你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure 数据工厂或 Azure Synapse Analytics 从 Amazon RDS for SQL Server 复制数据
本文概述如何使用 Azure 数据工厂和 Azure Synapse 管道中的复制活动从 Amazon RDS for SQL Server 复制数据。 有关详细信息,请阅读 Azure 数据工厂或 Azure Synapse Analytics 的简介文章。
支持的功能
此 Amazon RDS for SQL Server 连接器支持以下功能:
| 支持的功能 | IR |
|---|---|
| 复制活动(源/-) | ① ② |
| Lookup 活动 | ① ② |
| GetMetadata 活动 | ① ② |
| 存储过程活动 | ① ② |
① Azure 集成运行时 ② 自承载集成运行时
有关复制活动支持作为源或接收器的数据存储列表,请参阅支持的数据存储表。
具体而言,此 Amazon RDS for SQL Server 连接器支持:
- SQL Server 版本 2005 及更高版本。
- 使用 SQL 或 Windows 身份验证复制数据。
- 作为源,使用 SQL 查询或存储过程检索数据。 还可以选择从 Amazon RDS for SQL Server 源并行复制,有关详细信息,请参阅从 SQL 数据库进行并行复制部分。
SQL Server Express LocalDB 不受支持。
先决条件
如果数据存储位于本地网络、Azure 虚拟网络或 Amazon Virtual Private Cloud 内部,则需要配置自承载集成运行时才能连接到该数据存储。
如果数据存储是托管的云数据服务,则可以使用 Azure Integration Runtime。 如果访问范围限制为防火墙规则中允许的 IP,你可以选择将 Azure Integration Runtime IP 添加到允许列表。
此外,还可以使用 Azure 数据工厂中的托管虚拟网络集成运行时功能访问本地网络,而无需安装和配置自承载集成运行时。
要详细了解网络安全机制和数据工厂支持的选项,请参阅数据访问策略。
入门
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建 Amazon RDS for SQL Server 链接服务
使用以下步骤在 Azure 门户 UI 中创建 Amazon RDS for SQL Server 链接服务。
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡并选择“链接服务”,然后单击“新建”:
搜索 Amazon RDS for SQL Server 并选择 Amazon RDS for SQL Server 连接器。
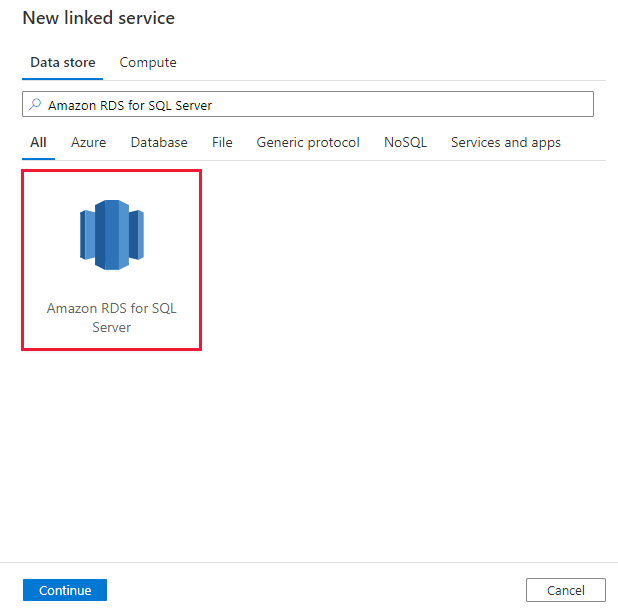
配置服务详细信息、测试连接并创建新的链接服务。
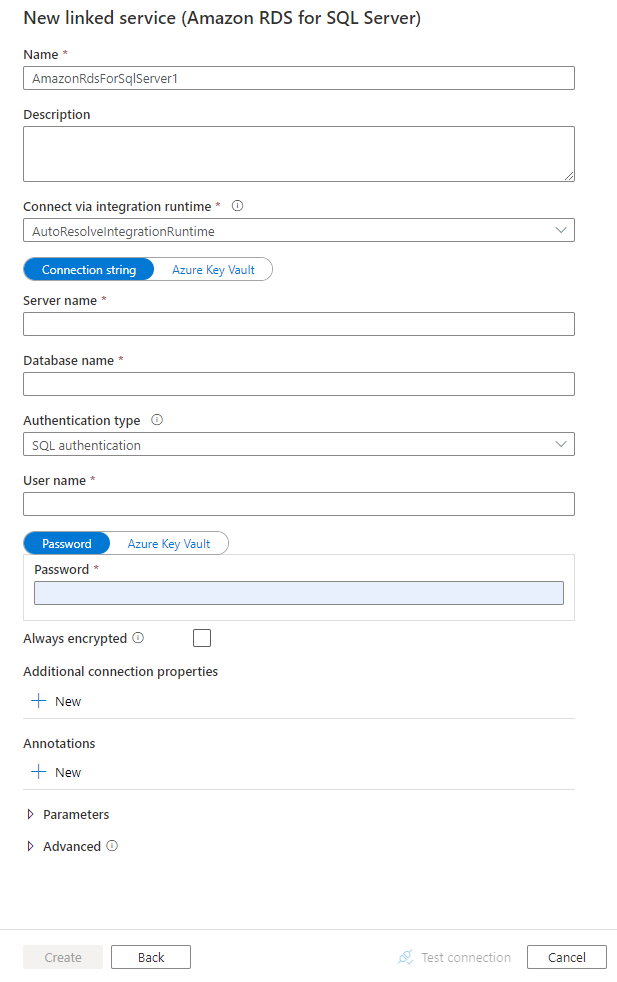
连接器配置详细信息
对于特定于 Amazon RDS for SQL Server 数据库连接器的数据工厂和 Synapse 管道实体,以下部分提供有关用于定义这些实体的属性的详细信息。
链接服务属性
Amazon RDS for SQL Server 连接器推荐版本支持 TLS 1.3。 请参阅此部分,了解如何将 Amazon RDS for SQL Server 连接器版本从旧版升级。 有关属性详细信息,请参阅相应部分。
注意
数据流中不支持 Amazon RDS for SQL Server 的“Always Encrypted”功能。
提示
如果遇到错误(错误代码为“UserErrorFailedToConnectToSqlServer”,且消息如“数据库的会话限制为 XXX 且已达到。”),请将 Pooling=false 添加到连接字符串中,然后重试。
建议的版本
应用推荐版本时,Amazon RDS for SQL Server 链接服务支持以下通用属性:
| properties | 描述 | 必需 |
|---|---|---|
| type | type 属性必须设置为 AmazonRdsForSqlServer。 | 是 |
| 服务器 | 要连接到的 SQL Server 实例的名称或网络地址。 | 是 |
| database | 数据库的名称。 | 是 |
