你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用批处理终结点从 Fabric 运行 Azure 机器学习模型(预览版)
适用范围: Azure CLI ml 扩展 v2(当前版本)Python SDK azure-ai-ml v2(当前版本)
Azure CLI ml 扩展 v2(当前版本)Python SDK azure-ai-ml v2(当前版本)
本文介绍如何从 Microsoft Fabric 使用 Azure 机器学习批处理部署。 尽管工作流使用部署到批处理终结点的模型,但它也支持从 Fabric 使用批处理管道部署。
重要
此功能目前处于公开预览状态。 此预览版在提供时没有附带服务级别协议,我们不建议将其用于生产工作负荷。 某些功能可能不受支持或者受限。
有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
先决条件
- 获取 Microsoft Fabric 订阅。 或者注册免费的 Microsoft Fabric 试用版。
- 登录 Microsoft Fabric。
- Azure 订阅。 如果没有 Azure 订阅,请在开始操作前先创建一个免费帐户。 试用免费版或付费版 Azure 机器学习。
- 一个 Azure 机器学习工作区。 如果你没有帐户,请使用如何管理工作区中的步骤创建一个。
- 确保你在工作区中具有以下权限:
- 创建/管理批处理终结点和部署:使用允许
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*的所有者角色、参与者角色或自定义角色。 - 在工作区资源组中创建 ARM 部署:在部署工作区的资源组中使用允许
Microsoft.Resources/deployments/write的所有者角色、参与者角色或自定义角色。
- 创建/管理批处理终结点和部署:使用允许
- 确保你在工作区中具有以下权限:
- 一个部署到批处理终结点的模型。 如果你没有这种模型,请使用在批处理终结点中部署评分模型中的步骤创建一个。
- 下载 heart-unlabeled.csv 示例数据集以用于评分。
体系结构
Azure 机器学习无法直接访问 Fabric 的 OneLake 中存储的数据。 不过,你可以使用 OneLake 的功能在 Lakehouse 中创建快捷方式,以读取和写入存储在 Azure Data Lake Gen2 中的数据。 由于 Azure 机器学习支持 Azure Data Lake Gen2 存储,因此,此设置允许你同时使用 Fabric 和 Azure 机器学习。 数据体系结构如下:

配置数据访问权限
若要允许 Fabric 和 Azure 机器学习读取和写入相同的数据而无需复制数据,可以利用 OneLake 快捷方式和 Azure 机器学习数据存储。 通过将 OneLake 快捷方式和数据存储指向同一存储帐户,可以确保 Fabric 和 Azure 机器学习读取和写入相同的基础数据。
