你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用于初学者的自定义翻译器
自定义翻译器可让你构建反映业务、行业和领域特定术语和风格的翻译系统。 训练和部署自定义系统很简单,不需要任何编程技能。 自定义翻译系统无缝集成到现有应用程序、工作流和网站中,并通过同样基于云的 Microsoft 文本翻译 API 服务(该服务支持每天数十亿次的翻译)在 Azure 上可用。
该平台使用户能够生成并发布自定义英语翻译系统。 自定义翻译器支持 60 多种语言,这些语言可以直接映射到适用于 NMT 的语言。 有关完整列表,请参阅翻译工具语言支持。
自定义翻译模型是否适合我?
训练有素的自定义翻译模型可以提供更准确的特定领域的翻译,因为它依赖于以前翻译的领域内文档来学习首选翻译。 翻译器在语境中使用这些术语和短语,在遵循语境语法的同时,以目标语言生成流畅的翻译。
训练一个完整的自定义翻译模型需要大量的数据。 如果你没有包含至少 10,000 个句子的已经过训练的文档,将无法训练完整语言翻译模型。 但是,可以训练只使用字典的模型,或使用文本翻译 API 提供的高质量的现成的翻译。
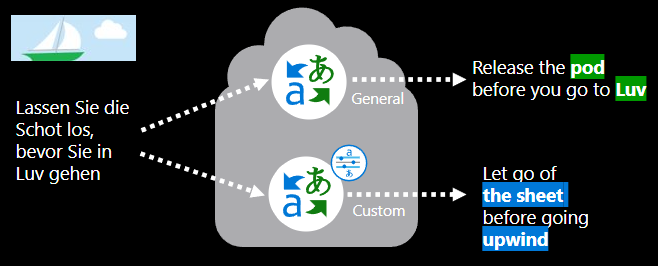
训练自定义翻译模型涉及哪些内容?
构建自定义翻译模型需要:
了解用例。
获取领域内翻译数据(最好是人工翻译)。
能够评估翻译质量或目标语言翻译。
如何评估我的用例?
明确用例和成功的标准是获取专业训练数据的第一步。 以下是一些注意事项:
所需的结果是什么?如何衡量它?
你的业务领域是什么?
你是否具有类似术语和风格的领域内句子?
用例是否涉及多个领域? 如果是,你应该构建一个翻译系统还是多个系统?
你是否有影响静态和传输中区域数据驻留的要求?
目标用户是在一个还是多个区域?
如何获取数据?
查找领域内的高质量数据通常是一项极具挑战性的任务,它因用户分类而异。 以下是一些你在评估可能获得的数据时可以问自己的问题:
企业在使用人工翻译的过程中,往往积累了大量的翻译数据。 贵公司是否有可供使用的过往的翻译数据?
你是否有大量的单语数据? 单语数据是指只使用一种语言的数据。 如果有,你能得到这些数据的翻译吗?
是否可以抓取门户来收集源句子并合成目标句子?
应该将哪些内容用做训练材料?
| 源 | 作用 | 遵循的规则 |
|---|---|---|
| 双语训练文档 | 告知系统你的术语和风格。 | 解放思想。 任何领域内的人工翻译都比机器翻译好。 根据你的需要添加和删除文档,尝试提高 BLEU 分数。 |
| 优化文档 | 训练神经机器翻译参数。 | 严格要求。 在编写它们时充分体现你将来要翻译的内容。 |
| 测试文档 | 计算 BLEU 分数。 | 严格要求。 编写测试文档,使其能以最佳方式表示你将来计划翻译的内容。 |
| 短语字典 | 强制执行给定的翻译 100% 的时间。 | 施加限制。 短语词典区分大小写,任何列出的单词或短语都按照你指定的方式进行翻译。 在许多情况下,最好不使用短语字典,而是让系统自己学习。 |
| 句子字典 | 强制执行给定的翻译 100% 的时间。 | 严格要求。 句子词典不区分大小写,适用于常见的领域内的短句子。 若要进行句子字典匹配,提交的整个句子必须与源字典条目匹配。 如果只是句子的一部分匹配,则该条目不匹配。 |
什么是 BLEU 分数?
