你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure 通信网关中的可靠性
Azure 通信网关使用 Azure 冗余机制和特定于 SIP 的重试行为来确保服务可靠。 网络必须满足特定要求,以确保服务可用性。
Azure 通信网关的冗余模型
生产 Azure 通信网关部署(也称为标准部署)由三个单独的区域组成:一个管理区域和两个服务区域。 实验室部署由一个管理区域和一个服务区域组成。
本文介绍两种不同的区域类型及其不同的冗余模型。 它涵盖了可用性区域的区域复原能力和灾难恢复的跨区域复原能力。 有关 Azure 中可靠性的更详细概述,请参阅 Azure 可靠性。
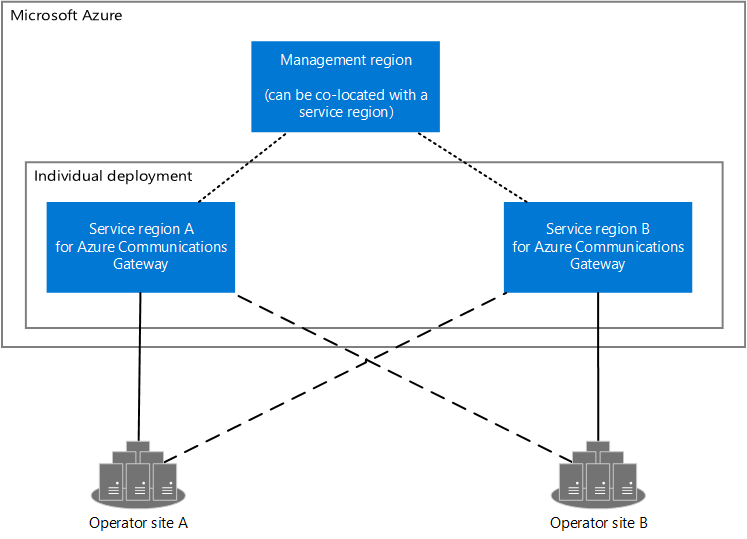
显示两个操作员站点和 Azure 通信网关的 Azure 区域的关系图。 Azure 通信网关有两个服务区域和一个管理区域。 服务区域连接到管理区域和操作员站点。 管理区域可与服务区域并置。
服务区域
服务区域包含用于处理网络与所选通信服务之间的流量的语音和 API 基础结构。
生产 Azure 通信网关部署有两个服务区域,这些服务区域部署在主动-主动模式下(操作员连接和 Teams 电话移动程序需要)。 服务区域之间的快速故障转移在基础结构/IP 级别和应用程序 (SIP/RTP/HTTP) 级别提供。
服务区域还包含 Azure 通信网关预配 API 的基础结构。
提示
生产部署必须始终有两个服务区域,即使选择的服务区域之一位于单区域 Azure 地理(例如卡塔尔)。 如果选择单区域 Azure Geography,请选择其他 Azure Geography 中的第二个 Azure 区域。
服务区域在操作中完全相同,可为区域和区域故障提供复原能力。 每个服务区域都可以使用 Azure 通信网关实例携带 100% 的流量。 因此,最终用户仍应该能够在任何区域或区域停机期间成功拨打和接听呼叫。
实验室部署有一个服务区域。
呼叫路由要求
Azure 通信网关提供“成功的重发”冗余模型:失败对等方处理的呼叫将终止,但新呼叫将路由到正常的对等方。 此模型反映了 Microsoft Teams 提供的冗余模型。
对于生产部署,我们希望你的网络有两个地理冗余站点。 每个站点应与 Azure 通信网关区域配对。 冗余模型依赖于网络与 Azure 通信网关服务区域之间的交叉连接。
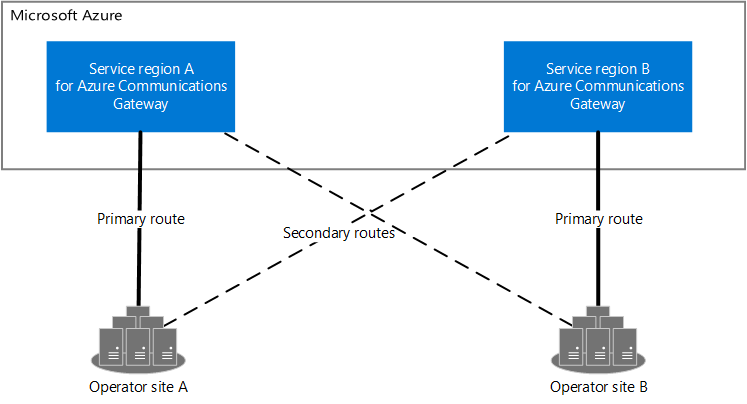
两个操作员站点(操作员站点 A 和操作员站点 B)和两个服务区域(服务区域 A 和服务区域 B)的关系图。 操作员站点 A 具有服务区域 A 的主要路由和服务区域 B 的辅助路由。操作员站点 B 具有服务区域 B 的主要路由,以及服务区域 A 的辅助路由。
实验室部署必须连接到网络中的一个站点。
每个 Azure 通信网关服务区域都提供一条 SRV 记录。 此记录包含提供 SBC 功能(用于将呼叫路由到通信服务)区域内的所有 SIP 对等方。 此 SRV 记录可以指向加入团队提供的 /28 IP 范围中的任何 IP 地址。
如果 Azure 通信网关包括移动控制点 (MCP),则每个服务区域都为 MCP 提供额外的 SRV 记录。 每个区域 MCP 记录都包含区域中优先级最高的 MCP,其他区域中的 MCP 优先级较低。
网络中的每个站点都必须:
- 默认情况下,将流量发送到其本地 Azure 通信网关服务区域。
- 使用 DNS SRV 查找区域中的 Azure 通信网关对等方,如 RFC 3263 中所述。
- 使用
