你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure 机器学习作为云规模分析的数据产品
Azure 机器学习是一个集成平台,用于从头到尾管理机器学习生命周期,包括帮助创建、操作和使用机器学习模型和工作流。 该服务的一些优势包括:
一些功能通过帮助创作者管理试验、访问数据、跟踪作业、调整超参数和自动执行工作流,支持创作者提高工作效率。
要解释、重现、审核以及与 DevOps 集成的模型功能,再加上丰富的安全控制模型,可支持操作员满足治理和合规性要求。
托管推理功能以及与 Azure 计算和数据服务的可靠集成可帮助简化服务的使用方式。
Azure 机器学习涵盖了数据科学生命周期的各个方面。 它涵盖了数据存储以及向模型部署进行的数据集注册。 它可用于从经典机器学习到深度学习的任何类型的机器学习。 包括监督式和非监督式学习。 无论你是希望编写 Python、R 代码还是使用零代码或低代码选项(如设计器),你都可以在 Azure 机器学习工作区中构建、训练和跟踪非常准确的机器学习和深度学习模型。
Azure 机器学习、Azure 平台和 Azure AI 服务可以协同工作来管理机器学习生命周期。 机器学习实践者可以使用 Azure Synapse Analytics、Azure SQL 数据库或 Microsoft Power BI 开始分析数据并转换到 Azure 机器学习,以制作原型、管理试验和进行操作。 在 Azure 登陆区域,Azure 机器学习可被视为数据产品。
云规模分析中的 Azure 机器学习
云采用框架 (CAF) 登陆区域基础、云规模分析数据登陆区域和 Azure 机器学习的配置为机器学习专业人员设置了一个预配置的环境,他们可向其中重复部署新的机器学习工作负载或迁移现有工作负载。 这些功能可帮助机器学习专业人员获得更大的灵活性和时间价值。
以下设计原则可指导实现 Azure 机器学习 Azure 登陆区域:
加速数据访问:将登陆区域存储组件预配置为 Azure 机器学习工作区中的数据存储。
启用协作:按项目组织工作区,并集中管理对登陆区域资源的访问,以支持数据工程、数据科学和机器学习专业人员协同工作。
安全实现:作为每个部署的默认设置,遵循最佳做法,并使用网络隔离、标识和访问管理来保护数据资产。
自助服务:机器学习专业人员可以通过探索用于部署新项目资源的选项,获得更大的灵活性和组织性。
数据管理和数据使用之间的关注点分离:标识传递是 Azure 机器学习和存储的默认身份验证类型。
更快的数据应用程序(源对齐):Azure 数据工厂、Azure Synapse Analytics 和 Databricks 登陆区域可以预配置为链接到 Azure 机器学习。
可观测性:中心日志记录和引用配置可帮助监视环境。
实现概述
注意
本部分建议特定于云规模分析的配置。 它对 Azure 机器学习文档和云采用框架最佳做法进行了补充。
工作区组织和设置
你可以为部署的每个登陆区域部署工作负载所需的机器学习工作区数。 以下建议可帮助进行设置:
每个项目部署至少一个机器学习工作区。
根据机器学习项目的生命周期,部署一个开发 (dev) 工作区来制作用例的原型,并尽早探索数据。 对于需要持续试验、测试和部署的工作,请部署一个暂存和生产工作区。
当数据登陆区域中的开发、暂存和生产工作区需要多个环境时,建议将每个环境登陆到同一生产数据登陆区域,以避免数据重复。
