你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用于 SAP HANA 的 Azure NetApp 文件上的 NFS v4.1 卷
Azure NetApp 文件提供本机 NFS 共享,可用于 /hana/shared、/hana/data 和 /hana/log 卷 。 对 /hana/data 和 /hana/log 卷使用基于 ANF 的 NFS 共享需要使用 v4.1 NFS 协议 。 当共享基于 ANF 时,NFS 协议 v3 不支持使用 /hana/data 和 /hana/log 卷。
重要
在 Azure NetApp 文件上实现的 NFS v3 协议不支持用于 /hana/data 和 /hana/log 。 从功能角度来看,对于 /hana/data 和 /hana/log 卷,NFS 4.1 是必需的 。 而对于 /hana/shared 卷,则可以从功能角度使用 NFS v3 或 NFS v4.1 协议。
重要注意事项
在考虑将 Azure NetApp 文件用于 SAP Netweaver 和 SAP HANA 时,请注意以下重要注意事项:
最小容量池为 4 TiB
最小卷大小为 100 GiB
基于 ANF 的 NFS 共享和装载这些共享的虚拟机必须位于同一 Azure 虚拟网络中,或者位于同一区域中对等互连的虚拟网络中
所选的虚拟网络必须具有一个委派给 Azure NetApp 文件的子网。 对于 SAP 工作负载,强烈建议为委托给 ANF 的子网配置 /25 范围。
重要的是要让虚拟机的部署位置足够靠近 Azure NetApp 存储,以实现低延迟,例如 SAP HANA 对重做日志写入的延迟要求。
- 同时,Azure NetApp 文件具有将 NFS 卷部署到特定 Azure 可用性区域的功能。 在大多数情况下,这种区域邻近性足以实现小于 1 毫秒的延迟。 此功能目前为公共预览版,有关详情,请参阅管理 Azure NetApp 文件的可用性区域卷放置一文。 此功能不需要与 Microsoft 进行任何交互式过程,即可实现 VM 与所分配的 NFS 卷之间的邻近放置。
- 要实现最佳邻近放置,可使用应用程序卷组功能。 此功能不仅要寻找最佳邻近放置,而且还要寻找 NFS 卷的最佳放置,因此,HANA 数据和重做日志卷由不同的控制器处理。 缺点是此方法需要与 Microsoft 进行一些交互式过程才能固定 VM。
请确保从数据库服务器到 ANF 卷的延迟得到测量并低于 1 毫秒
Azure NetApp 卷的吞吐量是卷配额和服务级别的函数,如 Azure NetApp 文件服务级别中所述。 调整 HANA Azure NetApp 卷的大小时,请确保生成的吞吐量满足 HANA 系统要求。 或者考虑使用手动 QoS 容量池,其中的卷容量和吞吐量可以单独进行配置和缩放(此文档中提供了特定于 SAP HANA 的示例)
请尝试“合并”卷以在更大卷中实现更高性能,例如,在可能时将一个卷用于 /sapmnt、/usr/sap/trans… 。
Azure NetApp 文件提供导出策略:你可以对允许的客户端、访问类型(读写、只读等)进行控制。
虚拟机上 sidadm 的用户 ID 和
sapsys的组 ID 必须与 Azure NetApp 文件中的配置匹配。实现 SAP 说明3024346 中提到的 Linux OS 参数
重要
对于 SAP HANA 工作负载,低延迟至关重要。 与 Microsoft 代表合作,确保虚拟机和 Azure NetApp 文件卷在邻近的地方部署。
