你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Tip
Microsoft Fabric Data Warehouse是数据湖基础上的企业规模关系仓库,具有未来就绪的体系结构、内置 AI 和新功能。 如果不熟悉数据仓库,请从Fabric Data Warehouse开始。 现有的指定 SQL 池工作负荷可以升级到 Fabric,以跨数据科学、实时分析和报告访问新功能。
在本文中,你将了解如何使用无服务器 Synapse SQL 池编写查询以读取 Delta Lake 文件。 Delta Lake 是开源存储层,可将 ACID(原子性、一致性、隔离性和持续性)事务引入 Apache Spark 和大数据工作负载。 你可以从如何查询 Delta Lake 表视频中了解详细信息。
重要
无服务器 SQL 池可以查询 Delta Lake 版本 1.0。 无服务器环境不支持自 Delta Lake 1.2 版本以来引入的更改,如重命名列。 如果使用的是更高版本的 Delta(包含删除矢量、v2 检查点等),应考虑使用其他查询引擎,例如 适用于 Lakehouses 的 Microsoft Fabric SQL 终结点。
通过 Synapse 工作区中的无服务器 SQL 池,可读取以 Delta Lake 格式存储的数据,并将其提供给报告工具。 无服务器 SQL 池可读取使用 Apache Spark、Azure Databricks 或其他任何 Delta Lake 格式的创建器创建的 Delta Lake 文件。
通过 Azure Synapse 中的 Apache Spark 池,数据工程师可使用 Scala、PySpark 和 .NET 修改 Delta Lake 文件。 无服务器 SQL 池可帮助数据分析师针对数据工程师创建的 Delta Lake 文件创建报表。
重要
使用无服务器 SQL 池查询 Delta Lake 格式功能已正式发布。 但是,查询 Spark Delta 表功能仍为公共预览版,尚未准备好用于生产环境。 查询使用 Spark 池创建的 Delta 表时,可能会出现一些已知问题。 请参阅无服务器 SQL 池自助中的已知问题。
先决条件
重要
只能在自定义数据库中创建数据源(不能在主数据库中或从 Apache Spark 池复制的数据库中操作)。
要使用本文中的示例,需要完成以下步骤:
- 创建数据库,其中包含了引用纽约黄色出租车存储帐户的数据源。
- 通过对第 1 步中创建的数据库执行设置脚本操作来初始化对象。 此安装脚本将创建数据源、数据库范围的凭据以及在这些示例中使用的外部文件格式。
如果已创建数据库,并已将上下文切换到该数据库(在某个查询编辑器中使用 USE database_name 语句或下拉列表选择数据库),则可以创建包含数据集根 URI 的外部数据源,并使用它查询 Delta Lake 文件。 例如:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