BLEU(双语评估替补)是一种算法,用于评估从一种语言机器翻译成另一种语言的文本的精确度或准确性。 自定义翻译器使用 BLEU 指标作为传达翻译准确性的一种方式。
BLEU 分数是一个 0 到 100 之间的数字。 0 分表示翻译质量低,翻译中没有任何内容与参考匹配。 100 分表示翻译与参考完全一致。 不需要达到 100 分 - BLEU 分数在 40 到 60 之间表明翻译质量高。
如果不提交优化或测试数据,会发生什么情况?
优化和测试句子以最佳方式代表你将来计划翻译的内容。 如果未提交任何优化或测试数据,自定义翻译器会自动从训练文档中排除句子,以用作优化和测试数据。
| 由系统生成 | 手动选择 |
|---|---|
| 方便。 | 可以针对未来的需求进行微调。 |
| 好的,如果你知道训练数据代表你计划翻译的内容。 | 请更自由地编写训练数据。 |
| 在扩大或缩小领域时,易于重做。 | 允许更多数据和更好的领域覆盖。 |
| 更改每个训练运行。 | 在重复的训练运行中保持静态 |
自定义翻译器如何处理训练材料?
要为训练做准备,文档需要经过一系列处理和筛选步骤。 这些步骤会在下面进行介绍。 了解筛选过程有助于了解显示的句子计数,以及可以采取的步骤,以准备训练自定义翻译器的文档。
句子对齐
如果文档不是 XLIFF、XLSX、TMX 或 ALIGN 格式,则自定义翻译器会将源文档和目标文档的句子一句句地互相对齐。 翻译器并不执行文档对齐操作,而是根据文档的命名约定找出另一语言的匹配文档。 在源文本中,自定义翻译器会尝试找出目标语言的相应句子。 它使用类似于嵌入式 HTML 标记的文档标记来帮助进行对齐。
如果发现源文档和目标文档中的句子数量有很大的差异,则源文档可能不是平行的或不能对齐。 如果文档配对时每侧的句子存在大的差异 (>10%),则必须再次进行查看,确保这些句子确实已对齐。
提取优化和测试数据
优化和测试数据是可选的。 如果未提供,系统将从训练文档中删除适当的百分比,用于调优和测试。 删除操作在训练过程中动态进行。 由于此步骤是训练的一部分,因此上传的文档不受影响。 训练成功后,可以在“模型详细信息”页上查看每个数据类别(训练、优化、测试和字典)的最终已用句子计数。
长度筛选器
- 删除任意一侧只有一个单词的句子。
- 删除任意一侧的包含 100 多个单词的句子。 中文、日语和朝鲜语除外。
- 删除少于三个字符的句子。 中文、日语和朝鲜语除外。
- 删除中文、日语、朝鲜语中超出 2000 个字符的句子。
- 删除字母数字字符少于 1% 的句子。
- 删除包含 50 多个单词的字典条目。
空格
- 将任何序列的空格字符(包括制表符和 CR/LF 序列)替换为单个空格的字符。
- 删除句子中的前导或尾随空格。
句末标点
将多个句末标点字符替换为单个实例。 日语字符规范化。
将全角字母和数字转换为半角字符。
非转义的 XML 标记
筛选会将非转义的标记转换为转义的标记:
标记 将变为 < < > > & & 无效字符
自定义翻译器会删除包含 Unicode 字符 U+FFFD 的句子。 字符 U+FFFD 表示编码转换失败。
上传数据之前应执行哪些步骤?
- 删除编码无效的句子。
- 删除 Unicode 控制字符。
- 如果可行,将句子对齐(源到目标)。
- 删除与源和目标语言不匹配的源句子和目标句子。
- 当源句子和目标句子使用混合语言时,请确保有意使用未翻译的单词,例如组织和产品的名称。
- 更正语法和版式错误,防止向模型教授这些错误。
- 虽然训练过程处理包含多个句子的源行和目标行,但最好将一个源句子映射到一个目标句子。
如何评估结果?
模型训练成功后,可以在模型详细信息页上查看 BLEU 评分和基线模型 BLEU 评分。 我们使用同一组测试数据来生成模型的 BLEU 分数和基线 BLEU 分数。 此数据将帮助你做出明智的决策,确定哪种模型更适合你的用例。