你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure 机器学习推理 HTTP 服务器调试评分脚本
Azure 机器学习推理 HTTP 服务器是一个 Python 包,它以 HTTP 终结点的形式公开评分函数,并将 Flask 服务器代码和依赖项包装到单一包中。 该服务器包含在用于推理的预生成 Docker 映像中,通过 Azure 机器学习部署模型时,会使用这些映像。 单独使用包,可以在本地部署模型以供生产,还可以在本地开发环境中轻松验证评分(条目)脚本。 如果评分脚本有问题,服务器将返回错误和发生错误的位置。
该服务器还可以用于在持续集成和部署管道中创建验证入口。 例如,可以使用候选脚本启动服务器,并针对本地终结点运行测试套件。
本文主要面向想要使用推理服务器进行本地调试的用户,但也有助于了解如何将推理服务器与联机终结点结合使用。
联机终结点本地调试
在将终结点部署到云之前对其进行本地调试,可以帮助提前捕获代码和配置中的错误。 若要在本地调试终结点,可以使用:
- Azure 机器学习推理 HTTP 服务器
- 本地终结点
本文重点介绍 Azure 机器学习推理 HTTP 服务器。
下表对各个方案进行了概述,便于你选择最适合你的方案。
| 方案 | 推理 HTTP 服务器 | 本地终结点 |
|---|---|---|
| 更新本地 Python 环境,而无需重新生成 Docker 映像 | 是 | 否 |
| 更新评分脚本 | 是 | 是 |
| 更新部署配置(部署、环境、代码、模型) | 否 | 是 |
| 集成 VS Code 调试程序 | 是 | 是 |
通过在本地运行推理 HTTP 服务器,就可以专注于调试评分脚本,而不受部署容器配置影响。
先决条件
- 需要:Python >=3.8
- Anaconda
提示
Azure 机器学习推理服务器在基于 Windows 和 Linux 的操作系统上运行。
安装
注意
若要避免包冲突,请在虚拟环境中安装服务器。
若要安装 azureml-inference-server-http package,请在 cmd/ 终端中运行以下命令:
python -m pip install azureml-inference-server-http
在本地调试评分脚本
若要在本地调试评分脚本,可以使用虚拟评分脚本测试服务器的行为方式,使用 VS Code 通过 azureml-inference-server-http 包进行调试,也可以使用示例存储库中的实际评分脚本、模型文件和环境文件测试服务器。
使用虚拟评分脚本测试服务器行为
创建目录以保存文件:
mkdir server_quickstart cd server_quickstart若要避免包冲突,请创建一个虚拟环境并激活该环境:
python -m venv myenv source myenv/bin/activate提示
测试后,运行
deactivate以停用 Python 虚拟环境。从 pypi 源安装
azureml-inference-server-http包:python -m pip install azureml-inference-server-http创建入口脚本 (
score.py)。 以下示例创建一个基本的入口脚本:echo ' import time def init(): time.sleep(1) def run(input_data): return {"message":"Hello, World!"} ' > score.py启动服务器 (azmlinfsrv) 并将
score.py设置为入口脚本:azmlinfsrv --entry_script score.py注意
服务器托管在 0.0.0.0 上,这意味着它将侦听托管计算机的所有 IP 地址。
使用
curl将评分请求发送到服务器:curl -p 127.0.0.1:5001/score服务器的响应方式应如下所示。
{"message": "Hello, World!"}
测试后,可以按 Ctrl + C 终止服务器。
现在,可以通过再次运行服务器 (azmlinfsrv --entry_script score.py)来修改评分脚本 (score.py) 并测试更改。
如何与 Visual Studio Code 集成
可通过两种方式使用 Visual Studio Code (VSCode) 和 Python 扩展通过 azureml-inference-server-http 包进行调试(启动模式和附加模式)。
启动模式:在 VS Code 中设置
launch.json,并在 VS Code 中启动 Azure 机器学习推理 HTTP 服务器。启动 VS Code 并打开包含脚本 (
score.py) 的文件夹。在 VS Code 中为该工作区将下面的配置添加到
launch.json中:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Debug score.py", "type": "python", "request": "launch", "module": "azureml_inference_server_http.amlserver", "args": [ "--entry_script", "score.py" ] } ] }在 VS Code 中启动调试会话。 选择“运行”- >“开始调试”(或
F5)。
附加模式:在命令行中启动 Azure 机器学习推理 HTTP 服务器,并使用 VS Code + Python 扩展来附加到进程。
注意
如果使用的是 Linux 环境,请先运行
sudo apt-get install -y gdb来安装gdb包。在 VS Code 中为该工作区将下面的配置添加到
launch.json中:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Python: Attach using Process Id", "type": "python", "request": "attach", "processId": "${command:pickProcess}", "justMyCode": true }, ] }使用 CLI (
