教程:使用 Azure 机器学习和 IoT Edge 的端到端解决方案
适用于:![]() IoT Edge 1.1
IoT Edge 1.1
重要
IoT Edge 1.1 终止支持日期为 2022 年 12 月 13 日。 请查看 Microsoft 产品生命周期,了解此产品、服务、技术或 API 的受支持情况。 有关更新到最新版本的 IoT Edge 的详细信息,请参阅 更新 IoT Edge。
IoT 应用程序常需要利用智能云和智能边缘。 在本教程中,我们将引导你使用从云中的 IoT 设备收集的数据训练机器学习模型,将该模型部署到 IoT Edge,并定期维护和优化该模型。
注意
这套教程中的概念适用于所有版本的 IoT Edge,而你创建的用于试用该方案的示例设备运行的是 IoT Edge 版本 1.1。
本教程的主要目的是介绍通过机器学习处理 IoT 数据,尤其在边缘进行处理。 虽然我们涉及通用机器学习工作流程的许多方面,但本教程并非旨在深入介绍机器学习。 就这一点而言,我们不尝试为用例创建高度优化的模型 -- 我们只需做足够的工作来说明创建和使用可行模型进行 IoT 数据处理的过程。
本教程的这一部分讨论:
- 完成本教程后续部分的先决条件。
- 本教程的目标受众。
- 本教程模拟的用例。
- 本教程实现用例的整个过程。
如果没有 Azure 订阅,请在开始之前创建一个 Azure 免费帐户。
先决条件
要完成本教程,需要访问你有权在其中创建资源的 Azure 订阅。 本教程中使用的一些服务将产生 Azure 费用。 如果还没有 Azure 订阅,可以通过 Azure 免费帐户开始。
还需要安装了 PowerShell 的计算机,可以在其中运行脚本以将 Azure 虚拟机设置为开发计算机。
在本文档中,我们使用以下一组工具:
Azure IoT 中心,用于数据捕获
Azure Notebooks,用作数据准备和机器学习实验的主要前端。 在笔记本中对示例数据的子集运行 Python 代码,是在数据准备期间获得快速迭代和交互式周转的好方法。 也可使用 Jupyter 笔记本准备脚本以在计算后端大规模运行。
Azure 机器学习,用作大规模机器学习和机器学习图像生成的后端。 我们使用在 Jupyter 笔记本中准备和测试的脚本来驱动 Azure 机器学习后端。
Azure IoT Edge,用于机器学习映像的云下应用
显然,还有其他选择。 例如,在某些情况下,IoT Central 可用作无代码替代方案,用于从 IoT 设备捕获初始训练数据。
目标受众和角色
本系列文章适用于没有 IoT 开发或机器学习经验的开发人员。 在边缘部署机器学习需要了解如何连接各种技术。 因此,本教程将介绍整个端到端场景,演示将这些技术结合用于 IoT 解决方案的一种方法。 在现实环境中,可能由几个不同专业的人来执行这些任务。 例如,开发人员将专注于设备或云代码,而数据科学家则设计分析模型。 为了使单个开发人员能够成功完成本教程,我们提供了补充指导,其中包含我们的见解和指向更多信息的链接,希望这些信息能帮助你了解正在完成的工作以及为什么要进行这些工作。
或者,你可以与具有不同职务的同事共同学习本教程,充分发挥各自的专业知识,并以团队的方式了解各方面的工作如何融合在一起。
无论如何,为了帮助指引读者,本教程中的每篇文章都指出了用户的角色。 这些角色包括:
- 云开发(包括 DevOps 职务的云开发人员)
- 数据分析
用例:预见性维护
本场景基于 2008 年预测和健康管理会议 (PHM08) 上提出的一个用例。 目标是预测一组涡轮风扇飞机发动机的剩余使用寿命(RUL)。 该数据是使用商业版 MAPSS(Modular Aero-Propulsion System Simulation)软件 C-MAPSS 生成的。 该软件提供灵活的涡扇发动机模拟环境,可方便地模拟健康、控制和发动机参数。