在本部分,你将创建或标识一个存储帐户,用于存储批处理终结点将使用的信息,以及 Fabric 用户将在 OneLake 中看到的信息。 Fabric 仅支持启用了分层名称的存储帐户,例如 Azure Data Lake Gen2。
创建存储帐户的 OneLake 快捷方式
在 Fabric 中打开“Synapse 数据工程”体验。
在左侧面板中,选择你的 Fabric 工作区以将其打开。
打开用于配置连接的湖屋。 如果你没有湖屋,请转到“数据工程”体验来创建一个湖屋。 在此示例中,你将使用名为 trusted 的湖屋。
在左侧导航栏中,打开“文件”对应的“更多选项”,然后选择“新建快捷方式”打开向导。

选择“Azure Data Lake Storage Gen2”选项。
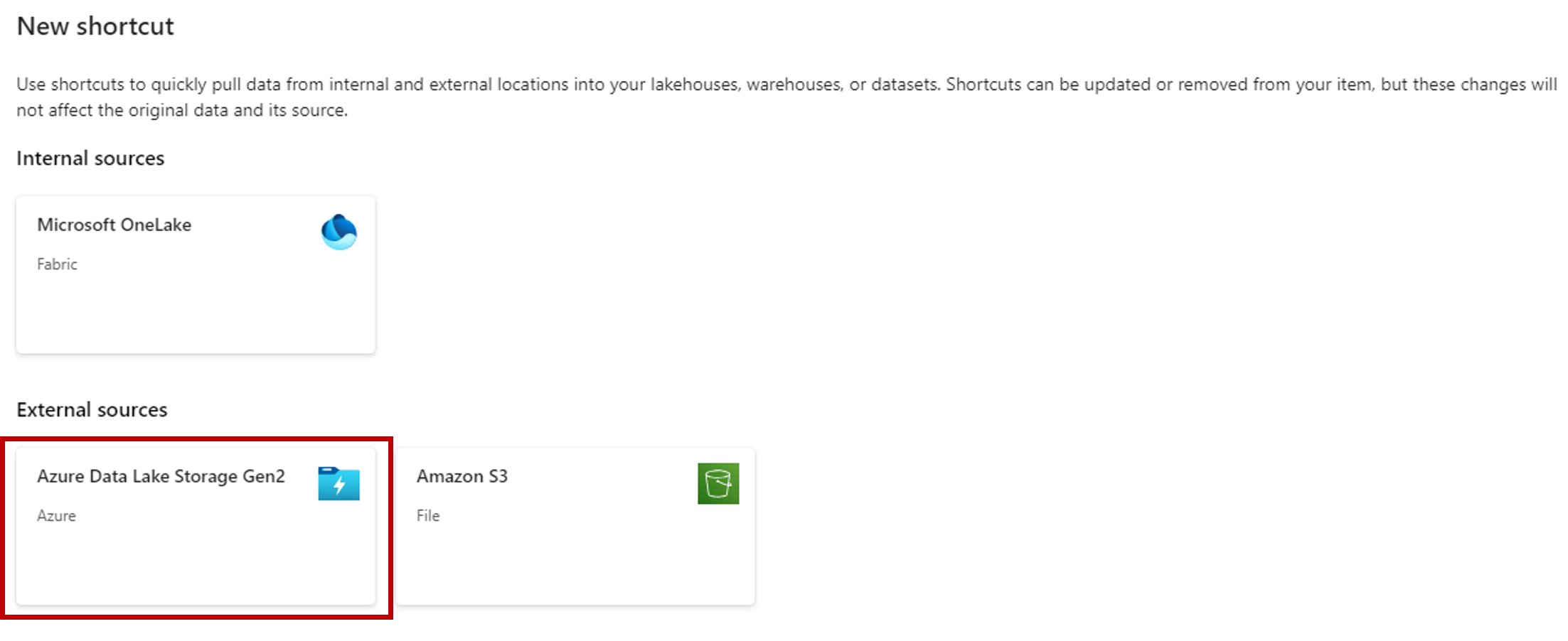
在“连接设置”部分,粘贴与 Azure Data Lake Gen2 存储帐户关联的 URL。
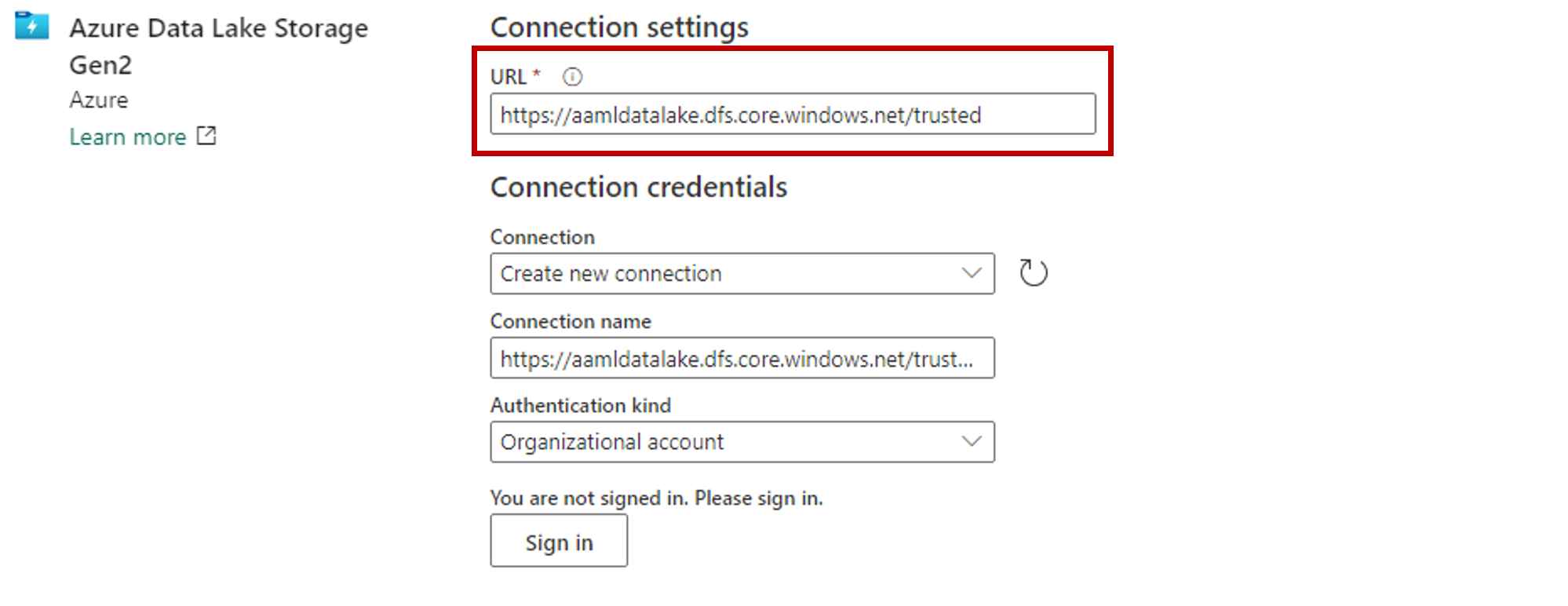
在“连接凭据”部分:
- 对于“连接”,请选择“创建新连接”。
- 对于“连接名称”,请保留默认填充的值。
- 对于“身份验证类型”,请选择“组织帐户”,以通过 OAuth 2.0 使用已连接用户的凭据。
- 选择“登录”进行登录。
选择下一步。
如果需要,请配置相对于存储帐户的快捷方式路径。 使用此设置来配置快捷方式将指向的文件夹。
配置快捷方式的“名称”。 此名称将是湖屋中的路径。 在此示例中,请将快捷方式命名为 datasets。
保存更改。



创建指向存储帐户的数据存储
