你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
以 Parquet 格式从事件中心捕获数据
本文介绍了如何使用无代码编辑器在 Azure Data Lake Storage Gen2 帐户中以 Parquet 格式自动捕获事件中心中的流式数据。
先决条件
具有一个事件中心的 Azure 事件中心命名空间,以及具有一个用于存储捕获数据的容器的 Azure Data Lake Storage Gen2 帐户。 这些资源必须可公开访问,并且不能位于防火墙后面或在 Azure 虚拟网络中受到保护。
如果没有事件中心,请按照快速入门:创建事件中心中的说明创建一个事件中心。
如果没有 Data Lake Storage Gen2 帐户,请按照创建存储帐户中的说明创建一个帐户
事件中心中的数据必须以 JSON、CSV 或 Avro 格式进行序列化。 出于测试目的,请在左侧菜单中选择“生成数据(预览)”,选择数据集中的“库存数据”,然后选择“发送”。


配置用于捕获数据的作业
使用以下步骤配置用于捕获 Azure Data Lake Storage Gen2 中的数据的流分析作业。
在 Azure 门户中,导航到你的事件中心。
在左侧菜单中,选择“功能”下的“处理数据”。 然后,在“以 Parquet 格式将数据捕获到 ADLS Gen2”卡片上选择“开始”。
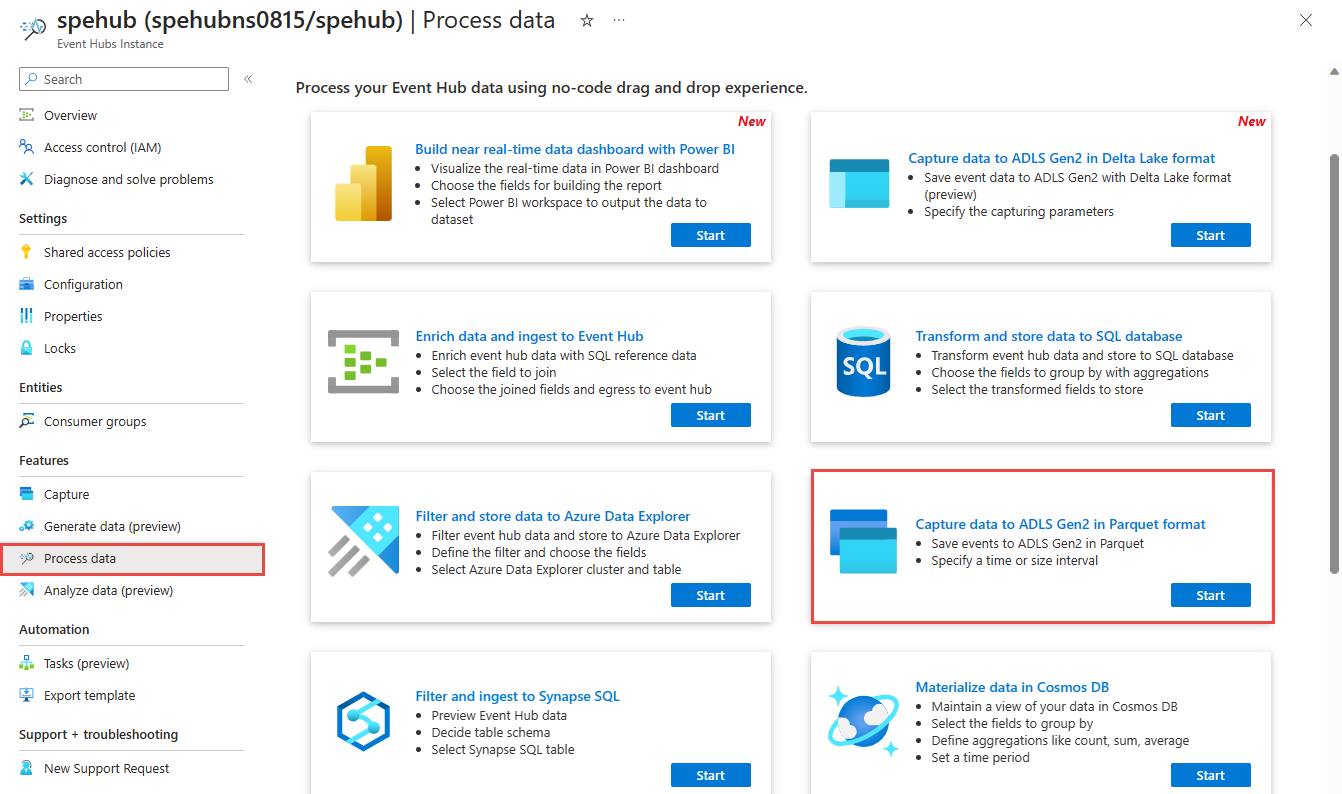
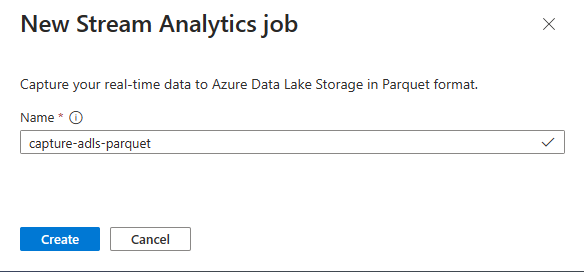
输入流分析作业的名称,然后选择“创建”。
指定事件中心中数据的“序列化”类型和作业将用于连接到事件中心的“身份验证方法”。 然后选择“连接” 。

成功建立连接后,你将看到:
输入数据中存在的字段。 可以选择“添加字段”,也可以选择字段旁边的三个点符号来选择性地删除、重命名或更改其名称。
图表视图下的“数据预览”表中的传入数据的实时示例。 它会定期刷新。 可以选择“暂停流式预览”以查看示例输入的静态视图。
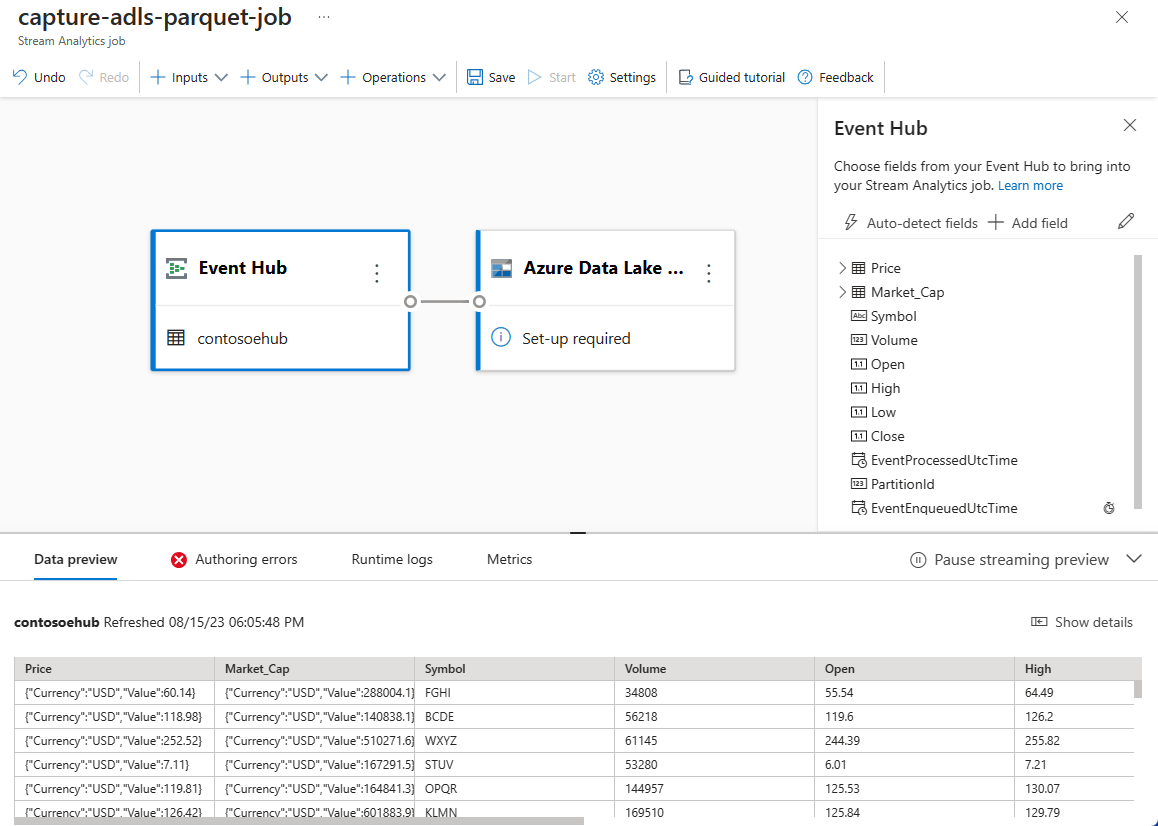
选择“Azure Data Lake Storage Gen2”磁贴以编辑配置。
在“Azure Data Lake Storage Gen2 ”配置页中,按以下步骤执行操作:
从下拉菜单中选择订阅、存储帐户名称和容器。
选择订阅后,应会自动填充身份验证方法和存储帐户密钥。
为“序列化”格式选择“Parquet”。
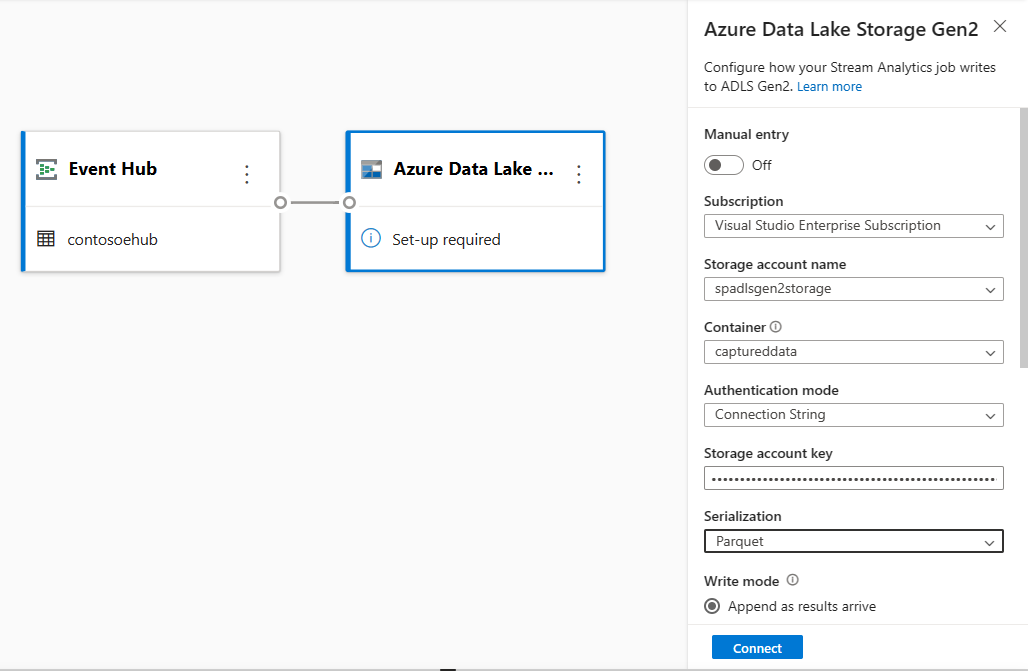
对于流式处理 blob,目录路径模式应该是动态值。 日期必须是 Blob 文件路径的一部分 - 引用为
{date}。 若要了解自定义路径模式,请参阅 Azure 流分析自定义 Blob 输出分区。
选择“连接”
建立连接后,你将看到输出数据中存在的字段。
选择命令栏上的“保存”以保存你的配置。
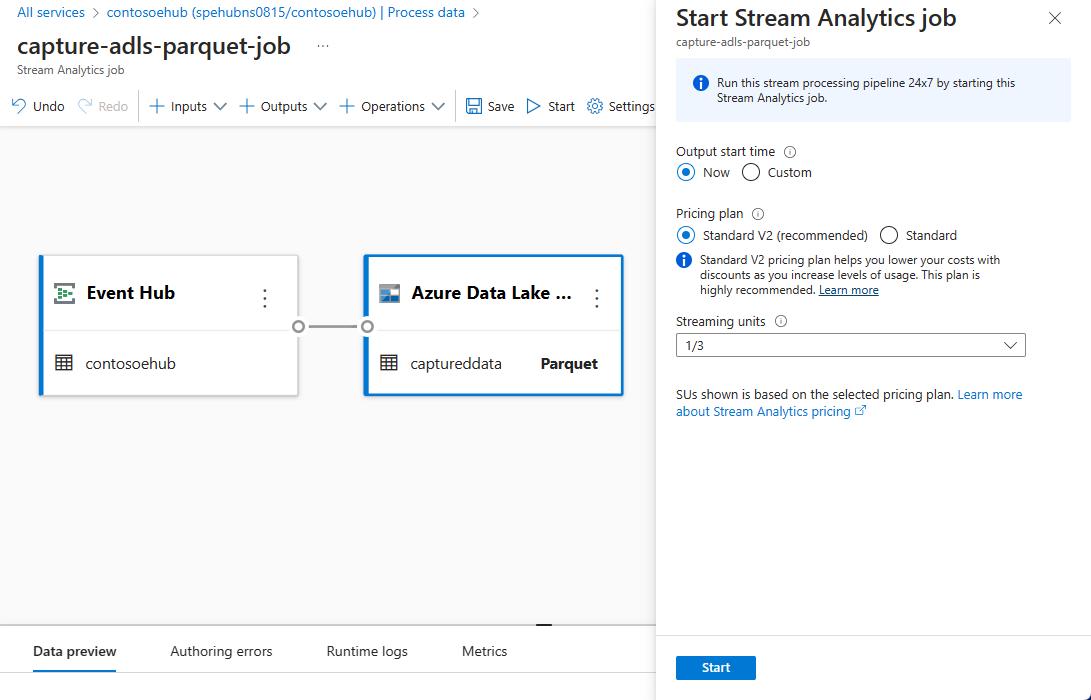
选择命令栏上的“开始”启动流式处理流,以捕获数据。 然后在“启动流分析作业”窗口中:
选择输出开始时间。
选择定价计划。
选择作业运行时使用的流单元 (SU) 数量。 SU 表示分配用于执行流分析作业的计算资源。 有关详细信息,请参阅 Azure 流分析中的流单元。
你应该会在事件中心“处理数据”页面的“流分析作业”选项卡中看到流分析作业。








验证输出
在事件中心的“事件中心实例”页面上,选择“生成数据”,选择数据集中的“库存数据”,然后选择“发送”将一些示例数据发送到事件中心。
验证 Parquet 文件是否在 Azure Data Lake Storage 容器中生成。

选择左侧菜单上的“处理数据”。 切换到“流分析作业”选项卡。选择“打开指标”以对其进行监视。

下面是显示输入和输出事件的指标的示例屏幕截图。




使用事件中心的异地复制功能时的注意事项
Azure 事件中心最近在公共预览版中推出了异地复制功能。 此功能与 Azure 事件中心的异地灾难恢复功能不同。
当故障转移类型为“强制”且复制一致性为“异步”时,流分析作业无法保证只将数据输出到 Azure 事件中心一次。
Azure 流分析作为使用事件中心作为输出的生产者,可能会在故障转移期间以及当主服务器和辅助服务器之间的复制延迟达到配置的最大延迟时在事件中心进行限制期间观察到作业上的水印延迟。
Azure 流分析作为使用事件中心作为输入的使用者,可能会在故障转移期间观察到作业上的水印延迟,并且可能会在故障转移完成后跳过数据或找到重复的数据。
考虑到这些注意事项,我们建议你在事件中心故障转移完成后立即在适当的开始时间重启流分析作业。 此外,由于事件中心异地复制功能为公共预览版,因此我们目前不建议将此模式用于生产性流分析作业。 在事件中心异地复制功能正式发布并可用于流分析生产作业之前,当前的流分析行为会得到改进。
后续步骤
现在你知道如何使用流分析无代码编辑器来创建以 Parquet 格式将事件中心数据捕获到 Azure Data Lake Storage Gen2 的作业。 接下来,可以详细了解 Azure 流分析以及如何监视已创建的作业。