配置 Azure Databricks 作业的设置
本文提供有关在作业 UI 中配置 Azure Databricks 作业和各个作业任务的详细信息。 若要了解如何使用 Databricks CLI 编辑作业设置,请运行 CLI 命令 databricks jobs update -h。 若要了解如何使用作业 API,请参阅作业 API。
有些配置选项是针对作业提供的,还有一些选项是针对任务提供的。 例如,只能在作业上设置最大并发运行数,同时为每个任务定义重试策略。
编辑作业
若要更改作业的配置,请执行以下操作:
- 在边栏中,单击
 “工作流”。
“工作流”。 - 在“名称”列中单击作业名称。
边侧面板将显示“作业详细信息”。 可以更改作业触发器、计算配置、通知和最大并发运行数,配置持续时间阈值,以及添加或更改标记。 如果启用了作业访问控制,还可以编辑作业权限。
为所有作业任务添加参数
可以在作业上配置参数,这些参数会传递到任何接受键值参数的作业任务,包括配置为接受关键字参数的 Python wheel 文件。 在作业级别设置的参数将添加到已配置的任务级参数。 传递给任务的作业参数在任务配置中可见,以及任务上配置的任何参数。
还可以将作业参数传递给未配置键值参数的任务,例如 JAR 或 Spark Submit 任务。 若要将作业参数传递给这些任务,请将参数的格式设置为 {{job.parameters.[name]}},并将 [name] 替换为标识参数的 key。
作业参数优先于任务参数。 如果作业参数和任务参数具有相同的键,则作业参数将替代任务参数。
当使用不同的参数运行作业或修复作业运行时,可以替代配置的作业参数或添加新的作业参数。
还可以使用一组动态值引用共享有关作业和任务的上下文。
若要添加作业参数,请单击作业详细信息侧面板中的编辑参数,并指定每个参数的键和默认值。 若要查看可用动态值引用的列表,请单击浏览动态值。
将标记添加到作业
若要向作业添加标签或 key:value 属性,可以在编辑作业时添加标记。 可以使用标记筛选作业列表作业;例如,可以使用 department 标记筛选属于特定部门的所有作业。
注意
由于作业标记不是为了存储敏感信息(如个人身份信息或密码)而设计的,因此 Databricks 建议仅对非敏感值使用标记。
标记还会传播到运行作业时创建的作业群集,使你可以将标记与现有群集监视配合使用。
若要添加或编辑标记,请单击“作业详细信息”侧面板中的“+ 标记”。 可以将标记添加为键和值或标签。 若要添加标签,请在“键”字段中输入标签,并将“值”字段留空。
配置共享群集
若要查看与某个群集关联的任务,请单击“任务”选项卡,并将鼠标悬停在边侧面板中的该群集上。 若要更改所有关联任务的群集配置,请单击群集下的“配置”。 若要配置所有关联任务的新群集,请单击群集下的“交换”。
