你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
在批处理终结点中部署用于评分的模型
适用范围: Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
批处理终结点提供了一种便捷的方式来部署可以对大量数据执行推理的模型。 这些终结点简化了托管批量评分模型的过程,使你可以将重点放在机器学习上,而不是基础结构上。
在以下情况下使用批处理终结点进行模型部署:
- 需要花费较长时间来运行推理的高开销模型。
- 需要对分布在多个文件中的大量数据执行推理。
- 没有低延迟要求。
- 可以利用并行化。
在本文中,你将使用批处理终结点来部署一个机器学习模型,以解决经典的 MNIST(改进版美国国家标准与技术研究所)数字识别问题。 然后,你部署的模型会对大量数据(本例中为图像文件)执行批量推理。 首先,需要对使用 Torch 创建的模型进行批量部署。 此部署将成为终结点中的默认部署。 稍后,需要为使用 TensorFlow (Keras) 创建的模型创建第二个部署,测试第二个部署,然后将其设置为终结点的默认部署。
要了解本地运行本文中命令所需的代码示例和文件,请参阅克隆示例存储库部分。 代码示例和文件包含在 azureml-examples 存储库中。
先决条件
在按照本文中的步骤操作之前,请确保满足以下先决条件:
Azure 订阅。 如果没有 Azure 订阅,请在开始操作前先创建一个免费帐户。 试用免费版或付费版 Azure 机器学习。
Azure 机器学习工作区。 如果没有,请使用如何管理工作区一文中的步骤创建一个。
若要执行以下任务,请确保在工作区中具有以下权限:
若要创建/管理批处理终结点和部署:请使用所有者角色、参与者角色或允许
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*的自定义角色。若要在工作区资源组中创建 ARM 部署:在部署工作区的资源组中使用所有者角色、参与者角色或允许
Microsoft.Resources/deployments/write的自定义角色。
需要安装以下软件才能使用 Azure 机器学习:
Azure CLI 和 Azure 机器学习的
ml扩展。az extension add -n ml
克隆示例存储库
本文中的示例基于 azureml-examples 存储库中包含的代码示例。 要在无需复制/粘贴 YAML 和其他文件的情况下在本地运行命令,请先克隆存储库,然后将目录更改为以下文件夹:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
准备你的系统
连接到工作区
首先,连接到你将处理工作的 Azure 机器学习工作区。
如果尚未为 Azure CLI 指定默认设置,则应保存默认设置。 若要避免多次传入订阅、工作区、资源组和位置的值,请运行此代码:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
创建计算
批处理终结点在计算群集上运行且支持 Azure 机器学习计算群集 (AmlCompute) 和 Kubernetes 群集。 群集是一种共享资源,因此一个群集可以托管一个或多个批处理部署(如果需要,还可以托管其他工作负载)。
创建名为 batch-cluster 的计算,如以下代码所示。 可以根据需要进行调整,并使用 azureml:<your-compute-name> 引用计算。
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
注意
此时不收取计算费用,因为在调用批处理终结点并提交批量评分作业之前,群集将保持为 0 个节点。 有关计算成本的详细信息,请参阅管理和优化 AmlCompute 的成本。
创建批处理终结点
批处理终结点是客户端可以调用以触发批量评分作业的 HTTPS 终结点。 批量评分作业是对多个输入进行评分的作业。 批处理部署是一组计算资源,托管执行实际批量评分(或批量推理)的模型。 一个批处理终结点可以包含多个批处理部署。 有关批处理终结点的详细信息,请参阅什么是批处理终结点?。
提示
其中一个批处理部署充当该终结点的默认部署。 调用终结点时,默认部署会执行实际的批量评分。 有关批处理终结点和部署的详细信息,请参阅批处理终结点和批处理部署。
