在 Azure Databricks 上运行 MLflow 项目
MLflow 项目是一种用于以可重用和可重现的方式打包数据科学代码的格式。 MLflow 项目组件包括用于运行项目的 API 和命令行工具,这些工具还与跟踪组件集成,以自动记录源代码的参数和 Git 提交,实现可重现性。
本文介绍了 MLflow 项目的格式,以及如何使用 MLflow CLI 在 Azure Databricks 群集上远程运行 MLflow 项目,以轻松纵向缩放数据科学代码。
MLflow 项目格式
任何本地目录或 Git 存储库都可以视为 MLflow 项目。 项目使用以下约定进行定义:
- 项目的名称是目录的名称。
- 软件环境在
python_env.yaml中指定(如果存在)。 如果不存在python_env.yaml文件,MLflow 在运行项目时使用仅包含 Python(特别是可用于 virtualenv 的最新 Python)的 virtualenv 环境。 - 项目中的任何
.py或.sh文件都可以是入口点,不显式声明参数。 当使用一组参数运行此类命令时,MLflow 会使用--key <value>语法在命令行上传递每个参数。
可通过添加 MLproject 文件来指定更多选项,MLproject 文件是 YAML 语法中的文本文件。 示例 MLproject 文件如下所示:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
对于 Databricks Runtime 13.0 ML 及更高版本,MLflow 项目无法在 Databricks 作业类型群集中成功运行。 若要将现有 MLflow 项目迁移到 Databricks Runtime 13.0 ML 及更高版本,请参阅 MLflow Databricks Spark 作业项目格式。
MLflow Databricks Spark 作业项目格式
MLflow Databricks Spark 作业项目是 MLflow 2.14 中引入的一种 MLflow 项目。 此项目类型支持从 Spark 作业群集内运行 MLflow 项目,并且只能使用 databricks 后端运行。
Databricks Spark 作业项目必须设置 databricks_spark_job.python_file 或 entry_points。 未指定任一设置或同时指定这两个设置都会引发异常。
以下是使用 databricks_spark_job.python_file 设置的 MLproject 文件示例。 此设置涉及使用 Python 运行文件及其参数的硬编码路径。
name: My Databricks Spark job project 1
databricks_spark_job:
python_file: "train.py" # the file which is the entry point file to execute
parameters: ["param1", "param2"] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
以下是使用 entry_points 设置的 MLproject 文件示例:
name: My Databricks Spark job project 2
databricks_spark_job:
python_libraries: # dependencies to be installed as databricks cluster libraries
- mlflow==2.4.1
- scikit-learn
entry_points:
main:
parameters:
model_name: {type: string, default: model}
script_name: {type: string, default: train.py}
command: "python {script_name} {model_name}"
通过 entry_points 设置,可以传入使用命令行参数的参数,例如:
mlflow run . -b databricks --backend-config cluster-spec.json \
-P script_name=train.py -P model_name=model123 \
--experiment-id <experiment-id>
以下限制适用于 Databricks Spark 作业项目:
- 此项目类型不支持在
MLproject文件中指定以下部分:docker_env、python_env或conda_env。 - 必须在
databricks_spark_job部分的python_libraries字段中指定项目的依赖项。 无法使用此项目类型自定义 Python 版本。 - 运行环境必须使用主 Spark 驱动程序运行时环境才能在使用 Databricks Runtime 13.0 或更高版本的作业群集中运行。
- 同样,根据项目需要定义的所有 Python 依赖项都必须安装为 Databricks 群集依赖项。 此行为不同于以前的项目运行行为,以前的项目运行行为需要在单独的环境中安装库。
运行 MLflow 项目
若要在默认工作区中的 Azure Databricks 群集上运行 MLflow 项目,请使用以下命令:
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
其中,<uri> 是包含 MLflow 项目的 Git 存储库 URI 或文件夹,<json-new-cluster-spec> 是包含 new_cluster 结构的 JSON 文档。 Git URI 的格式应为:https://github.com/<repo>#<project-folder>。
群集规范示例如下:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
如果需要在辅助角色上安装库,请使用“群集规范”格式。 请注意,Python wheel 文件必须上传到 DBFS 并指定为 pypi 依赖项。 例如:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
重要
- MLflow 项目不支持
.egg和.jar依赖项。 - 不支持使用 Docker 环境执行 MLflow 项目。
- 在 Databricks 上运行 MLflow 项目时,必须使用新的群集规范。 不支持对现有群集运行项目。
使用 SparkR
若要在 MLflow 项目运行中使用 SparkR,项目代码必须首先安装并导入 SparkR,如下所示:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
这样项目才可以初始化 SparkR 会话并正常使用 SparkR:
sparkR.session()
...
