你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn 。
快速入门:安装语音 SDK
本文内容
参考文档 | 包 (NuGet) | GitHub 上的其他示例
在本快速入门中,我们安装适用于 C# 的语音 SDK 。
文档中的代码示例以 C# 8 编写,并在 .NET standard 2.0 上运行。
适用于 C# 的语音 SDK 与 Windows、Linux 和 macOS 兼容。
注意
本文引用了 CentOS,这是一个接近生命周期结束 (EOL) 状态的 Linux 发行版。 请相应地考虑你的使用和规划。 有关详细信息,请参阅 CentOS 生命周期结束指南 。
适用于 C# 的语音 SDK 仅支持 x64、ARM32 (Debian/Ubuntu) 和 ARM64 (Debian/Ubuntu) 架构上的以下发行版:
Ubuntu 18.04/20.04
Debian 10/11
Red Hat Enterprise Linux (RHEL) 7/8
CentOS 7
重要
使用 Linux 分发版的最新 LTS 版本。 例如,如果使用 Ubuntu 20.04 LTS,请使用最新版本的 Ubuntu 20.04.X。
语音 SDK 依赖于以下 Linux 系统库:
GNU C 库的共享库(包括 POSIX 线程编程库 libpthreads)。
OpenSSL 库 (libssl) 版本 1.x 和证书 (ca-certificates)。
ALSA 应用程序的共享库 (libasound)。
还应安装 ca-certificates 以建立安全的 Websocket 并避免此 WS_OPEN_ERROR_UNDERLYING_IO_OPEN_FAILED 错误。
重要
语音 SDK 尚不支持 OpenSSL 3.0(Ubuntu 22.04 和 Debian 12 中的默认版本)。
运行以下 命令:
sudo apt-get update
sudo apt-get install build-essential libssl-dev ca-certificates libasound2 wget
若要在 Alpine Linux 中使用语音 SDK,请按照 Alpine Linux Wiki 中的运行 glibc 程序 所述创建 Debian chroot 环境。 然后按照此处的 Debian 说明操作。
sudo apt-get update
sudo apt-get install build-essential libssl-dev ca-certificates libasound2 wget
注意
本文引用了 CentOS,这是一个接近生命周期结束 (EOL) 状态的 Linux 发行版。 请相应地考虑你的使用和规划。 有关详细信息,请参阅 CentOS 生命周期结束指南 。
安装开发工具和库:
sudo yum update
sudo yum groupinstall "Development tools"
sudo yum install alsa-lib openssl wget
安装适用于 C# 的语音 SDK
适用于 C# 的语音 SDK 以 NuGet 包的形式提供并实现了 .NET Standard 2.0。 有关详细信息,请参阅 Microsoft.CognitiveServices.Speech 。
可以使用以下 dotnet add 命令从 .NET Core CLI 安装适用于 C# 的语音 SDK:
dotnet add package Microsoft.CognitiveServices.Speech
可以使用以下 Install-Package 命令安装适用于 C# 的语音 SDK:
Install-Package Microsoft.CognitiveServices.Speech
可以按照这些指南获取更多选项。
本指南介绍如何安装用于 .NET Framework (Windows) 控制台应用的语音 SDK 。
本指南需要:
创建 Visual Studio 项目并安装语音 SDK
需安装语音 SDK NuGet 包 ,以便在代码中引用它。 为此,可能首先需要创建 helloworld 项目。 如果已经有一个可以使用“.NET 桌面开发”工作负荷的项目,则可使用该项目并跳到使用 NuGet 包管理器安装语音 SDK 。
创建 helloworld 项目
打开 Visual Studio。
在“开始”下,选择“创建新项目”
在“创建新项目”中,选择“控制台应用(.NET Framework)”,然后选择“下一步” 。
在“配置新项目”中,为“项目名称”输入 helloworld,在“位置”中选择或创建目录路径,然后选择“创建”
从 Visual Studio 菜单栏中,选择“工具”>“获取工具和功能”。 此步骤会打开 Visual Studio 安装程序并显示“修改 ”对话框。
检查“.NET 桌面开发”工作负荷是否可用。 如果未安装工作负载,请选择它,然后选择“修改”以启动安装
如果已选中“.NET 桌面开发 ”,请选择“关闭 ”关闭该对话框。
关闭 Visual Studio 安装程序。
使用 NuGet 包管理器安装语音 SDK
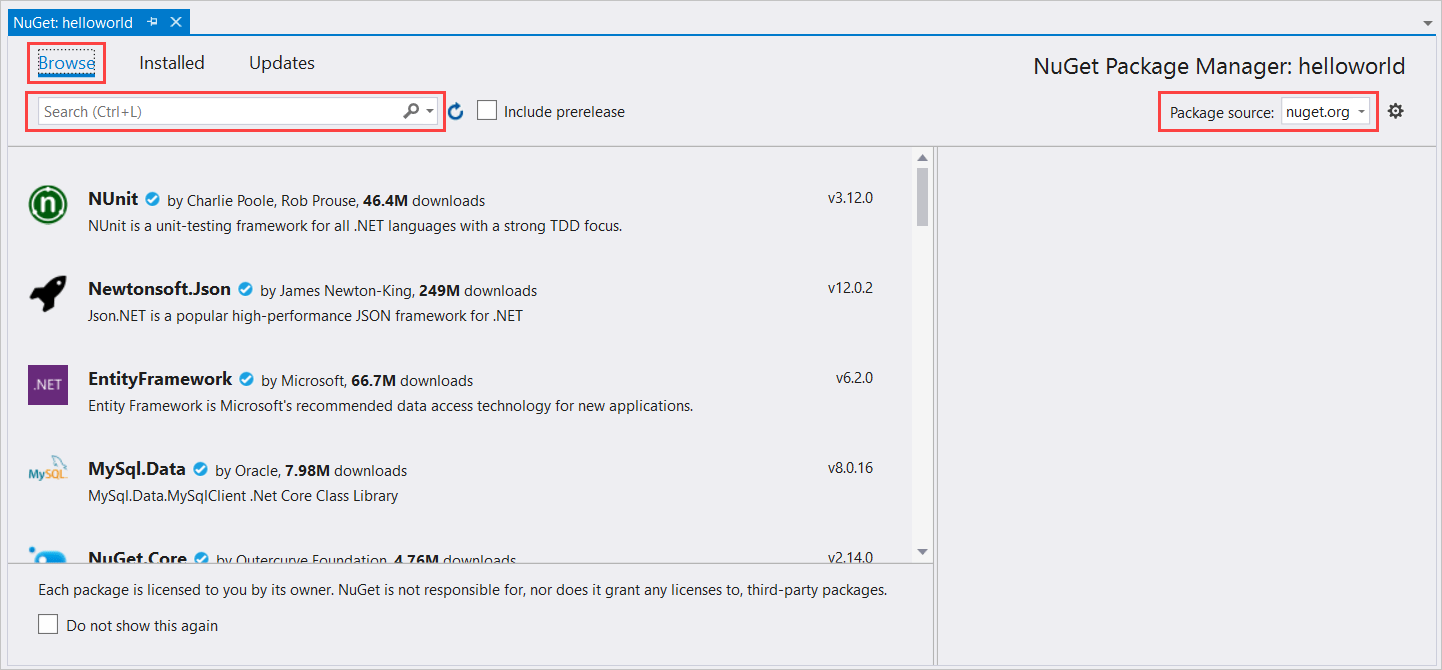
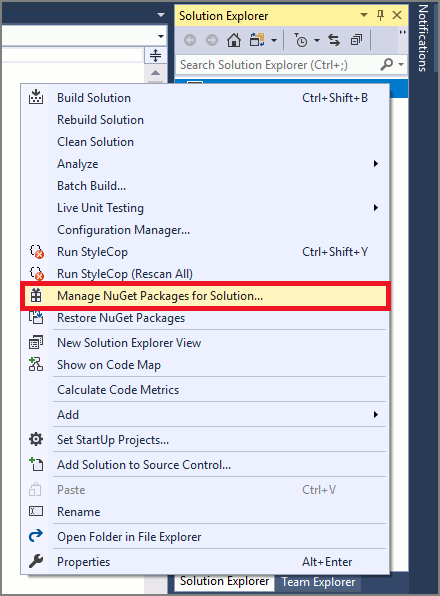
在解决方案资源管理器中右键单击“helloworld”项目,然后选择“管理 NuGet 包”以显示 NuGet 包管理器。
在右上角找到“包源 ”下拉框,并确保已选择 nuget.org 。
在左上角,选择“浏览”。
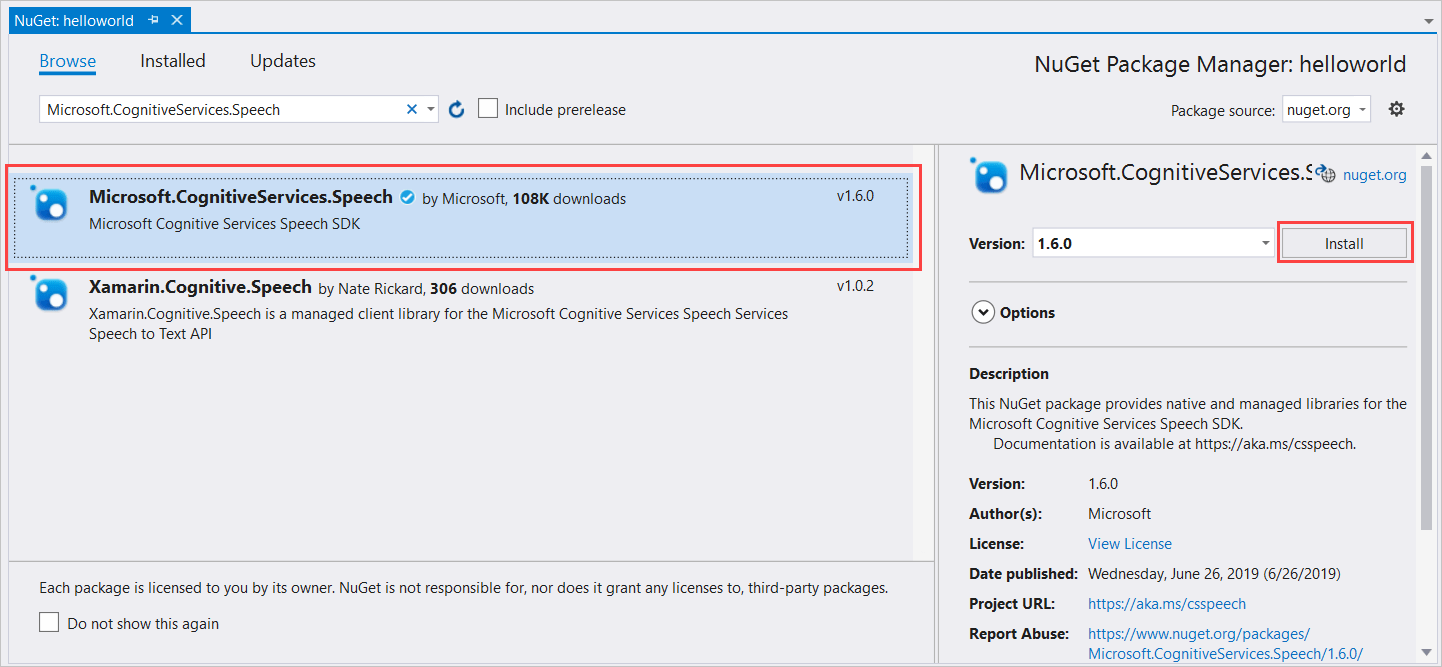
在搜索框中,输入 Microsoft.CognitiveServices.Speech ,然后选择 Enter 。