打开 Azure 机器学习工作室。
转到你的 Azure 机器学习工作区。
转到“数据”部分。
选择“数据存储”选项卡。
选择创建。
按如下所述配置数据存储:
对于“数据存储名称”,请输入 trusted_blob。
对于“数据存储类型”,请选择“Azure Blob 存储”。
提示
为何应配置 Azure Blob 存储而不是 Azure Data Lake Gen2? 批处理终结点只能将预测结果写入 Blob 存储帐户。 但是,每个 Azure Data Lake Gen2 存储帐户也是一个 Blob 存储帐户;因此,它们可以互换使用。
使用“订阅 ID”、“存储帐户”和“Blob 容器”(文件系统)从向导中选择存储帐户。
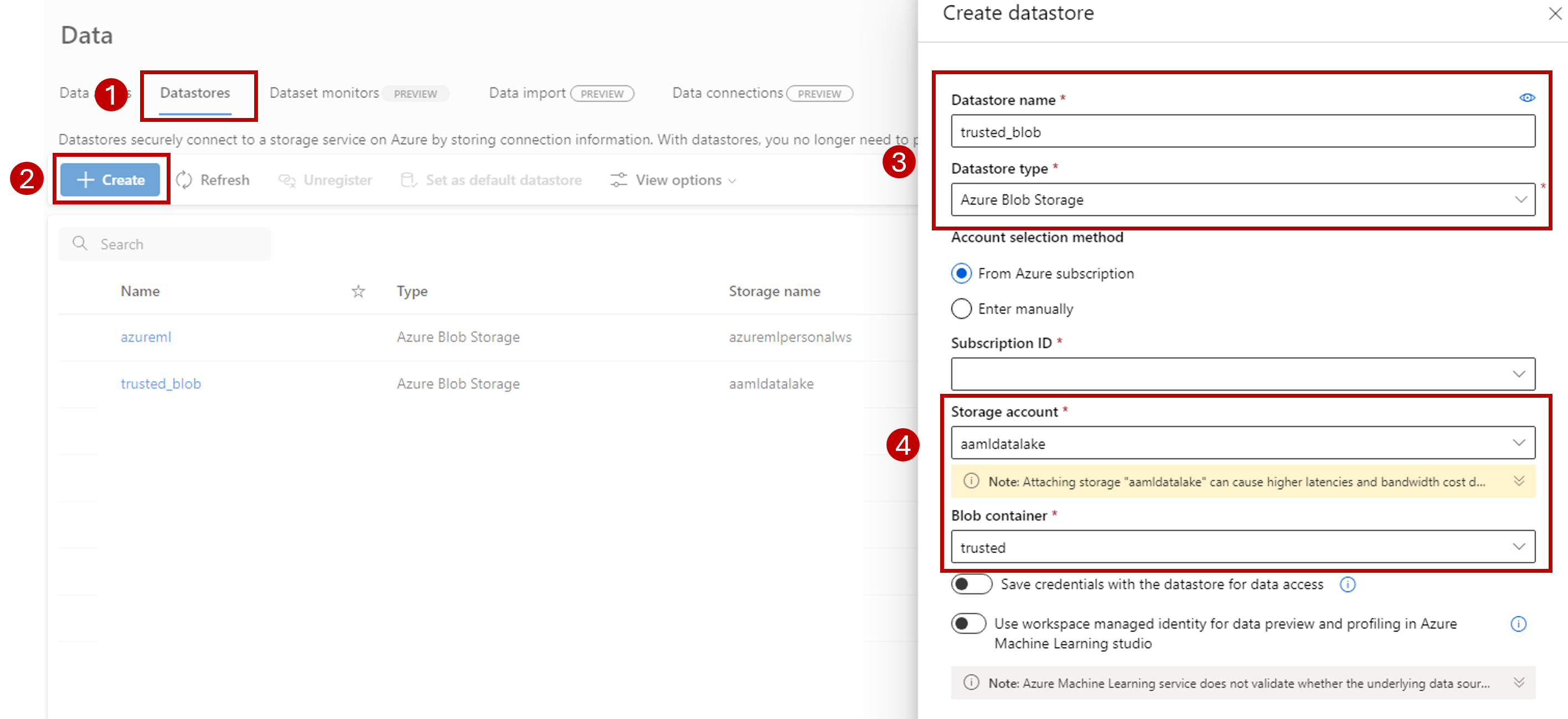
选择创建。
确保运行批处理终结点的计算有权装载此存储帐户中的数据。 尽管访问权限仍由调用终结点的标识授予,但运行批处理终结点的计算需要有权装载你提供的存储帐户。 有关详细信息,请参阅访问存储服务。
上传示例数据集
上传一些示例数据以供终结点用作输入:
转到你的 Fabric 工作区。
选择在其中创建了快捷方式的湖屋。
转到 datasets 快捷方式。
创建一个文件夹用于存储你要评分的示例数据集。 将该文件夹命名为 uci-heart-unlabeled。
使用“获取数据”选项,并选择“上传文件”以上传示例数据集 heart-unlabeled.csv。
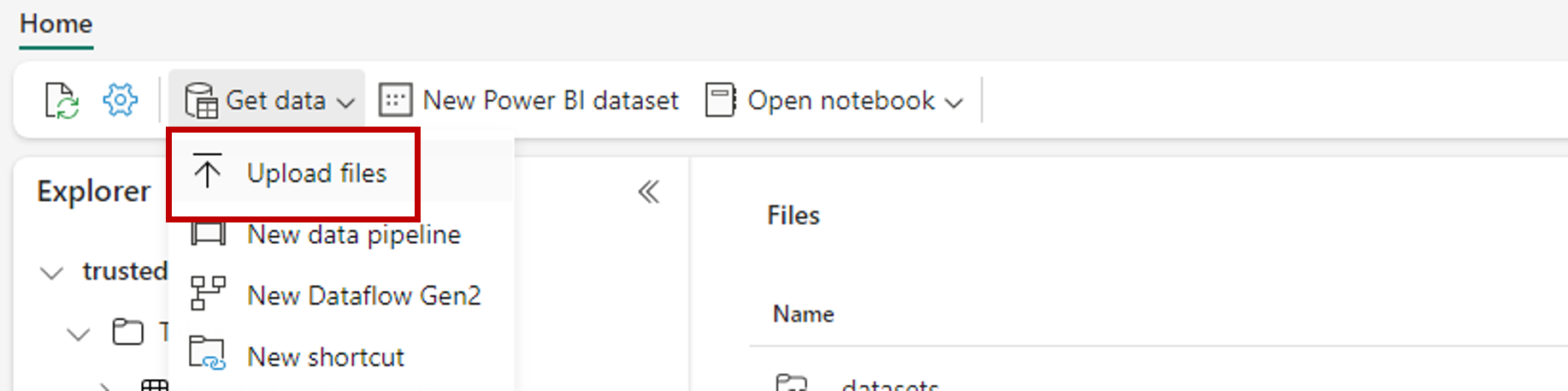