示例
此示例展示了如何创建试验,在 Azure Databricks 群集上运行 MLflow 教程项目,查看作业运行输出以及查看试验中的运行情况。
要求
- 使用
pip install mlflow安装 MLflow。 - 安装并配置 Databricks CLI。 在 Azure Databricks 群集上运行作业需要 Databricks CLI 身份验证机制。
步骤 1:创建试验
在工作区中,选择“创建”>“MLflow 试验”。
在“名称”字段中,输入
Tutorial。单击“创建”。 记下试验 ID。 在此示例中,它是
14622565。
步骤 2:运行 MLflow 教程项目
以下步骤设置 MLFLOW_TRACKING_URI 环境变量并运行项目,将训练参数、指标和训练模型记录到前一步中提到的试验中:
将
MLFLOW_TRACKING_URI环境变量设置为 Azure Databricks 工作区。export MLFLOW_TRACKING_URI=databricks运行 MLflow 教程项目,训练酒品模型。 将
<experiment-id>替换为上一步中记下的试验 ID。mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===复制 MLflow 运行输出的最后一行中的 URL
https://<databricks-instance>#job/<job-id>/run/1。
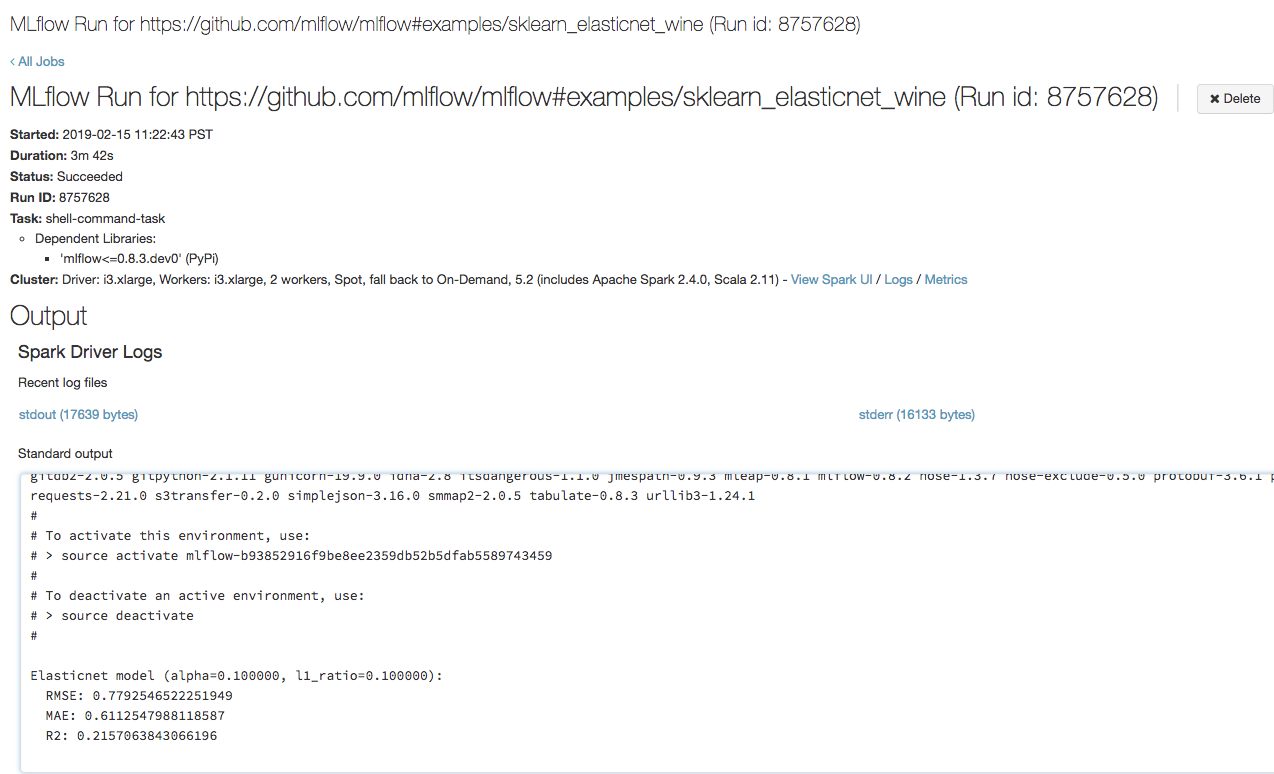
