你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
如何使用由 Azure 机器学习策划的开源基础模型
本文介绍如何在模型目录中微调、评估和部署基础模型。
可以使用模型卡上的示例推理窗体快速测试任何预先训练的模型,并提供自己的示例输入来测试结果。 此外,每个模型的模型卡包括了模型的简要说明,以及指向基于代码的推理、微调和模型评估的示例的链接。
如何使用自己的测试数据评估基础模型
可以使用评估 UI 窗体或使用基于代码的示例(从模型卡链接)针对测试数据集评估基础模型。
使用工作室进行评估
可以通过在任何基础模型的模型卡上选择“评估”按钮来调用评估模型窗体。
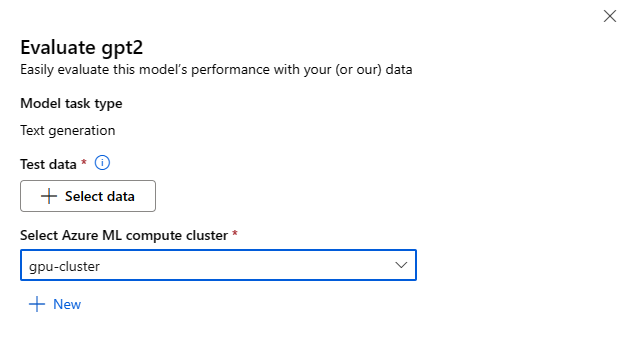
可以针对将使用模型的特定推理任务评估每个模型。
测试数据:
- 传入要用于评估模型的测试数据。 可以选择上传采用 JSONL 格式的本地文件,也可以从工作区中选择现有的已注册数据集。
- 选择数据集后,需要根据任务所需的架构映射输入数据中的列。 例如,映射与文本分类的“sentence”和“label”键对应的列名称

计算:
提供要用于微调模型的 Azure 机器学习计算群集。 评估需要在 GPU 计算上运行。 确保为要使用的计算 SKU 提供足够的计算配额。
在评估窗体中选择“完成”以提交评估作业。 作业完成后,可以查看模型的评估指标。 根据评估指标,可以决定是否要使用自己的训练数据微调模型。 此外,还可以决定是否要注册模型并将其部署到终结点。
使用基于代码的示例进行评估
为了支持用户开始使用模型评估,我们在 azureml-examples git 存储库中的评估示例中发布了示例(包括 Python 笔记本和 CLI 示例)。 每个模型卡还链接到相应任务的评估示例
如何使用自己的训练数据微调基础模型
为了提高工作负载中的模型性能,可能需要使用自己的训练数据微调基础模型。 通过使用工作室中的微调设置或使用从模型卡链接的基于代码的示例,可以轻松微调这些基础模型。
使用工作室进行微调
可以通过在任何基础模型的模型卡上选择“微调”按钮来调用微调设置窗体。
微调设置:
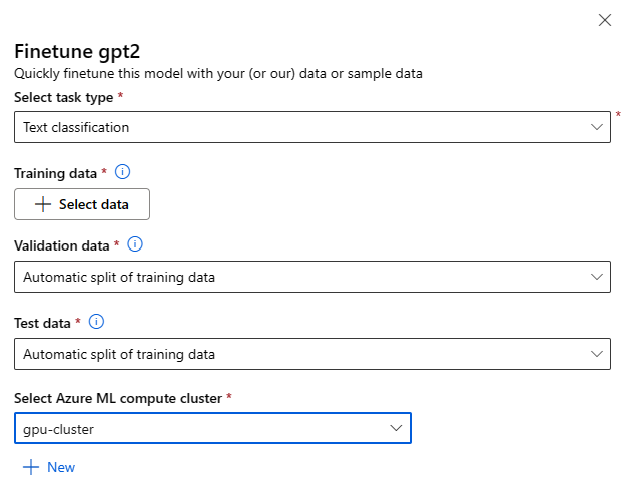
微调任务类型
- 可以针对一组特定任务微调模型目录中每个预先训练的模型(例如:文本分类、令牌分类、问答)。 从下拉列表中选择要使用的任务。