上传示例数据集。
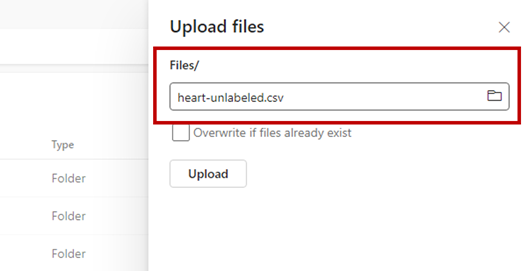
示例文件现在可供使用。 请记下该文件的保存位置的路径。


创建 Fabric 到批量推理的管道
在本部分,你将在现有 Fabric 工作区中创建 Fabric 到批量推理的管道,并调用批处理终结点。
使用主页面左下角的体验选择器图标返回“数据工程”体验(如果已离开该体验)。
打开你的 Fabric 工作区。
在主页的“新建”部分,选择“数据管道”。
为管道命名并选择“创建”。
在设计器画布的工具栏中选择“活动”选项卡。
选择该选项卡末尾的“更多选项”,然后选择“Azure 机器学习”。

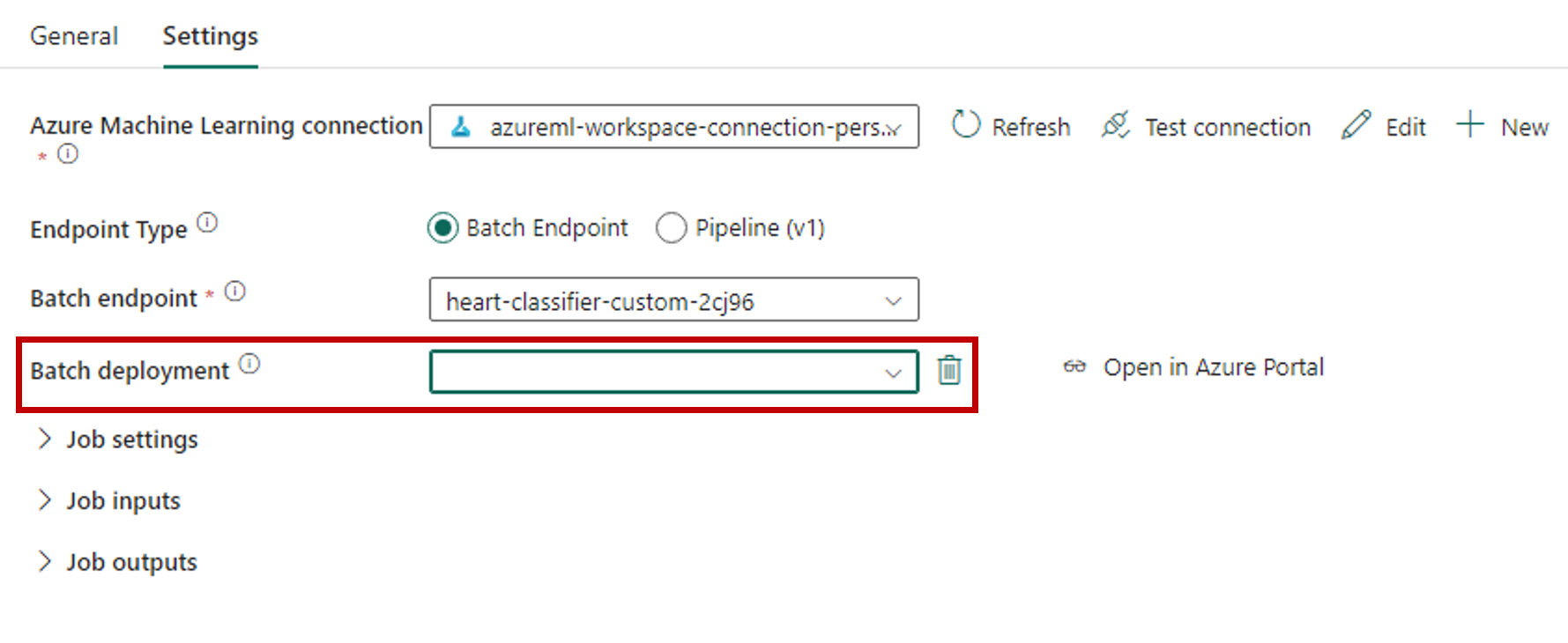
转到“设置”选项卡并如下所述配置活动:
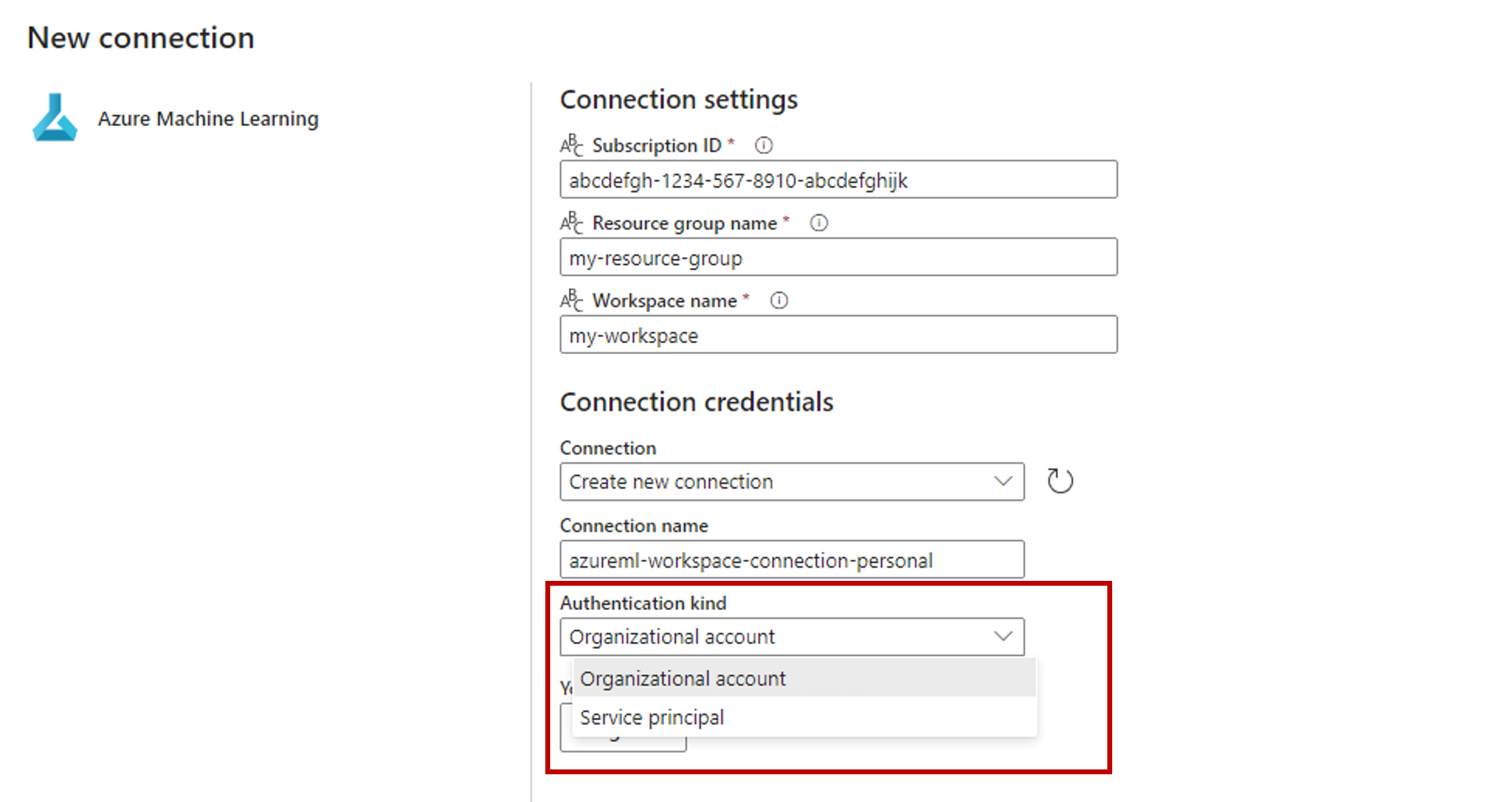
选择“Azure 机器学习连接”旁边的“新建”,以便与包含你的部署的 Azure 机器学习工作区建立新连接。

在创建向导的“连接设置”部分,指定“订阅 ID”、“资源组名称”和“工作区名称”(你的终结点已部署在这些位置)的值。

在“连接凭据”部分,选择“组织帐户”作为连接的“身份验证类型”值。 “组织帐户”使用已连接用户的凭据。 或者,你可以使用“服务主体”。 在生产设置中,我们建议使用服务主体。 无论身份验证类型如何,都请确保与连接关联的标识有权调用你部署的批处理终结点。
保存连接。 选择连接后,Fabric 会自动填充所选工作区中的可用批处理终结点。