如果数据源受到 SAS 密钥或自定义标识保护,则可以使用数据库范围的凭据配置数据源。
可以使用指向存储根文件夹的位置创建外部数据源。 创建外部数据源后,请在 OPENROWSET 函数中使用数据源和文件的相对路径。 这样就无需使用文件的完整绝对 URI。 然后,你还可定义自定义凭据来访问存储位置。
读取 Delta Lake 文件夹
重要
请使用先决条件中的安装脚本来设置示例数据源和表。
通过 OPENROWSET 函数,可提供根文件夹的 URL 来读取 Delta Lake 文件的内容。
要查看 DELTA 文件的内容,最简单的方法是向 OPENROWSET 函数提供文件 URL,并指定 DELTA 格式。 如果该文件可公开查看,或者你的 Microsoft Entra 标识有权访问该文件,则你应该可以使用类似于以下示例所示查询的查询来查看该文件的内容:
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
系统会自动从 Delta Lake 文件中读取列名称和数据类型。
OPENROWSET 函数对字符串列使用最佳猜测类型,如 VARCHAR(1000)。
OPENROWSET 函数中的 URI 必须引用包含 _delta_log 子文件夹的 Delta Lake 根文件夹。
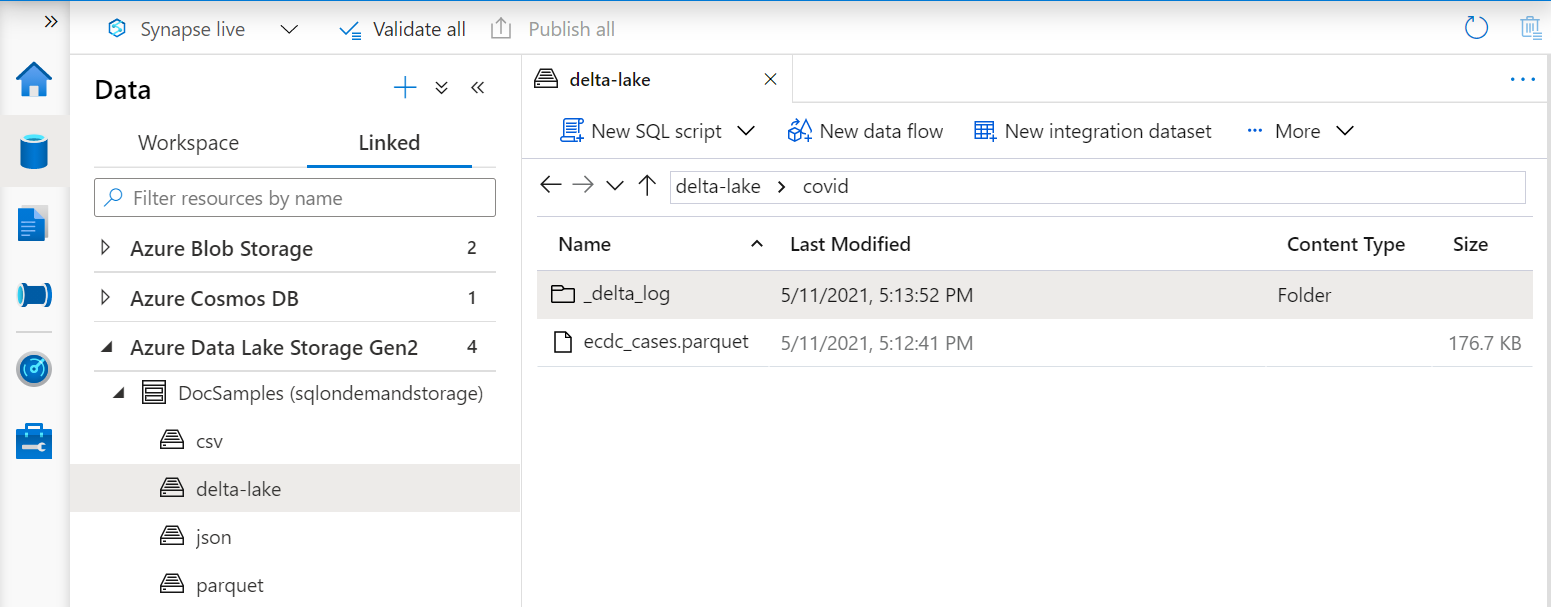
如果没有此子文件夹,则说明您未使用 Delta Lake 格式。 可使用一个脚本(例如以下示例 Apache Spark Python 脚本),将该文件夹中的普通 Parquet 文件转换为 Delta Lake 格式:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
为提高查询性能,请考虑在 WITH 子句中指定显式类型。
注意
无服务器 Synapse SQL 池使用架构推理来自动确定列及其类型。 架构推理的规则与 Parquet 文件所采用的规则相同。 对于 Delta Lake 数据类型映射到 SQL 原生类型,请检查 Parquet 的类型映射。
确保可访问文件。 如果你的文件是使用 SAS 密钥或自定义 Azure 标识来保护的,则你需要设置一个用于 SQL 登录的服务器级凭据。
重要
确保使用 UTF-8 数据库排序规则(例如 Latin1_General_100_BIN2_UTF8),因为 Delta Lake 文件中的字符串值采用 UTF-8 编码。
Delta Lake 文件中的文本编码与排序规则不匹配可能会导致意外的转换错误。
可以使用以下 T-SQL 语句轻松地更改当前数据库的默认排序规则:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8;有关排序规则的详细信息,请参阅 Synapse SQL 支持的排序规则类型。
显式指定架构
使用 OPENROWSET,你可以通过 WITH 语句明确地指定要从文件中读取的列:
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
根据结果集架构的显式规范,可最大程度地缩小类型大小并为字符串列使用更精确的类型 VARCHAR(6),而不是保守的 VARCHAR(1000)。 最大程度地缩小类型可能会显著提高查询的性能。
重要
确保在 Latin1_General_100_BIN2_UTF8 子句中为所有字符串列显式指定 UTF-8 排序规则(例如 WITH),或者在数据库级别设置 UTF-8 排序规则。
文件中的文本编码和字符串列排序规则不匹配可能会导致意外的转换错误。
可以使用 T-SQL 语句 轻松地更改当前数据库的默认排序规则
alter database current collate Latin1_General_100_BIN2_UTF8 可以使用以下定义轻松设置列类型的排序规则:geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
数据集
本示例中使用纽约黄色出租车数据集。 原始 PARQUET 数据集将转换为 DELTA 格式。在示例中使用 DELTA 版本。
查询分区数据
此示例中提供的数据集划分(分区)为单独的子文件夹。
与 Parquet 不同,无需使用 FILEPATH 函数定位特定分区。
OPENROWSET 将标识 Delta Lake 文件夹结构中的分区列,并允许使用这些列直接查询数据。 此示例显示 2017 年前三个月的票价金额(按年、月和支付类型)。
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
OPENROWSET 函数将消除与 where 子句中的 year 和 month 不匹配的分区。 该文件/分区修剪技术将显著减少数据集、提高性能并降低查询成本。
OPENROWSET 函数中的文件夹名称(在此示例中为 yellow)是使用 LOCATION 数据源中的 DeltaLakeStorage 连接的,并且必须引用包含 _delta_log 子文件夹的 Delta Lake 根文件夹。
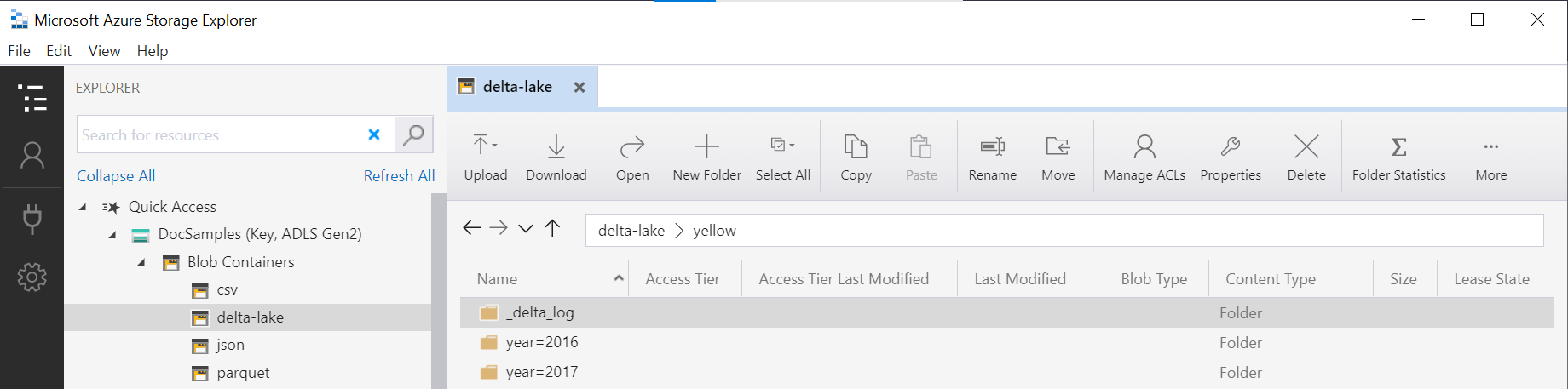
如果没有此子文件夹,则说明您未使用 Delta Lake 格式。 可使用以下 Apache Spark Python 脚本将文件夹中的普通 Parquet 文件转换为 Delta Lake 格式:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
DeltaTable.convertToDeltaLake 函数的第二个参数表示文件夹模式(本例中为 year=*/month=*)中的分区列(年和月)及其类型。
限制
- 查看 Synapse 无服务器 SQL 池自助页上的限制和其他已知问题。
相关内容
请继续前往下一篇文章,学习如何查询 Parquet 嵌套类型。 如果要继续生成 Delta Lake 解决方案,请了解如何在 Delta Lake 文件夹中创建视图或外部表。