在搜索结果中选择“Microsoft.CognitiveServices.Speech”包,然后选择“安装”以安装最新稳定版本。
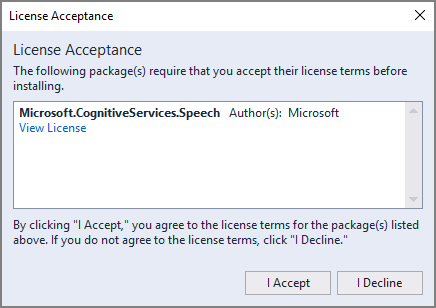
接受所有协议和许可证,开始安装。
安装此包后,“包管理器控制台”窗口中将显示一条确认消息。
选择目标体系结构
若要生成并运行控制台应用程序,请创建与计算机体系结构匹配的平台配置。
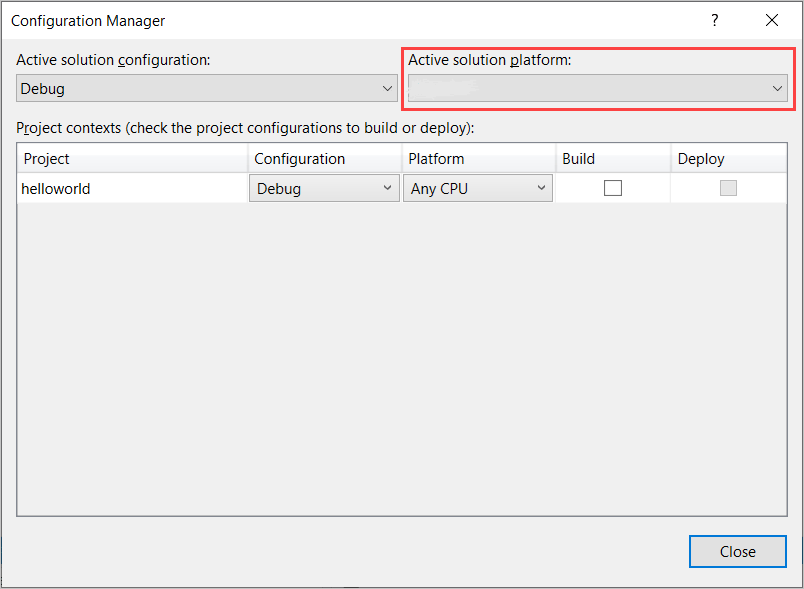
在菜单栏中,选择“生成 ”>“Configuration Manager ”。 此时将显示“配置管理器”对话框。
在“活动解决方案平台 ”下拉框中,选择“新建 ”。 此时将显示“新建解决方案平台”对话框。
在“键入或选择新平台 ”下拉框中:
如果运行的是 64 位 Windows,请选择 x64 。
如果运行的是 32 位 Windows,请选择 x86 。
选择“确定”,然后选择“关闭”。
本指南介绍如何安装用于 .NET Core 控制台应用的语音 SDK 。 .NET Core 是一个实现了 .NET Standard 规范的开源跨平台 .NET 平台。
本指南需要:
创建 Visual Studio 项目并安装语音 SDK
启动 Visual Studio 2017。
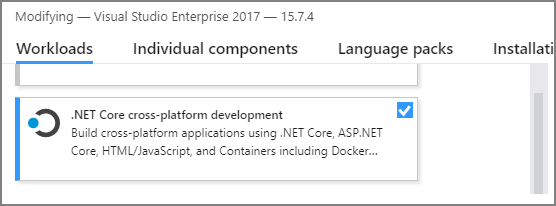
确保“.NET 跨平台开发 ”工作负载可用。 在 Visual Studio 菜单栏中选择“工具 ”>“获取工具和功能 ”,以打开 Visual Studio 安装程序。 如果此工作负荷已启用,请关闭对话框。
否则,请选择“.NET Core 跨平台开发 ”,然后选择“修改 ”。 安装新功能需要一定的时间。
在“新建项目 ”对话框中创建新的 Visual C# .NET Core 控制台应用。 在左窗格中,展开“已安装 ”>“Visual C# ”>“.NET Core ”。 然后,选择“控制台应用(.NET Core)” 。 在项目名称处,输入 helloworld 。
安装并引用语音 SDK NuGet 包 。 在解决方案资源管理器中,右键单击该解决方案,并选择“为解决方案管理 NuGet 包” 。
选择“浏览”,然后在右上角的“包源”中,选择“nuget.org”
搜索 Microsoft.CognitiveServices.Speech 包,并将其安装到“helloworld”项目中
接受显示的许可证即可开始安装 NuGet 包。
安装此包后,包管理器 控制台中将显示一条确认消息。
本指南介绍如何安装用于 Unity 的语音 SDK 。
适用于 Unity 开发的语音 SDK 支持 Windows 桌面版(x86 和 x64)或通用 Windows 平台(x86、x64、ARM/ARM64)、Android(x86、ARM32/64)、iOS(x64 模拟器和 ARM64)和 Mac (x64)。
先决条件
本指南需要:
安装适用于 Unity 的语音 SDK
若要安装适用于 Unity 的语音 SDK,请执行以下步骤:
下载并打开适用于 Unity 的语音 SDK 。 SDK 打包为 Unity 资产包 (.unitypackage),应该已经与 Unity 关联
确保选择所有文件,然后选择“导入”。 片刻之后,Unity 资产包即会导入到项目中。
有关将资产包导入 Unity 的详细信息,请参阅 Unity 文档 。
本指南介绍如何创建通用 Windows 平台 (UWP) 项目并安装适用于 C# 的语音 SDK 。 通用 Windows 平台允许开发在支持 Windows 10 的任何设备上运行的应用,包括电脑、Xbox、Surface Hub 和其他设备。
本指南需要:
创建 Visual Studio 项目并安装语音 SDK
若要为 UWP 开发创建 Visual Studio 项目,需执行以下操作:
设置 Visual Studio 开发选项。
创建项目并选择目标体系结构。
设置音频捕获。
安装语音 SDK。
设置 Visual Studio 开发选项
请确保已在 Visual Studio 中正确设置以用于 UWP 开发:
打开 Visual Studio 以显示“开始”窗口。
选择“继续但无需代码” ,转到 Visual Studio IDE。
在 Visual Studio 菜单栏中,选择“工具”
在“工作负载 ”选项卡上,找到“通用 Windows 平台开发 ”工作负载。 如果已选定该工作负载,请关闭“修改”对话框,然后关闭 Visual Studio 安装程序
选中“通用 Windows 平台开发 ”复选框,然后选择“修改 ”。
在“准备工作 ”对话框中,选择“继续 ”以安装 UWP 开发工作负载。 安装新功能可能花费一些时间。
关闭 Visual Studio 安装程序。
创建项目
接下来,创建项目并选择目标体系结构:
在 Visual Studio 菜单栏中,选择“文件” >“新建” >“项目” 以显示“创建新项目” 窗口。
查找并选择“空白应用(通用 Windows)”。 确保选择此项目类型的 C# 版本,而不是 Visual Basic。
选择下一步 。
在“配置新项目 ”对话框的“项目名称 ”中,输入 helloworld 。
在“位置”中,转到并选择或创建要用于保存项目的文件夹。
选择创建 。
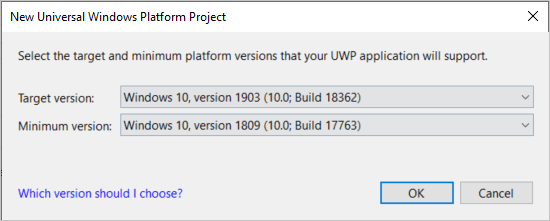
在“新建通用 Windows 平台项目 ”窗口的“最低版本 ”(第二个下拉框)中,选择“Windows 10 Fall Creators Update (10.0;内部版本 16299) ”。 这是对语音 SDK 的最低要求。
在“目标版本 ”(第一个下拉框)中,选择与“最低版本 ”中的值相等或更高的值。
选择“确定”解决方案资源管理器 ”窗格中。
选择目标平台体系结构。 在 Visual Studio 工具栏中,找到“解决方案平台 ”下拉框。 如果找不到,请选择“查看”>“工具栏”>“标准”以显示包含“解决方案平台”的工具栏。