对于“批处理终结点”,请选择要调用的批处理终结点。 在此示例中,请选择“heart-classifier-...”。
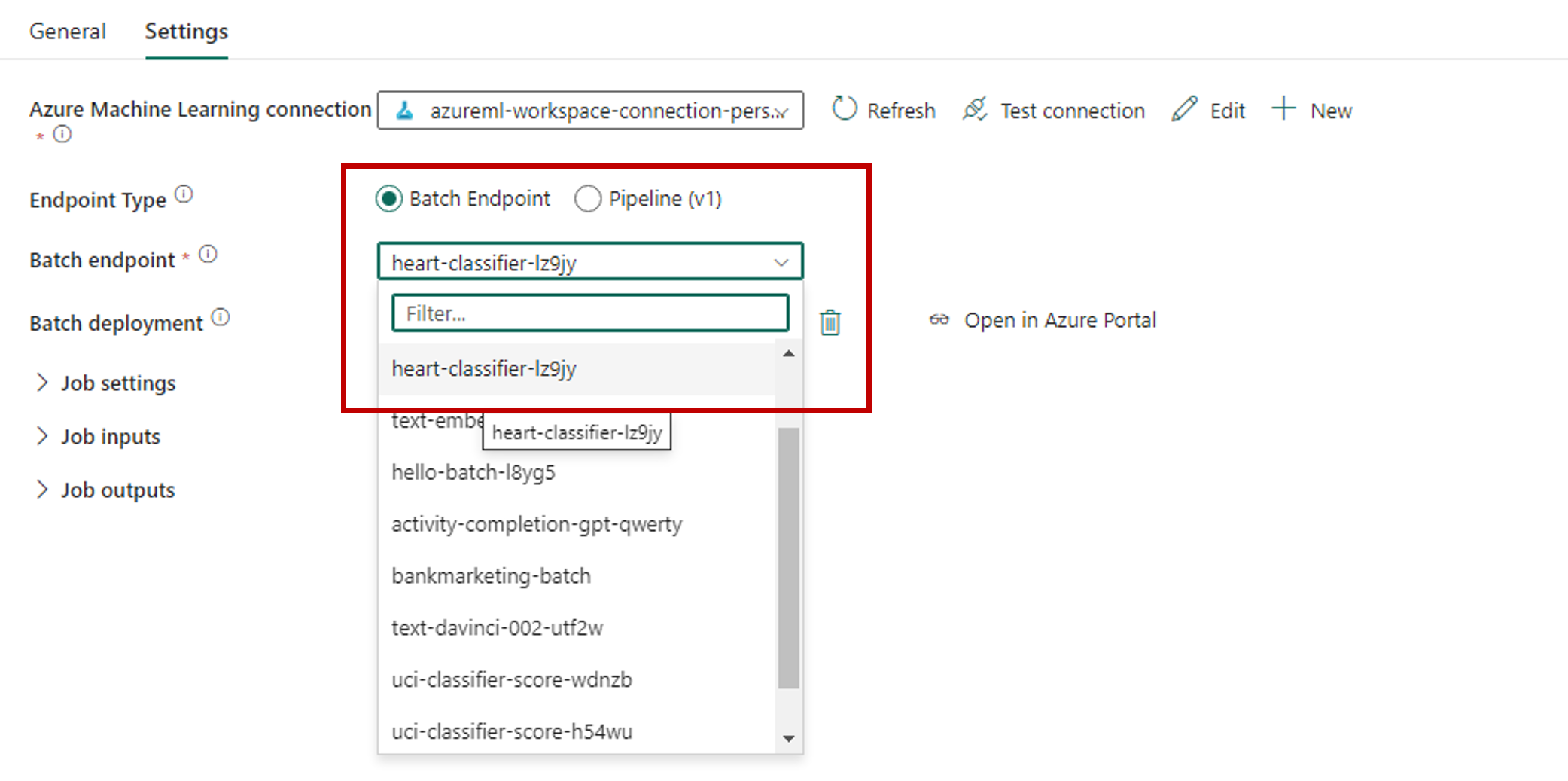
“批处理部署”部分会自动填充终结点下的可用部署。
对于“批处理部署”,请根据需要从列表中选择特定的部署。 如果你不选择部署,Fabric 将调用终结点下的“默认”部署,从而允许批处理终结点创建者决定要调用哪个部署。 在大多数情况下,可以保留此默认行为。







配置批处理终结点的输入和输出
在本部分,你将配置批处理终结点的输入和输出。 批处理终结点的输入提供运行流程所需的数据和参数。 Fabric 中的 Azure 机器学习批处理管道支持模型部署和管道部署。 提供的输入数量和类型取决于部署类型。 在此示例中,使用的模型部署只需一个输入并生成一个输出。
有关批处理终结点输入和输出的详细信息,请参阅了解批处理终结点中的输入和输出。
配置输入部分
如下所述配置“作业输入”部分:
展开“作业输入”部分。
选择“新建”以将新的输入添加到终结点。
将输入命名为
input_data。 由于使用的是模型部署,因此可以使用任意名称。 但是,对于管道部署,需要指明模型所需的输入的确切名称。选择刚刚添加的输入旁边的下拉菜单以打开输入的属性(名称和值字段)。
在“名称”字段中输入
JobInputType,指明你要创建的输入类型。在“值”字段中输入