| authenticationType | 用于身份验证的类型。 允许的值为 SQL(默认)、Windows。 请转到有关特定属性和先决条件的相关身份验证部分。 | 是 |
| alwaysEncryptedSettings | 指定 alwaysencryptedsettings 信息,要启用“Always Encrypted”以使用托管标识或服务主体来保护存储在 Amazon RDS for SQL Server 中的敏感数据,该信息是必需的。 有关详细信息,请参阅表格后面的 JSON 示例以及使用 Always Encrypted 部分。 如果不指定此属性,将禁用默认的 Always Encrypted 设置。 | 否 |
| 加密 | 指示客户端和服务器之间发送的所有数据是否需要 TLS 加密。 选项:必需(对于 true,默认值)/可选(对于 false)/严格。 | 否 |
| trustServerCertificate | 指示在绕过用于验证信任的证书链时是否加密通道。 | 否 |
| hostNameInCertificate | 验证连接的服务器证书时要使用的主机名。 如果未指定,则服务器名称用于证书验证。 | 否 |
| connectVia | 此集成运行时用于连接到数据存储。 从先决条件部分了解更多信息。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
有关其他连接属性,请查看下表:
| properties | 描述 | 必须 |
|---|---|---|
| applicationIntent | 连接到服务器时的应用程序工作负载类型。 允许的值为 ReadOnly 和 ReadWrite。 |
否 |
| connectTimeout | 在终止尝试并生成错误之前等待与服务器建立连接的时间(以秒为单位)。 | 否 |
| connectRetryCount | 识别空闲连接失败后尝试的重新连接次数。 该值应为介于 0 到 255 之间的整数。 | 否 |
| connectRetryInterval | 识别空闲连接失败后,每次重新连接尝试之间的时间(以秒为单位)。 该值应为介于 1 到 60 之间的整数。 | 否 |
| loadBalanceTimeout | 在连接被断开之前,连接在连接池中存在的最短时间(以秒为单位)。 | 否 |
| commandTimeout | 在终止尝试执行命令并生成错误之前的默认等待时间(以秒为单位)。 | 否 |
| integratedSecurity | 允许的值为 true 或 false。 指定 false 时,指示是否在连接中指定了 userName 和密码。 指定 true 时,指示当前 Windows 帐户凭据是否用于身份验证。 |
否 |
| failoverPartner | 主服务器关闭时要连接到的伙伴服务器的名称或地址。 | 否 |
| maxPoolSize | 特定连接的连接池中允许的最大连接数。 | 否 |
| minPoolSize | 特定连接的连接池中允许的最小连接数。 | 否 |
| multipleActiveResultSets | 允许的值为 true 或 false。 指定 true 时,应用程序可维护多重活动结果集 (MARS)。 指定 false 时,应用程序必须先处理或取消从某一批处理生成的所有结果集,然后才能对该连接执行任何其他批处理。 |
否 |
| multiSubnetFailover | 允许的值为 true 或 false。 如果你的应用程序要连接到不同子网上的 AlwaysOn 可用性组 (AG),那么将此属性设置为 true 会加快检测和连接到当前活动服务器。 |
否 |
| packetSize | 用于与服务器实例通信的网络数据包的大小(字节数)。 | 否 |
| 池 | 允许的值为 true 或 false。 指定 true 时,连接将共用。 指定 false 时,每次请求连接时都会显式打开连接。 |
否 |
SQL 身份验证
若要使用 SQL 身份验证,除了前面部分所述的通用属性,还指定以下属性:
| properties | 描述 | 必选 |
|---|---|---|
| userName | 用于连接到服务器的用户名。 | 是 |
| password | 对应于用户名的密码。 将此字段标记为 SecureString 以安全存储它。 或者,可以引用 Azure Key Vault 中存储的机密。 | 是 |
示例:使用 SQL 身份验证
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
示例:将 SQL 身份验证与 Azure Key Vault 中的密码结合使用