如果运行的是 64 位 Windows,请在下拉框中选择“x64”
注意
语音 SDK 支持所有与 Intel 兼容的处理器,但仅支持“x64”版的 ARM 处理器。
设置音频捕获
允许项目捕获音频输入:
在“解决方案资源管理器 ”中,选择“Package.appxmanifest ”,以打开包应用程序清单。
选择“功能”选项卡,然后选择“麦克风”功能
在菜单栏中,选择“文件”>“保存 Package.appxmanifest”以保存所做的更改。
安装适用于 UWP 的语音 SDK
最后,安装语音 SDK NuGet 包 ,并在项目中引用语音 SDK:
在“解决方案资源管理器”中,右键单击你的解决方案,然后选择“管理解决方案的 NuGet 包”以转到“NuGet - 解决方案”窗口。
选择“浏览”。 在“包源”中,选择“nuget.org”。
在“搜索”框中,输入 Microsoft.CognitiveServices.Speech 。 在该包显示在搜索结果中之后选择该包。
在搜索结果旁的“包状态”窗格中,选择“helloworld” 项目。
选择“安装” 。
在“预览更改”对话框中,选择“应用”
在“接受许可证”
安装完成后,“输出”窗格会显示类似于以下文本的消息:Successfully installed 'Microsoft.CognitiveServices.Speech 1.15.0' to helloworld。
本指南演示如何创建 Xamarin 窗体项目并安装语音 SDK 。 Xamarin 是一个开放源代码平台,用于通过 .NET 为 iOS、Android 和 Windows 构建现代的高性能应用程序。
对于 Xamarin 开发,语音 SDK 支持:
Windows 桌面 x86 和 x64
通用 Windows 平台 x86、x64、ARM/ARM64
Android x86、ARM32/64
iOS x64 模拟器和 ARM64
本指南需要:
创建 Visual Studio 项目并安装语音 SDK
若要创建 Visual Studio 项目,以便使用 .NET 和 Xamarin 进行跨平台移动应用开发,需执行以下操作:
设置 Visual Studio 开发选项。
创建项目并选择目标体系结构。
安装语音 SDK。
设置 Visual Studio 开发选项
请确保已在 Visual Studio 中正确进行设置,以便使用 .NET 进行跨平台移动开发:
打开 Visual Studio 2019。 然后选择“继续但无需代码”
在 Visual Studio 菜单中,选择“工具 ”>“获取工具和功能 ”以打开 Visual Studio 安装程序并查看“修改 ”对话框。
在“工作负载 ”选项上,找到“使用 .NET 的移动开发 ”工作负载。 如果已选定该工作负载,请关闭“修改”对话框,然后关闭 Visual Studio 安装程序
选中“使用 .NET 的移动开发 ”,然后选择“修改 ”。
在“准备工作 ”对话框中,选择“继续 ”以安装使用 .NET 进行移动开发的工作负载。 安装新功能可能花费一些时间。
关闭 Visual Studio 安装程序。
创建项目
接下来,创建项目并选择目标体系结构:
在 Visual Studio 菜单栏中,选择“文件” >“新建” >“项目” 以显示“创建新项目” 窗口。
找到并选择“移动应用(Xamarin.Forms)” 。
选择“下一步 ”。
在“配置新项目 ”对话框的“项目名称 ”中,输入 helloworld 。
在“位置”中,转到并选择或创建要用于保存项目的文件夹。
选择“创建” 。
在“新建跨平台应用”窗口中,选择“空白”模板,然后选择“Android”、“iOS”和“Windows (UWP)”创建 。
选择“确定”解决方案资源管理器 ”窗格中。
选择目标平台体系结构和启动项目。 在 Visual Studio 工具栏中,找到“解决方案平台 ”下拉框。 如果找不到,请选择“查看”>“工具栏”>“标准”以显示包含“解决方案平台”的工具栏。
如果运行的是 64 位 Windows,请在下拉框中选择“x64”
在“启动项目 ”下拉框中,选择“helloworld.UWP (通用 Windows) ”。
安装适用于 Xamarin 的语音 SDK
安装语音 SDK NuGet 包 ,并在项目中引用语音 SDK:
在解决方案资源管理器 中,右键单击解决方案。 选择“管理解决方案的 NuGet 包” ,转到“NuGet - 解决方案”窗口。
选择“浏览” 。
在“包源”中,选择“nuget.org”。
在“搜索”框中,输入 Microsoft.CognitiveServices.Speech 。 然后在该包显示在搜索结果中之后选择该包。
备注
Microsoft.CognitiveServices.Speech NuGet 中的 iOS 库未启用 Bitcode。 如果需要为应用程序启用 Bitcode 库,请使用专用于 iOS 项目的 Microsoft.CognitiveServices.Speech.Xamarin.iOS NuGet。
在搜索结果旁的“包状态”窗格中,选择所有项目。
选择“安装” 。
在“预览更改”
在“接受许可证”
安装成功完成后,可能会看到下述针对 helloworld.iOS 的警告。 此警告是已知问题,不会影响应用功能。
Could not resolve reference "C:\Users\Default\.nuget\packages\microsoft.cognitiveservices.speech\1.7.0\build\Xamarin.iOS\libMicrosoft.CognitiveServices.Speech.core.a". If this reference is required by your code, you may get compilation errors.