训练数据
传入要用于微调模型的训练数据。 可以选择上传采用 JSONL、CSV 或 TSV 格式的本地文件,也可以从工作区中选择现有的已注册数据集。
选择数据集后,需要根据任务所需的架构映射输入数据中的列。 例如:映射与文本分类的“sentence”和“label”键对应的列名称

- 验证数据:传入要用于验证模型的数据。 选择“自动拆分”会保留训练数据的自动拆分以供验证。 或者,可以提供不同的验证数据集。
- 测试数据:传入要用于评估已微调模型的测试数据。 选择“自动拆分”会保留训练数据的自动拆分以供测试。
- 计算:提供要用于微调模型的 Azure 机器学习计算群集。 微调需要在 GPU 计算上运行。 建议在微调时将计算 SKU 与 A100 / V100 GPU 配合使用。 确保为要使用的计算 SKU 提供足够的计算配额。
- 在微调窗体中选择“完成”以提交微调作业。 作业完成后,可以查看已微调模型的评估指标。 然后,可以通过微调作业来注册已微调的模型输出,并将此模型部署到终结点以进行推理。
使用基于代码的示例进行微调
目前,Azure 机器学习支持以下语言任务的微调模型:
- 文本分类
- 标记分类
- 问答
- 汇总
- 翻译
为了支持用户快速开始微调,我们已面向 azureml-examples git 存储库微调示例中的每个任务发布了示例(包括 Python 笔记本和 CLI 示例)。 每个模型卡还链接到受支持微调任务的微调示例。
将基础模型部署到终结点以进行推理
可将基础模型(包括模型卡中的预训练模型和已注册到工作区的已微调模型)部署到终结点,并随后将其用于推理。 支持部署到实时终结点和批处理终结点。 可以使用“部署 UI”向导或使用从模型卡链接的基于代码的示例来部署这些模型。
使用工作室进行部署
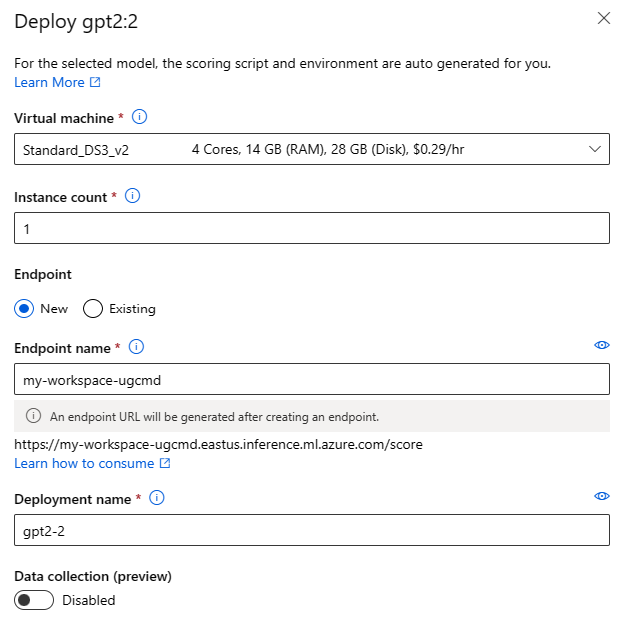
可以调用部署 UI 窗体,方法是在任何基础模型的模型卡上选择“部署”按钮,然后选择实时终结点或 Batch 终结点

部署设置
由于评分脚本和环境自动包含在基础模型中,因此只需指定要使用的虚拟机 SKU、实例数和要用于部署的终结点名称。
共享配额