命名终结点。 终结点的名称在 Azure 区域中必须唯一,因为该名称包含在终结点的 URI 中。 例如,
westus2中只能有一个名为mybatchendpoint的批处理终结点。配置批处理终结点
以下 YAML 文件定义了批处理终结点。 可以将此文件与 CLI 命令配合使用以创建批处理终结点。
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learning下表描述了终结点的关键属性。 有关完整的批处理终结点 YAML 架构,请参阅 CLI (v2) 批处理终结点 YAML 架构。
密钥 说明 name批处理终结点的名称。 在 Azure 区域级别需是唯一的。 description批处理终结点的说明。 此属性是可选的。 tags要包含在终结点中的标记。 此属性是可选的。 创建终结点:
创建批处理部署
模型部署是一组资源,在承载执行实际推理的模型时需要它。 若要创建批处理模型部署,你需要具备以下项:
- 工作区中已注册的模型
- 用于为模型评分的代码
- 安装了模型的依赖项的环境
- 预先创建的计算和资源设置
首先,注册要部署的模型 - 用于热门数字识别问题 (MNIST) 的 Torch 模型。 批处理部署只能部署已在工作区中注册的模型。 如果要部署的模型已注册,则可以跳过此步骤。
提示
模型与部署关联,而不与终结点关联。 这意味着,只要不同的模型(或模型版本)部署在不同的部署中,单个终结点就可以处理同一终结点下的不同模型(或模型版本)。
现在可以创建评分脚本了。 批处理部署需要一个评分脚本,该脚本指示应如何执行给定的模型,以及如何处理输入数据。 批处理终结点支持使用 Python 创建的脚本。 在本例中,你需要部署一个模型来读取表示数字的图像文件并输出相应的数字。 评分脚本如下所示:
注意
对于 MLflow 模型,Azure 机器学习会自动生成评分脚本,因此无需提供评分脚本。 如果你的模型是 MLflow 模型,则可以跳过此步骤。 有关批处理终结点如何与 MLflow 模型配合工作的详细信息,请参阅在批处理部署中使用 MLflow 模型一文。
警告
如果要在批处理终结点下部署自动化机器学习 (AutoML) 模型,请注意 AutoML 提供的评分脚本仅适用于联机终结点,而不适用于批处理执行。 有关如何为批处理部署创建评分脚本的信息,请参阅创建批处理部署的评分脚本。
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)创建要在其中运行批处理部署的环境。 环境应该包括批处理终结点所需的
azureml-core和azureml-dataset-runtime[fuse]包以及运行你的代码所需的任何依赖项。 在本例中,依赖项已捕获在conda.yaml文件中:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]重要
包
azureml-core和azureml-dataset-runtime[fuse]是批量部署所必需的,应包含在环境依赖项中。按如下所示指定环境:
环境定义将作为匿名环境包含在部署定义本身中。 你将在部署的以下行中看到:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml警告
批处理部署不支持特选环境。 需要指定自己的环境。 始终可以使用特选环境的基础映像作为你自己的环境来简化过程。
创建部署定义
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: info下表描述了批处理部署的关键属性。 有关完整的批处理部署 YAML 架构,请参阅 CLI (v2) 批处理部署 YAML 架构。
密钥 描述 name部署的名称。 endpoint_name要在其下创建部署的终结点的名称。 model用于批量评分的模型。 该示例使用 path以内联方式定义模型。 此定义允许使用自动生成的名称和版本自动上传和注册模型文件。 有关更多选项,请参阅模型架构。 对于生产方案,最佳做法应该是单独创建模型并在此处引用模型。 若要引用现有模型,请使用azureml:<model-name>:<model-version>语法。code_configuration.code包含用于为模型评分的所有 Python 源代码的本地目录。 code_configuration.scoring_scriptcode_configuration.code目录中的 Python 文件。 此文件必须具有init()函数和run()函数。 对于任何成本较高或者一般性的准备工作(例如将模型加载到内存中),请使用init()函数。init()将在进程开始时仅调用一次。 使用run(mini_batch)为每个项评分;mini_batch值是文件路径列表。run()函数应返回 Pandas 数据帧或数组。 每个返回的元素指示mini_batch中成功运行一次输入元素。 有关如何创作评分脚本的详细信息,请参阅了解评分脚本。environment用于为模型评分的环境。 该示例使用 conda_file和image以内联方式定义环境。conda_file依赖项将安装在image之上。 环境将自动使用自动生成的名称和版本进行注册。 有关更多选项,请参阅环境架构。 对于生产方案,最佳做法应该是单独创建环境并在此处引用环境。 若要引用现有环境,请使用azureml:<environment-name>:<environment-version>语法。compute用于运行批量评分的计算。 该示例使用在开头部分创建的 batch-cluster,并使用azureml:<compute-name>语法引用它。resources.instance_count每个批量评分作业要使用的实例数。 settings.max_concurrency_per_instance每个实例的并行 scoring_script运行的最大数量。settings.mini_batch_sizescoring_script可以在一次run()调用中处理的文件数。settings.output_action应如何在输出文件中组织输出。 append_row会将所有run()返回的输出结果合并到一个名为output_file_name的文件中。summary_only不会合并输出结果,而只会计算error_threshold。settings.output_file_nameappend_rowoutput_action批量评分输出文件的名称。settings.retry_settings.max_retries失败的 scoring_scriptrun()的最大尝试次数。settings.retry_settings.timeout对小批量进行评分的 scoring_scriptrun()超时(以秒计)。settings.error_threshold应忽略的输入文件评分失败次数。 如果整个输入的错误计数超出此值,则批量评分作业将终止。 此示例使用 -1,指示允许失败任意次,而不会终止批量评分作业。settings.logging_level日志详细程度。 值(以详细程度递增的顺序排列)为:WARNING、INFO 和 DEBUG。 settings.environment_variables要针对每个批量评分作业设置的环境变量名称/值对字典。 创建部署:
运行以下代码以在批处理终结点下创建一个批处理部署,并将其设置为默认部署。
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-default提示
--set-default参数将新创建的部署设置为终结点的默认部署。 这是一种简便的方法来创建终结点的新默认部署,尤其对于首次创建部署。 对于生产方案,最佳做法可能是创建一个新部署(而不将其设置为默认部署)。 验证部署是否按预期工作,稍后更新默认部署。 有关实现此过程的详细信息,请参阅部署新模型部分。检查批处理终结点和部署详细信息。

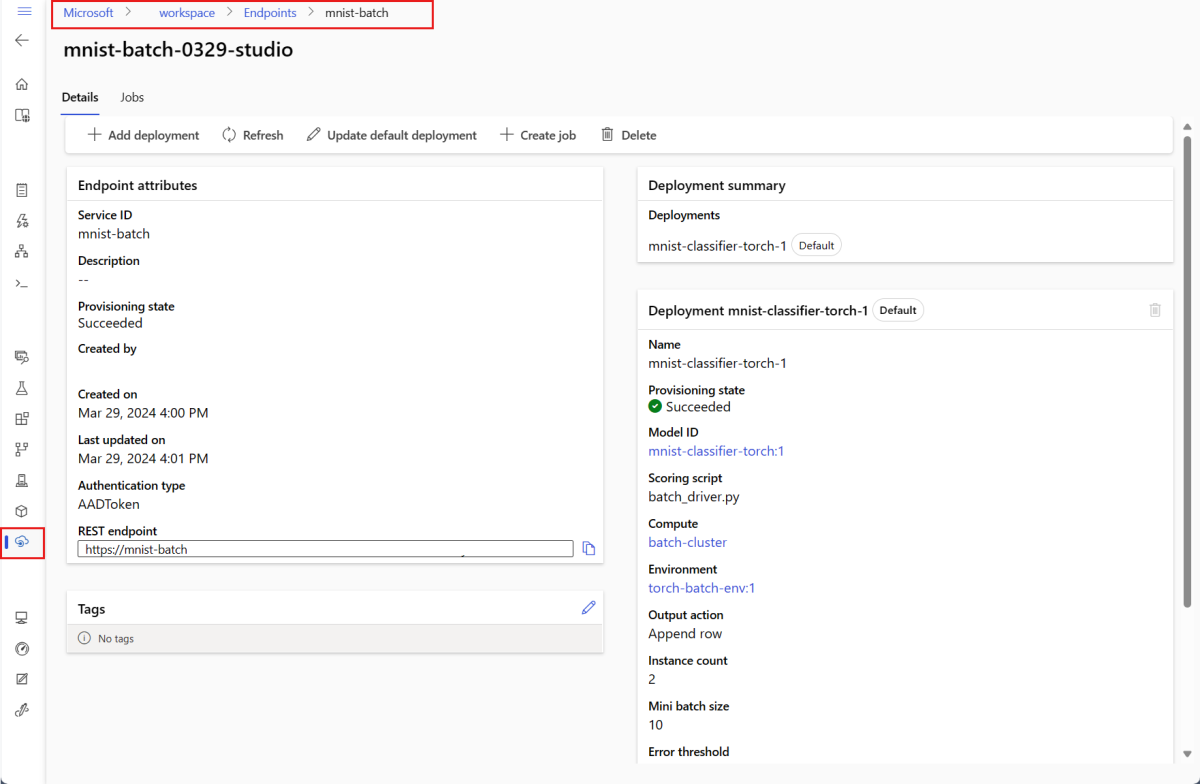
运行批量终结点并访问结果
调用批处理终结点会触发批量评分作业。 调用响应中返回作业 name,该作业可用于跟踪批量评分进度。 在批处理终结点中运行评分模型时,需要指定输入数据的路径,以便终结点可以找到要评分的数据。 以下示例演示如何通过 Azure 存储帐户中存储的 MNIST 数据集的示例数据启动新作业。
可以使用 Azure CLI、Azure 机器学习 SDK 或 REST 终结点来运行和调用批处理终结点。 有关这些选项的更多详细信息,请参阅为批处理终结点创建作业和输入数据。
注意
并行化的工作原理是什么?