语音 SDK 现已安装。 现在可以删除或重复使用在前面的步骤中创建的“helloworld”项目。
参考文档 | 包 (NuGet) | GitHub 上的其他示例
在本快速入门中,我们安装适用于 C++ 的语音 SDK 。
适用于 C++ 的语音 SDK 与 Windows、Linux 和 macOS 兼容。
注意
本文引用了 CentOS,这是一个接近生命周期结束 (EOL) 状态的 Linux 发行版。 请相应地考虑你的使用和规划。 有关详细信息,请参阅 CentOS 生命周期结束指南 。
适用于 C++ 的语音 SDK 仅支持 x86 (Debian/Ubuntu)、x64、ARM32 (Debian/Ubuntu) 和 ARM64 (Debian/Ubuntu) 架构上的以下发行版:
Ubuntu 18.04/20.04
Debian 10/11
Red Hat Enterprise Linux (RHEL) 7/8
CentOS 7
重要
使用 Linux 分发版的最新 LTS 版本。 例如,如果使用 Ubuntu 20.04 LTS,请使用最新版本的 Ubuntu 20.04.X。
语音 SDK 依赖于以下 Linux 系统库:
GNU C 库的共享库(包括 POSIX 线程编程库 libpthreads)。
OpenSSL 库 (libssl) 版本 1.x 和证书 (ca-certificates)。
ALSA 应用程序的共享库 (libasound)。
还应安装 ca-certificates 以建立安全的 Websocket 并避免此 WS_OPEN_ERROR_UNDERLYING_IO_OPEN_FAILED 错误。
重要
语音 SDK 尚不支持 OpenSSL 3.0(Ubuntu 22.04 和 Debian 12 中的默认版本)。
运行以下 命令:
sudo apt-get update
sudo apt-get install build-essential libssl-dev ca-certificates libasound2 wget
若要在 Alpine Linux 中使用语音 SDK,请按照 Alpine Linux Wiki 中的运行 glibc 程序 所述创建 Debian chroot 环境。 然后按照此处的 Debian 说明操作。
sudo apt-get update
sudo apt-get install build-essential libssl-dev ca-certificates libasound2 wget
注意
本文引用了 CentOS,这是一个接近生命周期结束 (EOL) 状态的 Linux 发行版。 请相应地考虑你的使用和规划。 有关详细信息,请参阅 CentOS 生命周期结束指南 。
安装开发工具和库:
sudo yum update
sudo yum groupinstall "Development tools"
sudo yum install alsa-lib openssl wget
安装适用于 C++ 的语音 SDK
适用于 C++ 的语音 SDK 以 NuGet 包的形式提供。 有关详细信息,请参阅 Microsoft.CognitiveServices.Speech 。
可以使用以下 dotnet add 命令从 .NET Core CLI 安装适用于 C++ 的语音 SDK:
dotnet add package Microsoft.CognitiveServices.Speech
可以使用以下 Install-Package 命令安装适用于 C++ 的语音 SDK:
Install-Package Microsoft.CognitiveServices.Speech
可以按照这些指南获取更多选项。
本指南介绍如何安装用于 Linux 的语音 SDK 。
使用以下过程下载并安装 SDK。 这些步骤包括以 .tar 文件格式下载所需的库和头文件 。
为语音 SDK 文件选择目录。 将 SPEECHSDK_ROOT 环境变量设置为指向该目录。 使用此变量,在将来的命令中可以轻松引用目录。
若要使用主目录中的 speechsdk 目录,请运行以下命令
export SPEECHSDK_ROOT="$HOME/speechsdk"
创建目录(如果不存在):
mkdir -p "$SPEECHSDK_ROOT"
下载并提取包含语音 SDK 二进制文件的 .tar.gz 存档:
wget -O SpeechSDK-Linux.tar.gz https://aka.ms/csspeech/linuxbinary
tar --strip 1 -xzf SpeechSDK-Linux.tar.gz -C "$SPEECHSDK_ROOT"
验证所提取的程序包的顶级目录的内容:
ls -l "$SPEECHSDK_ROOT"
目录列表应包含合作伙伴通知和许可证文件。 该列表还应包含容纳头文件 (.h ) 的 include 目录和容纳 arm32、arm64、x64 和 x86 库的 lib 目录。
路径
说明
license.md 许可
ThirdPartyNotices.md 合作伙伴通知
REDIST.txt 再分发声明
包括 C++ 所需的头文件
lib/arm32 ARM32 必需的用来链接应用程序的本机库
lib/arm64 ARM64 必需的用来链接应用程序的本机库
lib/x64 x64 必需的用来链接应用程序的本机库
lib/x86 x86 必需的用来链接应用程序的本机库
本指南介绍如何安装用于 macOS 10.14 或更高版本上的 C++ 的语音 SDK 。 这些步骤包括以 .zip 文件格式下载所需的库和头文件 。
为语音 SDK 文件选择目录。 将 SPEECHSDK_ROOT 环境变量设置为指向该目录。 使用此变量,在将来的命令中可以轻松引用目录。
若要使用主目录中的 speechsdk 目录,请运行以下命令
export SPEECHSDK_ROOT="$HOME/speechsdk"
创建目录(如果不存在):
mkdir -p "$SPEECHSDK_ROOT"
下载并提取包含语音 SDK XCFramework 的 .zip 存档:
wget -O SpeechSDK-macOS.zip https://aka.ms/csspeech/macosbinary
unzip SpeechSDK-macOS.zip -d "$SPEECHSDK_ROOT"
验证所提取的程序包的顶级目录的内容:
ls -l "$SPEECHSDK_ROOT"
目录列表应包含合作伙伴通知、许可证文件以及 MicrosoftCognitiveServicesSpeech.xcframework 目录
本指南介绍如何安装适用于 Windows 桌面操作系统上的 C++ 的语音 SDK 。
此安装指南需要:
在 Visual Studio 上创建项目并安装语音 SDK
若要为 C++ 桌面开发创建 Visual Studio 项目,需执行以下操作:
设置 Visual Studio 开发选项。
创建项目。
选择目标体系结构。
安装语音 SDK。
设置 Visual Studio 开发选项
若要开始,请确保已在 Visual Studio 中正确设置以用于 C++ 桌面开发:
打开 Visual Studio 2019 以显示“开始”窗口。
选择“继续但无需代码” ,转到 Visual Studio IDE。