重要
如果在虚拟机和 Azure NetApp 配置之间,sidadm 的用户 ID 和 sapsys 组 ID 不匹配,VM 上装载的 Azure NetApp 卷上的文件权限会显示为 nobody。 在载入新系统到 Azure NetApp 文件时,请确保指定的 sidadm 的用户 ID 和 sapsys 的组 ID 准确无误。
NCONNECT 装载选项
Nconnect 是 ANF 上托管的 NFS 卷的装载选项,允许 NFS 客户端针对单个 NFS 卷打开多个会话。 使用值大于 1 的 nconnect 还会触发 NFS 客户端在客户端上使用多个 RPC 会话(在来宾 OS 中)来处理来宾 OS 与装载的 NFS 卷之间的流量。 使用多个会话不仅可以处理一个 NFS 卷的流量,使用多个 RPC 会话还可以应对性能和吞吐量场景,例如:
- 在一个 VM 中装载具有不同服务级别的多个 ANF 托管 NFS 卷
- 卷和单个 Linux 会话的最大写入吞吐量介于 1.2 与 1.4 GB/秒之间。 针对一个 ANF 托管 NFS 卷使用多个会话可以提高吞吐量
有关支持 nconnect 作为装载选项的 Linux OS 版本以及 nconnect 的一些重要配置注意事项(尤其是在具有不同的 NFS 服务器终结点时),请阅读文档适用于 Azure NetApp 文件的 Linux NFS 装载选项最佳做法。
调整 Azure NetApp 文件上的 HANA 数据库的大小
Azure NetApp 卷的吞吐量是卷大小和服务级别的函数,如 Azure NetApp 文件服务级别中所述。
重要的是了解性能与大小的关系,服务的存储终结点存在物理限制。 每个存储终结点将在创建卷时动态注入 Azure NetApp 文件委托子网,并接收 IP 地址。 Azure NetApp 文件卷可以共享存储终结点,具体取决于可用的容量和部署逻辑
下表表明创建大型“标准”卷来存储备份是有意义的,而创建大于 12 TB 的“超级”卷是没有意义的,因为会超过单个卷的最大物理带宽容量。
如果 /hana/data 卷所需的写入吞吐量超过单个 Linux 会话可以提供的最大写入吞吐量,还可以使用 SAP HANA 数据卷分区作为替代方法。 利用 SAP HANA 数据卷分区可以在数据重新载入期间使 I/O 活动条带化,或者跨多个 NFS 共享上的多个 HANA 数据文件创建条带化 HANA 保存点。 有关 HANA 数据卷条带化的更多详细信息,请阅读以下文章:
| 大小 | 标准吞吐量 | 高级吞吐量 | 超级吞吐量 |
|---|---|---|---|
| 1 TB | 16 MB/秒 | 64 MB/秒 | 128 MB/秒 |
| 2 TB | 32 MB/秒 | 128 MB/秒 | 256 MB/秒 |
| 4 TB | 64 MB/秒 | 256 MB/秒 | 512 MB/秒 |
| 10 TB | 160 MB/秒 | 640 MB/秒 | 1,280 MB/秒 |
| 15 TB | 240 MB/秒 | 960 MB/秒 | 1,400 MB/秒1 |
| 20 TB | 320 MB/秒 | 1,280 MB/秒 | 1,400 MB/秒1 |
| 40 TB | 640 MB/秒 | 1,400 MB/秒1 | 1,400 MB/秒1 |
1:写入或单会话读取吞吐量限制(如果未使用 NFS 装载选项 nconnect)