批处理部署在文件级别分配工作,这意味着,如果某个文件夹包含 100 个文件并以 10 个文件为一个微批,则会生成 10 个批,每批包含 10 个文件。 请注意,无论涉及的文件大小如何,都会发生这种情况。 如果文件太大因而无法按较大的微批进行处理,我们建议将文件拆分为较小的文件以实现更高的并行度,或减少每个微批的文件数。 目前,批处理部署无法考虑文件大小分布的偏差。
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



批处理终结点支持读取位于不同位置的文件或文件夹。 要详细了解支持的类型以及如何指定它们,请参阅访问批处理终结点作业中的数据。
监视批处理作业执行进度
批量评分作业通常会花费一段时间来处理整个输入集。

检查批量评分结果
作业输出存储在云存储中,可以在工作区的默认 Blob 存储中,也可以在你指定的存储中。 若要了解如何更改默认值,请参阅配置输出位置。 通过以下步骤,可以在作业完成时在 Azure 存储资源管理器中查看评分结果:
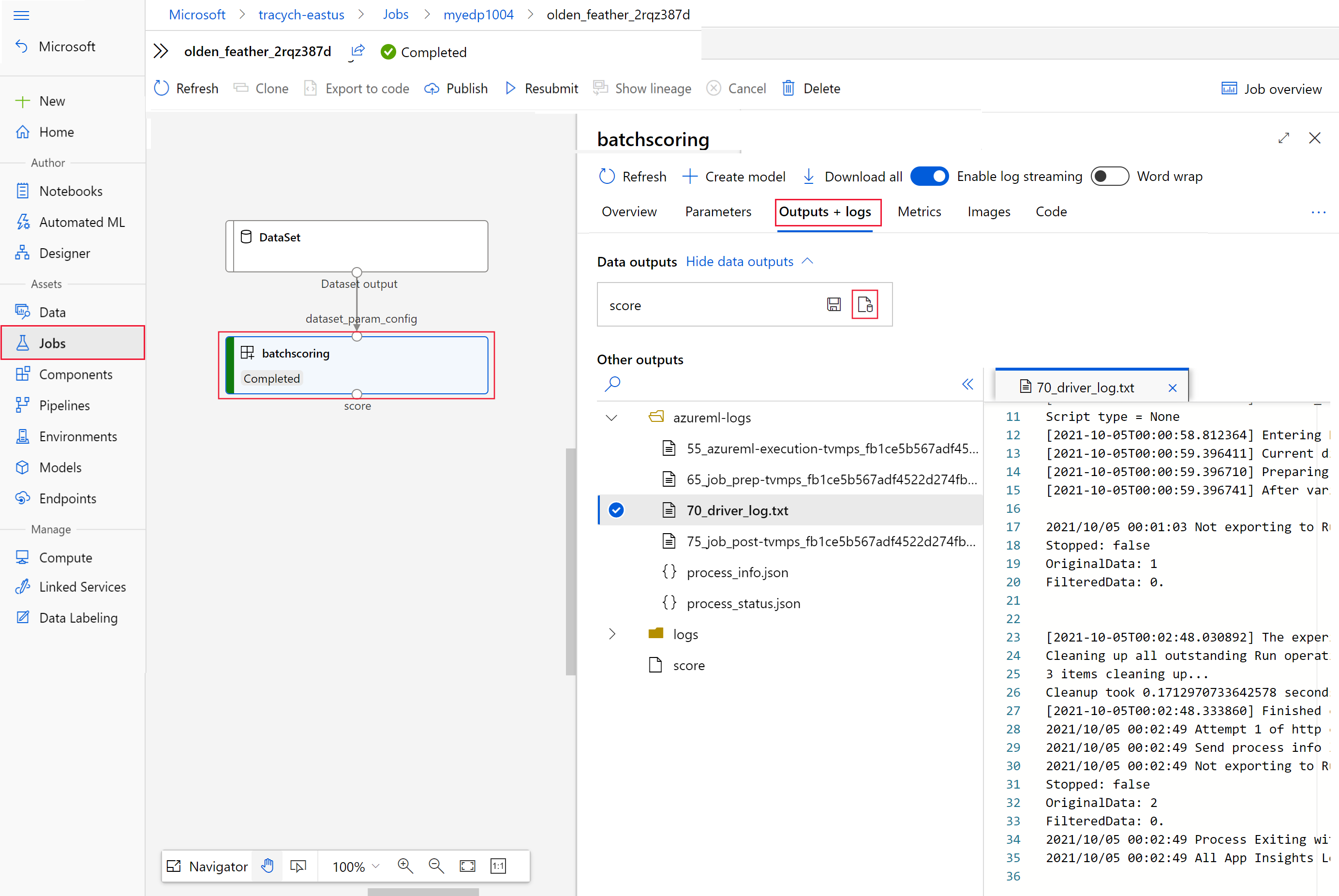
运行以下代码,在 Azure 机器学习工作室中打开批量评分作业。
invoke的响应中还包含以interactionEndpoints.Studio.endpoint值的形式提供的作业工作室链接。az ml job show -n $JOB_NAME --web在作业图中,选择
batchscoring步骤。选择“输出 + 日志”选项卡,然后选择“显示数据输出”。
在“数据输出”中,选择图标以打开“存储资源管理器”。
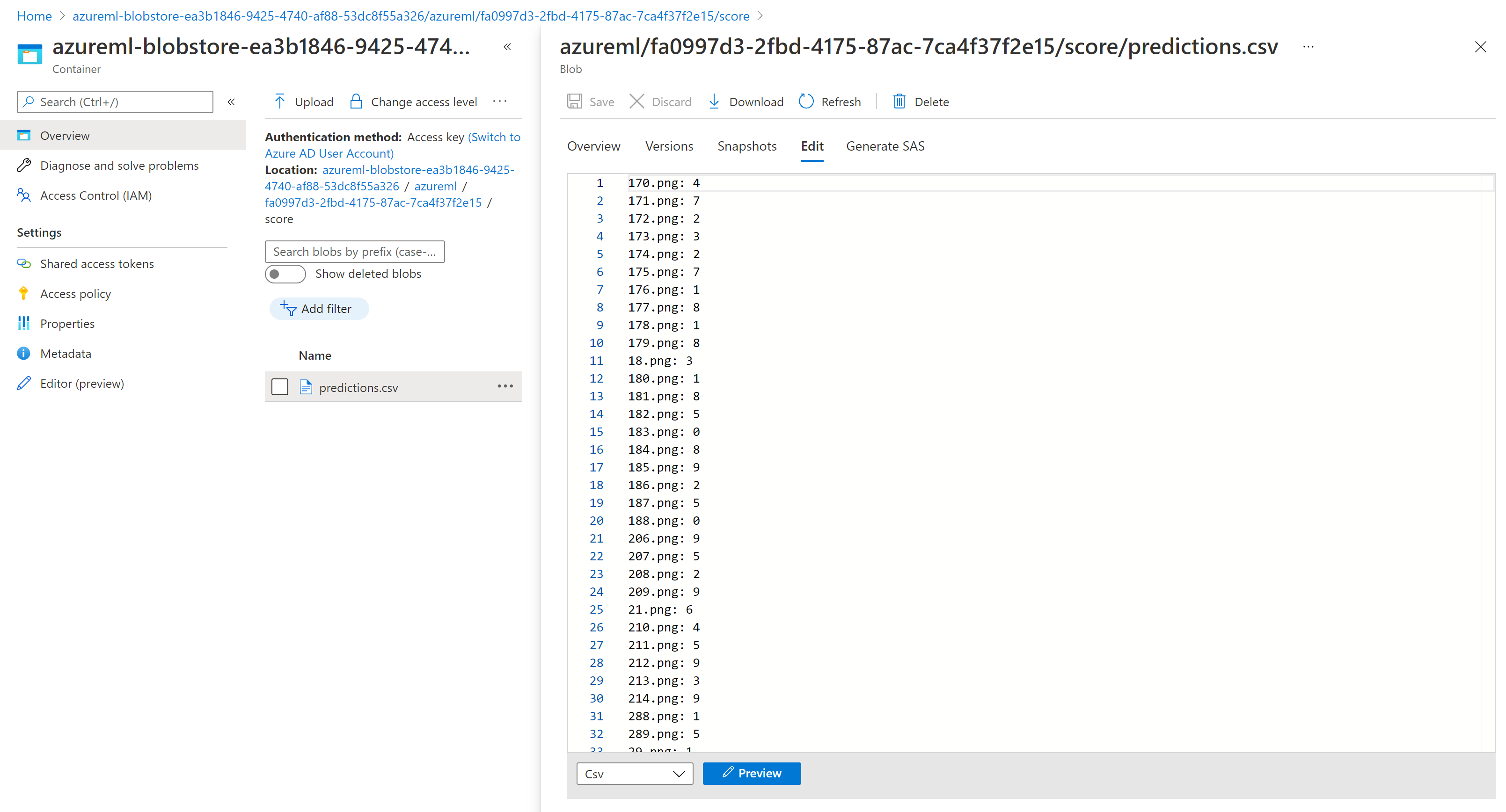
存储资源管理器中的评分结果类似以下示例页:


配置输出位置
默认情况下,批量评分结果存储在工作区的默认 Blob 存储中按作业名称(系统生成的 GUID)命名的某个文件夹内。 可以配置在调用批处理终结点时用于存储评分输出的位置。
使用 output-path 配置 Azure 机器学习已注册的数据集中的任何文件夹。 指定文件夹时,--output-path 的语法与 --input 的语法相同,即都为 azureml://datastores/<datastore-name>/paths/<path-on-datastore>/。 使用 --set output_file_name=<your-file-name> 配置新的输出文件名。
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

警告
必须使用唯一的输出位置。 如果输出文件已存在,批量评分作业将失败。
重要
与输入不同,输出只能存储在 blob 存储帐户上运行的 Azure 机器学习数据存储中。
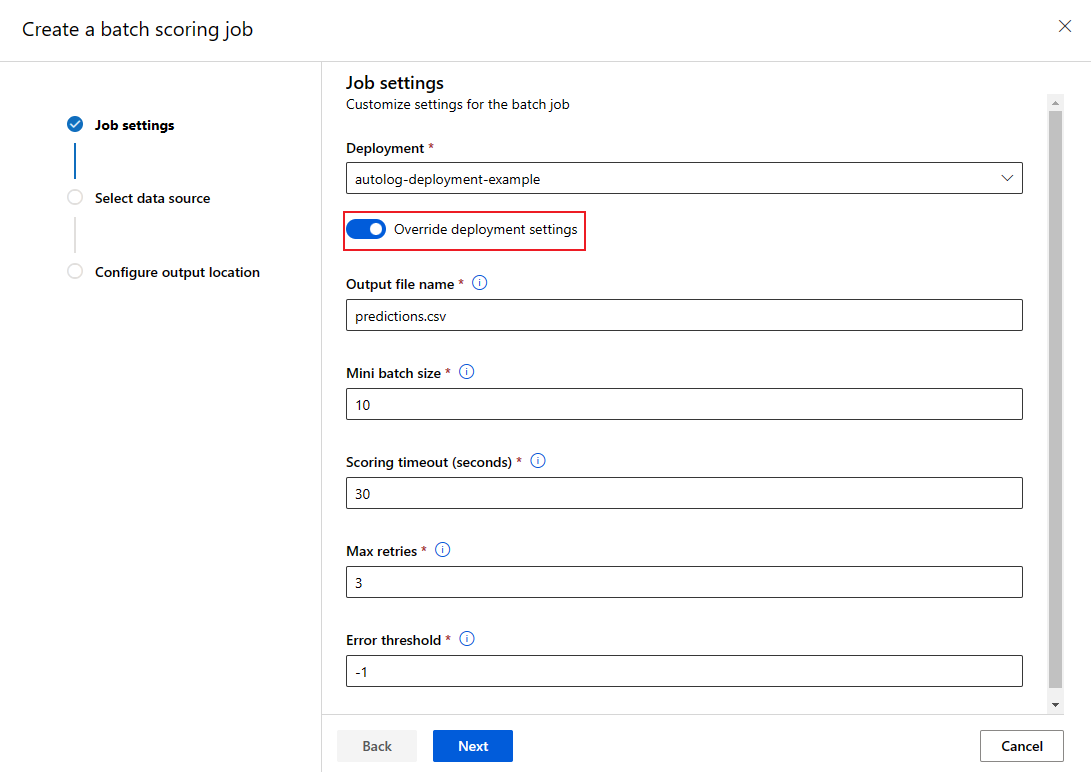
覆盖每个作业的部署配置
调用批处理终结点时,可以覆盖某些设置,以充分利用计算资源并提高性能。 可以按作业配置以下设置:
- 实例计数:使用此设置覆盖要从计算群集请求的实例数。 例如,对于较大的数据输入量,可能需要使用更多实例来加速端到端批量评分。