在 Visual Studio 菜单栏中,选择“工具”
在“工作负载”选项卡的“Windows”下,找到“使用 C++ 的桌面开发”工作负载。 如果尚未选定该工作负载,请将其选定。
在“单个组件”选项卡中,找到“NuGet 包管理器”
选择“关闭”或“修改”
如果选择“修改”,将开始安装。 此过程可能需要一些时间。
关闭 Visual Studio 安装程序。
创建项目
接下来,创建项目并选择目标体系结构:
在 Visual Studio 菜单栏中,选择“文件 ”>“新建 ”>“项目 ”以显示“创建新项目 ”窗口。
找到“控制台应用”并将其选中 。 确保选择此项目类型的 C++ 版本,而不是 C# 或 Visual Basic。
选择“下一页 ”。
在“配置新项目 ”对话框的“项目名称 ”中,输入 helloworld 。
在“位置 ”中,转到并选择或创建要用于保存项目的文件夹,然后选择“创建 ”。
选择目标平台体系结构。 在 Visual Studio 工具栏中,找到“解决方案平台 ”下拉框。 如果找不到,请选择“查看”>“工具栏”>“标准”以显示包含“解决方案平台”的工具栏。
如果运行的是 64 位 Windows,请在下拉框中选择“x64 ”。 64 位 Windows 也可以运行 32 位应用程序,因此可以根据自己的偏好选择“x86” 。
使用 Visual Studio 安装语音 SDK
最后,安装语音 SDK NuGet 包 ,并在项目中引用语音 SDK:
在“解决方案资源管理器”中,右键单击你的解决方案,然后选择“管理解决方案的 NuGet 包”以转到“NuGet - 解决方案”窗口。
选择“浏览”。
在“包源”中,选择“nuget.org”。
在“搜索”框中,输入 Microsoft.CognitiveServices.Speech 。 在该包显示在搜索结果中之后选择该包。
在搜索结果旁的“包状态”窗格中,选择“helloworld” 项目。
选择“安装” 。
在“预览更改”
在“接受许可证”Successfully installed 'Microsoft.CognitiveServices.Speech 1.15.0' to helloworld。
参考文档 | 包 (Go) | GitHub 上的其他示例
在本快速入门中,我们安装适用于 Go 的语音 SDK 。
注意
本文引用了 CentOS,这是一个接近生命周期结束 (EOL) 状态的 Linux 发行版。 请相应地考虑你的使用和规划。 有关详细信息,请参阅 CentOS 生命周期结束指南 。
适用于 Go 的语音 SDK 支持 x64 体系结构上的以下分发:
Ubuntu 18.04/20.04
Debian 9/10/11
Red Hat Enterprise Linux (RHEL) 8
CentOS 7
重要
使用 Linux 分发版的最新 LTS 版本。 例如,如果使用 Ubuntu 20.04 LTS,请使用最新版本的 Ubuntu 20.04.X。
语音 SDK 依赖于以下 Linux 系统库:
GNU C 库的共享库(包括 POSIX 线程编程库 libpthreads)。
OpenSSL 库 (libssl) 版本 1.x 和证书 (ca-certificates)。
ALSA 应用程序的共享库 (libasound)。
还应安装 ca-certificates 以建立安全的 Websocket 并避免此 WS_OPEN_ERROR_UNDERLYING_IO_OPEN_FAILED 错误。
重要
语音 SDK 尚不支持 OpenSSL 3.0(Ubuntu 22.04 和 Debian 12 中的默认版本)。
运行以下 命令:
sudo apt-get update
sudo apt-get install build-essential libssl-dev ca-certificates libasound2 wget
若要在 Alpine Linux 中使用语音 SDK,请按照 Alpine Linux Wiki 中的运行 glibc 程序 所述创建 Debian chroot 环境。 然后按照此处的 Debian 说明操作。
sudo apt-get update
sudo apt-get install build-essential libssl-dev ca-certificates libasound2 wget
注意
本文引用了 CentOS,这是一个接近生命周期结束 (EOL) 状态的 Linux 发行版。 请相应地考虑你的使用和规划。 有关详细信息,请参阅 CentOS 生命周期结束指南 。
安装开发工具和库:
sudo yum update
sudo yum groupinstall "Development tools"
sudo yum install alsa-lib openssl wget
安装 Go 二进制版本 1.13 或更高版本 。
安装适用于 Go 的语音 SDK
使用以下过程下载并安装 SDK。 这些步骤包括以 .tar 文件格式下载所需的库和头文件 。
为语音 SDK 文件选择目录。 将 SPEECHSDK_ROOT 环境变量设置为指向该目录。 使用此变量,在将来的命令中可以轻松引用目录。
若要使用主目录中的 speechsdk 目录,请运行以下命令
export SPEECHSDK_ROOT="$HOME/speechsdk"
创建目录(如果不存在):
mkdir -p "$SPEECHSDK_ROOT"
下载并提取包含语音 SDK 二进制文件的 .tar.gz 存档:
wget -O SpeechSDK-Linux.tar.gz https://aka.ms/csspeech/linuxbinary
tar --strip 1 -xzf SpeechSDK-Linux.tar.gz -C "$SPEECHSDK_ROOT"
验证所提取的程序包的顶级目录的内容:
ls -l "$SPEECHSDK_ROOT"
目录列表应包含合作伙伴通知和许可证文件。 该列表还应包含容纳头文件 (.h ) 的 include 目录和容纳 arm32、arm64、x64 和 x86 库的 lib 目录。
路径
说明
license.md 许可
ThirdPartyNotices.md 合作伙伴通知
REDIST.txt 再分发声明
包括 C++ 所需的头文件
lib/arm32 ARM32 必需的用来链接应用程序的本机库
lib/arm64 ARM64 必需的用来链接应用程序的本机库
lib/x64 x64 必需的用来链接应用程序的本机库
lib/x86 x86 必需的用来链接应用程序的本机库
通过以下步骤可使 Go 环境能够查找语音 SDK。
由于绑定依赖于 cgo,因此需要设置环境变量,以便 Go 可以找到 SDK。
export CGO_CFLAGS="-I$SPEECHSDK_ROOT/include/c_api"
export CGO_LDFLAGS="-L$SPEECHSDK_ROOT/lib/<architecture> -lMicrosoft.CognitiveServices.Speech.core"
重要
将 <architecture> 替换为 CPU 的处理器体系结构:x86、x64、arm32 或 arm64。
若要运行应用程序和 SDK,需要告知操作系统可在何处可以找到库。