本教程中使用的数据来自涡扇发动机退化仿真数据集。
来自自述文件:
试验场景
数据集由多个多变量时序组成。 每个数据集进一步分为训练子集和测试子集。 每个时序都来自不同的引擎,即数据可以被视为来自同一类型的引擎群。 每个发动机以不同程度的初始磨损和制造变化开始,这是用户不知道的。 这种磨损和变化被认为是正常的,即不认为它们是故障状态。 有三种运行设置会对发动机性能产生重大影响。 这些设置也包含在数据中。 数据中包含无用的传感器数据。
发动机在每个时序开始时正常运行,并在时序中的某个时间点发生故障。 在训练集中,故障会成级数扩大,直到系统发生故障。 在测试集中,时序在系统故障之前的某个时间结束。 竞争的目的是预测测试组中故障之前的剩余运行周期数,即发动机继续运行的最后一个周期之后的运行周期次数。 此外还提供了测试数据的真实剩余使用寿命(RUL)值的矢量。
由于数据是为竞赛发布的,因此推出机器学习模型的几种方法已经独立发布。 我们发现学习示例有助于理解创建特定机器学习模型所涉及的过程和推理。 有关示例,请参阅:
飞机发动机故障预测模型,作者:GitHub 用户 jancervenka。
涡扇发动机性能退化,作者:GitHub 用户 hankroark。
过程
下图说明了本教程中我们遵循的粗略步骤:
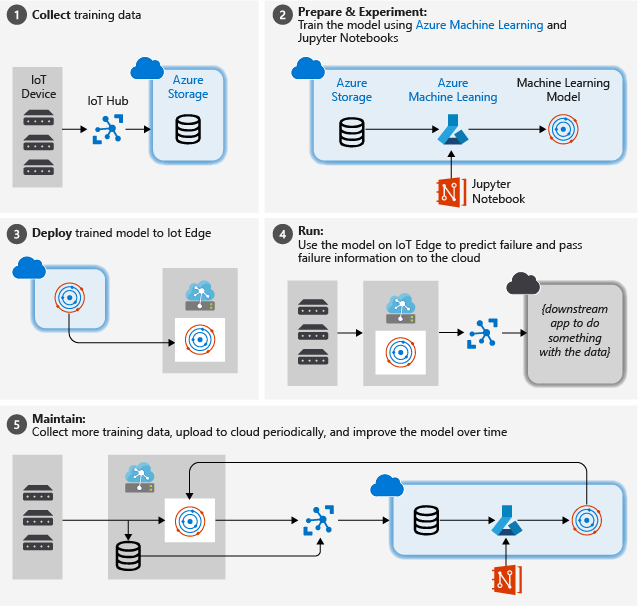
收集培训数据:该过程从收集培训数据开始。 在某些情况下,数据已经被收集到可用的数据库或数据文件中。 在其他情况下,特别是对于 IoT 场景,需要从 IoT 设备和传感器收集数据并将其存储在云中。
我们假设你没有一组涡扇发动机,因此项目文件包含一个简单的设备模拟器,可将 NASA 设备数据发送到云端。
准备数据。 在大多数情况下,需要对从设备和传感器收集的原始数据进行准备,才可将其用于机器学习。 此步骤可能涉及数据清理、数据重格式化或预处理,以注入额外信息供机器学习使用。
对于我们的飞机发动机数据,数据准备涉及根据对数据的实际观察结果计算样本中每个数据点距离下次故障的明确时间。 该信息允许机器学习算法找到实际传感器数据模式与发动机的预期剩余寿命之间的相关性。 此步骤高度特定于域。
构建机器学习模型。 基于准备好的数据,我们现在可以尝试用不同的机器学习算法和参数化来训练模型,并将结果相互比较。
在本例中,为了测试,我们将模型计算的预测结果与在一组发动机上观察到的实际结果进行比较。 在 Azure 机器学习中,我们可以管理在模型注册表中创建的模型的不同迭代。
部署模型。 一旦我们拥有满足成功标准的模型,便可以转向部署。 这涉及将模型包装到一个 Web 服务应用中,可以使用 REST 调用向该应用提供数据,并使其返回分析结果。 然后将该 Web 服务应用打包到一个 Docker 容器中,该容器又可以部署在云中或作为 IoT Edge 模块部署。 在此示例中,我们专注于部署 IoT Edge。
维护和优化模型。 部署模型后,我们的工作尚未完成。 在许多情况下,我们希望继续收集数据并定期将数据上传到云端。 这样,我们可以使用这些数据来重新训练和优化我们的模型,然后将经改进的模型重新部署到 IoT Edge。
清理资源
本教程是一系列文章的一部分,其中每篇文章都基于前一篇文章中介绍的内容。 在完成最后一个教程之前,请等待清理所有资源。
后续步骤
本教程分为以下几个部分:
- 设置开发计算机和 Azure 服务。
- 生成机器学习模块的培训数据。
- 培训和部署机器学习模块。
- 配置 IoT Edge 设备以充当透明网关。
- 创建和部署 IoT Edge 模块。
- 将数据发送到 IoT Edge 设备。
继续阅读下一篇文章,了解如何设置开发计算机并配置 Azure 资源。