如果要从模型目录部署 Llama-2、Phi、Nemotron、Mistral、Dolly 或 Deci-DeciLM 模型,但没有足够的配额可用于部署,则可通过 Azure 机器学习在有限的时间内使用共享配额池中的配额。 有关共享配额的详细信息,请参阅Azure 机器学习共享配额。

使用基于代码的示例进行部署
为了支持用户快速开始部署和推理,我们已在 azureml-examples git 存储库的推理示例中发布了示例。 已发布的示例包括 Python 笔记本和 CLI 示例。 每个模型卡还链接到用于实时和批处理推理的推理示例。
导入基础模型
如果要使用模型目录中未包含的开源模型,可以将模型从 Hugging Face 导入到 Azure 机器学习工作区。 Hugging Face 是一个用于自然语言处理 (NLP) 的开放源代码库,可为常用 NLP 任务提供预先训练的模型。 目前,模型导入支持为以下任务导入模型,只要模型满足模型导入笔记本中列出的要求:
- 完形填空
- 标记分类
- 问答
- summarization (汇总)
- 文本生成
- 文本分类
- 转换
- 图像分类
- 文本转图像
注意
Hugging Face 中的模型受 Hugging Face 模型详细信息页上提供的第三方许可条款约束。 你有责任遵守模型的许可条款。
可以选择模型目录右上角的“导入”按钮来使用模型导入笔记本。
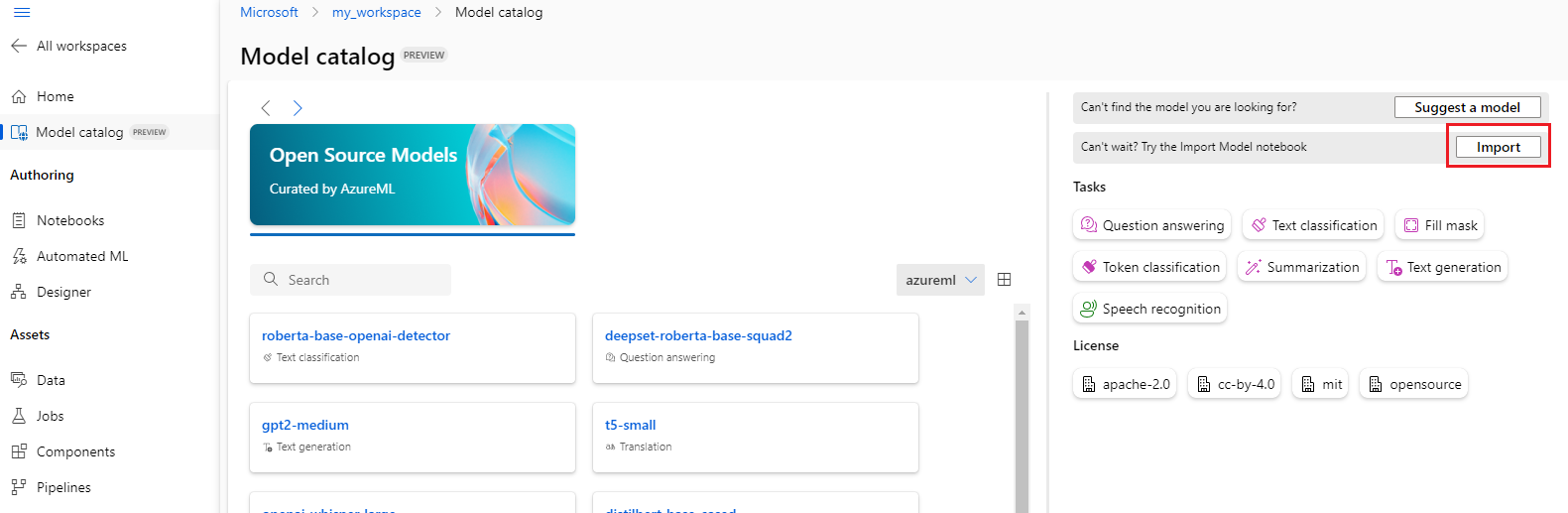
模型导入笔记本也包含在此处的 azureml-examples git 存储库中。
要导入模型,需要传入要从 Hugging Face 导入的模型的 MODEL_ID。 浏览 Hugging Face 中心上的模型,并标识要导入的模型。 确保模型的任务类型属于受支持的任务类型。 复制模型 ID(该 ID 在页面的 URI 中提供),也可以使用模型名称旁边的复制图标来复制该 ID。 将其分配给模型导入笔记本中的变量“MODEL_ID”。 例如:
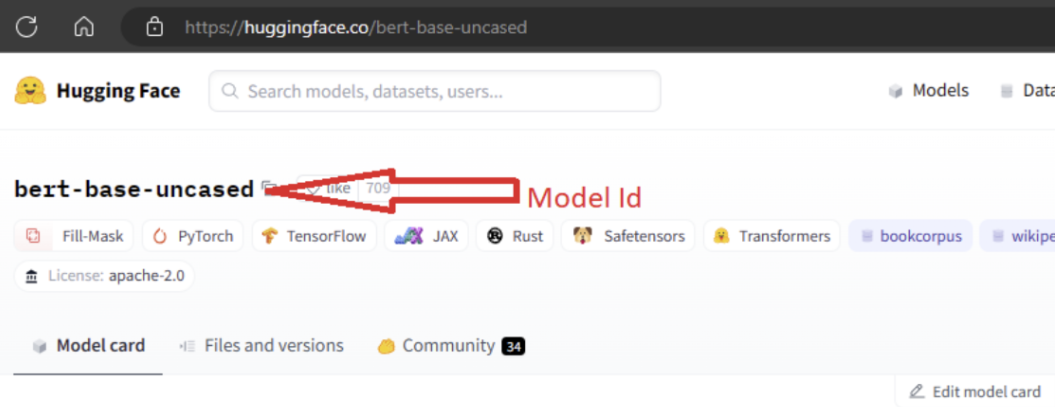
需要为要运行的模型导入提供计算。 运行模型导入会导致从 Hugging Face 导入指定的模型并将其注册到 Azure 机器学习工作区。 然后,可以微调此模型或将其部署到终结点以进行推理。
了解详细信息
- 探索 Azure 机器学习工作室中的模型目录。 需要 Azure 机器学习工作区来探索目录。
- 浏览模型目录和集合