UriFolder,指明输入是文件夹路径。 此字段支持的其他值包括“UriFile”(文件路径)或“Literal”(任何文本值,例如字符串或整数)。 需要使用部署所需的正确类型。选择属性旁边的加号可为此输入添加另一个属性。
在“名称”字段中输入
Uri,指明数据的路径。在“值”字段中输入
azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled,即数据的查找路径。 在此处,请使用指向存储帐户的路径,该存储帐户已同时链接到 Fabric 中的 OneLake 和 Azure 机器学习。 azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled 是 CSV 文件的路径,其中包含部署到批处理终结点的模型所需的输入数据。 也可以使用存储帐户的直接路径,例如https://<storage-account>.dfs.azure.com。
提示
如果输入的类型为“文本”,请将属性
Uri替换为“Value”。
如果终结点需要更多输入,请对每个终结点重复上述步骤。 在此示例中,模型部署只需要一个输入。
配置输出部分
如下所述配置“作业输出”部分:
展开“作业输出”部分。
选择“新建”,为终结点添加新输出。
将输出命名为
output_data。 由于使用的是模型部署,因此可以使用任意名称。 但是,对于管道部署,需要指明模型生成的输出的确切名称。选择刚刚添加的输出旁边的下拉菜单以打开输出的属性(名称和值字段)。
在“名称”字段中输入
JobOutputType,指明你要创建的输出类型。在“值”字段中输入
