
监视连接
可以使用 sys.Dm_exec_connections 视图,检索与特定数据库建立的连接有关的信息,以及每个连接的详细信息。 如果数据库位于弹性池中并且你拥有足够的权限,则该视图将返回弹性池中所有数据库的连接集。 此外,sys.dm_exec_sessions 视图在检索有关所有活动用户连接和内部任务的信息时非常有用。
查看当前会话
以下查询检索当前连接和会话的信息。 要查看所有连接和会话,请删除 WHERE 子句。
执行 VIEW DATABASE STATE 和 sys.dm_exec_requests 视图时,只有当你对数据库具有 sys.dm_exec_sessions 权限时,你才能看到数据库中所有正在执行的会话。 否则,只能看到当前会话。
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
监视查询性能
缓慢或长时间运行的查询会消耗大量系统资源。 本部分演示如何使用动态管理视图,通过 sys.dm_exec_query_stats 动态管理视图来检测一些常见的查询性能问题。 缓存计划中的每个查询语句在该视图中对应一行,并且行的生存期与计划本身相关联。 在从缓存删除计划时,也将从该视图中删除对应行。 如果查询没有缓存计划,例如因为使用了 OPTION (RECOMPILE),则该计划不会出现在此视图的结果中。
按 CPU 时间查找排名靠前的查询
下例返回了按每次执行的平均 CPU 时间排名的前 15 个查询的信息。 该示例根据查询散列收集了查询,以便逻辑上等值的查询能够根据累积资源消耗分组。
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
监视查询计划的累积 CPU 时间
低效的查询计划还可能会增加 CPU 占用率。 下例确定在最近的历史记录中哪个查询使用的 CPU 时间累计最长。
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
监视被阻止的查询
缓慢或长时间运行的查询会造成过多的资源消耗并会导致查询受阻。 受阻的原因可能是应用程序设计欠佳、查询计划不良、缺乏有用的索引等。
你可以使用 sys.dm_tran_locks 视图获取有关数据库中当前锁定的活动的信息。 有关代码示例,请参阅 sys.dm_tran_locks。 有关故障排除阻塞的详细信息,请参阅了解并解决 Azure SQL 阻塞问题。
监视死锁
在某些情况下,两个或多个查询可能会相互阻止,从而导致死锁。
可以创建扩展事件跟踪以捕获死锁事件,然后在查询存储中查找相关查询及其执行计划。 有关详细信息,请参阅分析和防止 Azure SQL 数据库中的死锁,包括导致 AdventureWorksLT 中出现死锁的实验室。 详细了解可能出现死锁的资源的类型。
相关内容
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