请参阅组织和设置 Azure 机器学习环境,详细了解如何组织和设置 Azure 机器学习资源。
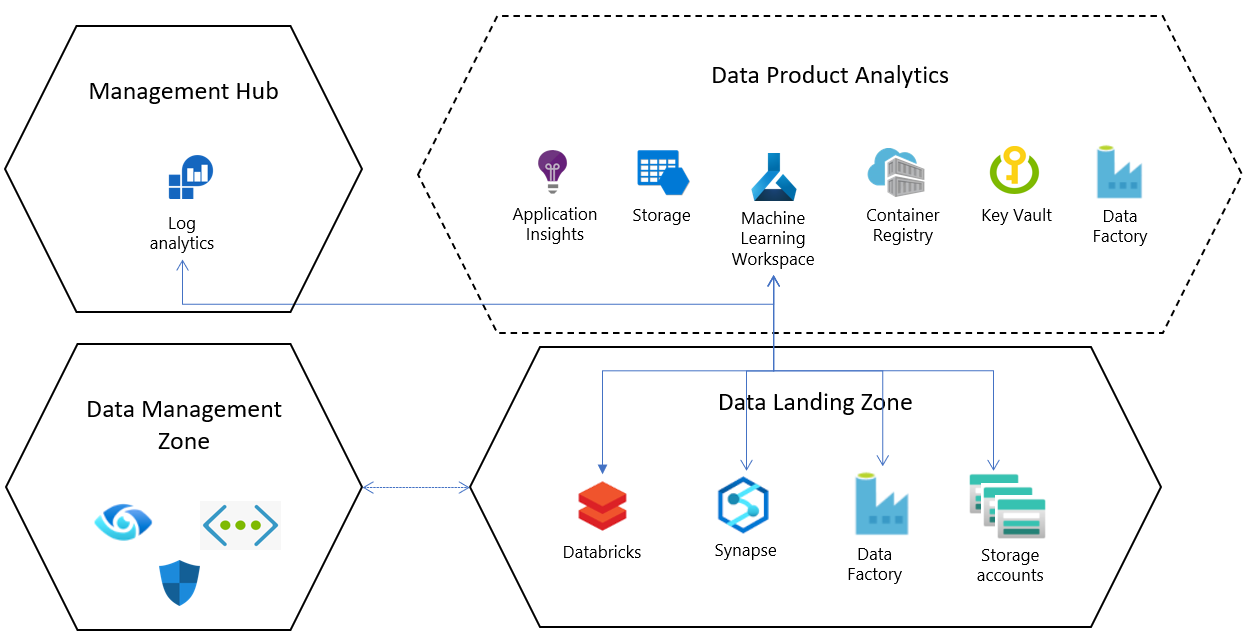
对于数据登陆区域中的每个默认资源配置,Azure 机器学习服务部署在具有以下配置和相关资源的专用资源组中:
- Azure Key Vault
- Application Insights
- Azure 容器注册表
- 使用Azure 机器学习连接到Azure 存储帐户和基于 Microsoft Entra 标识的身份验证,以帮助用户连接到该帐户。
- 为每个工作区设置诊断日志记录,并将诊断日志记录配置为企业级的 Log Analytics 中心资源;这可以帮助在登陆区域之中或之间集中分析 Azure 机器学习作业运行状况和资源状态。
- 请参阅什么是 Azure 机器学习工作区?,详细了解 Azure 机器学习资源和依赖项。
与数据登陆区域核心服务集成
数据登陆区域附带在核心服务层中部署的一组默认服务。 在数据登陆区域中部署 Azure 机器学习时,可以配置这些核心服务。
将 Azure Synapse Analytics 或 Databricks 工作区连接为链接服务,以集成数据和处理大数据。
默认情况下,数据湖服务在数据登陆区域中预配,Azure 机器学习产品部署附带预配置到这些存储帐户的连接(数据存储)。
网络连接
用于在 Azure 登陆区域中实现 Azure 机器学习的网络是根据 Azure 机器学习的安全最佳做法和 CAF 网络最佳做法设置的。 这些最佳做法包括以下配置:
- Azure 机器学习和相关资源配置为使用专用链接终结点。
- 托管计算资源仅使用专用 IP 地址进行部署。
- 可以在网络级别配置与 Azure 机器学习公共基础映像存储库和合作伙伴服务(如 Azure Artifacts)的网络连接。
标识和访问管理
请考虑以下有关使用 Azure 机器学习管理用户标识和访问的建议:
可以将 Azure 机器学习中的数据存储配置为使用基于凭据或标识的身份验证。 在 Azure Data Lake Storage Gen2 中使用访问控制和数据湖配置时,请将数据存储配置为使用基于标识的身份验证;这使 Azure 机器学习能够优化用户对存储的访问权限。
使用 Microsoft Entra 组管理存储和机器学习资源的用户权限。
Azure 机器学习可使用用户分配的托管标识进行访问控制,并限制对 Azure 容器注册表、Key Vault、Azure 存储和 Application Insights 的访问范围。
为在 Azure 机器学习中创建的托管计算群集创建用户分配的托管标识。
通过自助服务预配基础结构
可以使用 Azure 机器学习策略启用和治理自助服务。 下表列出了部署 Azure 机器学习时的一组默认策略。 有关详细信息,请参阅 Azure 机器学习的 Azure Policy 内置策略定义。
| 策略 | 类型 | 参考 |
|---|---|---|
| Azure 机器学习工作区应使用 Azure 专用链接。 | 内置 | 在 Azure 门户中查看 |
| Azure 机器学习工作区应使用用户分配的托管标识。 | 内置 | 在 Azure 门户中查看 |
| [预览版]:为指定的 Azure 机器学习计算配置允许的注册表。 | 内置 | 在 Azure 门户中查看 |
| 为 Azure 机器学习工作区配置专用终结点。 | 内置 | 在 Azure 门户中查看 |