azmlinfsrv --entry_script score.py) 启动推理服务器。在 VS Code 中启动调试会话。
- 在 VS Code 中,选择“运行”- >“开始调试”(或
F5)。 - 根据 CLI 界面显示的推理服务器日志,输入
azmlinfsrv(而不是gunicorn)的进程 ID。
注意
如果未显示进程选择器,请手动在
launch.json的processId字段中输入进程 ID。- 在 VS Code 中,选择“运行”- >“开始调试”(或
通过这两种方式,都可以逐步设置断点和调试。
端到端示例
在本部分中,我们将使用示例存储库中的示例文件(评分脚本、模型文件和环境)在本地运行服务器。 使用联机终结点部署机器学习模型并对其进行评分的文章中也使用了示例文件
克隆示例存储库。
git clone --depth 1 https://github.com/Azure/azureml-examples cd azureml-examples/cli/endpoints/online/model-1/通过 conda 创建并激活虚拟环境。 在本例中,
azureml-inference-server-http包会自动安装,因为它作为conda.yml中azureml-defaults包的依赖库而包含在内,如下所示。# Create the environment from the YAML file conda env create --name model-env -f ./environment/conda.yml # Activate the new environment conda activate model-env查看评分脚本。
onlinescoring/score.py
import os import logging import json import numpy import joblib def init(): """ This function is called when the container is initialized/started, typically after create/update of the deployment. You can write the logic here to perform init operations like caching the model in memory """ global model # AZUREML_MODEL_DIR is an environment variable created during deployment. # It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION) # Please provide your model's folder name if there is one model_path = os.path.join( os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl" ) # deserialize the model file back into a sklearn model model = joblib.load(model_path) logging.info("Init complete") def run(raw_data): """ This function is called for every invocation of the endpoint to perform the actual scoring/prediction. In the example we extract the data from the json input and call the scikit-learn model's predict() method and return the result back """ logging.info("model 1: request received") data = json.loads(raw_data)["data"] data = numpy.array(data) result = model.predict(data) logging.info("Request processed") return result.tolist()使用指定评分脚本和模型文件运行推理服务器。 指定的模型目录(
model_dir参数)将定义为AZUREML_MODEL_DIR变量并在评分脚本中检索。 在本例中,我们指定当前目录 (./),因为子目录在评分脚本中指定为model/sklearn_regression_model.pkl。azmlinfsrv --entry_script ./onlinescoring/score.py --model_dir ./如果服务器已启动并成功调用评分脚本,则会显示示例启动日志。 否则,日志中会出现错误消息。
使用示例数据测试评分脚本。 打开另一个终端并移动到同一工作目录以运行命令。 使用
curl命令将示例请求发送到服务器并接收评分结果。curl --request POST "127.0.0.1:5001/score" --header "Content-Type:application/json" --data @sample-request.json如果评分脚本中没有问题,则将返回评分结果。 如果发现错误,可以尝试更新评分脚本,并再次启动服务器以测试更新的脚本。
服务器路由
服务器正在侦听这些路由的端口 5001(默认情况)。
| 名称 | 路由 |
|---|---|
| 运行情况探测 | 127.0.0.1:5001/ |
| 分数 | 127.0.0.1:5001/score |
| OpenAPI (swagger) | 127.0.0.1:5001/swagger.json |
服务器参数
下表包含服务器接受的参数:
| 参数 | 必须 | 默认 | 说明 |
|---|---|---|---|
| entry_script | True | 空值 | 评分脚本的相对路径或绝对路径。 |
| model_dir | 错误 | 空值 | 包含用于推理的模型的目录的相对路径或绝对路径。 |
| port | False | 5001 | 服务器的服务端口。 |
| worker_count | False | 1 | 将处理并发请求的工作线程数。 |
| appinsights_instrumentation_key | 错误 | 空值 | 将发布日志的 Application Insights 的检测密钥。 |
| access_control_allow_origins | False | 空值 | 为指定的源启用 CORS。 使用“,”分隔多个源。 示例:“microsoft.com、bing.com” |
请求流
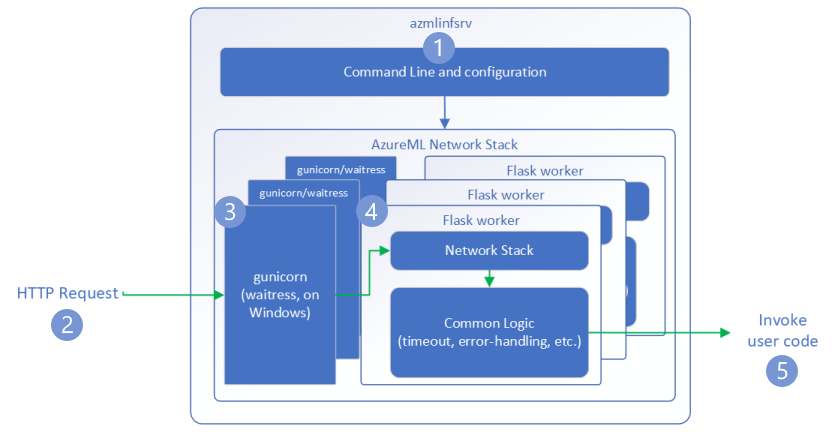
以下步骤说明 Azure 机器学习推理 HTTP 服务器 (azmlinfsrv) 如何处理传入请求:
- Python CLI 包装器位于服务器的网络堆栈周围,用于启动服务器。
- 客户端向服务器发送请求。
- 收到请求时,该请求会通过 WSGI 服务器,然后被分派给某个辅助角色。
- 然后,Flask 应用会处理请求,并加载入口脚本和任何依赖项。
- 最后,将请求发送到入口脚本。 然后,入口脚本对已加载的模型进行推理调用并返回响应。
日志介绍
下面介绍了 Azure 机器学习推理 HTTP 服务器的日志。 在本地运行 azureml-inference-server-http 时,可以获取日志,如果使用的是联机终结点,则可以获取容器日志。
注意
自版本 0.8.0 以来,日志记录格式已更改。 如果发现日志样式不同,请将 azureml-inference-server-http 包更新为最新版本。
提示
如果使用的是联机终结点,则来自推理服务器的日志以 Azure Machine Learning Inferencing HTTP server <version>开头。
启动日志
服务器启动时,日志会先显示服务器设置,如下所示:
Azure Machine Learning Inferencing HTTP server <version>
Server Settings
---------------
Entry Script Name: <entry_script>
Model Directory: <model_dir>
Worker Count: <worker_count>
Worker Timeout (seconds): None
Server Port: <port>
Application Insights Enabled: false
Application Insights Key: <appinsights_instrumentation_key>
Inferencing HTTP server version: azmlinfsrv/<version>
CORS for the specified origins: <access_control_allow_origins>
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:<port>/
Score: POST 127.0.0.1:<port>/score
<logs>
例如,遵循 end-to-end example 启动服务器时:
Azure Machine Learning Inferencing HTTP server v0.8.0
Server Settings
---------------
Entry Script Name: /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
Model Directory: ./
Worker Count: 1
Worker Timeout (seconds): None
Server Port: 5001
Application Insights Enabled: false
Application Insights Key: None
Inferencing HTTP server version: azmlinfsrv/0.8.0
CORS for the specified origins: None
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:5001/
Score: POST 127.0.0.1:5001/score
2022-12-24 07:37:53,318 I [32726] gunicorn.error - Starting gunicorn 20.1.0
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Listening at: http://0.0.0.0:5001 (32726)
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Using worker: sync
2022-12-24 07:37:53,322 I [32756] gunicorn.error - Booting worker with pid: 32756
Initializing logger
2022-12-24 07:37:53,779 I [32756] azmlinfsrv - Starting up app insights client
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Found user script at /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - run() is not decorated. Server will invoke it with the input in JSON string.
