实施自己的 LLM 终结点基准测试
本文提供了 Databricks 推荐的笔记本示例,其中展示了如何对 LLM 终结点进行基准测试。 该示例还简要介绍了 Databricks 如何执行 LLM 推理和计算作为终结点性能指标的延迟和吞吐量。
Databricks 上的 LLM 推理可度量基础模型 API 的预配吞吐量模式的每秒令牌数。 请参阅预配吞吐量中的每秒令牌范围意味着什么?。
基准测试示例笔记本
可以将以下笔记本导入 Databricks 环境,并指定要运行负载测试的 LLM 终结点的名称。
对 LLM 终结点进行基准测试
LLM 推理简介
LLM 通过两个步骤执行推理:
- 预填充,其中将并行处理输入提示中的令牌。
- 解码,其中以自动回归方式一次为一个令牌生成文本。 每个生成的令牌追加到输入中,然后反馈到模型中以生成下一个令牌。 当 LLM 输出特殊停止标记或满足用户定义的条件时,生成将停止。
大多数生产应用程序都有延迟预算,Databricks 建议在给定延迟预算的情况下最大程度提高吞吐量。
- 输入标记的数量对处理请求所需的内存具有重大影响。
- 输出标记的数量主导着总体响应延迟。
Databricks 将 LLM 推理拆分为以下子指标:
- 距第一个令牌的时间 (TTFT):这表示用户在输入查询后多久可以开始看到模型输出。 较短的响应等待时间在实时交互中至关重要,而在脱机工作负载中相对不那么重要。 此指标由处理提示然后生成第一个输出令牌所需的时间决定。
- 每个令牌的输出时间 (TPOT):为正在查询系统的每个用户生成一个输出令牌的时间。 此指标对应于每个用户感知到的模型“速度”。 例如,每标记 100 毫秒的 TPOT 是每秒 10 个标记,或每分钟约 450 个字词,这比一个人通常的阅读速度要快。
根据这些指标,可按下述定义总延迟和吞吐量:
- 延迟 = TTFT + (TPOT) *(要生成的令牌数)
- 吞吐量 = 所有并发请求的每秒输出令牌数
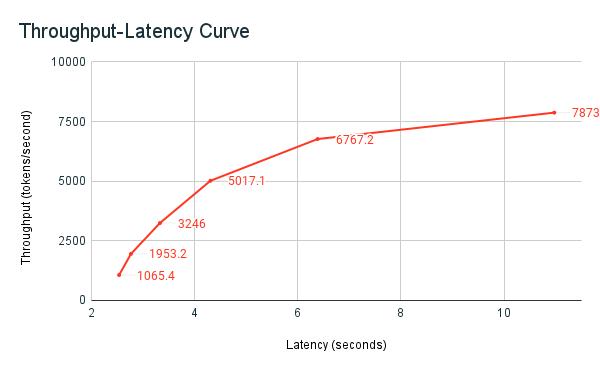
在 Databricks 上,提供 LLM 的终结点能够进行缩放以匹配客户端通过多个并发请求发送的负载。 延迟和吞吐量之间存在一个权衡关系。 这是因为在提供 LLM 的终结点上,并发请求可同时进行处理。 低并发请求负载的延迟会尽可能低。 但如果增加请求负载,延迟可能增加,但吞吐量也可能增加。 这是因为每秒可以处理两个请求的令牌,所需时间小于两倍。
因此,控制进入系统的并行请求数是平衡延迟与吞吐量的核心所在。 如果有低延迟用例,则需要向终结点发送更少的并发请求以保持低延迟。 如果有高吞吐量用例,则需要充分利用终结点以发出大量并发请求,这时宁愿增加延迟也要实现高吞吐量,因为这是值得的。
Databricks 基准测试工具
以前共享的基准测试示例笔记本是 Databricks 的基准测试工具。 笔记本显示延迟和吞吐量指标,并针对不同数量的并行请求相应权衡和规划吞吐量与延迟。 Databricks 终结点的自动缩放基于延迟与吞吐量之间的“均衡”策略。 在笔记本中,会发现随着同时查询终结点的并发用户增多,延迟以及吞吐量都会增加。
LLM 推理性能工程:最佳做法博客中更详细地介绍了有关 LLM 性能基准测试的 Databricks 理念。