| 配置机器学习计算以禁用本地身份验证方法。 | 内置 | 在 Azure 门户中查看 |
| Append-machinelearningcompute-setupscriptscreationscript | 自定义(CAF 登陆区域) | 在 GitHub 上查看 |
| Deny-machinelearning-hbiworkspace | 自定义(CAF 登陆区域) | 在 GitHub 上查看 |
| Deny-machinelearning-publicaccesswhenbehindvnet | 自定义(CAF 登陆区域) | 在 GitHub 上查看 |
| Deny-machinelearning-AKS | 自定义(CAF 登陆区域) | 在 GitHub 上查看 |
| Deny-machinelearningcompute-subnetid | 自定义(CAF 登陆区域) | 在 GitHub 上查看 |
| Deny-machinelearningcompute-vmsize | 自定义(CAF 登陆区域) | 在 GitHub 上查看 |
| Deny-machinelearningcomputecluster-remoteloginportpublicaccess | 自定义(CAF 登陆区域) | 在 GitHub 上查看 |
| Deny-machinelearningcomputecluster-scale | 自定义(CAF 登陆区域) | 在 GitHub 上查看 |
管理环境的建议
云规模分析数据登陆区域概述了可重复部署的引用实现,有助于设置可管理和可治理的环境。 请考虑以下有关使用 Azure 机器学习来管理环境的建议:
使用 Microsoft Entra 组管理对机器学习资源的访问权限。
发布中央监视仪表板,以监视机器学习的管道运行状况、计算利用率和配额管理。
如果传统上使用内置 Azure 策略,并且需要满足其他合规性要求,请构建自定义 Azure 策略以增强治理和自助服务。
若要跟踪研发成本,在探索用例的早期阶段,在登陆区域中部署一个机器学习工作区作为共享资源。
重要
将 Azure 机器学习群集用于生产级模型训练,将 Azure Kubernetes 服务 (AKS) 用于生产级部署。
提示
将 Azure 机器学习用于数据科学项目。 它涵盖了包含子服务和功能的端到端工作流,并使流程能够实现完全自动化。
后续步骤
使用 Data Product Analytics 模板和指南部署 Azure 机器学习,并参考 Azure 机器学习文档和教程以开始构建解决方案。
继续阅读以下四篇云采用框架文章,详细了解适用于企业的 Azure 机器学习部署和管理最佳做法:
组织和设置 Azure 机器学习环境:在计划 Azure 机器学习部署时,团队结构、环境或资源地理位置如何影响工作区的设置方式?
用于实现企业安全性的 Azure 机器学习最佳做法:了解如何使用 Azure 机器学习来保护环境和资源。
在组织规模管理 Azure 机器学习的预算、成本和配额:在管理 Azure 机器学习所产生的工作负载、团队和用户计算成本时,组织面临许多管理和优化挑战。
机器学习 DevOps 指南:机器学习 DevOps 是一种组织变革,它依赖于人员、流程和技术的结合,以可靠、可缩放、可信赖和自动化的方式提供机器学习解决方案。 本指南总结了供企业使用 Azure 机器学习采用机器学习 DevOps 的最佳做法和信息。