什么是 Mosaic AI 代理框架?
重要
此功能目前以公共预览版提供。
代理框架包括 Databricks 上的一组工具,这些工具旨在帮助开发人员构建、部署和评估生产质量代理,例如检索增强生成 (RAG) 应用程序。
本文介绍了代理框架是什么以及在 Azure Databricks 上开发 RAG 应用程序的好处。
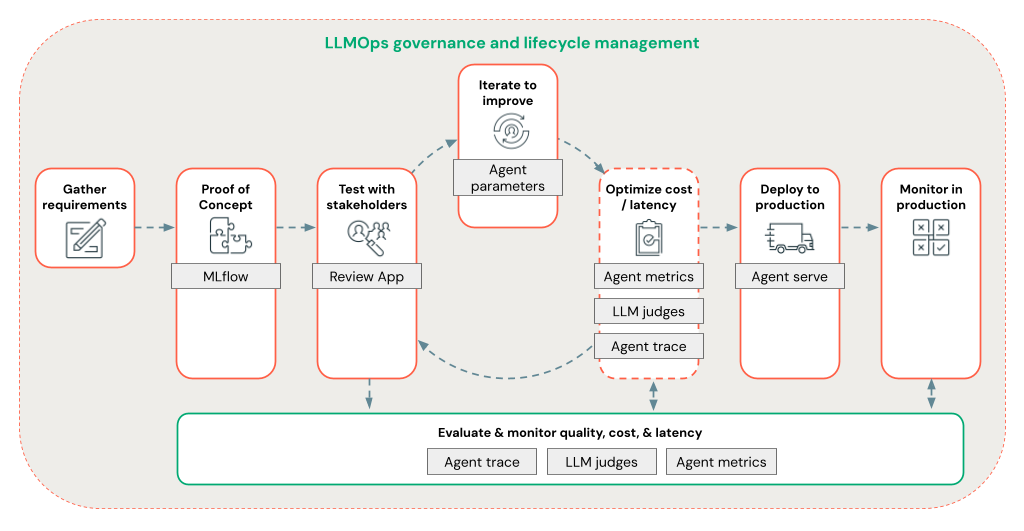
代理框架使开发人员能够通过端到端 LLMOps 工作流快速循环访问 RAG 开发的各个方面。
要求
- 必须为工作区启用 Azure AI 服务 AI 辅助功能。
- 代理应用程序的所有组件都必须在单一工作区中。 例如,在 RAG 应用程序的情况下,服务模型和矢量搜索实例需要位于同一工作区中。
生产级 RAG 开发
使用以下功能快速迭代代理开发:
使用任何库和 MLflow 创建和记录代理。 将代理参数化以快速试验和迭代代理开发。
部署代理到生产环境,并提供对令牌流式处理和请求/响应日志记录的本机支持,以及内置的评审应用,以获取代理的用户反馈。
代理跟踪使你能够记录、分析和比较代理代码中的跟踪,从而调试和了解代理如何响应请求。
什么是 RAG?
RAG 是一种生成式 AI 设计技术,可通过外部知识增强大型语言模型 (LLM)。 该技术通过以下方式改进 LLM:
- 专有知识:RAG 可以包含最初未用于训练 LLM 的专有信息,例如备忘录、电子邮件和用于回答特定领域问题的文档。
- 最新信息:RAG 应用程序可以为 LLM 提供来自更新数据源的信息。
- 引用来源:RAG 使 LLM 能够引用特定来源,从而允许用户验证响应的事实准确性。
- 数据安全和访问控制列表 (ACL):检索步骤可以设计为根据用户凭据有选择地检索个人或专有信息。
复合 AI 系统
RAG 应用程序是复合 AI 系统的一个示例:它通过与其他工具和程序相结合来扩展 LLM 的语言功能。
在最简单的形式下,RAG 应用程序执行以下操作:
- 检索:用户的请求用于查询外部数据存储,例如矢量存储、文本关键字搜索或 SQL 数据库。 目标是获取 LLM 响应的支持数据。
- 增强:检索到的数据与用户的请求相结合,通常使用带有附加格式和说明的模板来创建提示。
- 生成:提示传递给 LLM,然后 LLM 生成对查询的响应。
RAG 和生成式 AI 用例
下表列出了一些 RAG 用例。
| 用例 | 说明 |
|---|---|
| 问答聊天机器人 | 将 LLM 与聊天机器人结合使用,从公司文档和知识库中获取准确的答案。 聊天机器人可以自动提供客户支持并跟进网站线索,以快速回答问题并解决问题。 |
| 搜索增强 | 将 LLM 和搜索引擎结合使用,通过 LLM 生成的答案增强搜索结果,使用户更容易找到他们需要的信息。 |
| 知识引擎 | 使用公司数据(如人力资源和合规性文档)作为 LLM 的上下文,让员工轻松获得有关福利、政策、安全性和合规性问题的答案。 |
非结构化与结构化 RAG 数据
RAG 体系结构可以使用非结构化或结构化的支持数据。 在 RAG 中使用的数据取决于你的用例。
非结构化数据:没有特定结构或组织的数据。 包含文本和图像或多媒体内容(如音频或视频)的文档。
- Google/Office 文档
- Wiki
- 映像
- 视频
结构化数据:以特定架构按行和列排列的表格数据,例如数据库中的表。
- BI 或 Data Warehouse 系统中的客户记录
- 来自 SQL 数据库的交易数据
- 来自应用程序 API(例如 SAP、Salesforce 等)的数据
以下部分介绍了适用于非结构化数据的 RAG 应用程序。
RAG 数据管道
RAG 数据管道可以预处理和索引文档,以便快速准确地检索。
下图显示了使用语义搜索算法的非结构化数据集的示例数据管道。 Databricks 作业会协调每个步骤。
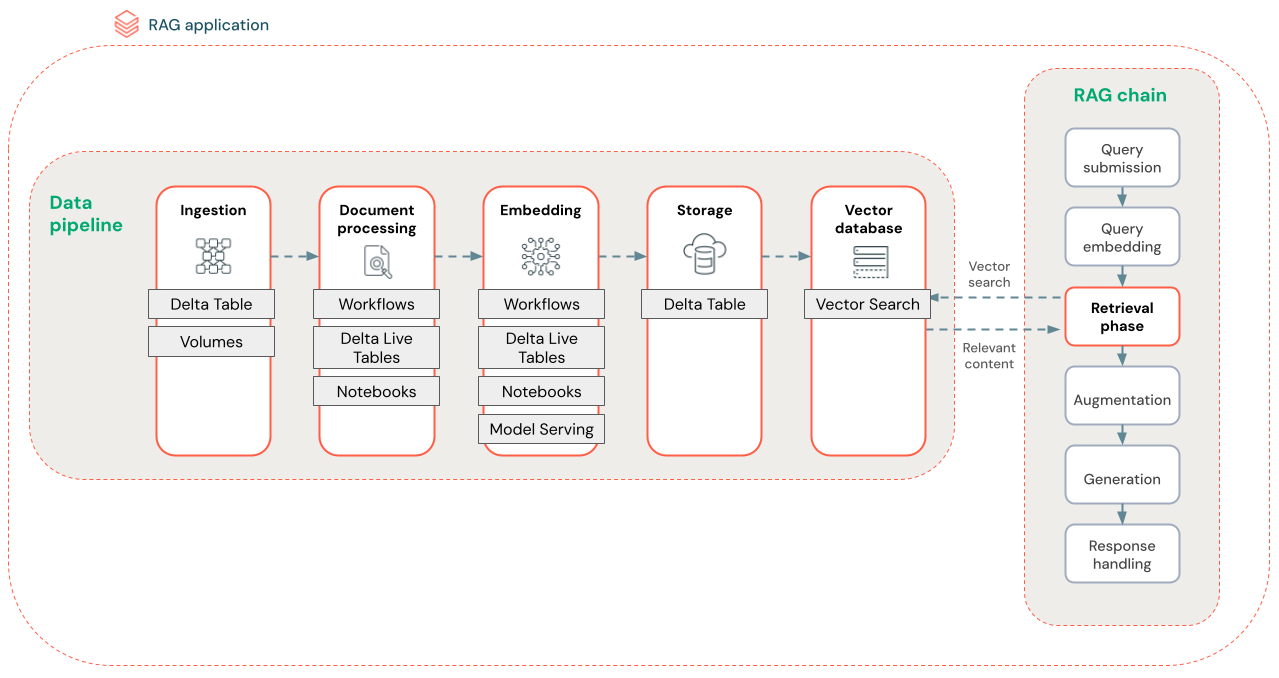
- 数据引入 - 从专有源引入数据。 将此数据存储在 Delta 表或 Unity Catalog 卷中。
- 文档处理:可以使用 Databricks 作业、Databricks 笔记本和 Delta Live Tables 来执行这些任务。
- 分析原始文档:将原始数据转换为可用格式。 例如,从 PDF 集合中提取文本、表格和图像,或使用光学字符识别技术从图像中提取文本。
- 提取元数据:提取文档元数据(如文档标题、页码和 URL),以帮助检索步骤更准确地查询。
- 区块文档:将数据拆分为适合 LLM 上下文窗口的区块。 检索这些重点区块(而不是整个文档)可为 LLM 提供更有针对性的内容来生成响应。
- 嵌入区块 - 嵌入模型使用块来创建信息的数字表示,称为矢量嵌入。 矢量表示文本的语义含义,而不仅仅是图面级关键字。 在这种情况下,可以计算嵌入并使用模型服务来为嵌入模型提供服务。
- 嵌入存储 - 将矢量嵌入和区块的文本存储在与矢量搜索同步的 Delta 表中。
- 矢量数据库 - 作为矢量搜索的一部分,嵌入和元数据被索引并存储在矢量数据库中,便于 RAG 代理查询。 当用户进行查询时,他们的请求会被嵌入到矢量中。 然后,数据库使用矢量索引来查找并返回最相似的区块。
每个步骤都涉及影响 RAG 应用程序质量的工程决策。 例如,在步骤 (3) 中选择正确的区块大小可确保 LLM 收到具体但有上下文的信息,而在步骤 (4) 中选择合适的嵌入模型可确定检索期间返回的区块的准确性。
Databricks 矢量搜索
计算相似性的工作量通常非常巨大,但 Databricks 矢量搜索等矢量索引可通过高效组织嵌入来优化这一点。 矢量搜索可快速对最相关的结果进行排名,而无需将每个嵌入与用户的查询单独进行比较。
矢量搜索会自动同步添加到 Delta 表的新嵌入并更新矢量搜索索引。
什么是 RAG 代理?