- 微批大小:使用此设置覆盖要包含在每个微批中的文件数。 微批数由输入文件总计数和微批大小确定。 较小的微批大小会生成更多微批。 微型批处理可以并行运行,但可能需要额外计划并产生额外的调用开销。
- 可以覆盖其他设置,例如最大重试次数、超时,以及错误阈值。 这些设置可能会影响不同工作负载的端到端批量评分时间。
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
将部署添加到终结点
配置了一个包含部署的批处理终结点后,可以继续微调模型并添加新的部署。 在同一个终结点下开发和部署新模型时,批处理终结点将继续为默认部署提供服务。 部署不能相互影响。
在本示例中,你将添加第二个部署,该部署使用 Keras 和 TensorFlow 构建的模型来解决相同的 MNIST 问题。
添加第二个部署
创建要在其中运行批处理部署的环境。 在该环境中包含运行代码所需的任何依赖项。 还需要添加库
azureml-core,因为它是正常进行批量部署所必需的。 以下环境定义具有运行包含 TensorFlow 的模型时所需的库。环境定义将作为匿名环境包含在部署定义本身中。
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml使用的 conda 文件如下所示:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]创建模型的评分脚本:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)创建部署定义
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv创建部署:
测试非默认批处理部署
若要测试新的非默认部署,需要知道你要运行的部署的名称。
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
请注意 --deployment-name 用于指定要执行的部署。 使用此参数可以对非默认部署执行 invoke 操作,而不更新批处理终结点的默认部署。
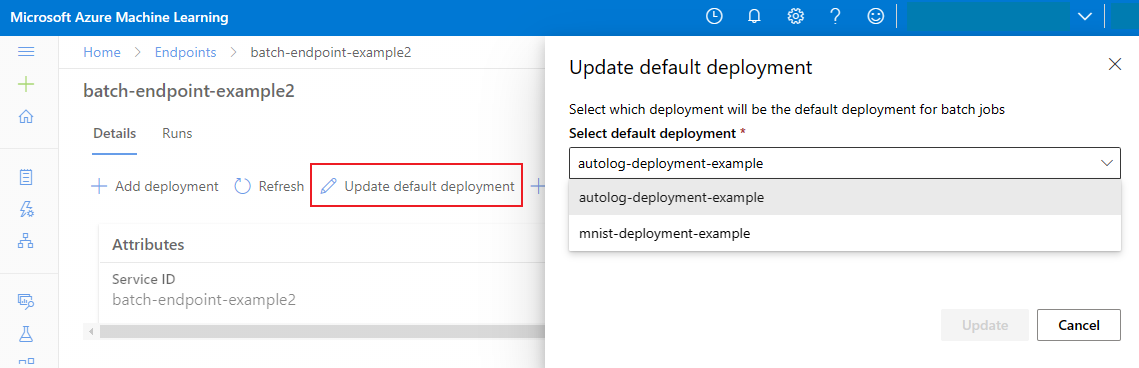
更新默认批处理部署
尽管可以在终结点内调用特定部署,但通常需要调用终结点本身,让终结点决定使用哪个部署 - 默认部署。 可以更改默认部署(进而更改处理部署的模型),而无需更改与调用终结点的用户之间的协定。 使用以下代码更新默认部署:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
删除批处理终结点和部署
如果不使用旧的批处理部署,请通过运行以下代码将其删除。 --yes 用于确认删除。
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
运行以下代码以删除批处理终结点和及其所有基础部署。 不会删除批量评分作业。
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes
相关内容
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