控制对作业的访问
作业所有者和管理员可以通过作业访问控制授予对其作业的精细权限。 作业所有者可以选择允许哪些其他用户或组查看作业的结果。 所有者还可以选择允许谁管理其作业运行(“立即运行”和“取消运行”权限)。
有关作业权限级别的信息,请参阅 作业 ACL。
必须具有作业的“可管理”或“是所有者”权限才能管理其权限。
在边栏中,单击“作业运行”。
单击作业名称。
在“作业详细信息”面板中,单击“编辑权限”。
在“权限设置”中,单击“选择用户、组或服务主体...”下拉菜单,然后选择用户、组或服务主体。
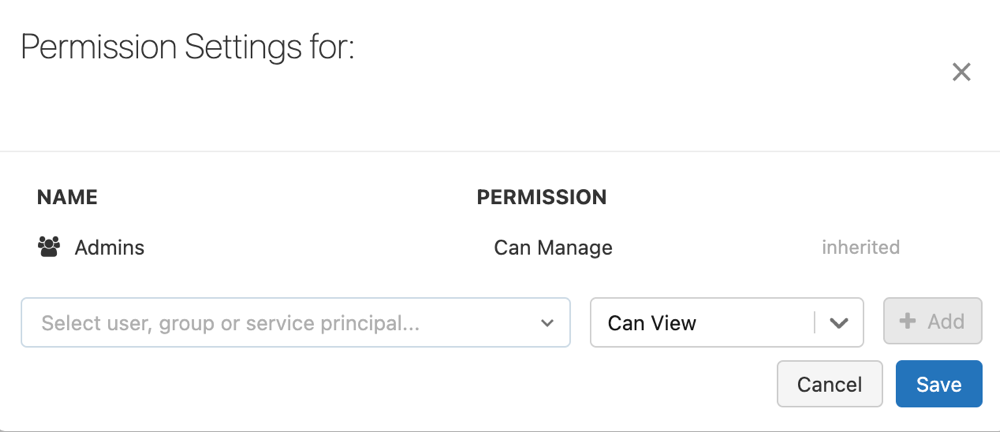
单击“添加” 。
单击“ 保存”。
管理作业所有者
默认情况下,作业的创建者具有“所有者”权限,并且是作业的“运行方式”设置中的用户。 作业以“运行身份”设置中的用户身份运行。 有关“运行方式”设置的详细信息,请参阅以服务主体身份运行作业。
工作区管理员可以将作业所有者更改为自己。 转移所有权后,会向前一个所有者授予“CAN MANAGE”权限
注意
当工作区上的 RestrictWorkspaceAdmins 设置设为 ALLOW ALL 时,工作区管理员可以将作业所有者更改为工作区中的任何用户或服务主体。 若要将工作区管理员限制为仅将作业所有者更改为他们自己,请参阅限制工作区管理员。
配置最大并发运行数
单击“高级设置”下的“编辑并发运行”,设置此作业的最大并行运行数。 尝试启动新的运行时,如果作业已达到其最大活动运行数,Azure Databricks 会跳过该运行。 若要以并发方式执行同一作业的多个运行,请将此值设置为高于默认值 1。 设置此值适用于这样的情形:例如,如果你按计划频繁触发作业并希望允许连续的运行彼此重叠,或者,如果你希望触发多个在输入参数方面有区别的运行。
启用作业运行队列
若要启用作业的运行,以便在由于并发限制而无法立即运行时将作业置于队列中,请单击“高级设置”下的“队列”切换。 请参阅如果我的作业因并发限制而无法运行,该怎么办?。
注意
默认情况下,为在 2024 年 4 月 15 日之后通过 UI 创建的作业启用队列。
配置作业的预期完成时间或超时
可以为作业配置可选的持续时间阈值,包括作业的预期完成时间和作业的最长完成时间。 要配置持续时间阈值,请单击“设置持续时间阈值”。
要配置作业的预期完成时间,请在“警告”字段中输入预期的持续时间。 如果作业超出此阈值,则可以为运行缓慢的作业配置通知。 请参阅为运行缓慢或延迟的作业配置通知。