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Invoking user's init function
2022-12-24 07:37:55,974 I [32756] azmlinfsrv.user_script - Users's init has completed successfully
2022-12-24 07:37:55,976 I [32756] azmlinfsrv.swagger - Swaggers are prepared for the following versions: [2, 3, 3.1].
2022-12-24 07:37:55,977 I [32756] azmlinfsrv - AML_FLASK_ONE_COMPATIBILITY is set, but patching is not necessary.
日志格式
推理服务器中的日志采用以下格式生成,启动器脚本除外,因为它们不是 python 包的一部分:
<UTC Time> | <level> [<pid>] <logger name> - <message>
此处的 <pid> 进程 ID,<level> 是日志记录级别的第一个字符:E 表示 ERROR,I 表示 INFO 等。
Python 中有六种级别的日志记录,含有与严重性相关的数字:
| 日志记录级别 | 数值 |
|---|---|
| 关键 | 50 |
| ERROR | 40 |
| WARNING | 30 |
| INFO | 20 |
| DEBUG | 10 |
| NOTSET | 0 |
故障排除指南
在本节中,我们将提供 Azure 机器学习推理 HTTP 服务器的基本故障排除技巧。 如果要对联机终结点进行故障排除,另请参阅联机终结点部署故障排除
基本步骤
故障排除的基本步骤包括:
- 收集 Python 环境的版本信息。
- 确保环境文件中指定的 azureml-inference-server-http python 包版本与启动日志中显示的 AzureML 推理 HTTP 服务器版本相匹配。 有时,pip 的依赖项解析程序会导致安装不必要的包版本。
- 如果在环境中指定 Flask(和/或其依赖项),请将其移除。 依赖项包括
Flask、Jinja2、itsdangerous、Werkzeug、MarkupSafe和click。 Flask 作为依赖项列在服务器包中,最好让服务器安装它。 这样,当服务器支持新版 Flask 时,你将自动获取新版本。
服务器版本
服务器包 azureml-inference-server-http 会发布到 PyPI。 可以在 PyPI 页面上查找我们的更改日志和所有先前版本。 如果使用的是早期版本,请更新到最新版本。
- 0.4.x:训练映像 ≤
20220601和azureml-defaults>=1.34,<=1.43中捆绑的版本。0.4.13是最新稳定版本。 如果使用版本0.4.11之前的服务器,则可能会看到 Flask 依赖项问题,例如无法从jinja2导入名称Markup。 如果可能,建议升级到0.4.13或0.8.x(最新版本)。 - 0.6.x:预装在推理映像 ≤ 20220516 的版本。 最新稳定版本为
0.6.1。 - 0.7.x:第一个支持 Flask 2 的版本。 最新稳定版本为
0.7.7。 - 0.8.x:日志格式发生更改,Python 3.6 支持删除。
包依赖项
与服务器 azureml-inference-server-http 最相关的包是以下包:
- flask
- opencensus-ext-azure
- inference-schema
如果在 Python 环境中指定 azureml-defaults,则会依赖 azureml-inference-server-http 包,并且将自动安装。
提示
如果使用 Python SDK v1,并且未在 Python 环境中显式指定 azureml-defaults,则 SDK 可能会为你添加包。 但是,它会将其锁定到 SDK 所在的版本。 例如,如果 SDK 版本为 1.38.0,则会将 azureml-defaults==1.38.0 添加到环境的 pip 要求中。
常见问题
1. 我在服务器启动过程中遇到如下错误:
TypeError: register() takes 3 positional arguments but 4 were given