export LD_LIBRARY_PATH="$SPEECHSDK_ROOT/lib/<architecture>:$LD_LIBRARY_PATH"
重要
将 <architecture> 替换为 CPU 的处理器体系结构:x86、x64、arm32 或 arm64。
参考文档 | GitHub 上的其他示例
在本快速入门中,我们安装适用于 Java 的语音 SDK 。
选择目标环境:
适用于 Java 的语音 SDK 与 Windows、Linux 和 macOS 兼容。
注意
本文引用了 CentOS,这是一个接近生命周期结束 (EOL) 状态的 Linux 发行版。 请相应地考虑你的使用和规划。 有关详细信息,请参阅 CentOS 生命周期结束指南 。
适用于 Java 的语音 SDK 支持 x64、ARM32 (Debian/Ubuntu) 和 ARM64 (Debian/Ubuntu) 体系结构上的以下发行版:
Ubuntu 18.04/20.04
Debian 10/11
Red Hat Enterprise Linux (RHEL) 7/8
CentOS 7
重要
使用 Linux 分发版的最新 LTS 版本。 例如,如果使用 Ubuntu 20.04 LTS,请使用最新版本的 Ubuntu 20.04.X。
语音 SDK 依赖于以下 Linux 系统库:
GNU C 库的共享库(包括 POSIX 线程编程库 libpthreads)。
OpenSSL 库 (libssl) 版本 1.x 和证书 (ca-certificates)。
ALSA 应用程序的共享库 (libasound)。
还应安装 ca-certificates 以建立安全的 Websocket 并避免此 WS_OPEN_ERROR_UNDERLYING_IO_OPEN_FAILED 错误。
重要
语音 SDK 尚不支持 OpenSSL 3.0(Ubuntu 22.04 和 Debian 12 中的默认版本)。
运行以下 命令:
sudo apt-get update
sudo apt-get install build-essential libssl-dev ca-certificates libasound2 wget
若要在 Alpine Linux 中使用语音 SDK,请按照 Alpine Linux Wiki 中的运行 glibc 程序 所述创建 Debian chroot 环境。 然后按照此处的 Debian 说明操作。
sudo apt-get update
sudo apt-get install build-essential libssl-dev ca-certificates libasound2 wget
注意
本文引用了 CentOS,这是一个接近生命周期结束 (EOL) 状态的 Linux 发行版。 请相应地考虑你的使用和规划。 有关详细信息,请参阅 CentOS 生命周期结束指南 。
安装开发工具和库:
sudo yum update
sudo yum groupinstall "Development tools"
sudo yum install alsa-lib openssl wget
语音 SDK 与具有 32/64 位 ARM 处理器和 Intel x86/x64 兼容处理器的 Android 设备兼容。
安装 Java 开发工具包,例如 Azul Zulu OpenJDK 。 Microsoft Build of OpenJDK 或你喜欢的 JDK 应该也能正常工作。
安装适用于 Java 的语音 SDK
某些说明使用特定的 SDK 版本,例如 1.24.2。 若要查看最新版本,请搜索我们的 GitHub 存储库 。
选择目标环境:
本指南介绍如何在 Java 运行时上安装用于 Java 的语音 SDK 。
支持的操作系统
用于 Java 包的语音 SDK 适用于以下操作系统:
按照以下步骤使用 Apache Maven 安装适用于 Java 的语音 SDK:
安装 Apache Maven 。
在需要新项目的位置打开命令提示符,并创建一个新的 pom.xml 文件。
将以下 XML 内容复制到 pom.xml 中:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.microsoft.cognitiveservices.speech.samples</groupId>
<artifactId>quickstart-eclipse</artifactId>
<version>1.0.0-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.microsoft.cognitiveservices.speech</groupId>
<artifactId>client-sdk</artifactId>
<version>1.37.0</version>
</dependency>
</dependencies>
</project>
若要安装语音 SDK 和依赖项,请运行以下 Maven 命令。
mvn clean dependency:copy-dependencies
创建 Eclipse 项目并安装语音 SDK
安装 Eclipse Java IDE 。 此 IDE 需要已安装 Java。
启动 Eclipse。
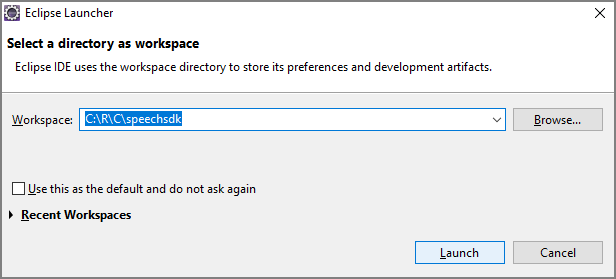
在 Eclipse Launcher 中,在“工作区”框中输入某个新工作区目录的名称。 然后选择“启动”。
片刻之后,Eclipse IDE 的主窗口将会显示。 关闭欢迎 屏幕(如果存在)。
从 Eclipse 菜单中,选择“文件”
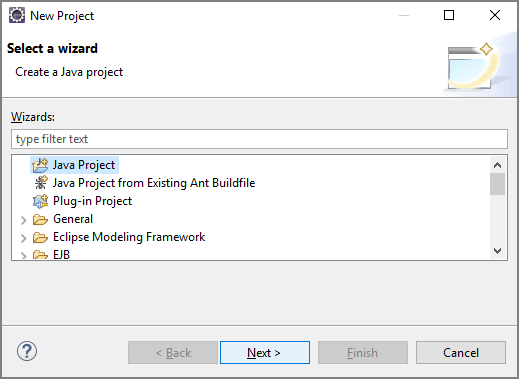
将显示“新建项目”
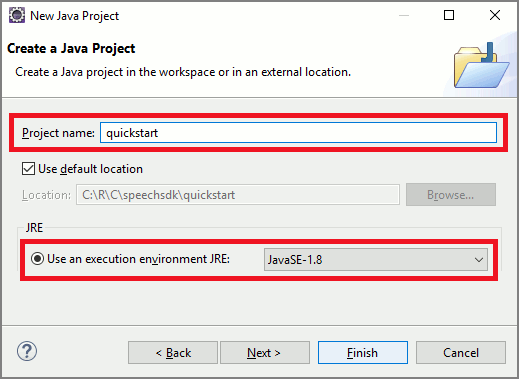
此时将启动“新建 Java 项目”向导。 在“项目名称”字段中,输入“快速入门”。 选择“JavaSE-1.8”作为执行环境。 选择“完成”。
如果出现了“打开关联的透视图?”窗口,请选择“打开透视图”。
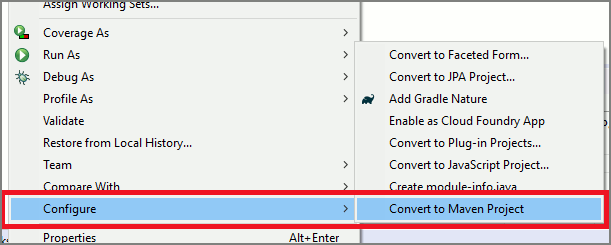
在“包资源管理器”中,右键单击“快速入门”项目。 从上下文菜单中选择“配置 ”>“转换为 Maven 项目 ”。
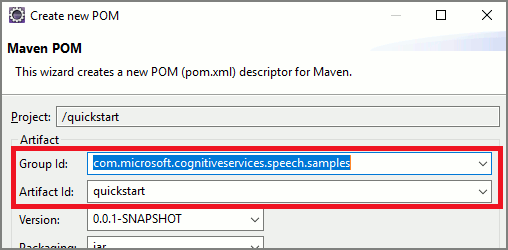
此时将显示“新建 POM”窗口。 在“组 ID”字段中,输入“com.microsoft.cognitiveservices.speech.samples”。 在“项目 ID”字段中,输入“快速入门”。 然后选择“完成”。
打开 pom.xml 文件并对其进行编辑:
在文件末尾,在结束标记 </project> 前面添加一个 dependencies 元素,并将语音 SDK 作为依赖项:
<dependencies>
<dependency>
<groupId>com.microsoft.cognitiveservices.speech</groupId>
<artifactId>client-sdk</artifactId>
<version>1.37.0</version>
</dependency>
</dependencies>
保存更改。
Gradle 配置
Gradle 配置需要显式引用 .jar 依赖项扩展:
// build.gradle
dependencies {
implementation group: 'com.microsoft.cognitiveservices.speech', name: 'client-sdk', version: "1.37.0", ext: "jar"
}
本指南介绍如何安装用于 Java on Android 的语音 SDK 。
将适用于 Android 的语音 SDK 打包为 Android 存档 (AAR) 文件 ,其中包含必要的库以及所需的 Android 权限。
使用 Android Studio 安装语音 SDK
在 Android Studio 中创建新项目,并将适用于 Java 的语音 SDK 添加为库依赖项。 该安装基于语音 SDK Maven 包和 Android Studio Chipmunk 2021.2.1。
创建一个空的项目
打开 Android Studio,然后选择“新建项目”。
在出现的“新建项目”窗口中,选择“电话和平板”>“空活动”,然后选择“下一步”。
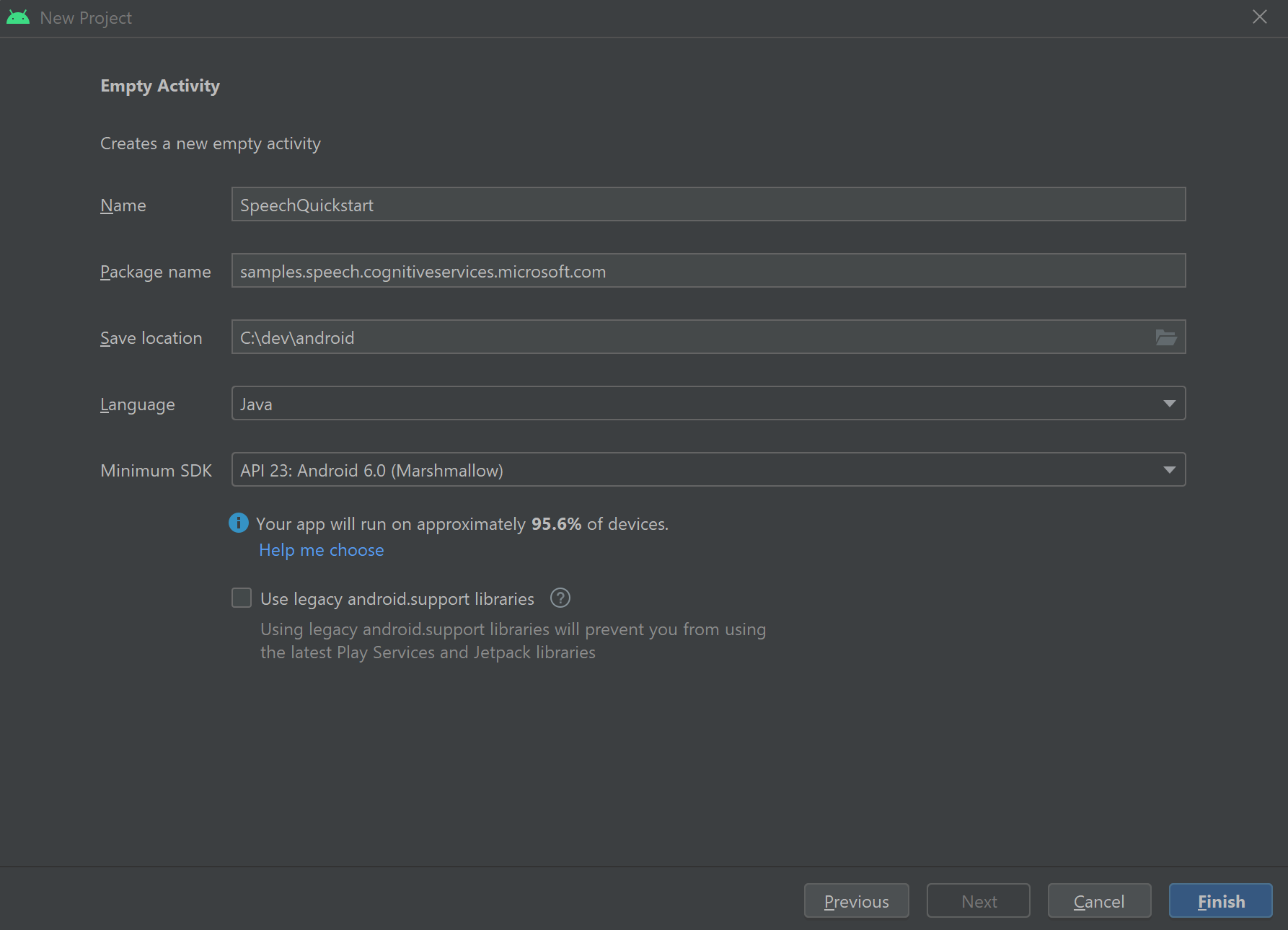
在“名称”文本框中输入 SpeechQuickstart。
在“包名称”文本框中输入 samples.speech.cognitiveservices.microsoft.com。
在“保存位置”选择框中选择项目目录。
在“语言”选择框中选择 “Java”。
在“最低 API 级别”选择框中选择 “API 23:Android 6.0 (Marshmallow)”。
选择“完成”
Android Studio 需要一些时间来准备你的新项目。 首次使用 Android Studio 时,设置首选项、接受许可证并完成向导可能需要几分钟时间。
在 Android 上安装适用于 Java 的语音 SDK
将语音 SDK 添加为项目中的依赖项。
选择“文件”>“项目结构”>“依赖项”>“应用”。
选择加号 (+ ),在“声明的依赖项”下添加依赖项。 然后从下拉菜单中选择“库依赖项 ”。
在显示的“添加库依赖项”窗口中,输入适用于 Java 的语音 SDK 名称和版本:com.microsoft.cognitiveservices.speech:client-sdk:1.37.0
确保所选的“组 ID” 为 com.microsoft.cognitiveservices.speech ,然后选择“确定”。
选择“确定”,关闭“项目结构”窗口并应用对项目所做的更改。
参考文档 | 包 (npm) | GitHub 上的其他示例 | 库源代码
在本快速入门中,我们安装适用于 JavaScript 的语音 SDK 。
适用于 JavaScript 的语音 SDK 以 npm 包的形式提供。 请参阅 microsoft-cognitiveservices-speech-sdk 及其配套的 GitHub 存储库 cognitive-services-speech-sdk-js 。
了解 Node.js 和客户端 Web 浏览器之间的各种体系结构影响。 例如,文档对象模型 (DOM) 不适用于服务器端应用程序。 Node.js 文件系统 不适用于客户端应用程序。
安装适用于 JavaScript 的语音 SDK
请根据目标环境使用以下指南之一:
本指南介绍如何安装可以在 Node.js 中使用的 JavaScript 版语音 SDK 。
安装 Node.js 。
创建一个新目录,运行 npm init 并浏览其提示。
若要安装适用于 JavaScript 的语音 SDK,请运行以下 npm install 命令:
npm install microsoft-cognitiveservices-speech-sdk
有关详细信息,请参阅 Node.js 示例 。
本指南介绍如何安装可以在网页中使用的适用于 JavaScript 的语音 SDK 。
解压缩到文件夹
新建空文件夹。 如果要在 Web 服务器上托管示例,请确保 Web 服务器可访问文件夹。
将语音 SDK 作为 .zip 包 下载,并将其解压缩到新建文件夹。 已解压缩这些文件:
microsoft.cognitiveservices.speech.sdk.bundle.js:语音 SDK 的人工可读版本。
microsoft.cognitiveservices.speech.sdk.bundle.js.map:用于调试 SDK 代码的映射文件
microsoft.cognitiveservices.speech.sdk.bundle.d.ts:用于 TypeScript 的对象定义。
microsoft.cognitiveservices.speech.sdk.bundle-min.js:语音 SDK 的缩小版本。
speech-processor.js:用于提高某些浏览器性能的代码。
在文件夹中创建名为 index.html 的新文件,使用文本编辑器打开此文件。
HTML 脚本标记
从适用于 JavaScript 的语音 SDK 中下载并提取 microsoft.cognitiveservices.speech.sdk.bundle.js 文件。 将其置于可供 HTML 文件访问的文件夹中。
<script src="microsoft.cognitiveservices.speech.sdk.bundle.js"></script>;
提示
如果以 Web 浏览器为目标并使用 <script> 标记,则不需 sdk 前缀。 sdk 前缀是一个别名,用于为 require 模块命名。
或者,可以直接在 HTML <head> 元素中包含一个 <script> 标记,该标记依赖于 JSDelivr 。
<script src="https://cdn.jsdelivr.net/npm/microsoft-cognitiveservices-speech-sdk@latest/distrib/browser/microsoft.cognitiveservices.speech.sdk.bundle-min.js">
</script>
有关详细信息,请参阅基于浏览器的示例 。
使用语音 SDK
有关 import 的详细信息,请参阅 JavaScript 网站上的导出和导入 。
或者,可以使用 require 语句:
const sdk = require("microsoft-cognitiveservices-speech-sdk");
参考文档 | 包(下载) | GitHub 上的其他示例
在本快速入门中,我们安装适用于 Objective-C 的语音 SDK 。
安装适用于 Objective-C 的语音 SDK
用于 Objective-C 的语音 SDK 以 CocoaPod 包的形式本机提供,适用于 Mac x64 和基于 ARM 的系统。
Mac 的系统需求:
macOS CocoaPod 包可供下载并在 Xcode 9.4.1 (或更高版本)集成开发环境 (IDE) 中使用。
转到 .xcodeproj 项目文件所在的 Xcode 目录。
运行 pod init 以创建一个名为 Podfile 的 Pod 文件。
将 Podfile 文件的内容替换为以下内容。 将 target 名称从 AppName 更新为应用的名称。 根据需要更新平台或 Pod 版本。
platform :osx, 10.14
use_frameworks!