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
示例:使用 Always Encrypted
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Windows 身份验证
若要使用 Windows 身份验证,则除了上一部分所述的通用属性外,还需要指定以下属性:
| properties | 描述 | 必选 |
|---|---|---|
| userName | 指定用户名。 例如 domainname\username。 | 是 |
| password | 指定为用户名指定的用户帐户的密码。 将此字段标记为 SecureString 以安全存储它。 或者,可以引用 Azure Key Vault 中存储的机密。 | 是 |
示例:使用 Windows 身份验证
{
"name": "AmazonSqlLinkedService",
"properties": {
"type": "AmazonRdsForSqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
旧版本
应用旧版本时,Amazon RDS for SQL Server 链接服务支持以下通用属性:
| properties | 描述 | 必需 |
|---|---|---|
| type | type 属性必须设置为 AmazonRdsForSqlServer。 | 是 |
| alwaysEncryptedSettings | 指定 alwaysencryptedsettings 信息,要启用“Always Encrypted”以使用托管标识或服务主体来保护存储在 Amazon RDS for SQL Server 中的敏感数据,该信息是必需的。 有关详细信息,请参阅使用 Always Encrypted 部分。 如果不指定此属性,将禁用默认的 Always Encrypted 设置。 | 否 |
| connectVia | 此集成运行时用于连接到数据存储。 从先决条件部分了解更多信息。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
此 Amazon RDS for SQL Server 连接器支持以下身份验证类型。 有关详细信息,请参阅相应部分。
旧版本的 SQL 身份验证
若要使用 SQL 身份验证,则除了上一部分所述的通用属性外,还需要指定以下属性:
| properties | 描述 | 必需 |
|---|---|---|
| connectionString | 指定连接到 Amazon RDS for SQL Server 数据库所需的 connectionString 信息。 指定登录名作为用户名,并确保要连接的数据库映射到此登录名。 | 是 |
| password | 如果要将密码放在 Azure Key Vault 中,请从连接字符串中拉取 password 配置。 有关详细信息,请参阅在 Azure 密钥保管库中存储凭据。 |
否 |
旧版本的 Windows 身份验证
若要使用 Windows 身份验证,则除了上一部分所述的通用属性外,还需要指定以下属性:
| properties | 描述 | 必需 |
|---|---|---|
| connectionString | 指定连接到 Amazon RDS for SQL Server 数据库所需的 connectionString 信息。 | 是 |
| userName | 指定用户名。 例如 domainname\username。 | 是 |
| password | 指定为用户名指定的用户帐户的密码。 将此字段标记为 SecureString 以安全存储它。 或者,可以引用 Azure Key Vault 中存储的机密。 | 是 |
数据集属性
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集一文。 本部分提供 Amazon RDS for SQL Server 数据集支持的属性列表。
要从 Amazon RDS for SQL Server 数据库复制数据,支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 数据集的 type 属性必须设置为 AmazonRdsForSqlServerTable。 | 是 |
| schema | 架构的名称。 | 否 |
| 表 | 表/视图的名称。 | 否 |
| tableName | 具有架构的表/视图的名称。 此属性支持后向兼容性。 对于新的工作负荷,请使用 schema 和 table。 |
否 |
示例
{
"name": "AmazonRdsForSQLServerDataset",
"properties":
{
"type": "AmazonRdsForSqlServerTable",
"linkedServiceName": {
"referenceName": "<Amazon RDS for SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
复制活动属性
有关可用于定义活动的节和属性的完整列表,请参阅管道一文。 本部分提供 Amazon RDS for SQL Server 源支持的属性列表。
Amazon RDS for SQL Server 作为源
提示
若要使用数据分区从 Amazon RDS for SQL Server 高效加载数据,请参阅从 SQL 数据库进行并行复制了解详细信息。
要从 Amazon RDS for SQL Server 复制数据,请将复制活动中的源类型设置为 AmazonRdsForSqlServerSource。 复制活动的 source 节支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 复制活动源的 type 属性必须设置为 AmazonRdsForSqlServerSource。 | 是 |
| sqlReaderQuery | 使用自定义 SQL 查询读取数据。 例如 select * from MyTable。 |
否 |
| sqlReaderStoredProcedureName | 此属性是从源表读取数据的存储过程的名称。 最后一个 SQL 语句必须是存储过程中的 SELECT 语句。 | 否 |
| storedProcedureParameters | 这些参数用于存储过程。 允许的值为名称或值对。 参数的名称和大小写必须与存储过程参数的名称和大小写匹配。 |
否 |
| isolationLevel | 指定 SQL 源的事务锁定行为。 允许的值为:ReadCommitted、ReadUncommitted、RepeatableRead、Serializable、Snapshot 。 如果未指定,则使用数据库的默认隔离级别。 请参阅此文档了解更多详细信息。 | 否 |
| partitionOptions | 指定用于从 Amazon RDS for SQL Server 加载数据的数据分区选项。 允许值包括:None(默认值)、PhysicalPartitionsOfTable 和 DynamicRange 。 启用分区选项(即该选项不为 None)时,从 Amazon RDS for SQL Server 并发加载数据的并行度由复制活动上的 parallelCopies 设置控制。 |
否 |
| partitionSettings | 指定数据分区的设置组。 当分区选项不是 None 时适用。 |
否 |
在 partitionSettings 下: |
||
| partitionColumnName | 以整数类型、日期类型或日期/时间类型(int、smallint、bigint、date、smalldatetime、datetime、datetime2 或 datetimeoffset)指定源列的名称,范围分区将使用它进行并行复制。 如果未指定,系统会自动检测表的索引或主键并将其用作分区列。当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?DfDynamicRangePartitionCondition 。 有关示例,请参阅从 SQL 数据库进行并行复制部分。 |
否 |
| partitionUpperBound | 分区范围拆分的分区列的最大值。 此值用于决定分区步幅,不用于筛选表中的行。 将对表或查询结果中的所有行进行分区和复制。 如果未指定,复制活动会自动检测该值。 当分区选项是 DynamicRange 时适用。 有关示例,请参阅从 SQL 数据库进行并行复制部分。 |
否 |
| partitionLowerBound | 分区范围拆分的分区列的最小值。 此值用于决定分区步幅,不用于筛选表中的行。 将对表或查询结果中的所有行进行分区和复制。 如果未指定,复制活动会自动检测该值。 当分区选项是 DynamicRange 时适用。 有关示例,请参阅从 SQL 数据库进行并行复制部分。 |
否 |
请注意以下几点:
- 如果为 AmazonRdsForSqlServerSource 指定 sqlReaderQuery,则复制活动针对 Amazon RDS for SQL Server 源运行此查询以获取数据。 也可通过指定 sqlReaderStoredProcedureName 和 storedProcedureParameters 来指定存储过程,前提是存储过程使用参数 。
- 在源中使用存储过程检索数据时,请注意,如果存储过程旨在当传入不同的参数值时返回不同的架构,则从 UI 导入架构时,或通过自动创建表的功能将数据复制到 SQL 数据库时,可能会遇到故障或出现意外的结果。
示例:使用 SQL 查询
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
示例:使用存储过程
"activities":[
{
"name": "CopyFromAmazonRdsForSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForSqlServerSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
存储过程定义
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
从 SQL 数据库进行并行复制
复制活动中的 Amazon RDS for SQL Server 连接器提供内置的数据分区,用于并行复制数据。 可以在复制活动的“源”表中找到数据分区选项。
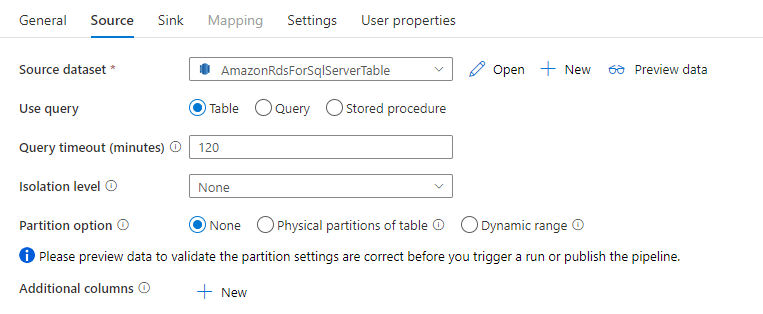
启用分区复制时,复制活动将对 Amazon RDS for SQL Server 源运行并行查询,以按分区加载数据。 可通过复制活动中的 parallelCopies 设置控制并行度。 例如,如果将 parallelCopies 设置为 4,则该服务会根据指定的分区选项和设置并发生成并运行 4 个查询,每个查询从 Amazon RDS for SQL Server 检索一部分数据。
建议同时启用并行复制和数据分区,尤其是从 Amazon RDS for SQL Server 加载大量数据时。 下面是适用于不同方案的建议配置。 将数据复制到基于文件的数据存储中时,建议将数据作为多个文件写入文件夹(仅指定文件夹名称),在这种情况下,性能优于写入单个文件。
| 方案 | 建议的设置 |
|---|---|
| 从包含物理分区的大型表进行完整加载。 | 分区选项:表的物理分区。 在执行期间,该服务将自动检测物理分区并按分区复制数据。 若要检查表是否有物理分区,可参考此查询。 |
| 从不包含物理分区但包含用于数据分区的整数或日期时间列的大型表进行完整加载。 | 分区选项:动态范围分区。 分区列(可选):指定用于对数据进行分区的列。 如果未指定,将使用主键列。 分区上限和分区下限(可选) :指定是否要确定分区步幅。 这不适用于筛选表中的行,表中的所有行都将进行分区和复制。 如果未指定,则复制活动将自动检测值,这可能需要花费很长时间,具体取决于“最小值”和“最大值”。 建议提供上限和下限。 例如,如果分区列“ID”的值范围为 1 至 100,并且将此值的下限设置为 20、上限设置为 80,并行复制设置为 4,服务将按 4 个分区(分区的 ID 范围分别为 <=20、[21, 50]、[51, 80] 和 >=81)检索数据。 |
| 使用自定义查询从不包含物理分区但包含用于数据分区的整数或日期/日期时间列的表加载大量数据。 | 分区选项:动态范围分区。 查询: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>。分区列:指定用于对数据进行分区的列。 分区上限和分区下限(可选) :指定是否要确定分区步幅。 这不适用于筛选表中的行,查询结果中的所有行都将进行分区和复制。 如果未指定,复制活动会自动检测该值。 例如,如果分区列“ID”的值范围为 1 至 100,并且将此值的下限设置为 20、上限设置为 80,并行复制设置为 4,服务将按 4 个分区(分区的 ID 范围分别为 <=20、[21, 50]、[51, 80] 和 >=81)检索数据。 下面是针对不同场景的更多示例查询: 1.查询整个表: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2.使用列选择和附加的 where 子句筛选器从表中查询: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3.使用子查询进行查询: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4.在子查询中使用分区查询: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
