你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
答案的置信度分数
如果用户查询的匹配依据为知识库,QnA Maker 会返回相关答案和置信度分数。 此分数指明了答案是给定用户查询的正确匹配答案的置信度。
置信度分数是介于 0 和 100 之间的数字。 100 分表明很可能是完全匹配,而 0 分则表明找不到匹配答案。 分数越高,答案的置信度就越大。 对于给定查询,可能会返回多个答案。 在这种情况下,答案按置信度分数降序顺序返回。
在下面的示例中,可以看到一个 QnA 实体包含 2 个问题。

对于上面的示例,不同类型用户查询的置信度分数介于如下示例分数范围内:
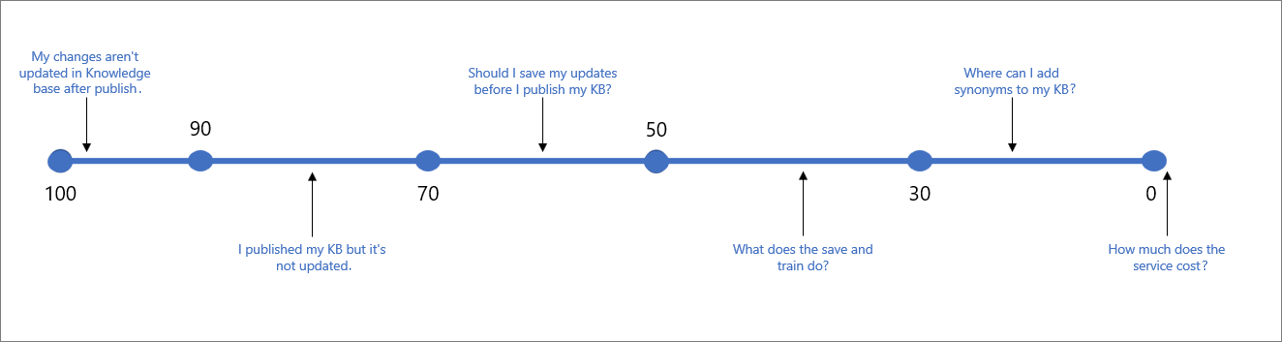
下表指明了与给定分数关联的典型置信度。
| 分数值 | 分数含义 | 示例查询 |
|---|---|---|
| 90 - 100 | 与用户查询和知识库问题几乎完全匹配 | “我的更改并未在发布后的知识库中更新” |
| > 70 | 高置信度 - 通常是能够完全回答用户查询的合理答案 | “我已发布我的知识库,但它并未更新” |
| 50 - 70 | 中等置信度 - 通常是应该能回答用户查询的主要意向的较合理答案 | “我是否应在发布知识库前保存我的更新?” |
| 30 - 50 | 低置信度 - 通常是部分回答用户意向的相关答案 | “保存和定型有何作用?” |
| < 30 | 极低置信度 - 通常未回答用户查询,但有一些匹配字词或短语 | “我可以在哪里将同义词添加到我的知识库” |
| 0 | 无匹配,因此未返回任何答案。 | “服务费用是多少” |
选择分数阈值
上表指明了大多数知识库上应该会出现的分数。 不过,由于每个知识库都不同,它们具有不同类型的字词、意向和目标,因此建议测试并选择最适合自己的阈值。 默认情况下,阈值设置为 0,以便返回所有可能的答案。 建议为大多数知识库使用阈值 50。
选择阈值时,请务必平衡“准确度”和“覆盖率”,并根据自己的需求来调整阈值。
如果“准确度”(或精准率)对方案更为重要,请提高阈值。 这样,每次返回的答案的置信度都会更高,且更有可能就是用户所要找的答案。 在这种情况下,最终可能会导致更多问题没有答案。 例如,如果将阈值设置为 70,可能会错过一些含糊不清的示例(例如,“什么是保存和定型?”)。
如果“覆盖率”(或召回率)更为重要,且希望尽可能多地回答问题(即使答案与用户问题仅部分相关,也不例外),请降低阈值。 也就是说,可能会更多出现以下情况:答案并未回答用户实际查询,而是提供了其他一些相关答案。 例如:如果将阈值设置为 30,可以为“我可以在哪里编辑知识库?”这类查询提供回答
设置阈值
将阈值分数设置为 GenerateAnswer API JSON 主体的属性。 这意味着要为每次 GenerateAnswer 调用设置该分数。
在机器人框架中,使用 C# 或 Node.js 将分数设置为 options 对象的一部分。
提高置信度分数
若要提高对用户查询的特定响应的置信度分数,可以将用户查询添加到知识库,作为该响应的备用问题。 还可以使用区分大小写的字变更向知识库中的关键字添加同义词。
相似的置信度分数
当多个响应具有相似的置信度分数时,查询很可能过于通用,因此与多个答案匹配的可能性都相同。 尝试更好地构建 QnA,以便每个 QnA 实体都有不同的意向。
测试与生产的置信度分数差异
即使内容相同,答案的置信度分数在知识库的测试版和发布版之间也可能有微不足道的差异。 这是因为测试知识库和已发布知识库的内容位于不同的 Azure AI 搜索索引中。
测试索引保存知识库的所有 QnA 对。 查询测试索引时,查询应用于整个索引,然后结果限制为该特定知识库的分区。 如果测试查询结果对验证知识库的能力产生负面影响,可以:
- 使用以下某一项来组织知识库:
- 限制为 1 KB 的 1 个资源:将单个 QnA 资源(以及生成的 Azure AI 搜索测试索引)限制为单个知识库。
- 2 个资源 - 1 个用于测试,1 个用于生产:有两个 QnA Maker 资源,一个用于测试(具有自己的测试和生产索引),另一个用于产品(也具有自己的测试和生产索引)
- 在查询测试和生产知识库时,始终使用相同的参数,例如 top
发布知识库时,知识库的问答内容将从测试索引转移到 Azure 搜索中的生产索引。 请参阅发布操作的工作原理。
如果不同区域都有知识库,则每个区域都使用自己的 Azure AI 搜索索引。 因为使用的索引不同,所以得分并不完全相同。
找不到匹配项
当排名程序找不到良好匹配时,将返回置信度分数 0.0 或“None”,并且默认响应为“在知识库中找不到良好匹配”。 可以在调用终结点的机器人或应用程序代码中重写此默认响应。 或者,也可以在 Azure 中设置重写响应,这将更改在特定 QnA Maker 服务中部署的所有知识库的默认值。