target 'AppName' do
pod 'MicrosoftCognitiveServicesSpeech-macOS', '~> 1.37.0'
end
运行 pod install 以安装语音 SDK。
或者,下载二进制 CocoaPod 并提取其内容。 在 Xcode 项目中,添加对提取的 MicrosoftCognitiveServicesSpeech.xcframework 文件夹及其内容的引用。
注意
.NET 开发人员可以使用 Xamarin.Mac 应用程序框架生成本机 macOS 应用程序。 有关详细信息,请参阅 Xamarin.Mac 。
用于 Objective-C 的语音 SDK 以 CocoaPod 包的形式本机提供。
iOS 的系统需求:
macOS 版本 10.14 或更高版本
目标 iOS 9.3 或更高版本
macOS CocoaPod 包可供下载并在 Xcode 9.4.1 (或更高版本)集成开发环境 (IDE) 中使用。
转到 .xcodeproj 项目文件所在的 Xcode 目录。
运行 pod init 以创建一个名为 Podfile 的 Pod 文件。
将 Podfile 文件的内容替换为以下内容。 将 target 名称从 AppName 更新为应用的名称。 根据需要更新平台或 Pod 版本。
platform :ios, '9.3'
use_frameworks!
target 'AppName' do
pod 'MicrosoftCognitiveServicesSpeech-iOS', '~> 1.37.0'
end
运行 pod install 以安装语音 SDK。
或者,下载二进制 CocoaPod 并提取其内容。 在 Xcode 项目中,添加对提取的 MicrosoftCognitiveServicesSpeech.xcframework 文件夹及其内容的引用。
注意
.NET 开发人员可以使用 Xamarin.iOS 应用程序框架生成本机 iOS 应用程序。 有关详细信息,请参阅 Xamarin.iOS 。
参考文档 | 包(下载) | GitHub 上的其他示例
在本快速入门中,我们安装适用于 Swift 的语音 SDK 。
安装适用于 Swift 的语音 SDK
用于 Swift 的语音 SDK 以 CocoaPod 包的形式本机提供,适用于 Mac x64 和基于 ARM 的系统。
Mac 的系统需求:
macOS CocoaPod 包可供下载并在 Xcode 9.4.1 (或更高版本)集成开发环境 (IDE) 中使用。
转到 .xcodeproj 项目文件所在的 Xcode 目录。
运行 pod init 以创建一个名为 Podfile 的 Pod 文件。
将 Podfile 文件的内容替换为以下内容。 将 target 名称从 AppName 更新为应用的名称。 根据需要更新平台或 Pod 版本。
platform :osx, 10.14
use_frameworks!
target 'AppName' do
pod 'MicrosoftCognitiveServicesSpeech-macOS', '~> 1.37.0'
end
运行 pod install 以安装语音 SDK。
或者,下载二进制 CocoaPod 并提取其内容。 在 Xcode 项目中,添加对提取的 MicrosoftCognitiveServicesSpeech.xcframework 文件夹及其内容的引用。
注意
.NET 开发人员可以使用 Xamarin.Mac 应用程序框架生成本机 macOS 应用程序。 有关详细信息,请参阅 Xamarin.Mac 。
用于 Swift 的语音 SDK 以 CocoaPod 包的形式本机提供。
iOS 的系统需求:
macOS 版本 10.14 或更高版本
目标 iOS 9.3 或更高版本
macOS CocoaPod 包可供下载并在 Xcode 9.4.1 (或更高版本)集成开发环境 (IDE) 中使用。
转到 .xcodeproj 项目文件所在的 Xcode 目录。
运行 pod init 以创建一个名为 Podfile 的 Pod 文件。
将 Podfile 文件的内容替换为以下内容。 将 target 名称从 AppName 更新为应用的名称。 根据需要更新平台或 Pod 版本。
platform :ios, '9.3'
use_frameworks!
target 'AppName' do
pod 'MicrosoftCognitiveServicesSpeech-iOS', '~> 1.37.0'
end
运行 pod install 以安装语音 SDK。
或者,下载二进制 CocoaPod 并提取其内容。 在 Xcode 项目中,添加对提取的 MicrosoftCognitiveServicesSpeech.xcframework 文件夹及其内容的引用。
注意
.NET 开发人员可以使用 Xamarin.iOS 应用程序框架生成本机 iOS 应用程序。 有关详细信息,请参阅 Xamarin.iOS 。
参考文档 | 包 (PyPi) | GitHub 上的其他示例
在本快速入门中,我们安装适用于 Python 的语音 SDK 。
适用于 Python 的语音 SDK 与 Windows、Linux 和 macOS 兼容。
注意
本文引用了 CentOS,这是一个接近生命周期结束 (EOL) 状态的 Linux 发行版。 请相应地考虑你的使用和规划。 有关详细信息,请参阅 CentOS 生命周期结束指南 。
适用于 Python 的语音 SDK 支持 x64 和 ARM64 体系结构上的以下分发:
Ubuntu 18.04/20.04
Debian 10/11
Red Hat Enterprise Linux (RHEL) 8
CentOS 7
重要
使用 Linux 分发版的最新 LTS 版本。 例如,如果使用 Ubuntu 20.04 LTS,请使用最新版本的 Ubuntu 20.04.X。
语音 SDK 依赖于以下 Linux 系统库:
GNU C 库的共享库(包括 POSIX 线程编程库 libpthreads)。
OpenSSL 库 (libssl) 版本 1.x 和证书 (ca-certificates)。
ALSA 应用程序的共享库 (libasound)。
还应安装 ca-certificates 以建立安全的 Websocket 并避免此 WS_OPEN_ERROR_UNDERLYING_IO_OPEN_FAILED 错误。
重要
语音 SDK 尚不支持 OpenSSL 3.0(Ubuntu 22.04 和 Debian 12 中的默认版本)。
运行以下 命令:
sudo apt-get update
sudo apt-get install build-essential libssl-dev ca-certificates libasound2 wget
若要在 Alpine Linux 中使用语音 SDK,请按照 Alpine Linux Wiki 中的运行 glibc 程序 所述创建 Debian chroot 环境。 然后按照此处的 Debian 说明操作。
sudo apt-get update
sudo apt-get install build-essential libssl-dev ca-certificates libasound2 wget
注意
本文引用了 CentOS,这是一个接近生命周期结束 (EOL) 状态的 Linux 发行版。 请相应地考虑你的使用和规划。 有关详细信息,请参阅 CentOS 生命周期结束指南 。
安装开发工具和库:
sudo yum update
sudo yum groupinstall "Development tools"
sudo yum install alsa-lib openssl wget
安装从 3.7 开始或更高版本的 Python 。
若要检查安装情况,请打开终端并运行命令 python --version。 如果 Python 安装正确,则会收到类似 Python 3.8.10 的响应。
如果你使用的是 macOS 或 Linux,可能需要改为运行命令 python3 --version。
若要启用 python 而不是 python3,请运行 alias python='python3' 以设置别名。 语音 SDK 快速入门示例指定了 python 用法。
安装适用于 Python 的语音 SDK
安装适用于 Python 的语音 SDK 之前,请确保满足平台先决条件 。
从 PyPI 安装
若要安装适用于 Python 的语音 SDK,请在控制台窗口中运行以下命令:
pip install azure-cognitiveservices-speech
升级到最新的语音 SDK 版本
若要升级到最新的语音 SDK,请在控制台窗口中运行以下命令:
pip install --upgrade azure-cognitiveservices-speech
可以通过查看 azure.cognitiveservices.speech.__version__ 变量来检查当前安装的适用于 Python 的语音 SDK 版本。 例如,在控制台窗口中运行以下命令:
pip list
使用 Visual Studio Code 安装语音 SDK
若要安装适用于 Python 的语音 SDK,请执行以下操作:
下载并安装 Visual Studio Code 。
运行 Visual Studio Code 并安装 Python 扩展:
选择“文件”>“首选项”>“扩展”。
搜索“Python”,查找由 Microsoft 发布的“适用于 Visual Studio Code 的 Python 扩展”,然后选择“安装”。
选择“终端”>“新建终端”,以在 Visual Studio Code 中打开终端。
在终端提示符下,运行以下命令以安装适用于 Python 的语音 SDK 包。
python -m pip install azure-cognitiveservices-speech
有关 Visual Studio Code 和 Python 的详细信息,请参阅 Visual Studio Code 和 VS Code 中的 Python 入门 。
使用语音 SDK
添加以下 import 语句以在 Python 项目中使用语音 SDK:
import azure.cognitiveservices.speech as speechsdk
相关内容