要配置作业的最长完成时间,请在“超时”字段中输入最长持续时间。 如果作业未在此时间内完成,则 Azure Databricks 会将其状态设置为“已超时”并且作业将停止。
编辑任务
要设置任务配置选项:
- 在边栏中,单击 “工作流”。
- 在“名称”列中单击作业名称。
- 单击“任务”选项卡并选择要编辑的任务。
定义任务依赖关系
可以使用“依赖于”下拉菜单定义作业中任务的执行顺序。 可将此字段设置为作业中的一个或多个任务。
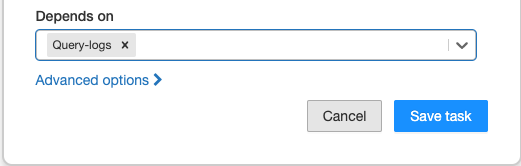
注意
如果作业仅包括一个任务,“依赖于”将不可见。
配置任务依赖关系会创建任务执行的有向无环图 (DAG)。DAG 是在作业计划程序中表示执行顺序的常用方式。 以下面包括四个任务的作业为例:
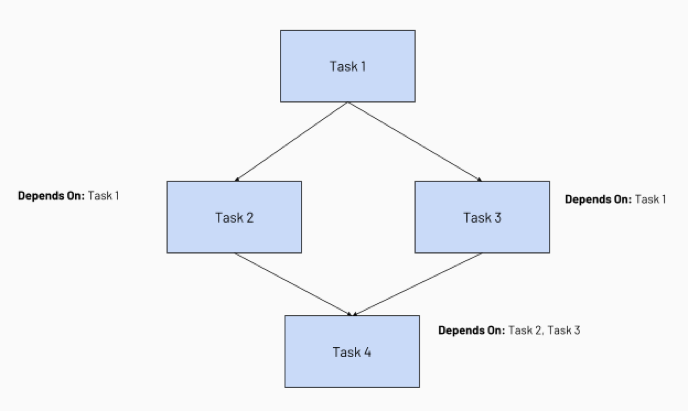
- 任务 1 是根任务,不依赖于任何其他任务。
- 任务 2 和任务 3 依赖于任务 1 首先完成。
- 最后,任务 4 依赖于任务 2 和任务 3 成功完成。
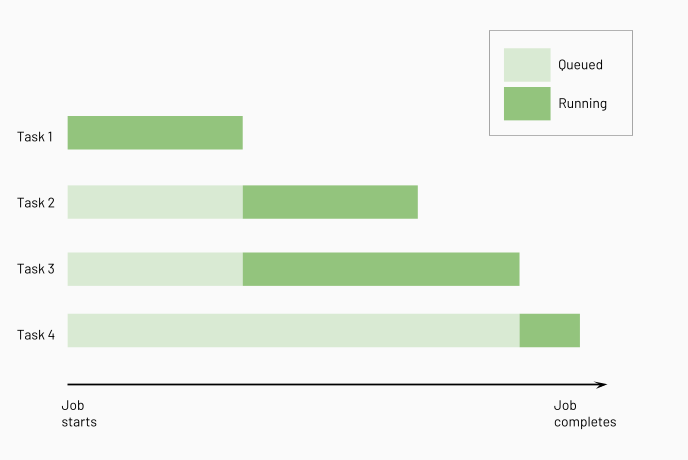
Azure Databricks 在运行下游任务之前运行上游任务,并且会并行运行尽可能多的这些任务。 以下示意图演示了这些任务的处理顺序:
为任务配置群集
要配置运行任务的群集,请单击“群集”下拉菜单。 可以编辑共享作业群集,但如果共享群集仍由其他任务使用,则不能删除该群集。
若要详细了解如何选择和配置群集以运行任务,请参阅将 Azure Databricks 计算用于作业。
配置依赖库
依赖库将在该任务运行之前安装在群集上。 必须设置所有任务依赖项,以确保在运行开始之前已安装它们。 请按照管理库依赖项中的建议指定依赖项。
配置任务的预期完成时间或超时
可以为任务配置可选的持续时间阈值,包括任务的预期完成时间和任务的最长完成时间。 要配置持续时间阈值,请单击“持续时间阈值”。
要配置任务的预期完成时间,请在“警告”字段中输入持续时间。 如果任务超过此阈值,则会触发事件。 可以使用此事件在任务运行缓慢时发出通知。 请参阅为运行缓慢或延迟的作业配置通知。
要配置任务的最长完成时间,请在“超时”字段中输入最长持续时间。 如果作业未在此时间内完成,则 Azure Databricks 会将其状态设置为“已超时”。
配置任务的重试策略
若要配置一个策略来确定失败任务运行的重试时间和次数,请单击“重试”旁边的“+ 添加”。 重试间隔以失败运行开始时间与随后的重试运行开始时间之间相隔的毫秒数计算。
注意
如果同时配置“超时”和“重试”,则超时将应用于每次重试。
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