在管道中,您可以使用复制操作在云中的数据存储之间复制数据。 复制数据后,可以使用管道中的其他活动对其进行转换和分析。
复制活动连接到您的数据源和目的地,然后在它们之间高效地传输数据。 下面是服务如何处理复制过程:
- 连接到您的源:创建与源数据存储库的安全连接以读取数据。
- 处理数据:根据配置处理序列化/反序列化、压缩/解压缩、列映射和数据类型转换。
- 写入目标:将处理后的数据传输到您的目标数据存储。
- 提供监视:跟踪复制操作,并提供故障排除和优化的详细日志和指标。
Tip
如果您只需要复制数据而不需要进行转换,那么 复制作业 可能是更好的选择。 复制作业为不需要创建完整管道的数据传输场景提供更加简化的使用体验。 请参阅: 复制作业概述 或使用 我们的决策表比较复制活动和复制作业。
Prerequisites
若要开始,需要完成以下先决条件:
- 具有活动订阅的 Microsoft Fabric 租户帐户。 免费创建帐户。
- 已启用 Microsoft Fabric 的工作区。
使用复制助手添加复制活动
按照以下步骤使用复制助手设置复制操作。
从复制助手开始
打开现有管道或创建新管道。
选择画布上的“复制数据”,打开“复制助手”工具以开始使用。 或者从功能区上“活动”选项卡下的“复制数据”下拉列表中选择“使用复制助手”。
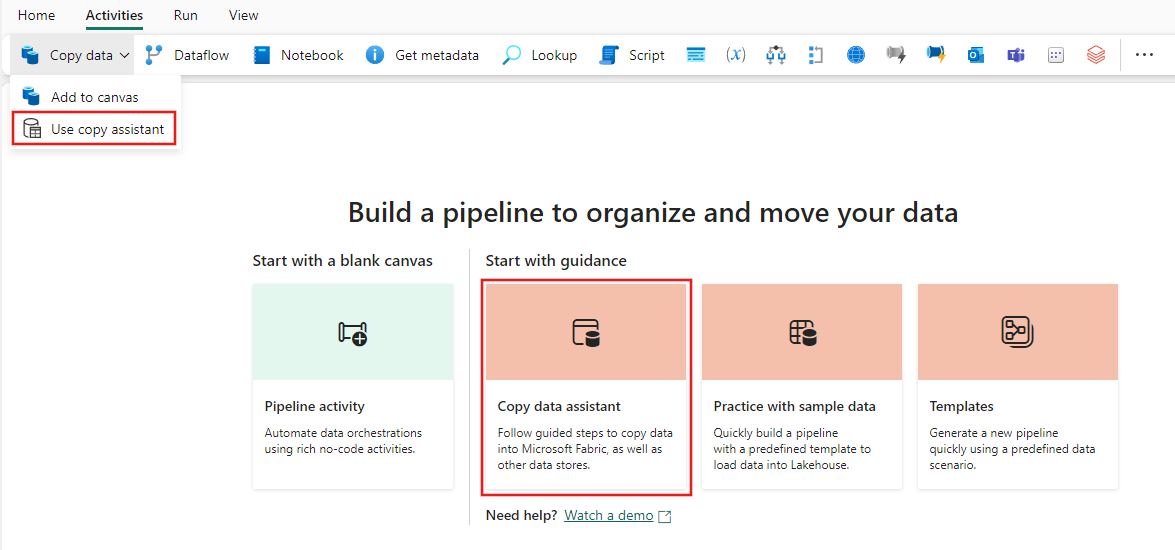

配置源代码
从类别中选择数据源类型。 你将使用 Azure Blob 存储作为示例。 选择Azure Blob 存储。
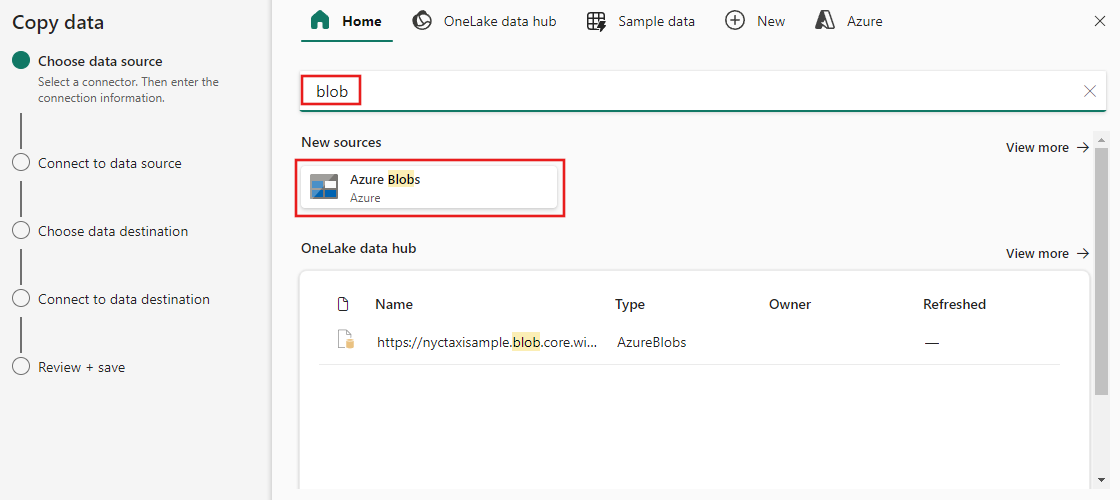
通过选择“创建新连接”,创建与数据源的连接。
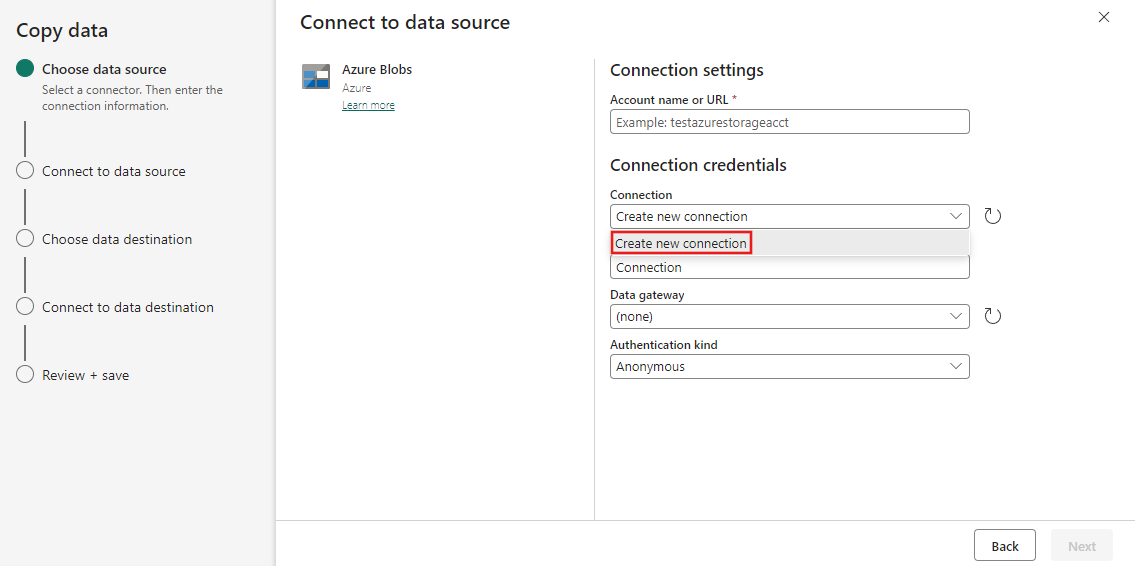
选择“创建新连接”后,填写所需的连接信息,然后选择“下一步”。 有关为每种类型的数据源创建连接的详细信息,请参阅每个 连接器文章。
如果已有连接,可以选择 “现有连接 ”,并从下拉列表中选择连接。
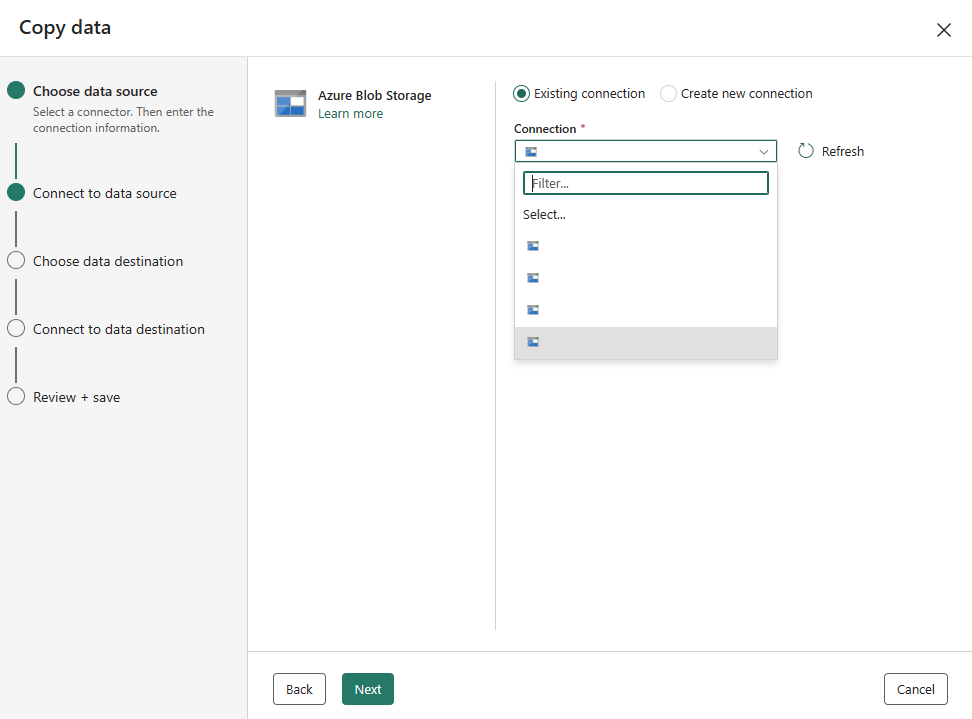
选择要在此源配置步骤中复制的文件或文件夹,然后选择“下一步”。





配置您的目标地址
从类别中选择数据源类型。 你将使用 Azure Blob 存储作为示例。 可以按照上一部分中的步骤创建链接到新 Azure Blob 存储帐户的新连接,也可以使用连接下拉列表中的现有连接。 测试连接和编辑功能可用于每个选定的连接。
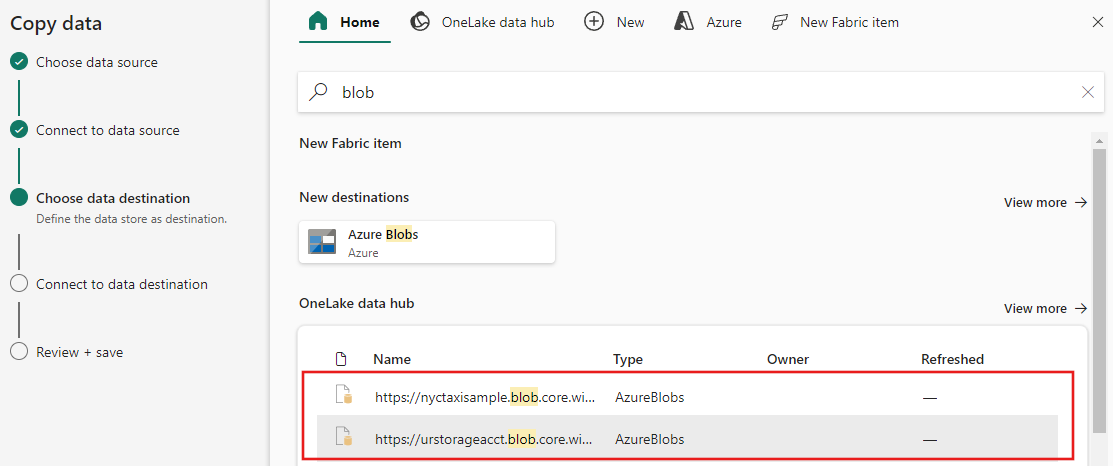
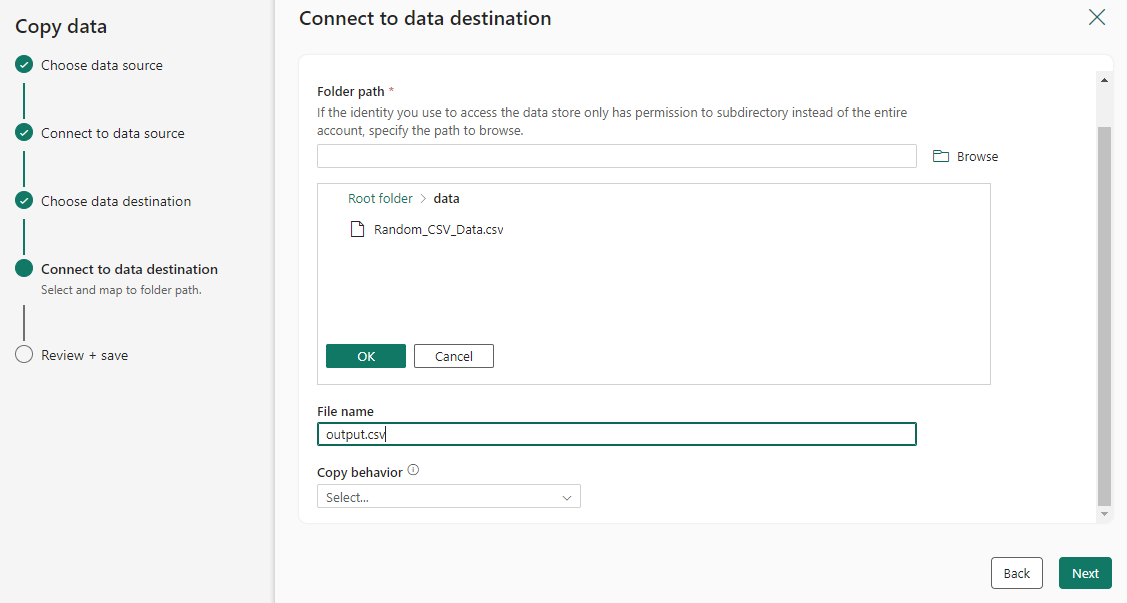
配置源数据并将其映射到目标。 然后选择“下一步”以完成目标配置。
Note
您只能在同一个复制活动中使用一个本地数据网关。 如果源和接收器都是本地数据源,则需要使用相同的网关。 若要在使用不同网关的本地数据源之间移动数据,需要在一个复制活动中使用第一个网关将数据复制到中间的云端源。 然后,可以使用另一个复制活动,通过第二个网关从中间云源复制数据。



查看并创建复制活动
在前面的步骤中查看复制活动设置,然后选择“确定”以完成。 或者,如果需要,可以返回到上述步骤,在工具中编辑设置。


完成后,复制活动就将被添加到您的管道画布中。 选中后,所有设置(包括此复制活动的高级设置)都将位于选项卡下。

现在,可以使用此单个复制活动保存管道,也可以继续设计管道。
直接添加复制活动
请按照以下步骤直接添加复制活动。
添加“复制活动”
打开现有管道或创建新管道。
通过在活动选项卡下选择“>复制活动”或选择“>添加到画布”,来添加复制活动。
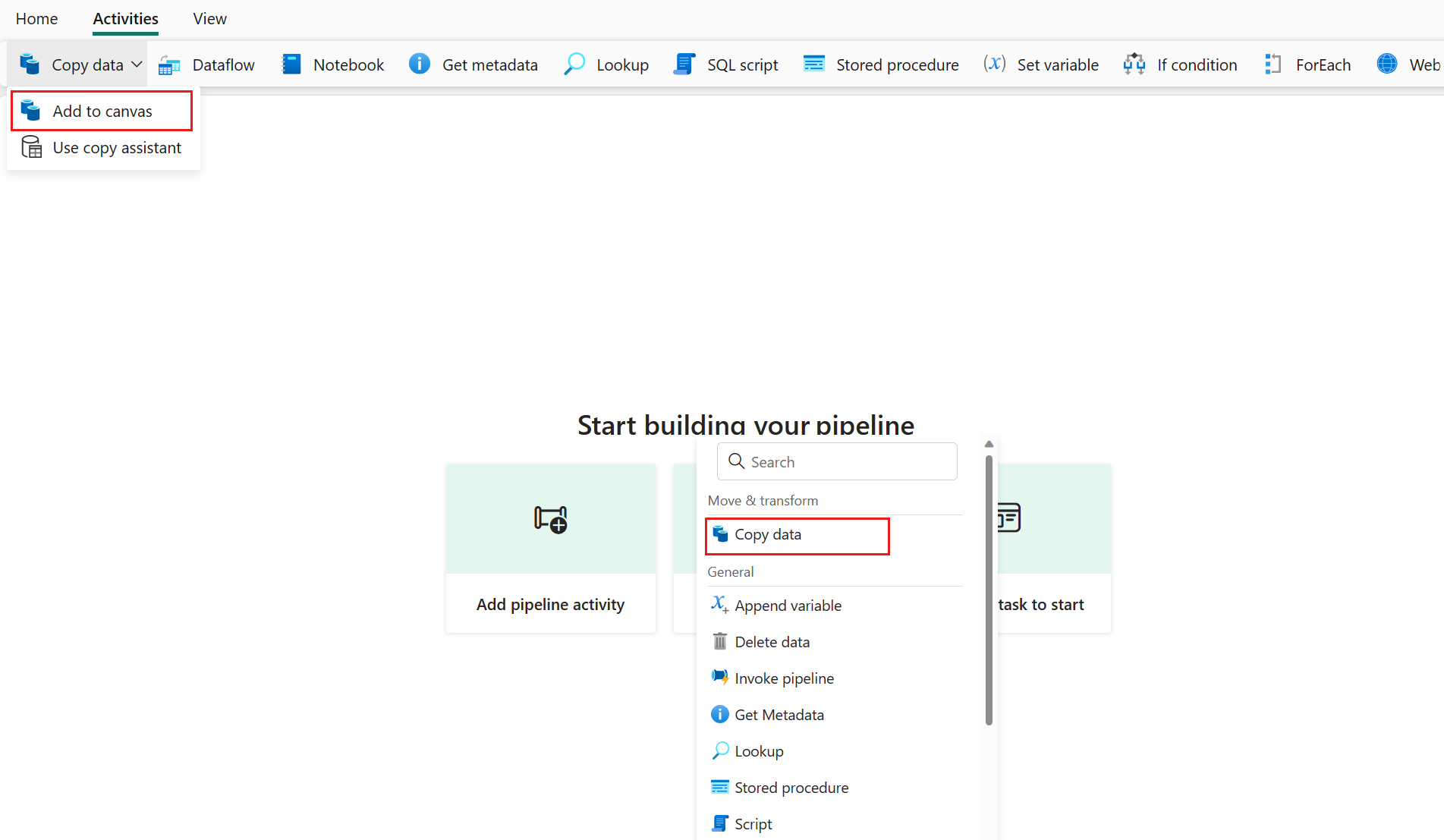

在“常规”选项卡下配置常规设置
若要了解如何配置常规设置,请参阅 常规。
在“源”选项卡下配置源
在 “连接”中,选择现有连接,或选择“ 更多 ”以创建新连接。
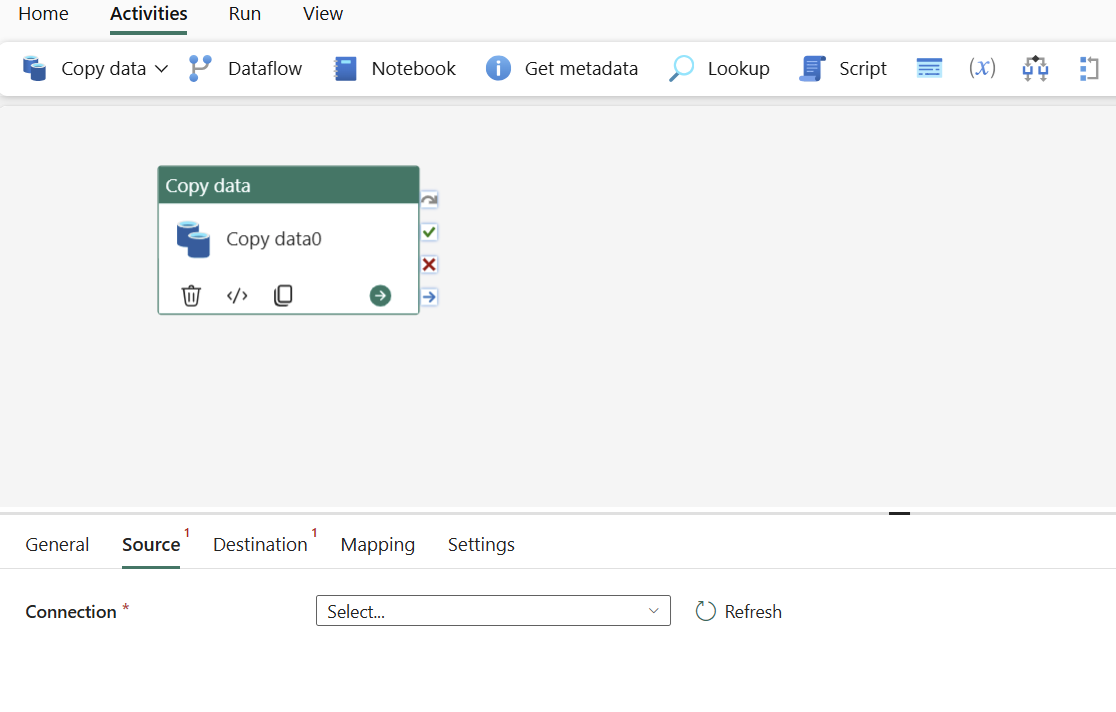
从弹出窗口中选择数据源类型。 你将使用 Azure SQL Database 作为示例。 选择“Azure SQL 数据库”,然后选择“继续” 。
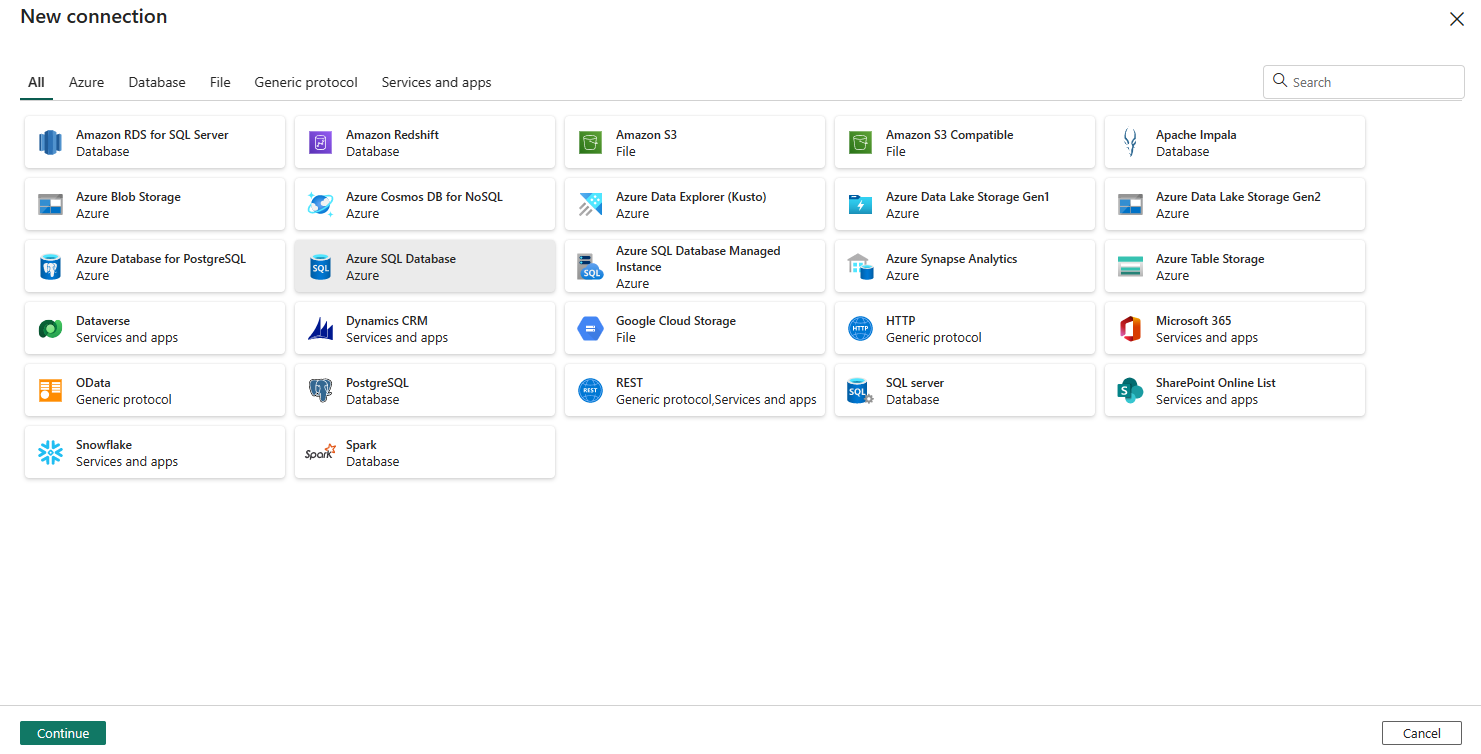
它会导航到连接创建页。 在面板上填写所需的连接信息,然后选择创建。 有关为每种类型的数据源创建连接的详细信息,请参阅每个 连接器文章。
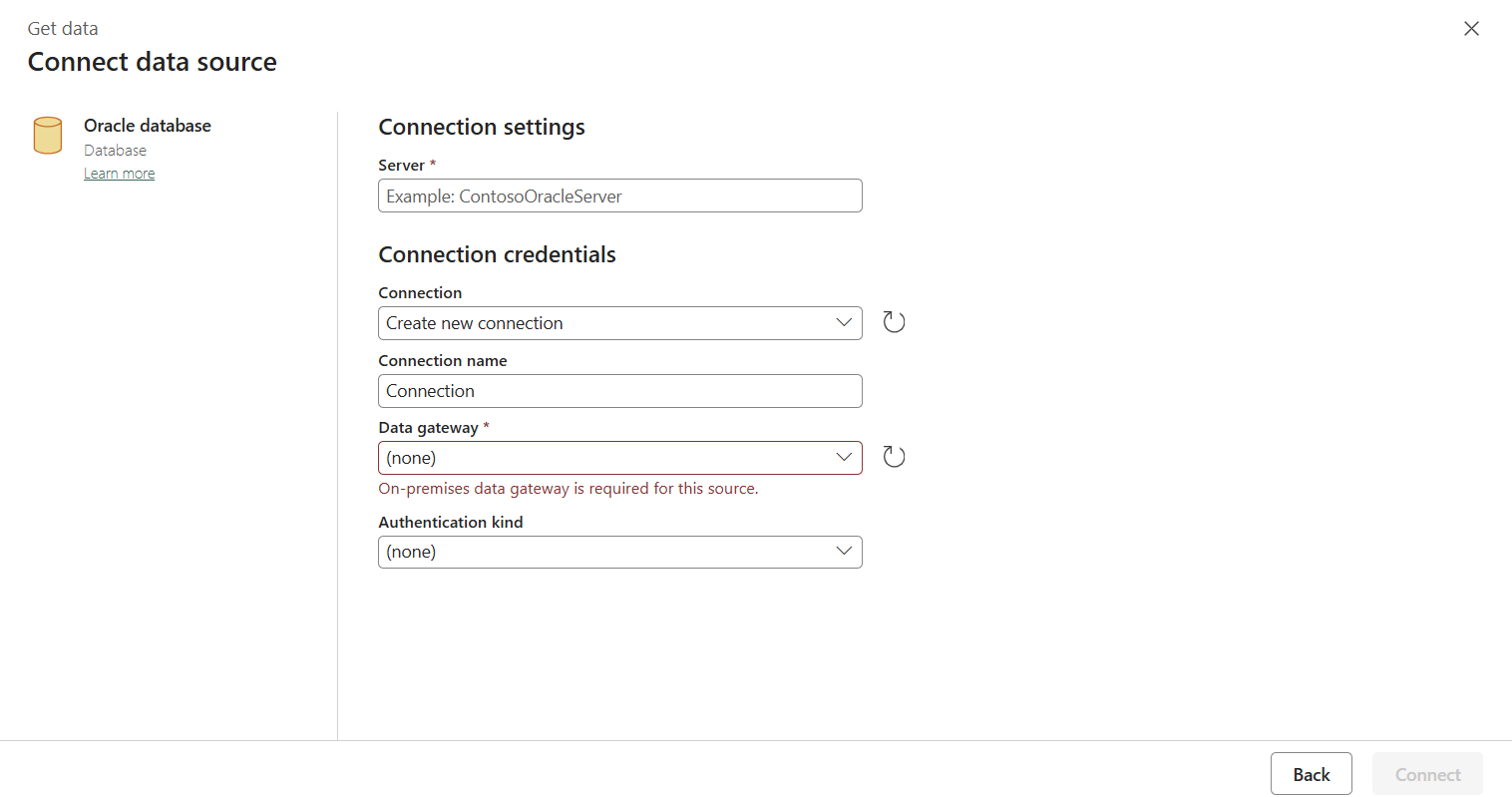
创建连接后,它会返回到管道页面。 然后选择 “刷新 ”,获取从下拉列表中创建的连接。 如果之前已创建现有 Azure SQL 数据库连接,也可以直接从下拉列表中选择现有的 Azure SQL 数据库连接。 测试连接和编辑功能可用于每个选定的连接。 然后在“连接类型”中选择“Azure SQL 数据库”。
指定要复制的表。 选择“预览数据”以预览源表。 还可以使用 查询 和 存储过程 从源读取数据。
展开 “高级 ”,获取查询超时或分区等更高级设置。 (高级设置因连接器而异。



在“目标”选项卡下配置目标
在 “连接 ”中选择现有连接,或选择“ 更多 ”以创建新连接。 它可以是您的工作区中的内部一级数据存储,例如 Lakehouse,或外部数据存储。 在此示例中,我们使用 Lakehouse。
创建连接后,它会返回到管道页面。 然后选择 “刷新 ”,获取从下拉列表中创建的连接。 如果之前已创建现有 Lakehouse 连接,也可以直接从下拉列表中选择现有连接。
指定表或设置文件路径,以将文件或文件夹定义为目标。 在此处选择“表”并指定要写入数据的表。
展开 “高级”以获取更高级的设置,例如每个文件的最大行数或表操作。 (高级设置因连接器而异。
现在,可以使用此复制活动保存管道,也可以继续设计管道。
在“映射”选项卡下配置映射
如果使用的连接器支持映射,则可以转到 “映射 ”选项卡来配置映射。
选择“导入架构”以导入数据架构。
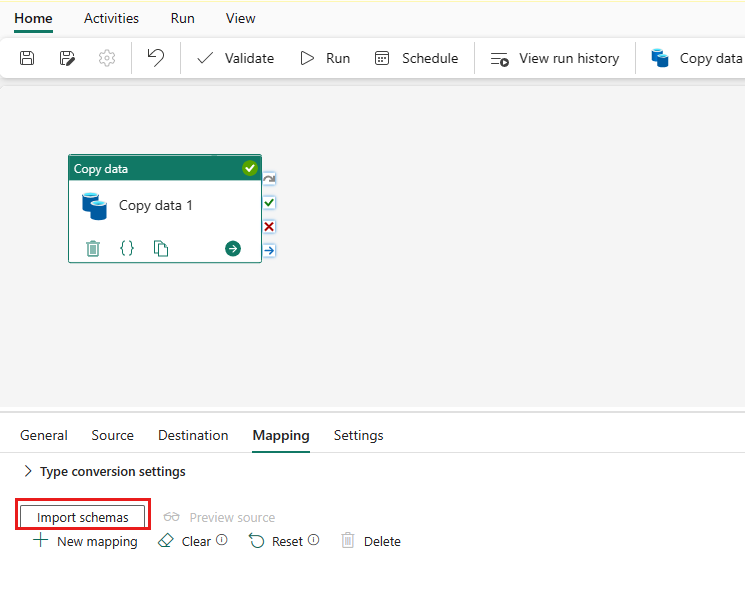
可以看到自动映射显示。 指定 源 列和 目标 列。 如果在目标中创建新表,则可以在此处自定义 目标 列名称。 如果要将数据写入现有目标表,则无法修改现有 目标 列名称。 还可以查看源列和目标列的 类型。
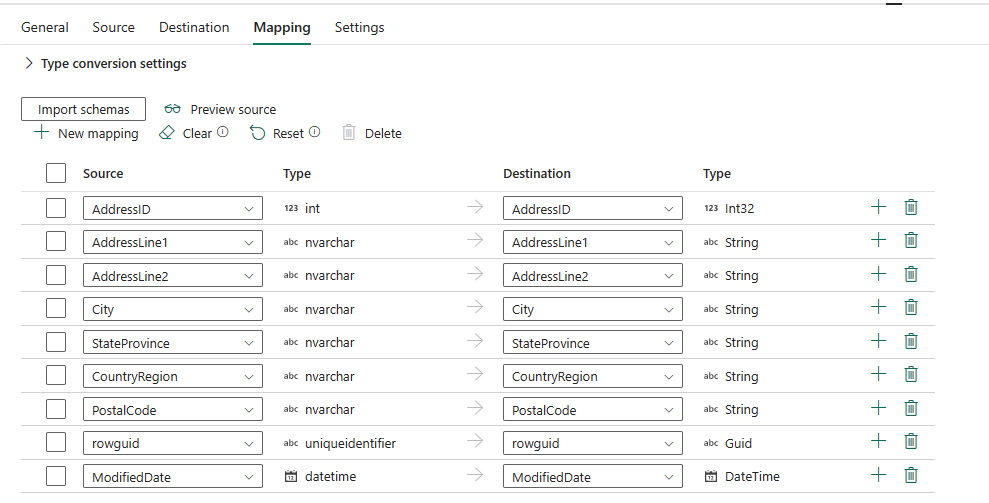


还可以选择“ + 新建映射 ”以添加新映射,选择“ 清除 ”以清除所有映射设置,然后选择“ 重置 ”以重置所有映射 源 列。
数据类型映射
管道中的复制活动和复制作业通过以下步骤执行源类型到目标类型的映射:
- 从源本地数据类型转换为 Fabric Data Factory 使用的中间数据类型。
- 根据需要自动转换临时数据类型以匹配相应的目标类型。
- 从临时数据类型转换为目标本机数据类型。
管道中的复制活动和复制作业当前支持以下临时数据类型:Boolean、Byte、Byte array、Datetime、DatetimeOffset、Decimal、Double、GUID、Int16、Int32、Int64、SByte、Single、String、Timespan、UInt16、UInt32 和 UInt64。
在从源到目标的临时类型之间支持以下数据类型转换。
| 源\目标 | 布尔 | 字节数组 | 日期/时间 | 十进制 | 浮点 | GUID | 整数 | String | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| 布尔 | ✓ | ✓ | ✓ | ✓ | |||||
| 字节数组 | ✓ | ✓ | |||||||
| 日期/时间 | ✓ | ✓ | |||||||
| 十进制 | ✓ | ✓ | ✓ | ✓ | |||||
| 浮点 | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| 整数 | ✓ | ✓ | ✓ | ✓ | |||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) 日期/时间包括 DateTime、DateTimeOffset、日期和时间。
(2) 浮点类型包括 Single 和 Double。
(3) 整数包括 SByte、Byte、Int16、UInt16、Int32、UInt32、Int64 和 UInt64。
若要了解特定连接器的详细数据类型转换,请 从此处转到该连接器的复制活动配置文章。
Note
在表格数据之间进行复制时,目前支持此类数据类型转换。 不支持分层源/目标,这意味着源和目标临时类型之间没有系统定义的数据类型转换。
在“设置”选项卡下配置其他设置
设置 选项卡包含性能、过渡等设置。

请参阅下表以了解每个设置的描述。
| Setting | Description | JSON 脚本属性 |
|---|---|---|
| 智能吞吐量优化 | 指定以优化吞吐量。 您可以选择以下选项: • 自动 • 标准 • 均衡 • 最大值 选择“自动”时,将根据源-目标对和数据模式动态应用最佳设置。 还可以自定义吞吐量,自定义值可以是 4-256,而更高的值意味着更多的收益。 |
dataIntegrationUnits |
| 复制并行度 | 指定数据加载将使用的并行度。 | parallelCopies |
| 自适应性能优化(预览版) | 指定服务是否可以根据自定义配置应用性能优化和调优。 | 自适应性能调优 |
| 数据一致性验证 | 如果为此属性设置 true ,在复制二进制文件时,复制活动将检查文件大小、lastModifiedDate 和从源存储复制到目标存储的每个二进制文件的校验和,以确保源存储与目标存储之间的数据一致性。 复制表格数据时,复制活动将检查作业完成后的总行计数,以确保从源中读取的行数与复制到目标的行数和跳过的不兼容行数之和相同。 请注意,启用此选项会影响复制性能。 |
validateDataConsistency |
| 容错 | 选择此选项时,可以忽略复制过程中发生的一些错误。 例如,源存储与目标存储之间的不兼容行、在数据移动期间删除的文件等。 | • 启用跳过不兼容行 (enableSkipIncompatibleRow) • skipErrorFile: fileMissing fileForbidden invalidFileName |
| 启用日志记录 | 选择此选项时,可以记录复制的文件、跳过的文件和行。 | / |
| 启用暂存 | 指定是否要通过过渡暂存存储复制数据。 仅针对有用的场景启用暂存。 | enableStaging |
| 对于 工作区 | ||
| Workspace | 指定使用内置暂存存储。 确保数据管道的上次修改用户至少被分配了工作区中的“参与者”角色。 | / |
| 对于 外部 | ||
| 预发布帐户连接 | 指定 Azure Blob 存储或 Azure Data Lake Storage Gen2 的连接,以指代用作过渡暂存存储的存储实例。 如果没有暂存连接,请创建一个。 | 连接(在 externalReferences 下) |
| 存储路径 | 指定要包含此暂存数据的路径。 如果不提供路径,该服务将创建容器以存储临时数据。 只在使用具有共享访问签名的存储时,或者要求临时数据位于特定位置时才指定路径。 | 路径 |
| 启用压缩 | 指定是否应先压缩数据,再将数据复制到目标。 此设置可减少传输的数据量。 | enableCompression |
| Preserve | 指定在数据复制期间是否保留元数据/ACL。 | preserve |
Note
若使用暂存复制并启用压缩,则不支持对暂存 Blob 连接的服务主体身份验证。
Note
工作区暂存超时 60 分钟。 对于长时间运行的作业,建议使用外部存储用作临时存储。
在复制活动中配置参数
参数可用于控制管道及其活动的行为。 可以使用“添加动态内容”来指定复制活动属性的参数。 我们以 Lakehouse/数据仓库的指定为例,看看如何使用它。
在源或目标中,选择“连接”下拉列表中的“使用动态内容”。
在弹出窗格“添加动态内容”中的“参数”选项卡下,选择 +。
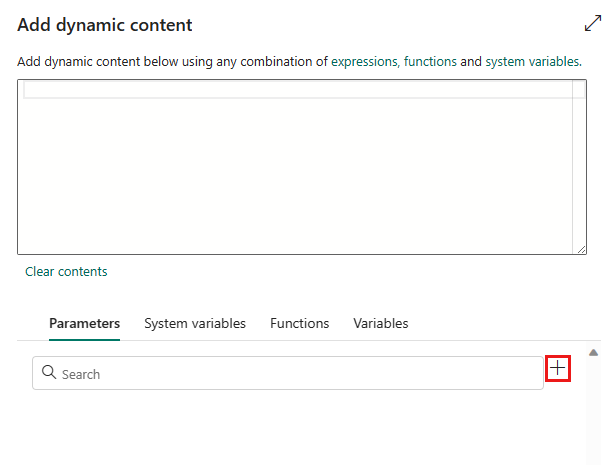
指定参数的名称,并根据需要为其指定默认值,也可以在管道中触发参数时指定参数的值。

参数值应为 Lakehouse/数据仓库连接 ID。 若要获取它,请打开 “管理连接”和“网关”,选择要使用的 Lakehouse/数据仓库连接,然后打开 “设置” 以获取连接 ID。 如果要创建新连接,可以在此页上选择 “+ 新建 ”,或者通过 “连接” 下拉列表获取数据页。
选择“保存”,以返回到 添加动态内容 窗格。 然后选择参数,使其显示在表达式框中。 然后选择“确定”。 你将返回到管道页,可以看到在 Connection 之后指定了参数表达式。
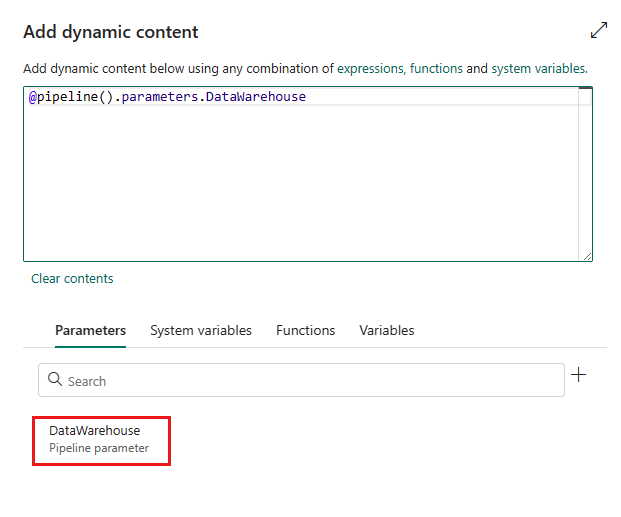
指定 Lakehouse 或数据仓库的 ID。 若要查找 ID,请进入您的工作区中的 Lakehouse 或数据仓库。 ID 出现在 URL 之后
/lakehouses/或/datawarehouses/之后。Lakehouse ID:

仓库 ID:
