Databricks 自动日志记录
本页涵盖了如何自定义 Databricks 自动日志记录,该功能会在你利用各种热门机器学习库训练模型时自动捕获模型参数、指标、文件和世系信息。 训练会话记录为 MLflow 跟踪运行。 此外还会跟踪模型文件,从而让你能够轻松地将这些文件记录到 MLflow 模型注册表。
注意
若要为生成式 AI 工作负载启用跟踪日志记录,MLflow 支持 OpenAI 自动记录。
以下视频演示了在交互式 Python 笔记本中通过 scikit-learn 模型训练会话进行 Databricks 自动记录。 跟踪信息会自动捕获并显示在“试验运行”边栏和 MLflow UI 中。
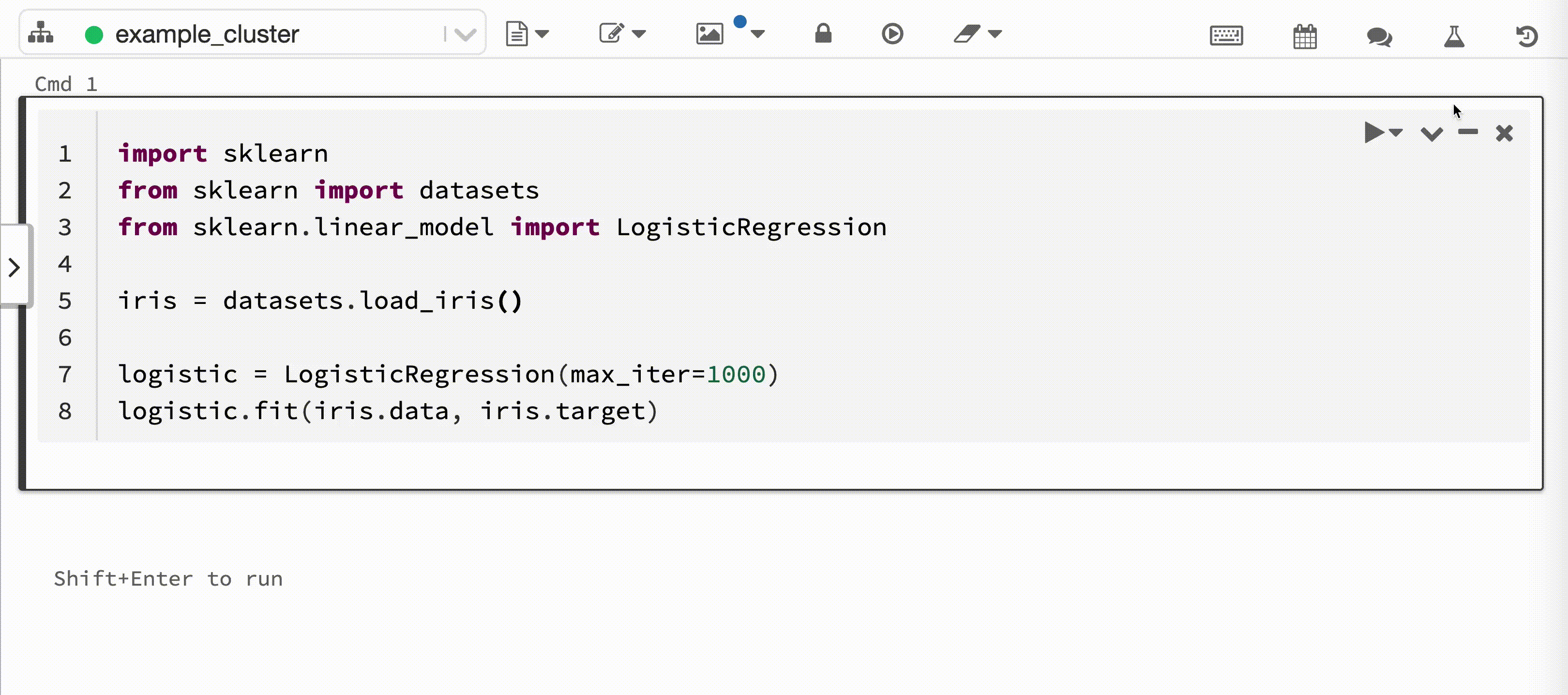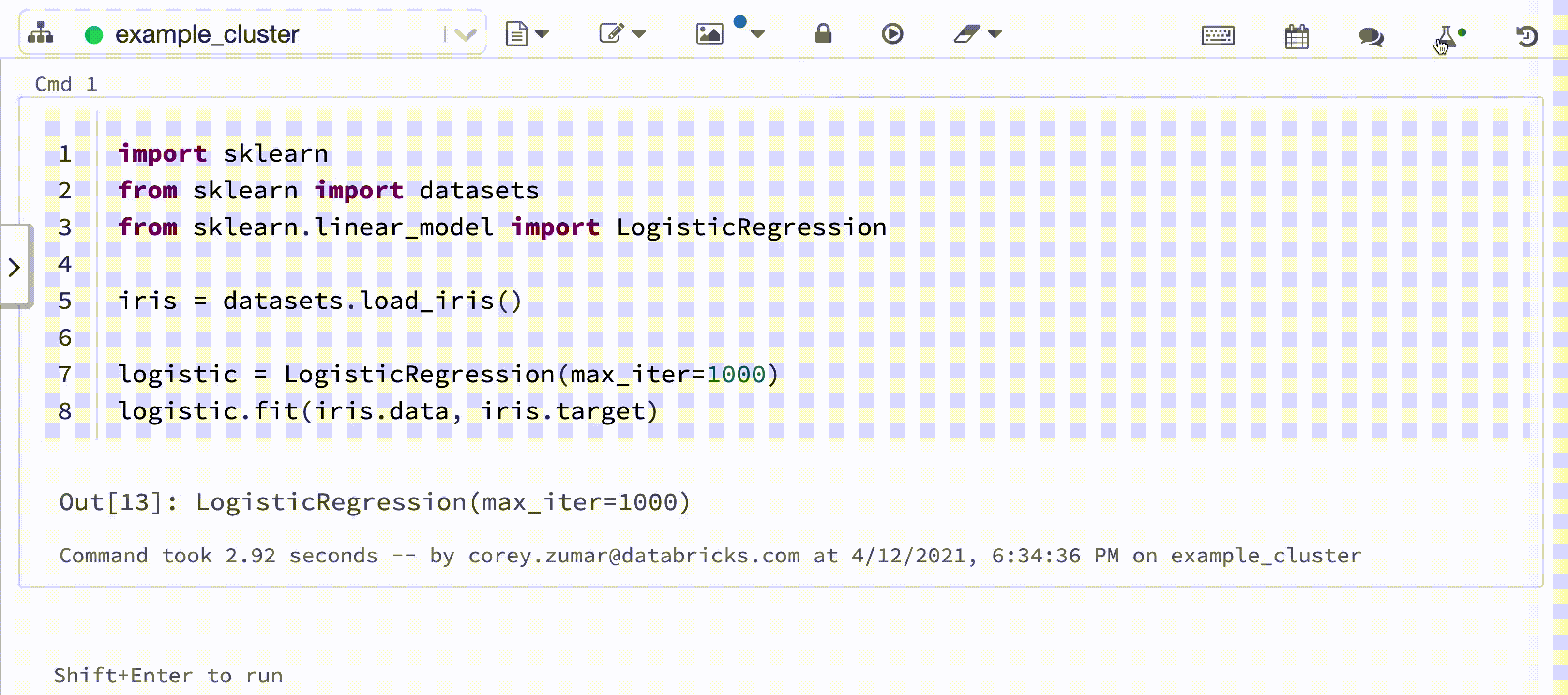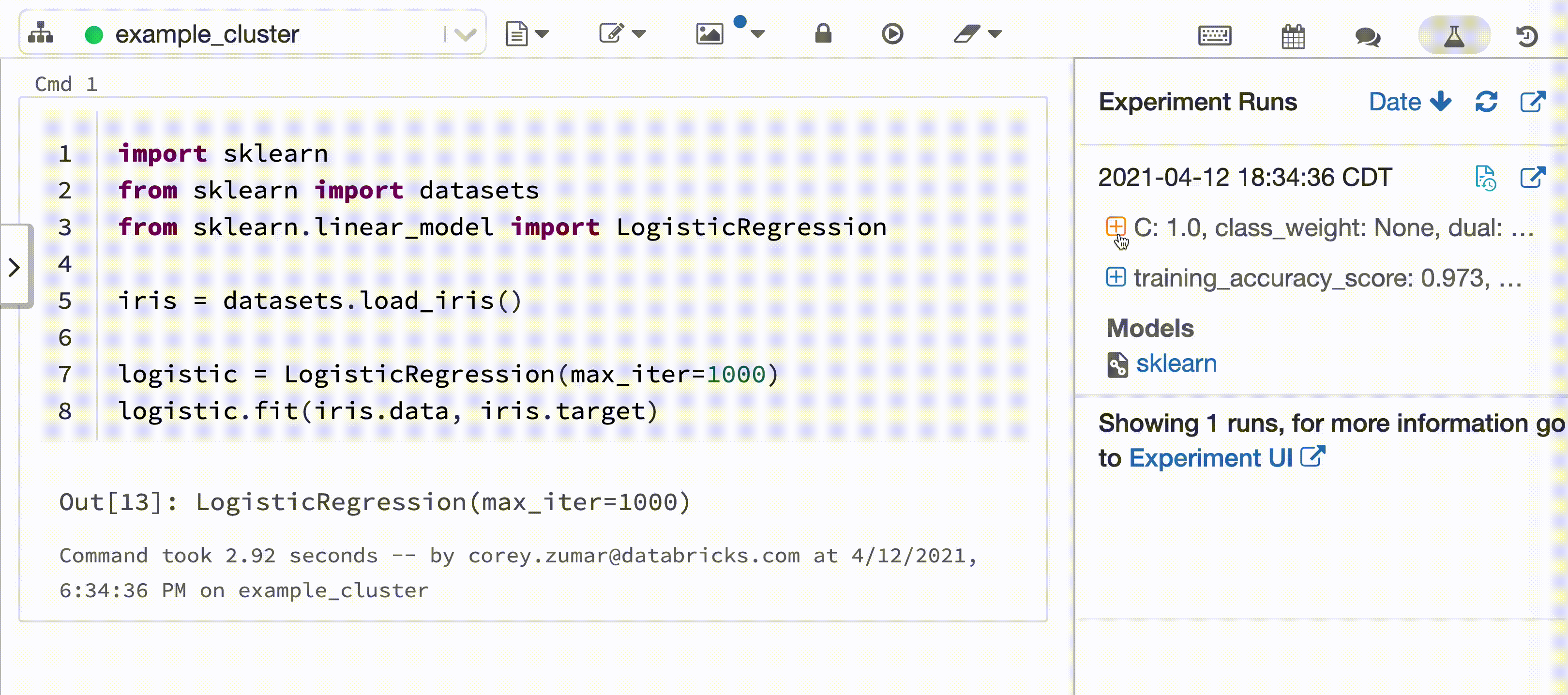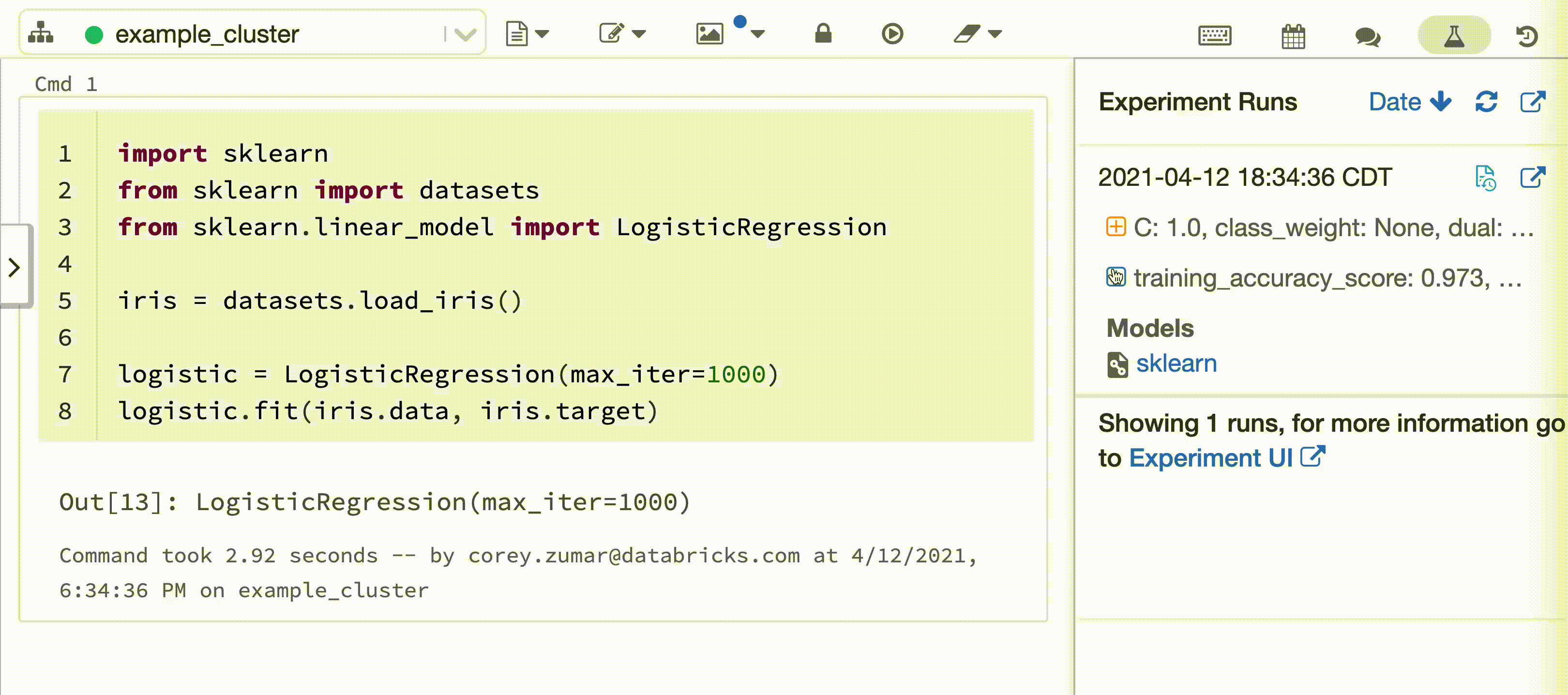
要求
- Databricks Autologging 已在所有具有 Databricks Runtime 10.4 LTS ML 或更高版本的区域中正式发布。
- Databricks Autologging 已在一些选定的具有 Databricks Runtime 9.1 LTS ML 或更高版本的预览版区域中正式发布。
工作原理