_sip._tls.<regional-FQDN-from-portal>对服务区域与网络连接的域名进行 DNS SRV 查找。 将<regional-FQDN-from-portal>替换为 Azure 门户中你的资源“概述”页面中“主机名”字段中的每区域 FQDN。 例如,如果部署使用commsgw.azure.com域名,请查找第一个区域的_sip._tls.pstn-region1.<deployment-id>.commsgw.azure.com。 - 如果 SRV 查找返回多个目标,请使用每个目标的权重和优先级来选择单个目标。
- 使用
- 向可用的 Azure 通信网关对等方发送新的呼叫。
- 能够从与 Azure 通信网关关联的每个 IP 范围中的任何 IP 地址接收流量。
当网络为 SBC 功能将呼叫路由到 Azure 通信网关的 SIP 对等机时,必须这样做:
- 使用 SIP OPTIONS(或 OPTIONS 和 SIP 流量的组合)监视 Azure 通信网关 SIP 对等互连的可用性。
- 重试接收 408 响应、503 响应或 504 响应或未收到响应的 INVITE,方法是将其重新路由到本地站点中的其他可用对等方。 仅当本地服务区域中的所有对等方都失败时,才搜寻到其他服务区域(由其他区域的 SRV 记录定义)。
- 从不重试接收 408、503 和 504 以外的错误响应的呼叫。
如果 Azure 通信网关部署包括集成的移动控制点 (MCP),则网络必须按如下方式对 MCP 执行以下操作:
- 检测区域中的 MCP 何时不可用,将该区域 SRV 记录的目标标记为不可用,并定期重试以确定区域何时再次可用。 MCP 不响应 SIP OPTIONS。
- 根据组织的策略处理 MCP 的 5xx 响应。 例如,可以重试请求,或者允许呼叫继续,而无需通过 Azure 通信网关和 Microsoft 电话系统。
此路由行为的详细信息特定于网络。 在集成项目期间,你必须同意他们与加入团队的同意。
管理区域
管理区域包含了用于 Azure 通信网关的排序、监视和计费的基础结构。 这些区域中的所有基础结构都以区域冗余的方式部署,这意味着所有数据会自动复制到该区域中的每个可用性区域。 所有关键配置数据也会复制到每个服务区域,以确保在 Azure 区域故障期间服务正常运行。
可用性区域支持
Azure 可用性区域是每个 Azure 地区内的至少三个在物理上独立的数据中心组。 每个区域中的数据中心都配备了独立的电源、冷却系统和网络基础结构。 在本地区域发生故障的情况下,设计可用性区域,以便一个区域受到影响时,其余两个区域支持区域服务、容量和高可用性。
故障范围包括软件和硬件故障,以及地震、洪水和火灾等事件。 容错是通过 Azure 服务的冗余和逻辑隔离来实现的。 有关 Azure 中可用性区域的详细信息,请参阅地区和可用性区域。
已启用 Azure 可用性区域的服务旨在提供适当级别的可靠性和灵活性。 可以通过两种方式进行相关配置。 可以采用区域冗余配置,实现跨区域自动复制,也可以采用区域性配置,将实例固定到特定区域。 还可以将这些方法结合。 有关区域与区域冗余体系结构的详细信息,请参阅有关使用可用性区域和地区的建议。
服务区域的区域关闭体验
在区域范围的中断期间,受影响区域处理的呼叫将终止,在服务自我修复将基础资源重新平衡到正常区域之前,该区域内的容量会短暂丢失。 自我修复功能不依赖于区域还原;Microsoft 托管服务的自我修复状态预期应会利用其他局部区域的容量来补偿丢失的区域。 携带资源的流量以区域冗余的方式进行部署,但在最低规模流量上,流量可能由单个资源处理。 在这种情况下,本文中所述的故障转移机制会将所有流量重新均衡到其他服务区域,同时将携带流量的资源重新部署到正常的区域中。
管理区域的区域关闭体验
在区域范围的服务中断期间,无需在区域恢复过程中执行任何操作。 管理区域自我修复和重新平衡,以自动利用健康区域。
灾难恢复:回退到其他区域
灾难恢复 (DR) 是指从会导致故障时间和数据丢失的高影响事件(例如自然灾害或部署失败)中恢复。 不管灾难的原因是什么,最好的补救措施就是一个定义全面且经过测试的 DR 计划,以及一个主动支持 DR 的应用程序设计。 在开始考虑创建灾难恢复计划之前,请参阅设计灾难恢复策略的建议。