重要的是需要了解,数据会写入存储后端中的相同 SSD。 创建容量池中的性能配额是为了能够管理环境。 存储 KPI 对于所有 HANA 数据库大小都是等同的。 在几乎所有情况下,这种假设并不能反映现实和客户期望。 HANA 系统的大小不一定意味着小型系统需要较低的存储吞吐量,而大型系统需要较高的存储吞吐量。 但一般而言,对于较大的 HANA 数据库实例,我们可以期望更高的吞吐量要求。 由于 SAP 对底层硬件的大小调整规则,此类较大 HANA 实例在实例重新启动后加载数据等任务中也可提供更多的 CPU 资源和更高的并行性。 因此,应根据客户期望和要求采用卷大小。 而不仅仅将单纯的容量要求作为驱动因素。
在 Azure 中为 SAP 设计基础结构时,应了解 SAP 的一些最低存储吞吐量要求(对于生产系统): 这些要求可转换为以下最低吞吐量特征:
| 卷类型和 I/O 类型 | SAP 所需的最小 KPI | “高级”服务级别 | “超级”服务级别 |
|---|---|---|---|
| 日志卷写入 | 250 MB/秒 | 4 TB | 2 TB |
| 数据卷写入 | 250 MB/秒 | 4 TB | 2 TB |
| 数据量读取 | 400 MB/秒 | 6.3 TB | 3.2 TB |
由于所有这三个 KPI 都是必需的,因此需要将 /hana/data 卷的大小调整为更大的容量,以满足最低读取要求。 使用手动 QoS 容量池时,可以单独定义卷的大小和吞吐量。 由于容量和吞吐量均取自同一个容量池,池的服务级别和大小必须足够大才能保证总体性能(请参阅此处的示例)
对于不需要高带宽的 HANA 系统,可以通过较小的卷大小来降低 ANF 卷吞吐量;使用手动 QoS 时,可以直接调整吞吐量。 如果 HANA 系统需要更多吞吐量,则可以通过联机重设容量大小来调整卷。 没有为备份卷定义 KPI。 但是,备份卷吞吐量对于执行良好的环境是必不可少的。 日志和数据卷性能必须按照客户期望进行设计。
重要
无论在单个 NFS 卷上部署的容量如何,预计吞吐量都将 1.2-1.4 GB/秒的带宽范围(由单个会话中的使用者利用)内稳定下来。 这与 ANF 产品/服务的基础体系结构以及围绕 NFS 的相关 Linux 会话限制有关。 Azure NetApp 文件的性能基准测试结果一文中记录的性能和吞吐量数针对具有多个客户端 VM 的一个共享 NFS 卷而执行,因此具有多个会话。 这种情况不同于我们在 SAP 中测量的情况。 我们针对 NFS 卷衡量单个 VM 的吞吐量的位置。 托管在 ANF 上。
为了满足 SAP 数据和日志的最低吞吐量要求,并根据 /hana/shared 准则,建议的大小如下所示:
| 数据量(Volume) | 大小 高级存储层 |
大小 超级存储层 |
支持的 NFS 协议 |
|---|---|---|---|
| /hana/log/ | 4 TiB | 2 TiB | v4.1 |
| /hana/data | 6.3 TiB | 3.2 TiB | v4.1 |
| /hana/shared scale-up | 最小值(1 TB,1 x RAM) | 最小值(1 TB,1 x RAM) | v3 或 v4.1 |
| /hana/shared scale-out | 1 x 工作器节点 RAM 每四个工作器节点 |
1 x 工作器节点 RAM 每四个工作器节点 |
v3 或 v4.1 |
| /hana/logbackup | 3 x RAM | 3 x RAM | v3 或 v4.1 |
| /hana/backup | 2 x RAM | 2 x RAM | v3 或 v4.1 |
对于所有卷,强烈建议使用 NFS v4.1。
