计算
Azure Databricks 计算是指可以选择在 Azure Databricks 工作区中可用的计算资源。 用户需要访问计算才能运行数据工程、数据科学和数据分析工作负载,例如生产 ETL 管道、流分析、即席分析和机器学习。
用户可以连接到现有计算,也可以创建新计算(如果具有适当的权限)。
可以使用工作区的“计算”部分查看你有权访问的计算:
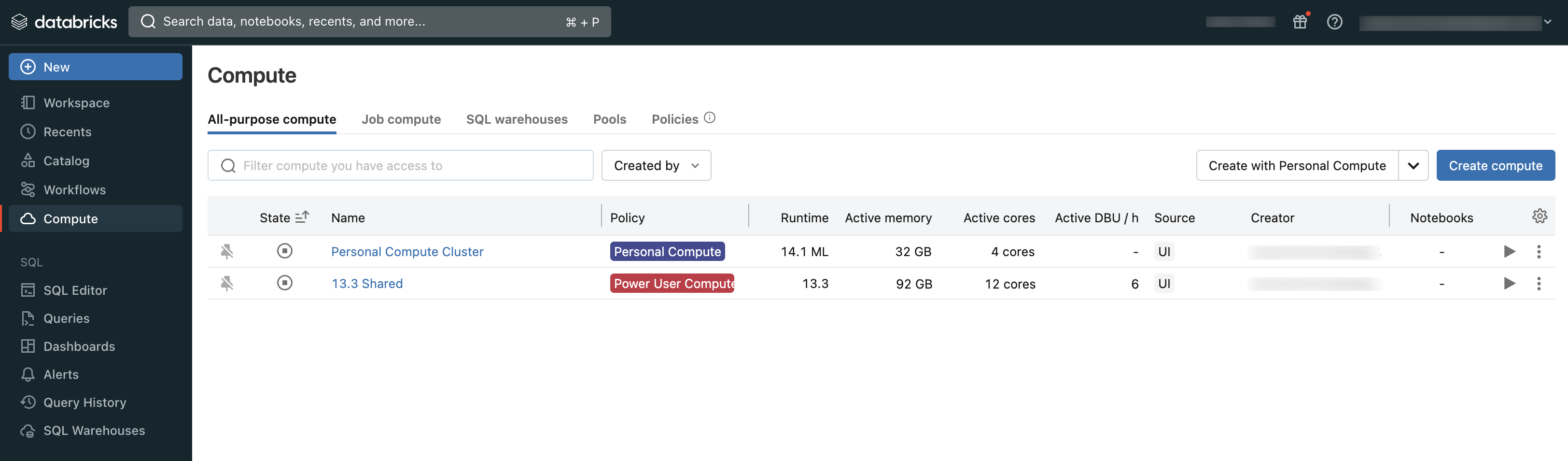
计算类型
Azure Databricks 中提供以下类型的计算:
适用于笔记本的无服务器计算:用于在笔记本中执行 SQL 和 Python 代码的按需可缩放计算。
适用于作业的无服务器计算:用于运行 Databricks 作业的按需可缩放计算,无需配置和部署基础结构。
作业计算:用于运行自动化作业的预配计算。 每次将作业配置为在新计算上运行时,Azure Databricks 作业计划程序就会自动创建作业计算。 计算会在作业完成时终止。 无法重启作业群集。 请参阅配置作业的计算。
实例池:具有空闲、现成实例的计算,用于减少启动和自动缩放时间。 可以使用 UI、CLI 或 REST API 创建此计算。
无服务器 SQL 仓库:用于对 SQL 编辑器或交互式笔记本中的数据对象运行 SQL 命令的按需弹性计算。 可以使用 UI、CLI 或 REST API 创建 SQL 仓库。
经典 SQL 仓库:用于对 SQL 编辑器或交互式笔记本中的数据对象运行 SQL 命令。 可以使用 UI、CLI 或 REST API 创建 SQL 仓库。
本部分中的文章介绍如何使用 Azure Databricks UI 处理计算资源。 有关其他方法,请参阅什么是 Databricks CLI?和 Databricks REST API 参考。
Databricks Runtime
Databricks Runtime 是在计算上运行的核心组件集。 Databricks Runtime 是通用作业计算中的可配置设置,但在 SQL 仓库中自动选择。
每个 Databricks Runtime 版本都包含可提高大数据分析的可用性、性能和安全性的更新。 计算上的 Databricks Runtime 添加了许多功能,包括:
- Delta Lake 是基于 Apache Spark 构建的下一代存储层,可提供 ACID 事务、优化的布局和索引以及针对数据管道生成的执行引擎改进。 请参阅什么是 Delta Lake?。
- 已安装的 Java、Scala、Python 和 R 库。
- Ubuntu 及其随附的系统库。
- 启用了 GPU 的群集的 GPU 库。
- 与平台的其他组件(如笔记本、作业和群集管理)集成的 Azure Databricks 服务。
有关每个运行时版本的内容的信息,请参阅发行说明。
运行时版本控制
将定期发布 Databricks Runtime 版本:
- 长期支持版本由 LTS 限定符(例如 3.5 LTS)表示。 对于每个主要版本,我们都声明一个“规范”功能版本,并为其提供为期三年的支持。 有关详细信息,请参阅 Databricks 支持生命周期。
- 主版本的变化通过递增小数点之前的版本号来表示(例如从 3.5 跳转到 4.0)。 它们在发生重大更改时发布,其中一些可能无法向后兼容。
- 功能版本的变化通过递增小数点之后的版本号来表示(例如从 3.4 跳转到 3.5)。 每个主要版本都包含多个功能版。 功能版总是向后兼容其主要版本中的先前版本。