使用分区选项加载数据的最佳做法:
- 选择独特的列作为分区列(如主键或唯一键),以避免数据倾斜。
- 如果表具有内置分区,请使用名为“表的物理分区”分区选项来提升性能。
- 如果使用 Azure Integration Runtime 复制数据,则可设置较大的“数据集成单元 (DIU)”(>4) 以利用更多计算资源。 检查此处适用的方案。
- “复制并行度”可控制分区数量,将此数字设置得太大有时会损害性能,建议将此数字设置按以下公式计算的值:(DIU 或自承载 IR 节点数)*(2 到 4)。
示例:从包含物理分区的大型表进行完整加载
"source": {
"type": "AmazonRdsForSqlServerSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
示例:使用动态范围分区进行查询
"source": {
"type": "AmazonRdsForSqlServerSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
检查物理分区的示例查询
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
如果表具有物理分区,你可看到“HasPartition”为“是”,如下所示。

查找活动属性
若要了解有关属性的详细信息,请查看 Lookup 活动。
GetMetadata 活动属性
若要了解有关属性的详细信息,请查看 GetMetadata 活动
使用 Always Encrypted
从/向启用了“Always Encrypted”的 Amazon RDS for SQL Server 复制数据时,请遵循以下步骤:
将列主密钥 (CMK) 存储在 Azure 密钥保管库中。 详细了解如何使用 Azure 密钥保管库配置 Always Encrypted
确保授予对存储了列主密钥 (CMK) 的密钥保管库的访问权限。 有关所需的权限,请参阅此文。
创建链接服务,以使用托管标识或服务主体连接到 SQL 数据库并启用“Always Encrypted”功能。
排查连接问题
配置 Amazon RDS for SQL Server 实例以接受远程连接。 启动 Amazon RDS for SQL Server Management Studio,右键单击服务器,然后选择“属性”。 从列表中选择“连接”,并选中“允许远程连接到此服务器”复选框 。
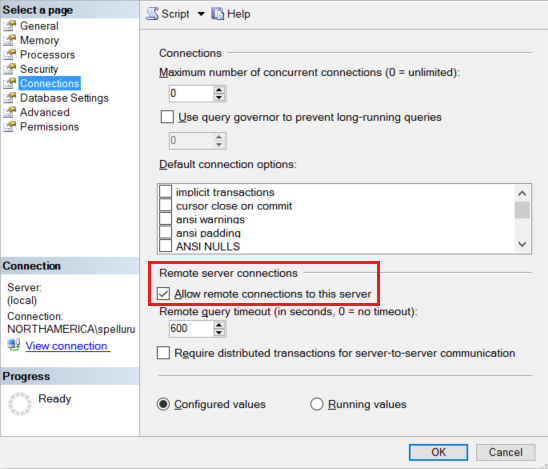
有关详细步骤,请参阅配置远程访问服务器配置选项。
启动“Amazon RDS for SQL Server 配置管理器”。 针对所需实例展开“Amazon RDS for SQL Server 网络配置”,并选择“MSSQLSERVER 的协议” 。 协议将显示在右窗格中。 右键单击“TCP/IP”并选择“启用”以启用 TCP/IP 。
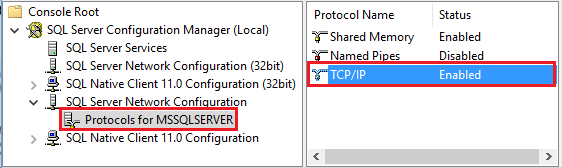
有关详细信息和启用 TCP/IP 协议的其他方法,请参阅启用或禁用服务器网络协议。
在同一窗口中,双击“TCP/IP”以启动“TCP/IP 属性”窗口 。
切换到“IP 地址”选项卡。向下滚动到“IPAll”部分。 记下“TCP 端口”的值。 默认值为 1433。
在计算机上创建 Windows 防火墙规则,以便允许通过此端口传入流量。
验证连接:若要使用完全限定的名称连接到 Amazon RDS for SQL Server,请从另一台计算机使用 Amazon RDS for SQL Server Management Studio。 示例为
"<machine>.<domain>.corp.<company>.com,1433"。
升级 Amazon RDS for SQL Server 版本
若要升级 Amazon RDS for SQL Server 版本,请在“编辑链接服务”页中,选择“版本”下的“推荐”,并参考推荐版本的链接服务属性来配置链接服务。
建议版本和旧版本之间的差异
下表显示了使用建议版本和旧版本的 Amazon RDS for SQL Server 之间的功能差异。
| 建议的版本 | 旧版本 |
|---|---|
支持通过 encrypt 作为 strict 的 TLS 1.3。 |
不支持 TLS 1.3。 |
相关内容
有关复制活动支持作为源和接收器的数据存储的列表,请参阅受支持的数据存储。