请仔细查看有关调整 /hana/shared 大小的注意事项,因为适当大小的 /hana/shared 卷有助于系统的稳定性。
备份卷的大小是估算值。 需要根据工作负载和操作过程来定义精确要求。 对于备份,可以将不同 SAP HANA 实例的多个卷整合为一个(或两个)较大卷,这可能会具有较低服务级别的 ANF。
注意
本文档中所述 Azure NetApp 文件大小调整建议的目的在于满足 SAP 向其基础架构提供商表达的最低要求。 在实际客户部署和工作负载场景中,这可能还不够。 请将这些建议作为起点,并根据具体工作负载的要求进行调整。
因此,可以考虑对已为超级磁盘存储列出的 ANF 卷部署类似的吞吐量。 同时请考虑为不同 VM SKU 的卷列出的大小情况,正如超级磁盘表中所做的那样。
提示
可以动态调整 Azure NetApp 文件卷的大小,而无需 unmount 卷、停止虚拟机或停止 SAP HANA。 这具有灵活性,可同时满足应用程序的预期和不可预见的吞吐量需求。
有关如何使用基于 ANF 的 NFS v4.1 卷部署带备用节点的 SAP HANA 横向扩展配置的文档,已在以下位置发布:使用 SUSE Linux Enterprise Server 上的 Azure NetApp 文件在 Azure VM 上进行带备用节点的 SAP HANA 横向扩展。
Linux 内核设置
若要在 ANF 上成功部署 SAP HANA,需要根据 SAP 说明 3024346 实现 Linux 内核设置。
对于使用高可用性 (HA) 的系统,如果使用了 pacemaker 和 Azure 负载均衡器,则需要在 /etc/sysctl.d/91-NetApp-HANA.conf 文件中实现以下设置
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
如果系统运行时未使用 pacemaker 和 Azure 负载均衡器,则应在 /etc/sysctl.d/91-NetApp-HANA.conf 中实现这些设置
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
具有区域邻近性的部署
若要实现 NFS 卷和 VM 的区域邻近性,可以按照管理 Azure NetApp 文件的可用性区域卷放置中所述的说明进行操作。 使用此方法时,VM 和 NFS 卷将位于同一 Azure 可用性区域中。 在大多数 Azure 区域中,对于 SAP HANA 的较小重做日志写入,此类型的邻近性应足以实现小于 1 毫秒的延迟。 此方法不需要与 Microsoft 进行任何交互式操作,即可将 VM 放置并固定到特定数据中心。 因此,你可以在所部署的可用性区域中提供的所有 VM 类型和系列中灵活更改 VM 大小和系列。 因此,你可以灵活地应对不断变化的情况,或者更快地迁移到更具成本效益的 VM 大小或系列。 建议将此方法用于非生产系统和可以处理接近 1 毫秒的重做日志延迟的生产系统。 目前此功能以公共预览版提供。
通过适用于 SAP HANA (AVG) 的 Azure NetApp 文件应用程序卷组进行部署
为了部署与 VM 邻近的 ANF 卷,开发了一个新功能,称为适用于 SAP HANA (AVG) 的 Azure NetApp 文件应用程序卷组。 我们已发布一系列文章来介绍该功能。 最好从了解适用于 SAP HANA 的 Azure NetApp 文件应用程序卷组一文开始阅读。 阅读这些文章后,就会明白使用 AVG 时也涉及使用 Azure 邻近放置组。 邻近放置组是通过与创建的卷绑定在一起的新功能进行使用的。 为确保在 HANA 系统的整个生存期内不让 VM 离开 ANF 卷,建议在部署的每个区域中使用 Avset/ PPG 组合。 部署顺序如下所示:
- 使用所需表单请求将空 AvSet 固定到计算 HW,以确保 VM 不会迁移
- 将 PPG 分配到可用性集并启动分配给此可用性集的 VM
- 使用适用于 SAP HANA 的 Azure NetApp 文件应用程序卷组功能来部署 HANA 卷
以理想方式使用 AVG 的邻近放置组配置如下所示:
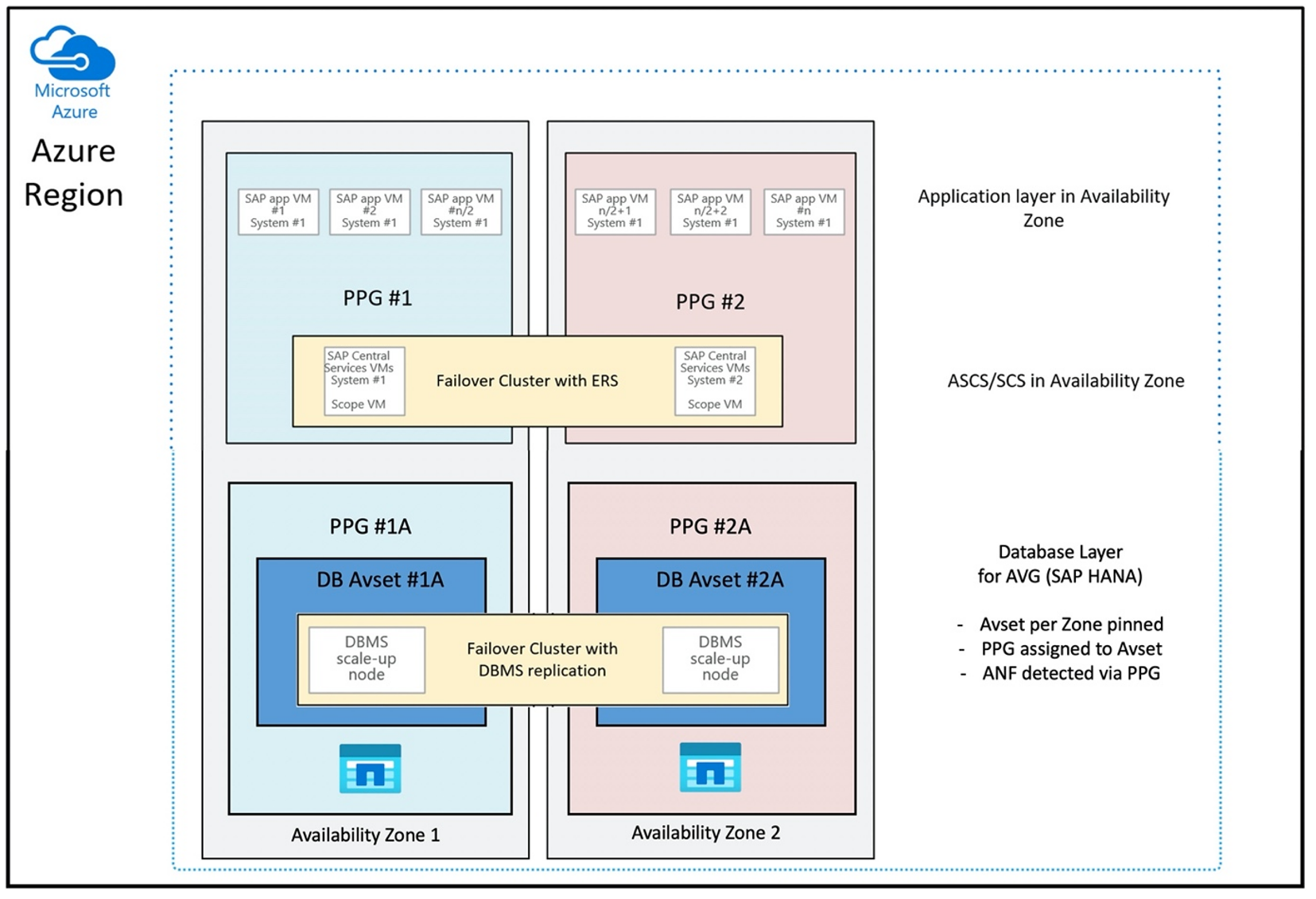
此图显示你要为 DBMS 层使用 Azure 邻近放置组。 因此,它可以与 AVG 一起使用。 最好在邻近放置组中只加入运行 HANA 实例的 VM。 即使只是使用一个单 HANA 实例的 VM,也必须使用邻近放置组,以便 AVG 识别最近的 ANF 硬件。 并且尽可能接近使用 NFS 卷的 VM 分配基于 ANF 的 NFS 卷。
此方法可生成与低延迟相关的最佳结果。 不仅仅是通过使 NFS 卷和 VM 尽可能靠近。 而且还会考虑到在 NetApp 后端的不同控制器之间放置数据和重做日志卷方面的注意事项。 不过,缺点是 VM 部署只会固定到一个数据中心。 这样,就失去了更改 VM 类型和系列的灵活性。 因此,应仅针对绝对需要如此低存储延迟的系统使用此方法。 对于所有其他系统,应尝试使用 VM 和 ANF 的传统区域性部署进行部署。 在大多数情况下,这足以满足低延迟方面的要求。 这还可确保轻松维护和管理 VM 和 ANF。
可用性
ANF 系统更新和升级可在不影响客户环境的情况下进行应用。 定义的 SLA 为 99.99%。
卷以及 IP 地址和容量池
对于 ANF,必须了解底层基础结构的构建方式。 容量池只是一个构造,它根据容量池服务级别提供容量和性能预算以及计费单位。 容量池与底层基础结构没有物理关系。 在服务上创建卷时,将创建存储终结点。 将单个 IP 地址分配给此存储终结点,以提供对卷的数据访问。 如果创建多个卷,则所有卷将分布在底层裸机机群中,并绑定到此存储终结点。 ANF 具有一个逻辑,可在已配置存储的卷或/和容量达到内部预定义级别后自动分布客户工作负载。 你可能会注意到这种情况,因为会自动创建具有新 IP 地址的新存储终结点以访问卷。 ANF 服务不提供客户对此分发逻辑的控制。
日志卷和日志备份卷
“日志卷” (/hana/log) 用于写入联机重做日志。 因而有打开的文件位于此卷中,对此卷拍摄快照没什么意义。 联机重做日志文件已满或执行重做日志备份后,联机重做日志文件会存档或备份到日志备份卷。 若要提供合理的备份性能,日志备份卷需要良好的吞吐量。 若要优化存储成本,合并多个 HANA 实例的日志备份卷会十分有意义。 这样多个 HANA 实例可使用相同卷,并将其备份写入不同目录。 使用此类合并可以获得更大的吞吐量,因为你需要使卷更大一些。
这同样适用于将完整 HANA 数据库备份写入的卷。
备份
除流式处理备份以及备份 SAP HANA 数据库的 Azure 备份服务(如 Azure 虚拟机上的 SAP HANA 备份指南一文中所述)之外,通过 Azure NetApp 文件还可以执行基于存储的快照备份。
SAP HANA 支持:
- 为使用 SAP HANA 1.0 SPS7 和更高版本的单容器系统提供基于存储的快照备份支持
- 为包含单个租户的、使用 SAP HANA 2.0 SPS1 和更高版本的多数据库容器 (MDC) HANA 环境提供基于存储的快照备份支持