File "/var/azureml-server/aml_blueprint.py", line 251, in register
super(AMLBlueprint, self).register(app, options, first_registration)
TypeError: register() takes 3 positional arguments but 4 were given
你已在 python 环境中安装 Flask 2,但运行的 azureml-inference-server-http 版本不支持 Flask 2。 在 azureml-inference-server-http>=0.7.0 中添加了对 Flask 2 的支持,该支持也在 azureml-defaults>=1.44 中。
如果不在 AzureML Docker 映像中使用此包,请使用最新版
azureml-inference-server-http或azureml-defaults。如果在 AzureML Docker 映像中使用此包,请确保使用在 2022 年 7 月或之后构建的映像。该映像版本在容器日志中提供。 应该能够找到如下所示的日志:
2022-08-22T17:05:02,147738763+00:00 | gunicorn/run | AzureML Container Runtime Information 2022-08-22T17:05:02,161963207+00:00 | gunicorn/run | ############################################### 2022-08-22T17:05:02,168970479+00:00 | gunicorn/run | 2022-08-22T17:05:02,174364834+00:00 | gunicorn/run | 2022-08-22T17:05:02,187280665+00:00 | gunicorn/run | AzureML image information: openmpi4.1.0-ubuntu20.04, Materializaton Build:20220708.v2 2022-08-22T17:05:02,188930082+00:00 | gunicorn/run | 2022-08-22T17:05:02,190557998+00:00 | gunicorn/run |映像的生成日期显示在“具体化生成”之后,在上面的示例中为
20220708或 2022 年 7 月 8 日。 此映像与 Flask 2 兼容。 如果在容器日志中未看到这样的横幅,则表明映像已过期,应进行更新。 如果使用 CUDA 映像且找不到较新的映像,请检查映像在 AzureML-Containers 中是否已弃用。 如果是,则应该能够找到替换项。如果将服务器与联机终结点结合使用,则还可以在 Azure 机器学习工作室中的联机终结点页的“部署日志”下找到日志。 如果你使用 SDK v1 进行部署,并且未在部署配置中显式指定映像,则它会默认使用与本地 SDK 工具集匹配的
openmpi4.1.0-ubuntu20.04版本,该版本可能不是映像的最新版本。 例如,SDK 1.43 将默认使用不兼容的openmpi4.1.0-ubuntu20.04:20220616。 请确保使用最新 SDK 进行部署。如果出于某种原因而无法更新映像,可以通过固定
azureml-defaults==1.43或azureml-inference-server-http~=0.4.13(将通过Flask 1.0.x来安装较旧版本的服务器)来暂时避免此问题。
2. 启动期间在模块 opencensus、jinja2、MarkupSafe 或 click 上遇到 ImportError 或 ModuleNotFoundError,如以下消息所示:
ImportError: cannot import name 'Markup' from 'jinja2'
旧版 (<= 0.4.10) 服务器未将 Flask 的依赖项固定到兼容版本。 此问题已在最新版服务器中解决。
后续步骤
- 有关如何创建入口脚本和部署模型的详细信息,请参阅如何使用 Azure 机器学习部署模型。
- 了解用于推理的预生成 Docker 映像
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