你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 MLflow 和 Azure 机器学习跟踪 Azure Synapse Analytics ML 试验
本文介绍在 Azure Synapse Analytics 工作区中工作时如何使 MLflow 连接到 Azure 机器学习。 可以利用此配置来执行跟踪、模型管理和模型部署。
MLflow 是一个开放源代码库,用于管理机器学习试验的生命周期。 MLflow 跟踪是 MLflow 的一个组件,用于记录和跟踪训练运行指标和模型项目。 详细了解 MLflow。
如果你要使用某个 MLflow 项目通过 Azure 机器学习进行训练,请参阅使用 MLflow 项目和 Azure 机器学习训练 ML 模型(预览版)。
先决条件
安装库
在 Azure Synapse Analytics 中的专用群集上安装库:
使用试验所需的包创建
requirements.txt文件,但请确保该文件还包括以下包:requirements.txt
mlflow azureml-mlflow azure-ai-ml导航到 Azure Analytics 工作区门户。
导航到“管理”选项卡并选择“Apache Spark 池”。
单击群集名称旁边的三个点,然后选择“包”。
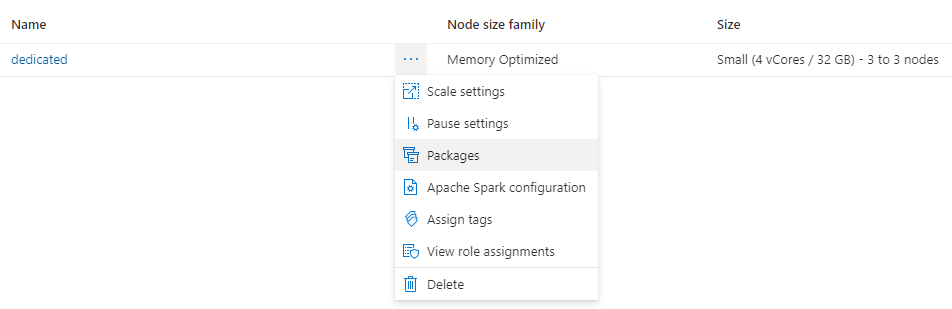
在“要求文件”部分,单击“上传”。
上传
requirements.txt文件。等待群集重启。
使用 MLflow 对试验进行跟踪
Azure Synapse Analytics 可配置为使用连接到 Azure 机器学习工作区的 MLflow 来跟踪试验。 Azure 机器学习提供了一个集中式存储库,用于管理试验、模型和部署的整个生命周期。 它还具有使用 Azure 机器学习部署选项启用更轻松的部署路径的优势。
将笔记本配置为使用连接到 Azure 机器学习的 MLflow
若要将 Azure 机器学习用作试验的集中式存储库,可以利用 MLflow。 在正在使用的每个笔记本上,需要配置跟踪 URI 以指向将要使用的工作区。 下面的示例演示了实现方式:
配置跟踪 URI
获取工作区的跟踪 URI:
登录并配置工作区:
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>可以使用
az ml workspace命令获取跟踪 URI:az ml workspace show --query mlflow_tracking_uri
配置跟踪 URI:
然后,
set_tracking_uri()方法将 MLflow 跟踪 URI 指向该 URI。import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)提示
使用共享环境(如 Azure Databricks 群集、Azure Synapse Analytics 群集或类似环境)时,可以在群集级别设置环境变量
MLFLOW_TRACKING_URI以自动配置 MLflow 跟踪 URI,以指向群集中运行的基于所有会话的 Azure 机器学习,而不是指向群集中运行的基于每会话的 Azure 机器学习。

配置身份验证
配置跟踪后,还需要配置对关联工作区进行身份验证的方式。 默认情况下,适用于 MLflow 的 Azure 机器学习插件将通过打开默认浏览器提示输入凭据来执行交互式身份验证。 有关在 Azure 机器学习工作区中为 MLflow 配置身份验证的其他方法,请参阅为 Azure 机器学习配置 MLflow:配置身份验证。
如果交互式作业有用户连接到会话,你可以依赖交互式身份验证,因此无需进一步操作。
警告
在系统提示输入凭据时,交互式浏览器身份验证将阻止代码执行。 此方法不适用于无人参与的环境(如训练作业)中的身份验证。 建议配置不同的身份验证模式。
对于需要无人参与执行的方案,则必须配置服务主体,以便与 Azure 机器学习通信。
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
提示
使用共享环境时,建议在计算中配置这些环境变量。 最佳做法是在 Azure 密钥保管库实例中将这些环境变量作为机密进行管理。
例如,在 Azure Databricks 中,可以在群集配置的环境变量中使用机密,如下所示:AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}。 有关在 Azure Databricks 中实现此方法的详细信息,请参阅引用环境变量中的机密或参考适用于你平台的文档。
Azure 机器学习中的试验名称
默认情况下,Azure 机器学习跟踪在名为 Default 的默认试验中运行。 通常最好是设置要处理的试验。 使用以下语法来设置试验的名称:
mlflow.set_experiment(experiment_name="experiment-name")
跟踪参数、指标和项目
然后,可以像之前一样在 Azure Synapse Analytics 中使用 MLflow。 有关详细信息,请参阅记录并查看指标和日志文件。
使用 MLflow 在注册表中注册模型
可以在 Azure 机器学习工作区中注册模型,该工作区提供集中式存储库来管理模型的生命周期。 以下示例记录使用 Spark MLLib 训练的模型,并在注册表中注册该模型。
mlflow.spark.log_model(model,
artifact_path = "model",
registered_model_name = "model_name")
如果还没有模型注册为该名称,该方法将注册一个新模型,创建版本 1,并返回 ModelVersion MLflow 对象。
如果已有模型注册为该名称,该方法将创建一个新的模型版本并返回版本对象。
可以使用 MLflow 管理在 Azure 机器学习中注册的模型。 有关详细信息,请参阅使用 MLflow 在 Azure 机器学习中管理模型注册表。
部署和使用在 Azure 机器学习中注册的模型
使用 MLflow 在 Azure 机器学习服务中注册的模型可以用作:
Azure 机器学习终结点(实时和批处理):此部署允许在 Azure 容器实例 (ACI)、Azure Kubernetes (AKS) 或我们的托管终结点中的实时和批量推理中利用 Azure 机器学习部署功能。
MLFlow 模型对象或 Pandas UDF,可在流式处理或批处理管道中的 Azure Synapse Analytics 笔记本中使用。
将模型部署到 Azure 机器学习终结点
可以利用 azureml-mlflow 插件将模型部署到 Azure 机器学习工作区。 有关如何将模型部署到不同目标的完整详细信息,请查看如何部署 MLflow 模型页面。
重要
模型需要在 Azure 机器学习注册表中注册才能进行部署。 Azure 机器学习中不支持部署未注册的模型。
部署模型以使用 UDF 进行批量评分
可以选择 Azure Synapse Analytics 群集进行批量评分。 系统将加载 MLFlow 模型,并将其用作 Spark Pandas UDF 对新数据进行评分。
from pyspark.sql.types import ArrayType, FloatType
model_uri = "runs:/"+last_run_id+ {model_path}
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
清理资源
如果希望保留 Azure Synapse Analytics 工作区,但不再需要 Azure 机器学习工作区,则可以删除 Azure 机器学习工作区。 如果不打算使用工作区中记录的指标和项目,目前尚未提供单独删除它们的功能。 可以改为删除包含存储帐户和工作区的资源组,这样就不会产生任何费用:
在 Azure 门户中,选择最左侧的“资源组”。
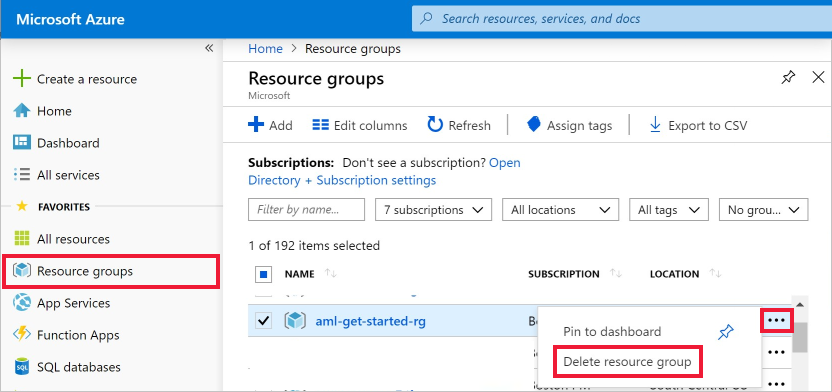
从列表中选择已创建的资源组。
选择“删除资源组”。
输入资源组名称。 然后选择“删除”。