在 DR 方面,Microsoft 使用责任共担模型。 在共担责任模型中,Microsoft 会确保基线基础结构和平台服务可用。 同时,许多 Azure 服务不会自动复制数据,也不会从失败区域回退以交叉复制到另一个启用的区域。 对于这些服务,你负责设置适用于工作负载的灾难恢复计划。 大多数在 Azure 平台即服务 (PaaS) 产品/服务上运行的服务都提供支持 DR 的功能和指导,你可以使用特定于服务的功能来支持快速恢复,从而帮助制定 DR 计划。
本部分介绍区域范围的服务中断期间 Azure 通信网关的行为。
灾难恢复:服务区域的跨区域故障转移
在区域范围的服务中断期间,本文中所述的故障转移机制(选项轮询和 SIP 重试失败)会将所有呼叫流量重新均衡到其他服务区域,从而保持可用性。 我们将开始还原区域冗余。 在长时间停机期间还原区域冗余可能需要使用其他 Azure 区域。 如果需要将失败的区域迁移到另一个区域,我们将在开始任何迁移之前咨询你。
Azure 通信网关中的 SBC 函数提供 OPTIONS 轮询,使网络能够确定对等可用性。 对于 MCP,网络必须能够检测 MCP 何时不可用,并定期重试以确定 MCP 何时再次可用。 MCP 不响应 SIP OPTIONS。
预配 API 客户端使用部署的基本域名联系 Azure 通信网关。 此域的 DNS 记录的生存时间 (TTL) 为 60 秒。 当某个区域发生故障时,Azure 会更新 DNS 记录以引用另一个区域,因此发出新的 DNS 查找的客户端将收到新区域的详细信息。 建议确保客户端可以在超时或 5xx 响应后 60 秒重试请求,并进行新的 DNS 查找。
提示
实验室部署不提供跨区域故障转移(因为它们只有一个服务区域)。
灾难恢复:管理区域的跨区域故障转移
通过号码管理门户进行的语音流量和预配不受管理区域中故障的影响,因为相应的 Azure 资源托管在服务区域中。 号码管理门户的用户可能需要再次登录。
在还原服务之前,监视服务可能暂时不可用。 如果管理区域遇到延长停机时间,我们将受影响的资源迁移到另一个可用区域。
选择管理和服务区域
Azure 通信网关的单个部署旨在处理地理区域内的流量。 在同一地理区域(例如北美)内部署生产部署中的这两个服务区域。 此模型可确保语音呼叫的延迟保持在操作员连接和 Teams 电话移动程序所需的限制范围内。
选择服务区域位置时,请考虑以下几点:
- 从可用 Azure 区域列表中选择。 可以在“产品按区域”页上看到可以选择为服务区域的 Azure 区域。
- 选择靠近自己的本地的区域以及网络与 Microsoft 之间的对等互连位置,以减少呼叫延迟。
- 首选区域对,以最大程度地减少发生多区域中断时的恢复时间。
从以下列表中选择管理区域:
- 美国东部
- 美国中西部
- 西欧
- 英国南部
- 印度中部
- 加拿大中部
- 澳大利亚东部
管理区域可以与服务区域并置。 建议选择离服务区域最近的管理区域。
注意
如果你正在启用 Azure 运营商通话保护预览版,则你选择的服务区域可能不是部署支持资源的 Azure 区域。 如需当前支持的 Azure 运营商通话保护服务区域的列表,请参阅按区域列出的 Azure 产品,并在有关于选择哪个区域的问题时与你的加入团队交谈。
服务级别协议
本文档中所述的可靠性设计由 Microsoft 实现,不可配置。 有关 Azure 通信网关服务级别协议 (SLA) 的详细信息,请参阅 Azure 通信网关 SLA。
后续步骤
- 了解如何将 Azure 通信网关连接到网络
- 了解 Azure 通信网关如何保护网络和数据安全
- 详细了解如何规划 Azure 通信网关部署
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