步骤 3:查看 Azure Databricks 作业运行
在浏览器中打开在上一步中复制的 URL 以查看 Azure Databricks 作业运行输出:
步骤 4:查看试验和 MLflow 运行详细信息
导航到 Azure Databricks 工作区中的试验。
单击试验。
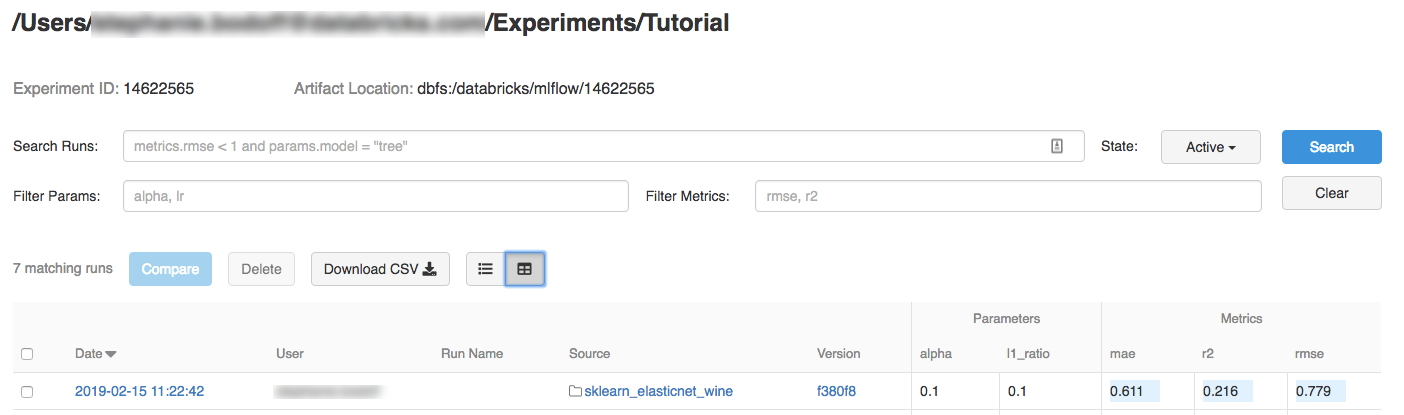
若要显示运行详细信息,请单击 Date 列中的链接。
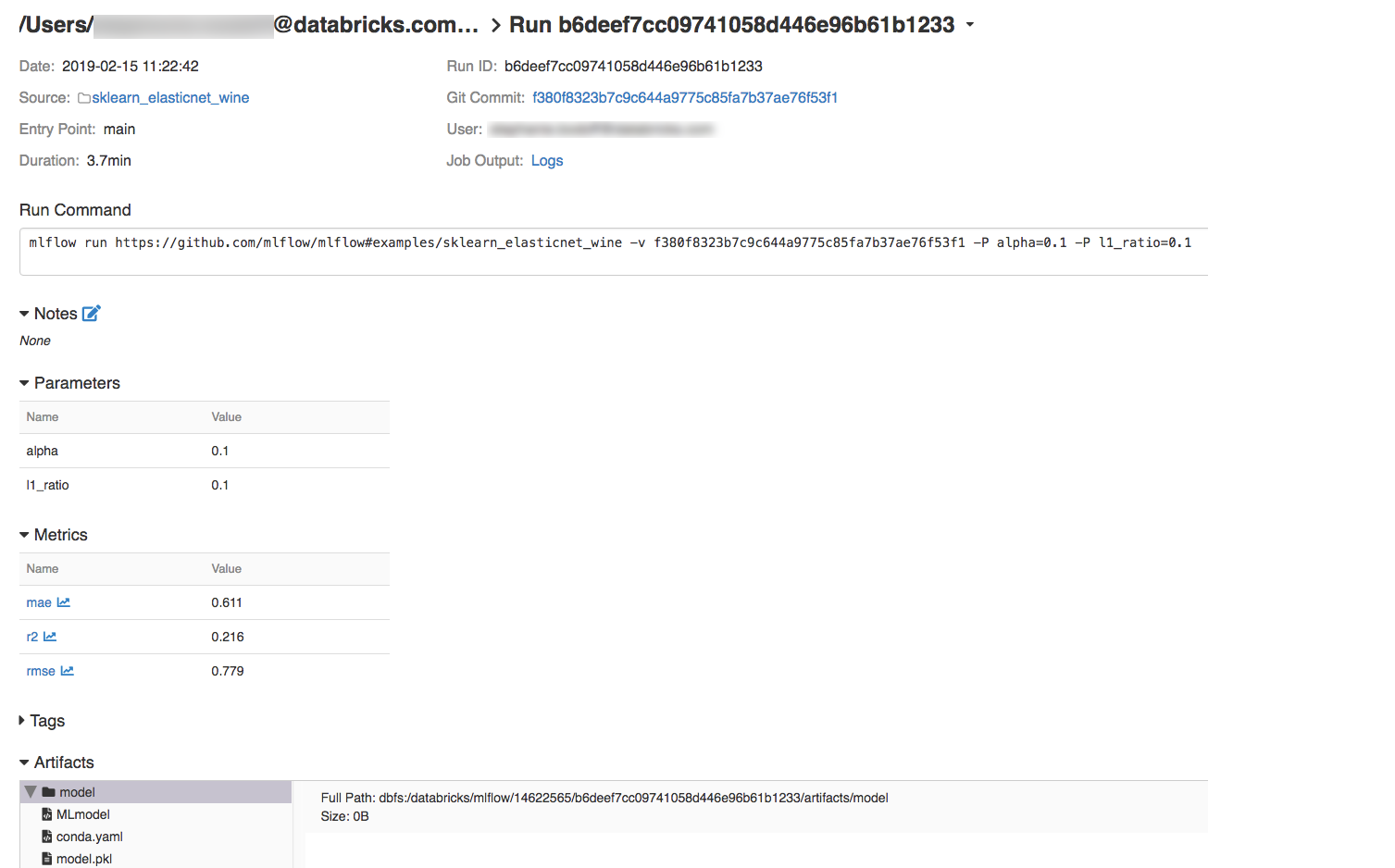
通过单击作业输出字段中的日志链接,可以查看运行中的日志。
资源
如需了解一些 MLflow 项目示例,请参阅 MLflow 应用库,该库包含一个现成的项目存储库,旨在使代码中易于包含 ML 功能。