检索增强生成 (RAG) 代理是 RAG 应用程序的关键部分,它通过集成外部数据检索来增强大型语言模型 (LLM) 的功能。 RAG 代理可处理用户查询,从矢量数据库中检索相关数据,并将这些数据传递给 LLM 以生成响应。
LangChain 或 Pyfunc 等工具通过连接其输入和输出将这些步骤链接起来。
下图显示了聊天机器人的 RAG 代理以及用于构建每个代理的 Databricks 功能。
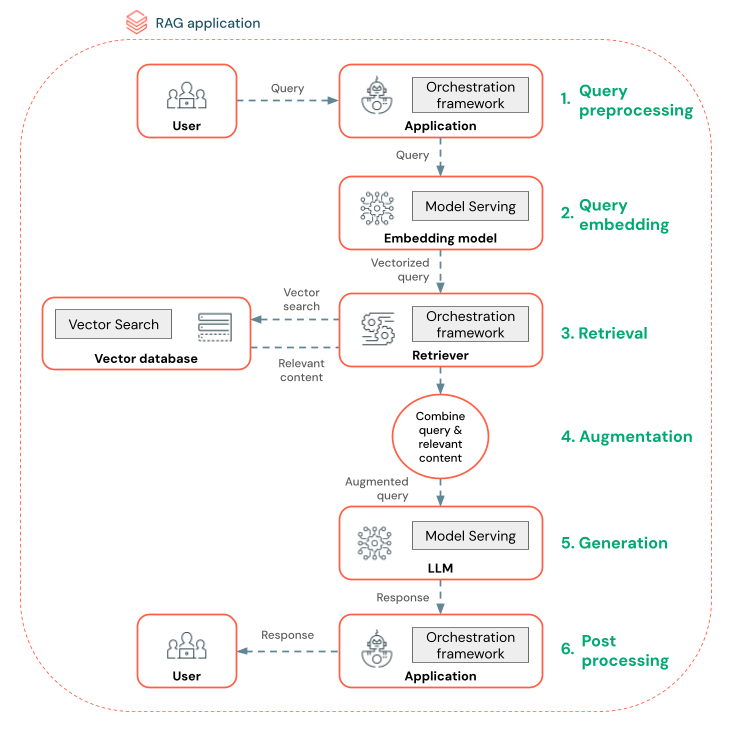
- 查询预处理 - 用户提交查询,然后对其进行预处理以使其适合查询矢量数据库。 这可能涉及将请求放入模板或提取关键字。
- 查询矢量化 - 使用模型服务嵌入请求,使用的嵌入模型与将区块嵌入数据管道的模型相同。 这些嵌入可以比较请求和预处理区块之间的语义相似性。
- 检索阶段 - 检索器(负责获取相关信息的应用程序)获取矢量化查询并使用矢量搜索执行矢量相似性搜索。 最相关的数据区块根据其与查询的相似性进行排名和检索。
- 提示增强 - 检索器将检索到的数据区块与原始查询相结合,为 LLM 提供更多上下文。 提示经过精心设计,以确保 LLM 理解查询的上下文。 通常,LLM 有一个用于格式化响应的模板。 调整提示的这一过程称为提示工程。
- LLM 生成阶段 - LLM 使用由检索结果丰富的增强查询生成响应。 LLM 可以是自定义模型或基础模型。
- 后处理 - 可以处理 LLM 的响应以应用额外的业务逻辑、添加引用或以其他方式根据预定义的规则或约束细化生成的文本
在此过程中可以应用各种防护措施以确保符合企业政策。 这可能涉及筛选适当的请求、在访问数据源之前检查用户权限以及对生成的响应使用内容审核技术。
评估和监视
评估和监视有助于确定 RAG 应用程序是否满足质量、成本和延迟要求。 评估发生在开发过程中,监视则发生在应用程序部署到生产环境后。
非结构化数据的 RAG 有许多影响质量的组件。 例如,数据格式更改会影响检索到的区块和 LLM 生成相关响应的能力。 因此,除了评估整个应用程序之外,评估各个组件也很重要。
有关更多信息,请参阅 Mosaic AI 代理评估简介。
上市区域
有关代理框架的区域可用性,请参阅“区域可用性受限的功能”