UriFile,指明输出是文件路径。 此字段的另一个受支持值是 UriFolder(文件夹路径)。 与作业输入部分不同,不支持将 Literal(任何文本值,例如字符串或整数)用作输出。选择属性旁边的加号可为此输出添加另一个属性。
在“名称”字段中输入
Uri,指明数据的路径。在“值”字段中输入
@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv'),即输出应放置到的路径。 Azure 机器学习批处理终结点仅支持使用数据存储路径作为输出。 由于输出必须唯一以避免冲突,因此你使用了动态表达式@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv')来构造路径。
如果终结点返回更多输出,请对每个终结点重复上述步骤。 在此示例中,模型部署只生成一个输出。
(可选)配置作业设置
还可以通过添加以下属性来配置“作业设置”:
对于模型部署:
| 设置 | 说明 |
|---|---|
MiniBatchSize |
批大小。 |
ComputeInstanceCount |
要从部署中请求的计算实例数。 |
对于管道部署:
| 设置 | 说明 |
|---|---|
ContinueOnStepFailure |
指示管道在发生故障后是否应停止处理节点。 |
DefaultDatastore |
指示要用于输出的默认数据存储。 |
ForceRun |
指示管道是否应强制所有组件运行,即使可以从先前的运行推断输出。 |
配置后,可以测试管道。