你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure 流量管理器中的可靠性
本文包含 Azure 流量管理器的跨区域灾难恢复和业务连续性支持。
跨区域灾难恢复和业务连续性
灾难恢复 (DR) 是指从会导致故障时间和数据丢失的高影响事件(例如自然灾害或部署失败)中恢复。 不管灾难的原因是什么,最好的补救措施就是一个定义全面且经过测试的 DR 计划,以及一个主动支持 DR 的应用程序设计。 在开始考虑创建灾难恢复计划之前,请参阅设计灾难恢复策略的建议。
在 DR 方面,Microsoft 使用责任共担模型。 在共担责任模型中,Microsoft 会确保基线基础结构和平台服务可用。 同时,许多 Azure 服务不会自动复制数据,也不会从失败区域回退以交叉复制到另一个启用的区域。 对于这些服务,你负责设置适用于工作负载的灾难恢复计划。 大多数在 Azure 平台即服务 (PaaS) 产品/服务上运行的服务都提供支持 DR 的功能和指导,你可以使用特定于服务的功能来支持快速恢复,从而帮助制定 DR 计划。
Azure 流量管理器是一个基于 DNS 的流量负载均衡器,可用于将流量分布到全球 Azure 区域中面向公众的应用程序。 流量管理器还提供具有高可用性和快速响应能力的公共终结点。
流量管理器使用 DNS 根据流量路由方法将客户端请求定向到适当的服务终结点。 流量管理器还为每个终结点提供运行状况监视功能。 终结点可以是托管在 Azure 内部或外部的任何面向 Internet 的服务。 流量管理器提供多种流量路由方法和终结点监视选项来满足不同的应用程序需求和自动故障转移模型。 流量管理器能够灵活应对故障,包括整个 Azure 区域的故障。
多区域地理位置中的灾难恢复
DNS 是转移网络流量的最有效机制之一。 DNS 非常高效,因为 DNS 通常是全局的且位于数据中心外部。 DNS 还不受任何区域或可用区 (AZ) 级别故障的影响。
创建灾难恢复体系结构时,有以下两个技术现状:
使用部署机制在主环境和备用环境之间复制实例、数据和配置。 这种类型的灾难恢复可通过 Microsoft Azure 合作伙伴设备/服务(例如 Veritas 或 NetApp)使用 Azure Site Recovery 在本机完成(请参阅 Azure Site Recovery 文档)。
开发一种将网络/Web 流量从主站点转移到备用站点的解决方案。 这种灾难恢复可通过 Azure DNS、Azure 流量管理器 (DNS) 或第三方全局负载均衡器实现。
本文重点介绍 Azure 流量管理器灾难恢复规划。
服务中断检测、通知和管理
灾难期间,将对主终结点进行探测,并将状态更改为“已降级” ,而灾难恢复站点的状态一直为“联机” 。 默认情况下,流量管理器将所有流量发送到主终结点(优先级最高)。 如果主终结点的状态显示为“已降级”,流量管理器会将流量路由到第二个终结点(只要它保持正常运行)。 可以在流量管理器中配置更多终结点,以用作额外的故障转移终结点,或用作负载均衡器在终结点之间共同均衡负载。
设置灾难恢复和中断检测
若有复杂的体系结构和多组能执行相同功能的资源,可以将 Azure 流量管理器(基于 DNS)配置为检查资源的运行状况,并将来自不正常运行的资源的流量路由到正常运行的资源。
在下面的示例中,主要区域和次要区域均采用完全部署。 这种部署包括云服务和同步数据库。
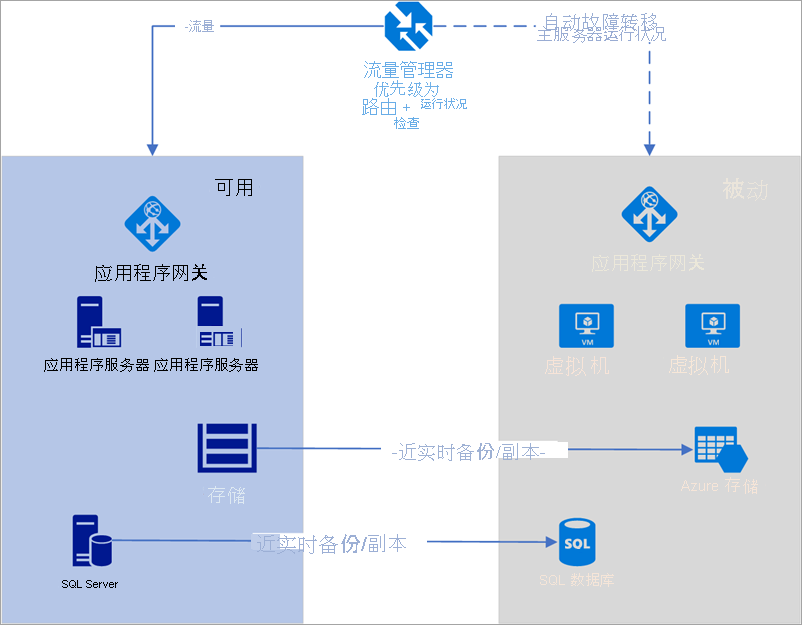
图:使用 Azure 流量管理器执行自动故障转移
但是,只有主要区域在主动处理来自用户的网络请求。 只有当主要区域出现服务中断时,次要区域才会激活。 在这种情况下,会将所有新网络请求路由到次要区域。 由于数据库备份几乎是瞬间完成,因此两个负载均衡器都有可对其检查运行状况的 IP,并且实例始终正常运行。借助此拓扑,无需任何手动干预,即可执行低 RTO 的故障转移。 在主要区域发生故障后,次要故障转移区域必须可供立即投入使用。
此方案非常适合使用 Azure 流量管理器完成,其中内置了可执行各种运行状况检查的探针,包括 http/https 和 TCP。 Azure 流量管理器还包含规则引擎,可以配置为在故障发生时执行故障转移,如下所述。 假设使用流量管理器执行以下解决方案:
- 客户有静态 IP 为 100.168.124.44 的区域 #1 终结点 prod.contoso.com,以及静态 IP 为 100.168.124.43 的区域 #2 终结点 dr.contoso.com。
- 其中每个环境都通过面向公众的属性(如负载均衡器)前置。 负载平衡器可以配置为,拥有基于 DNS 的终结点或完全限定的域名 (FQDN),如上所述。
- 区域 2 中的所有实例与区域 1 是近实时复制关系。 此外,计算机映像是最新的,所有软件/配置数据都进行了修补并与区域 1 保持一致。
- 自动缩放已提前预先配置。
配置 Azure 流量管理器自动故障转移:
新建 Azure 流量管理器配置文件 新建 Azure 流量管理器配置文件,命名为“contoso123”,再选择“优先级”作为“路由方法”。 若有要与之关联的现有资源组,可以选择现有资源组,否则新建资源组。
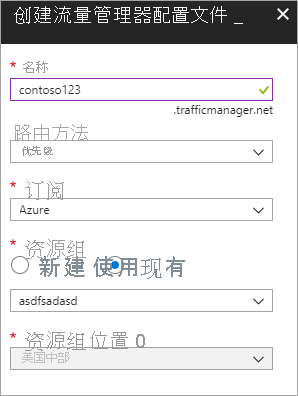
图 - 创建流量管理器配置文件
在流量管理器配置文件中创建终结点
在这一步,创建指向生产站点和灾难恢复站点的终结点。 此时,选择“类型” 作为外部终结点,但如果资源托管在 Azure 中,也可以选择“Azure 终结点” 。 如果选择“Azure 终结点”,请选择 Azure 分配的“应用服务”或“公共 IP”作为“目标资源”。 优先级设置为“1”,因为它是区域 1 的主服务。 同样,也在流量管理器中创建灾难恢复终结点。
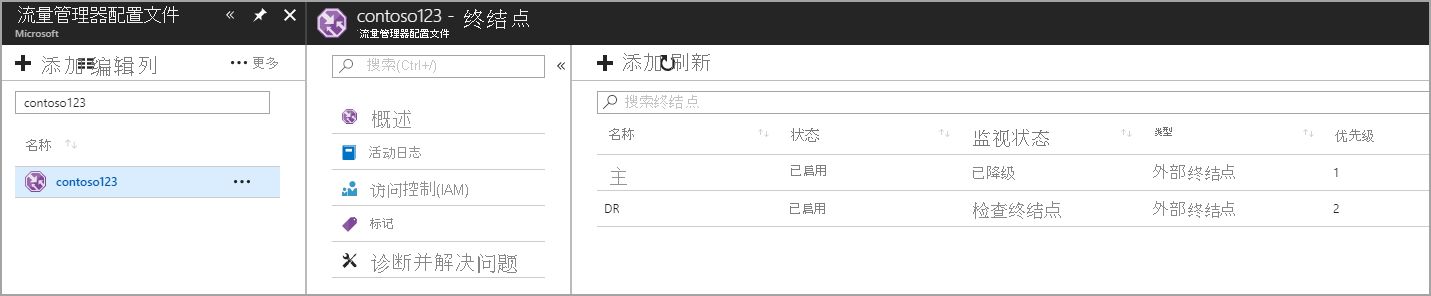
图:创建灾难恢复终结点
设置运行状况检查和故障转移配置
在这一步,将 DNS TTL 设置为 10 秒,大多数面向 Internet 的递归解析程序都采用此设置。 此配置意味着,没有 DNS 解析程序会缓存信息超过 10 秒。
对于终结点监视设置,“路径”当前设置为“/”或根路径,但也可以将终结点设置自定义为评估路径(例如,prod.contoso.com/index)。
下面的示例展示了使用 https 作为探测协议。 不过,也可以选用 http 或 tcp 。 协议选择取决于最终应用程序。 “探测时间间隔”设置为 10 秒(可启用快速探测),重试次数设置为 3 次。 因此,如果三个连续时间间隔的记录结果都为故障,流量管理器就会通过故障转移复原到第二个终结点。
自动故障转移总时间的计算公式如下:
Time for failover = TTL + Retry * Probing interval在这种情况下,值为 10 + 3 * 10 = 40 秒(最大值)。
如果重试次数设置为 1 次,且 TTL 设置为 10 秒,那么故障转移时间为 10 + 1 * 10 = 20 秒。
请将重试次数设置为大于 1 的值,这样就不可能因误报或任何网络小跳点而执行故障转移。
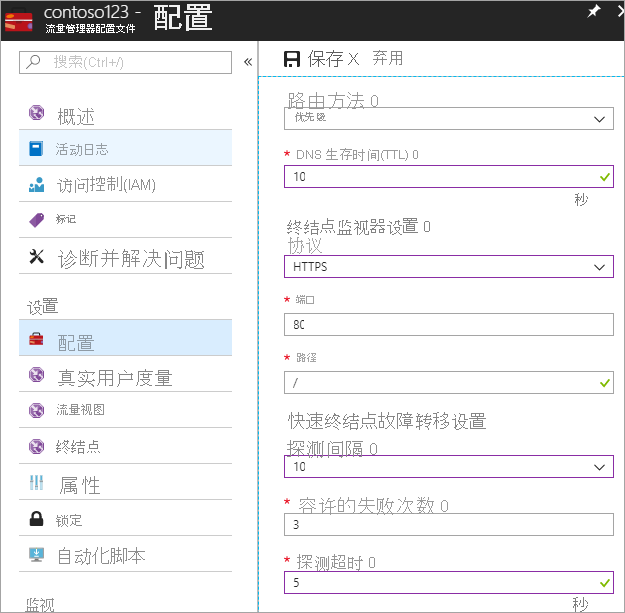
图:设置运行状况检查和故障转移配置
后续步骤
详细了解 Azure 流量管理器。
详细了解 Azure DNS。