将交互式 Python 笔记本附加到 Azure Databricks 群集时,Databricks 日志记录调用 mlflow.autolog() 为模型训练会话设置跟踪。 在笔记本中训练模型时,使用 MLflow 跟踪自动跟踪模型训练信息。 有关如何保护和管理此模型训练信息的信息,请参阅安全性和数据管理。
mlflow.autolog() 调用的默认配置是:
mlflow.autolog(
log_input_examples=False,
log_model_signatures=True,
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=True,
silent=False
)
可以自定义自动日志记录配置。
使用情况
如果要使用 Databricks 自动日志记录,可以使用交互式 Azure Databricks Python 笔记本在支持的框架中训练机器学习模型。 Databricks 自动日志记录会将模型世系信息、参数和指标自动记录到 MLflow 跟踪。 还可以自定义 Databricks 自动日志记录的行为。
注意
Databricks 自动日志记录不适用于使用 MLflow fluent API 以及 mlflow.start_run() 创建的运行。 在这些情况下,必须调用 mlflow.autolog() 以将自动记录的内容保存到 MLflow 运行。 请参阅跟踪其他内容。
自定义日志记录行为
若要自定义日志记录,请使用 mlflow.autolog()。
此函数提供配置参数,用于启用模型日志记录 (log_models)、日志数据集 (log_datasets)、收集输入示例 (log_input_examples)、日志模型签名 (log_model_signatures)、配置警告 (silent) 等。
跟踪其他内容
若要使用 Databricks 自动日志记录创建的 MLflow 运行跟踪其他指标、参数、文件和元数据,请按照以下 Azure Databricks 交互式 Python 笔记本中的步骤操作:
- 使用
exclusive=False调用 mlflow.autolog()。 - 使用 mlflow.start_run() 启动 MLflow 运行。
可以在
with mlflow.start_run()中包装此调用;执行此操作时,运行会在完成后自动结束。 - 使用 MLflow 跟踪方法,例如 mlflow.log_param() 跟踪训练前内容。
- 在 Databricks 自动日志记录支持的框架中训练一个或多个机器学习模型。
- 使用 MLflow 跟踪方法,例如 mlflow.log_metric(),跟踪训练后内容。
- 如果未在步骤 2 中使用
with mlflow.start_run(),可以使用 mlflow.end_run() 结束 MLflow 运行。
例如:
import mlflow
mlflow.autolog(exclusive=False)
with mlflow.start_run():
mlflow.log_param("example_param", "example_value")
# <your model training code here>
mlflow.log_metric("example_metric", 5)
禁用 Databricks 自动日志记录
若要在 Azure Databricks 交互式 Python 笔记本中禁用 Databricks 自动日志记录,请使用 disable=True 来调用 mlflow.autolog():
import mlflow
mlflow.autolog(disable=True)
管理员还可从管理员设置页“高级”选项卡中禁用工作区中所有群集的 Databricks 自动日志记录。 必须重启群集,此更改才能生效。
支持的环境和框架
Databricks 自动日志记录在交互式 Python 笔记本中受支持且可用于以下 ML 框架:
- scikit-learn
- Apache Spark MLlib
- TensorFlow
- Keras
- PyTorch Lightning
- XGBoost
- LightGBM
- Gluon
- Fast.ai
- statsmodels
- PaddlePaddle
- OpenAI
- LangChain
有关每个受支持框架的详细信息,请参阅 MLflow 自动日志记录。
MLflow 跟踪启用
MLflow 跟踪利用相应模型框架集成中的 autolog 功能,控制对支持跟踪的集成的跟踪支持的启用或禁用。
例如,若要在使用 LlamaIndex 模型时启用跟踪,请使用 mlflow.llama_index.autolog() 和 log_traces=True:
import mlflow
mlflow.llama_index.autolog(log_traces=True)
在其自动日志实现中启用跟踪的受支持集成包括:
安全性和数据管理
使用 Databricks 自动日志记录跟踪的所有模型训练信息都存储在 MLflow 跟踪中,并受 MLflow 试验权限保护。 可以使用 MLflow 跟踪 API 或 UI 共享、修改或删除模型训练信息。
管理
管理员可以在管理员设置页的“高级”选项卡中为工作区的所有交互式笔记本会话启用或禁用 Databricks 自动日志记录。 在重启群集之前,更改不会生效。
限制
- Azure Databricks 作业不支持 Databricks 自动日志记录。 若要从作业中使用自动日志记录,可以显式调用 mlflow.autolog()。
- Databricks 自动日志记录仅在 Azure Databricks 群集的驱动程序节点上启用。 若要从工作器节点使用自动日志记录,必须从在每个工作器上执行的代码内显式调用 mlflow.autolog()。
- 不支持 XGBoost scikit-learn 集成。
Apache Spark MLlib、Hyperopt 和自动 MLflow 跟踪
Databricks 自动日志记录不会更改适用于 Apache Spark MLlib 和 Hyperopt 的现有自动 MLflow 跟踪集成的行为。
注意
在 Databricks Runtime 10.1 ML 中,禁用适用于 Apache Spark MLlib CrossValidator 和 TrainValidationSplit 模型的自动 MLflow 跟踪集成也会禁用适用于所有 Apache Spark MLlib 模型的 Databricks 自动日志记录功能。