- 为包含多个租户的、使用 SAP HANA 2.0 SPS4 和更高版本的多数据库容器 (MDC) HANA 环境提供基于存储的快照备份支持
创建基于存储的快照备份是简单的四步骤过程,
- 创建 HANA(内部)数据库快照 - 你或工具需要执行的活动
- SAP HANA 将数据写入数据文件以在存储中创建一致的状态 - HANA 在创建 HANA 快照后执行此步骤
- 在存储中的 /hana/data 卷上创建快照 - 你或工具需要执行的步骤。 无需在 /hana/log 卷上执行快照操作
- 删除 HANA(内部)数据库快照并恢复正常操作 - 你或工具需要执行的步骤
警告
缺少最后一个步骤或未能执行最后一个步骤会对 SAP HANA 的内存需求产生严重影响,可能会导致 SAP HANA 停止
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
可以使用各种工具,通过多种方式来管理此快照备份过程。 一个示例是 GitHub https://github.com/netapp/ntaphana 上提供的 Python 脚本“ntaphana_azure.py”。这是示例代码,“按原样”提供,没有任何维护或支持。
注意
快照本身不是受保护的备份,因为快照与刚拍摄快照的卷都位于相同的物理存储中。 每天必须在不同的位置至少“保护”一个快照。 这可以在同一环境、远程 Azure 区域或 Azure Blob 存储中进行。
可用于基于存储快照的应用程序一致性备份的解决方案:
- Microsoft 什么是 Azure 应用程序一致快照工具是一种命令行工具,用于为第三方数据库启用数据保护。 此工具在处理完将数据库置于应用程序一致状态所需的所有编排之后,将执行存储快照。 执行存储快照后,该工具会将数据库返回到操作状态。 AzAcSnap 支持对 HANA 大型实例和 Azure NetApp 文件进行基于快照的备份。 有关详细信息,请阅读什么是 Azure 应用程序一致性快照工具一文
- 对于 Commvault 备份产品的用户,另一个选项是 Commvault IntelliSnap V.11.21 和更高版本。 此版本或更高版本的 Commvault 提供 Azure NetApp 文件快照支持。 Commvault IntelliSnap 11.21 一文提供了详细信息。
使用 Azure blob 存储备份快照
备份到 Azure blob 存储是一种经济高效且快速的方法,可用于保存基于 ANF 的 HANA 数据库存储快照备份。 若要将快照保存到 Azure Blob 存储,AzCopy 工具是首选工具。 下载此工具的最新版本并安装(例如在安装 GitHub 中的 Python 脚本的 bin 目录中)。 下载最新 AzCopy 工具:
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
最高级的功能是同步选项。 如果使用同步选项,则 azcopy 会使源目录和目标目录保持同步。 参数 --delete-destination 的使用十分重要。 如果没有此参数,azcopy 不会删除目标站点上的文件,目标端的空间使用率会增长。 在 Azure 存储帐户中创建块 Blob 容器。 随后为 blob 容器创建 SAS 密钥,并将快照文件夹同步到 Azure Blob 容器。
例如,如果每日快照应同步到 Azure blob 容器以保护数据。 只应保留一个快照,可以使用以下命令。
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
后续步骤
阅读文章: