你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
将 Azure 流分析与 Azure 机器学习集成
可以在 Azure 流分析作业中将机器学习模型实现为用户定义的函数 (UDF),以便基于流输入数据执行实时评分和预测。 Azure 机器学习可让你使用任何常用的开放源代码工具(例如 TensorFlow、scikit-learn 或 PyTorch)来准备、训练和部署模型。
先决条件
在将机器学习模型作为函数添加到流分析作业之前,请完成以下步骤:
使用 Azure 机器学习将模型部署为 Web 服务。
机器学习终结点必须具有关联的 swagger,这有助于流分析了解输入和输出的架构。 可以此示例 swagger 定义为参考来确保已正确设置。
确保 Web 服务接受并返回 JSON 序列化的数据。
在 Azure Kubernetes 服务中部署模型,以进行大规模生产部署。 如果 Web 服务无法处理来自作业的请求数,流分析作业的性能将会下降,从而影响延迟。 仅当你使用 Azure 门户时,Azure 容器实例中部署的模型才受支持。
将机器学习模型添加到作业
可直接从 Azure 门户或 Visual Studio Code 将 Azure 机器学习函数添加到流分析作业。
Azure 门户
在 Azure 门户中导航到你的流分析作业,在“作业拓扑”下选择“函数”。 然后从“+添加”下拉菜单中,选择“Azure 机器学习服务” 。
在“Azure 机器学习服务函数”窗体中填写以下属性值:
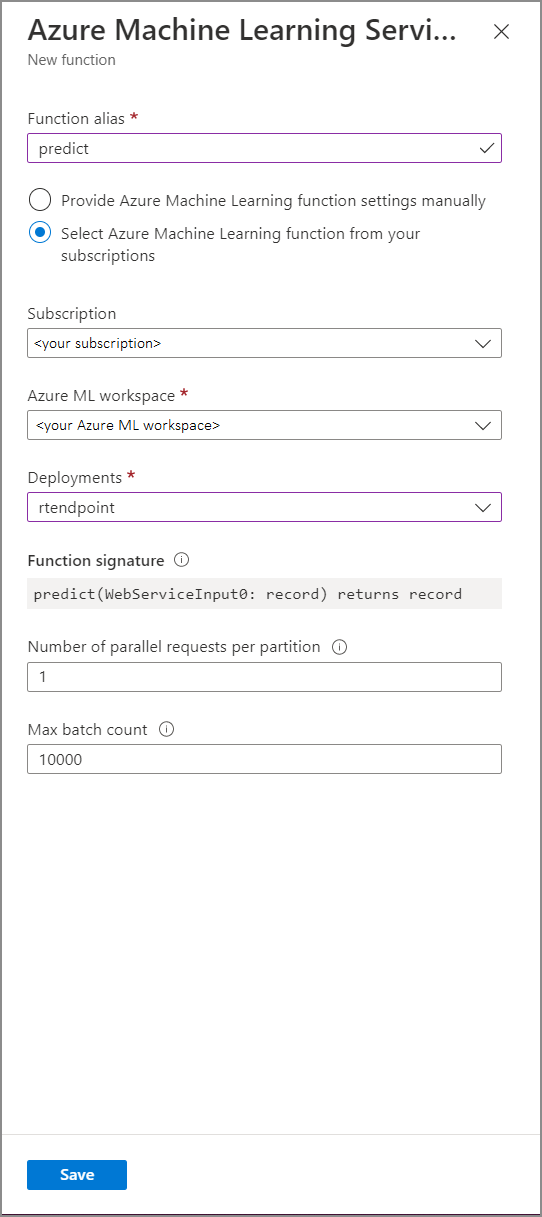
下表描述了流分析中的 Azure 机器学习服务函数的每个属性。
| 属性 | 说明 |
|---|---|
| 函数别名 | 输入一个名称以在查询中调用函数。 |
| 订阅 | Azure 订阅。 |
| Azure 机器学习工作区 | 用于将模型部署为 Web 服务的 Azure 机器学习工作区。 |
| 终结点 | 托管模型的 Web 服务。 |
| 函数签名 | 从 API 的架构规范推理出的 Web 服务签名。 如果签名无法加载,请检查是否已在评分脚本中提供了用于自动生成架构的示例输入和输出。 |
| 每个分区的并行请求数 | 这是一项高级配置,用于优化大规模吞吐量。 此数字表示从作业的每个分区发送到 Web 服务的并发请求数。 具有 6 个或更少流单元 (SU) 的作业有一个分区。 具有 12 个 SU 的作业有两个分区,具有 18 个 SU 的作业有三个分区,依此类推。 例如,如果你的作业有两个分区,而你将此参数设置为 4,那么将会有 8 个并发请求从该作业发送到 Web 服务。 |
| 最大批数 | 这是一项高级配置,用于优化大规模吞吐量。 此数字表示在发送到 Web 服务的单个请求中要一起进行批处理的最大事件数。 |
从查询调用机器学习终结点
当流分析查询调用某个 Azure 机器学习 UDF 时,作业将创建一个要发送到 Web 服务的 JSON 序列化请求。 该请求基于流分析从终结点的 swagger 中推断出的特定于模型的架构。
警告
使用 Azure 门户查询编辑器进行测试时,不会调用机器学习终结点,因为作业未运行。 若要测试来自门户的终结点调用,需要运行流分析作业。
以下流分析查询示例演示如何调用 Azure 机器学习 UDF:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
如果发送到 ML UDF 的输入数据与预期的架构不一致,终结点将返回错误代码为 400 的响应,这将导致流分析作业进入失败状态。 建议为作业启用资源日志,这样就可以轻松地调试和解决此类问题。 因此,强烈建议执行以下操作:
- 验证 ML UDF 的输入是否不为 null
- 验证作为 ML UDF 输入的每个字段的类型,确保它与终结点所需的类型匹配
注意
即使通过条件表达式(即 CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END)调用,ML UDF 也针对给定查询步骤的每一行进行计算。 如果需要,请使用 WITH 子句创建发散路径,从而仅在需要时调用 ML UDF,然后再使用 UNION 将路径合并到一起。
向 UDF 传递多个输入参数
机器学习模型的最常见输入示例是 numpy 数组和数据帧。 可以使用 JavaScript UDF 创建数组,并使用 WITH 子句创建 JSON 序列化的数据帧。
创建输入数组
可以创建接受 N 个输入的 JavaScript UDF,并创建可用作 Azure 机器学习 UDF 输入的数组。
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
将 JavaScript UDF 添加到作业后,可以使用以下查询调用 Azure 机器学习 UDF:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
以下 JSON 是一个示例请求:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
创建 Pandas 或 PySpark 数据帧
可以使用 WITH 子句来创建可作为输入传递给 Azure 机器学习 UDF 的 JSON 序列化数据帧,如下所示。
以下查询通过选择所需字段创建一个数据帧,并使用该数据帧作为 Azure 机器学习 UDF 的输入。
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
以下 JSON 是来自上述查询的示例请求:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
优化 Azure 机器学习 UDF 的性能
将模型部署到 Azure Kubernetes 服务时,可以分析模型以确定资源利用率。 还可以为部署启用 App Insights,以了解请求速率、响应时间和失败率。
如果你的方案使用较高的事件吞吐量,那么你可能需要更改流分析中的以下参数,以实现最佳性能和较低的端到端延迟:
- 最大批计数。
- 每个分区的并行请求数。
确定适当的批大小
部署 Web 服务后,发送具有不同批大小的示例请求。批大小从 50 开始,以 100 为增量递增。 例如 200、500、1000、2000,等等。 你将发现,在达到特定的批大小后,响应延迟会增大。 该特定大小(超过该值后,响应延迟会增大)应是作业的最大批计数。
确定每个分区的并行请求数
经过最佳缩放后,流分析作业应该能够将多个并行请求发送到 Web 服务,并在几毫秒内收到响应。 Web 服务的响应延迟可能会直接影响流分析作业的延迟和性能。 如果从作业调用 Web 服务花费了很长时间,那么你可能会发现水印延迟增大,还可能会发现积压的输入事件数量增加。
通过确保已为 Azure Kubernetes 服务 (AKS) 群集预配适当数量的节点和副本,可实现低延迟。 Web 服务高度可用并返回成功响应至关重要。 如果作业收到可重试的错误,如“服务不可用”响应 (503),它会以指数退避方法自动重试。 如果作业收到其中一个错误作为来自终结点的响应,它将进入失败状态。
- 错误的请求 (400)
- 冲突 (409)
- 找不到 (404)
- 未授权 (401)
限制
如果你使用 Azure ML 托管终结点服务,则流分析目前只能访问启用了公用网络访问的终结点。 在页面上详细了解 Azure ML 专用终结点。