你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
解决 Azure HDInsight 中的 Apache Hive 内存不足错误
了解处理大型表时如何通过配置 Hive 内存设置解决 Apache Hive 内存不足 (OOM) 错误。
对大型表运行 Apache Hive 查询
客户运行了 Hive 查询:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
此查询有一些繁琐之处:
- T1 是大型表 TABLE1 的别名,其中包含多个 STRING 列类型。
- 其他表没有那么大,但包含许多列。
- 所有表都彼此联接,在某些情况下,TABLE1 和其他表中的多个列也相互联接。
Hive 查询在 24 节点 A3 HDInsight 群集上用了 26 分钟才完成。 客户注意到以下警告消息:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
通过使用 Apache Tez 执行引擎, 相同的查询运行了 15 分钟,并引发以下错误:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
使用更大的虚拟机(例如,D12)时,也出现了该错误。
调试内存不足错误
我们的支持团队和工程团队合作发现了造成内存不足错误的原因之一是 Apache JIRA 中所述的已知问题:
"如果 hive.auto.convert.join.noconditionaltask = true,我们将检查 noconditionaltask.size,如果映射联接中表大小之和小于 noconditionaltask.size,则计划将生成一个映射联接,但问题在于,计算时并不会考虑不同哈希表实施所引入的开销,因此,如果输入大小之和与 noconditionaltask 大小差距不大,则查询将命中 OOM。"
hive-site.xml 文件中的 Hive.auto.convert.join.noconditionaltask 已设置为 true:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
映射联接很可能是 Java 堆空间内存不足错误的原因。 如博客文章 HDInsight 中的 Hadoop Yarn 内存设置所述,使用 Tez 执行引擎时,所用的堆空间事实上属于 Tez 容器。 请参阅下图,其中描述了 Tez 容器内存。
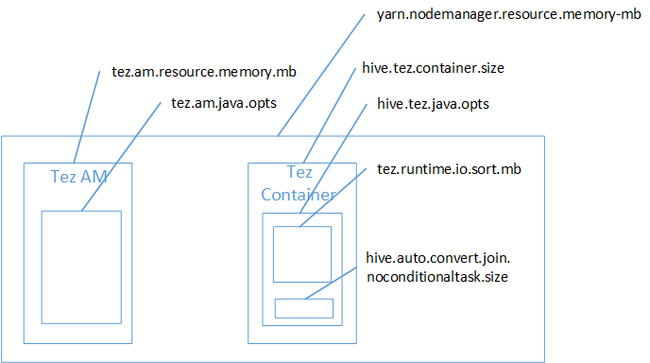
如该博客文章中所述,以下两项内存设置定义了堆的容器内存:hive.tez.container.size 和 hive.tez.java.opts。 从我们的经验来看,内存不足异常并不意味着容器太小。 而是表示 Java 堆大小 (hive.tez.java.opts) 太小。 因此,每当看到内存不足时,可尝试增大 hive.tez.java.opts。 必要时,可能需要增大 hive.tez.container.size。 java.opts 设置应该大约为 container.size 的 80%。
注意
hive.tez.java.opts 设置必须始终小于 hive.tez.container.size。
由于 D12 计算机具有 28 GB 内存,因此我们决定使用 10 GB (10240 MB) 的容器大小并将 80% 分配给 java.opts:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
使用新设置,查询可在 10 分钟内成功运行。
后续步骤
遇到 OOM 错误不一定表示容器太小。 相反地,应该配置内存设置,以便将堆大小增加为至少是容器内存大小的 80%。 有关优化 Hive 查询,请参阅在 HDInsight 中优化 Apache Hadoop 的 Apache Hive 查询。