在加载到湖屋之前使用存储过程预处理数据
本教程介绍如何在 Synapse 数据仓库中使用管道脚本活动运行存储过程,以创建表并预处理 Synapse Data Warehouse中的数据。 之后,我们将预处理的表加载到湖屋中。
先决条件
已启用 Microsoft Fabric 的工作区。 如果还没有工作区,请参阅创建工作区一文。
在 Azure Synapse 数据仓库中准备存储过程。 提前创建以下存储过程:
CREATE PROCEDURE spM_add_names AS --Create initial table IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[names]') AND TYPE IN (N'U')) BEGIN DROP TABLE names END; CREATE TABLE names (id INT,fullname VARCHAR(50)); --Populate data INSERT INTO names VALUES (1,'John Smith'); INSERT INTO names VALUES (2,'James Dean'); --Alter table for new columns ALTER TABLE names ADD first_name VARCHAR(50) NULL; ALTER TABLE names ADD last_name VARCHAR(50) NULL; --Update table UPDATE names SET first_name = SUBSTRING(fullname, 1, CHARINDEX(' ', fullname)-1); UPDATE names SET last_name = SUBSTRING(fullname, CHARINDEX(' ', fullname)+1, LEN(fullname)-CHARINDEX(' ', fullname)); --View Result SELECT * FROM names;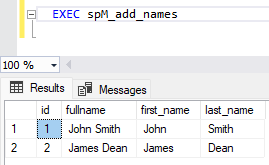
创建管道脚本活动以运行存储过程
在本部分中,我们使用脚本活动来运行在先决条件中创建的存储过程。
从“活动”工具栏中选择“脚本”活动,然后选择“属性”窗格中的“设置”选项卡,以选择连接详细信息。 选择该处的“连接”下拉菜单,以选择“更多”。 然后,可以连接到 Azure Synapse Data Warehouse。
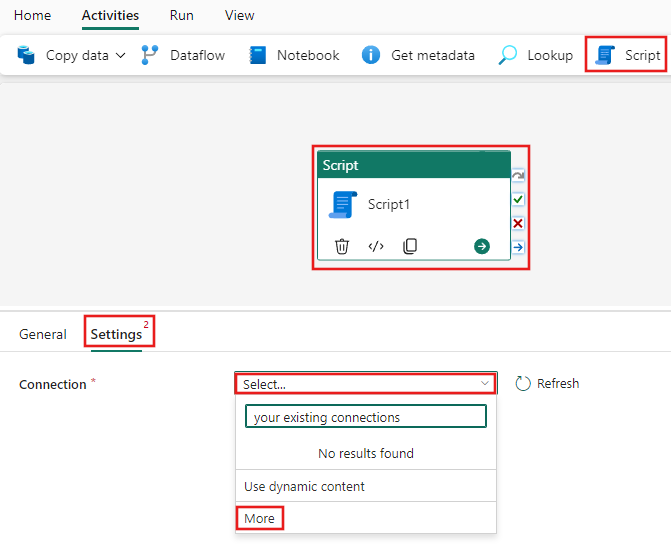
在“新建源”部分下,选择 Azure Synapse Analytics (SQL DW)。

为“基本身份验证”提供“服务器”、“数据库”和“用户名”和“密码”字段,并在“连接名称”中输入“SynapseConnection”。 然后,选择“创”以创建新连接。

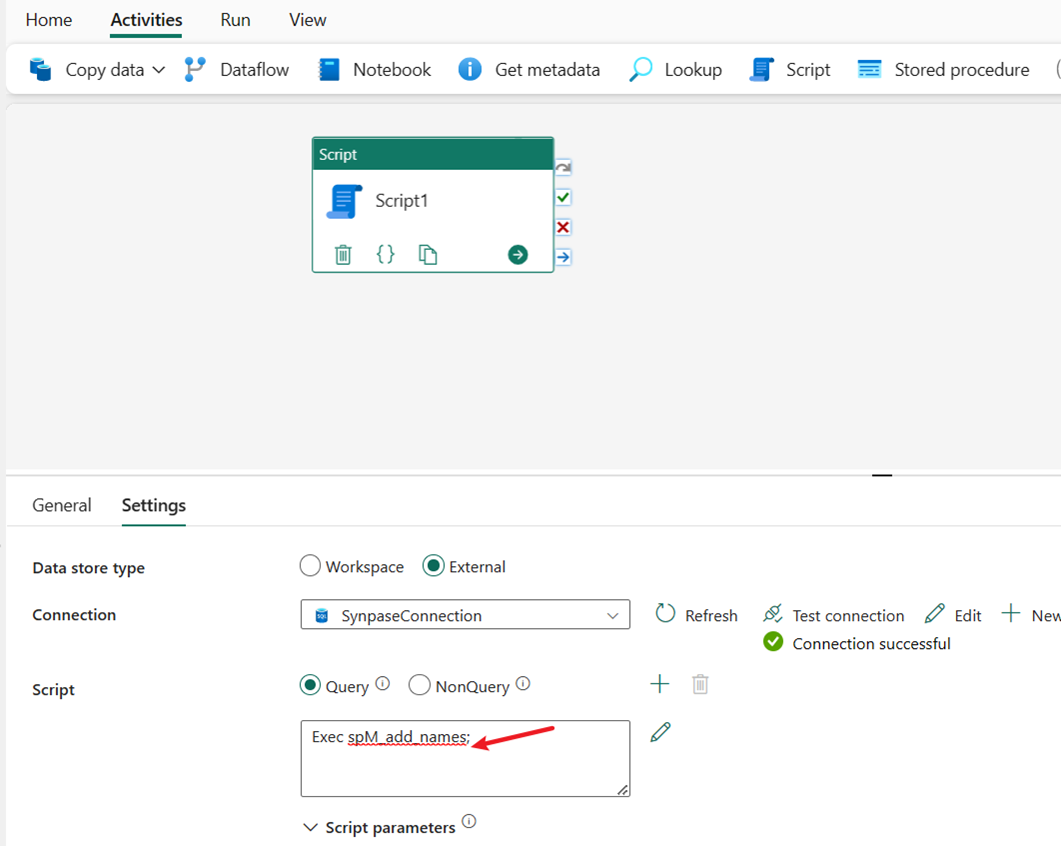
输入 EXEC spM_add_names 以运行存储过程。 这将会创建一个新表 dbo.name,并使用简单转换预处理数据,以便将 fullname 字段更改为两个字段,first_name 和 last_name。


使用管道活动将预处理的表数据加载到湖屋
从“活动”工具栏中选择“复制数据”,然后选择“使用复制助手”,或使用“管道登陆”页面上的“复制数据助手”,以启动“复制数据助手”。
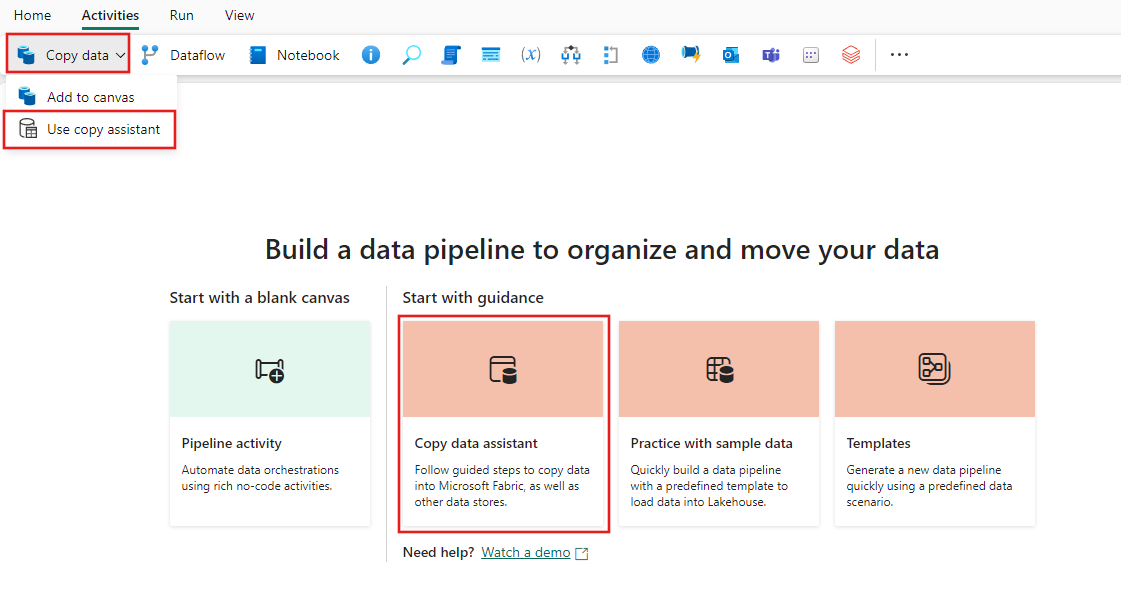
在搜索筛选器中输入 Synapse,并选择数据源的 Azure Synapse Analytics (SQL DW),然后选择“下一步”。

选择之前创建的现有连接 SynapseConnection。

选择存储过程创建和预处理的表 dbo.names。 然后,选择“下一步”。

选择“湖屋”。
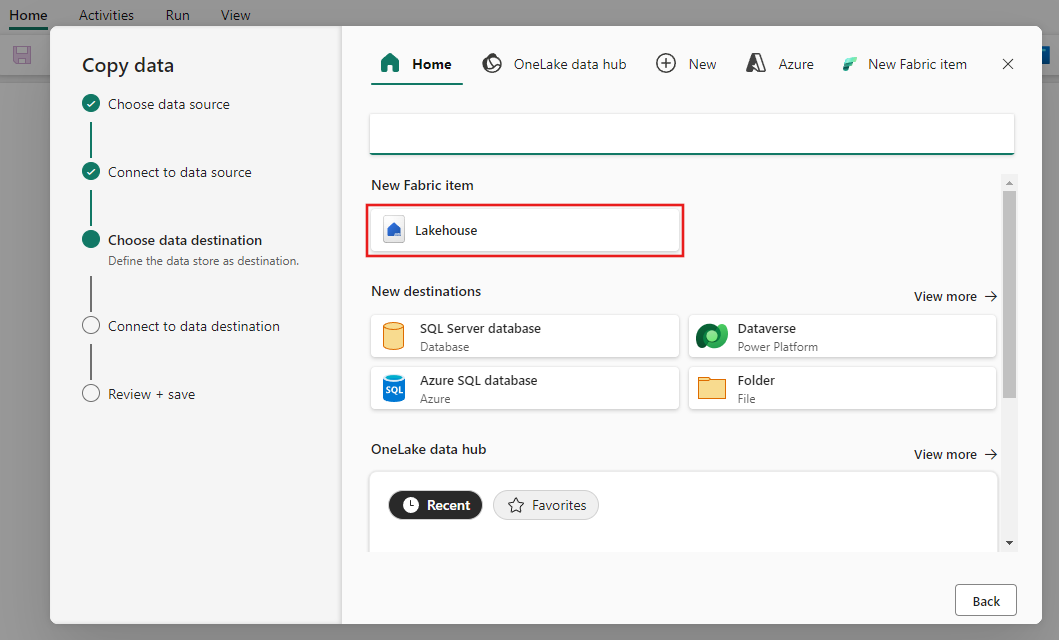
输入名称,然后选择“创建和连接”。
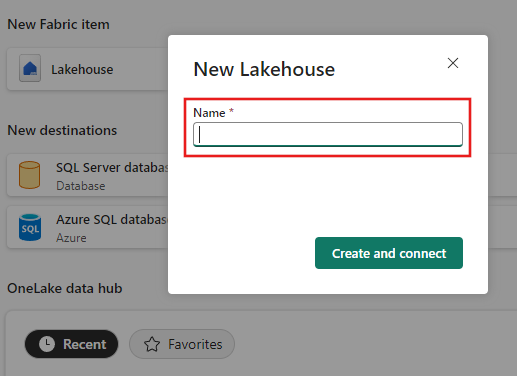
为要复制到湖屋目标的数据输入目标表名称,然后选择“下一步”。
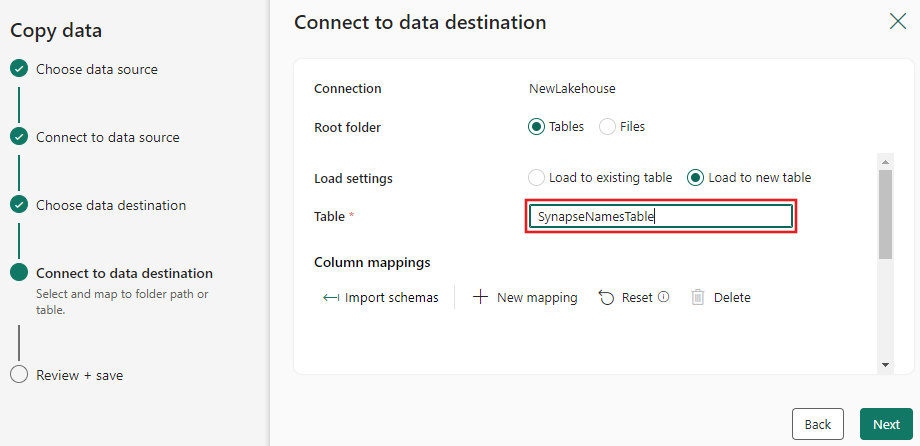
查看“复制助手”最后一页上的摘要。 取消选中“立即开始数据传输”复选框,然后选择“确定”。

选择“确定”后,新的复制活动将添加到管道画布上。
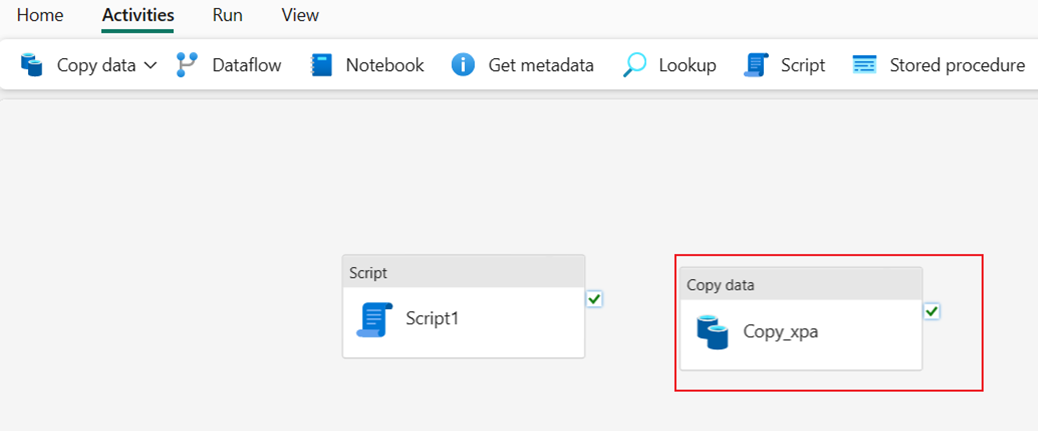




执行两个管道活动以加载数据
从脚本活动通过“成功时”连接脚本和复制数据活动。
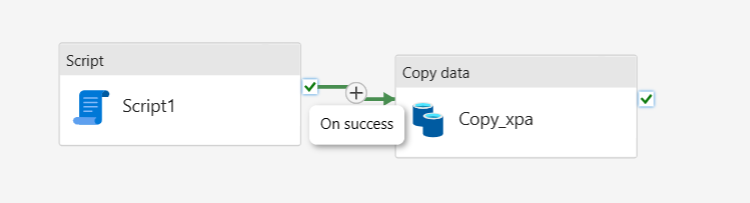
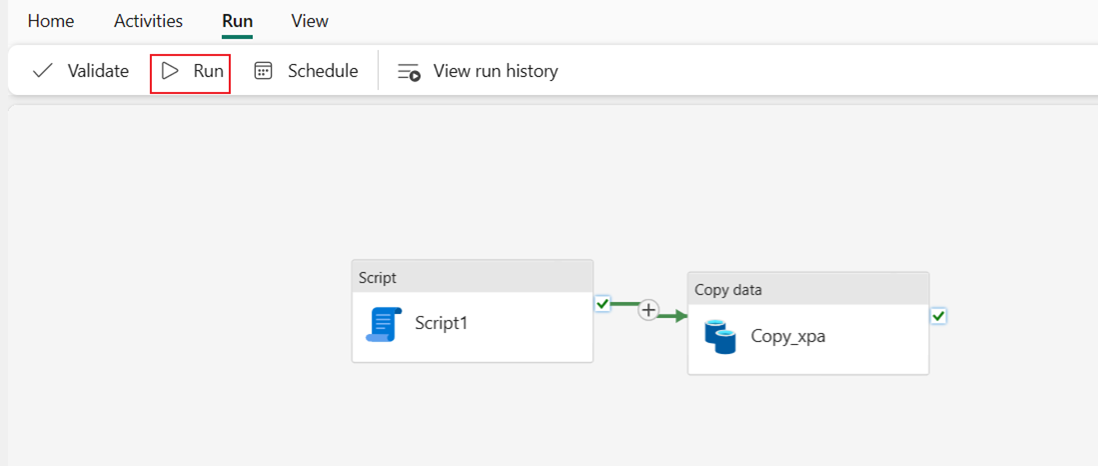
选择“运行”,然后选择“保存并运行”以运行管道中的两个活动。

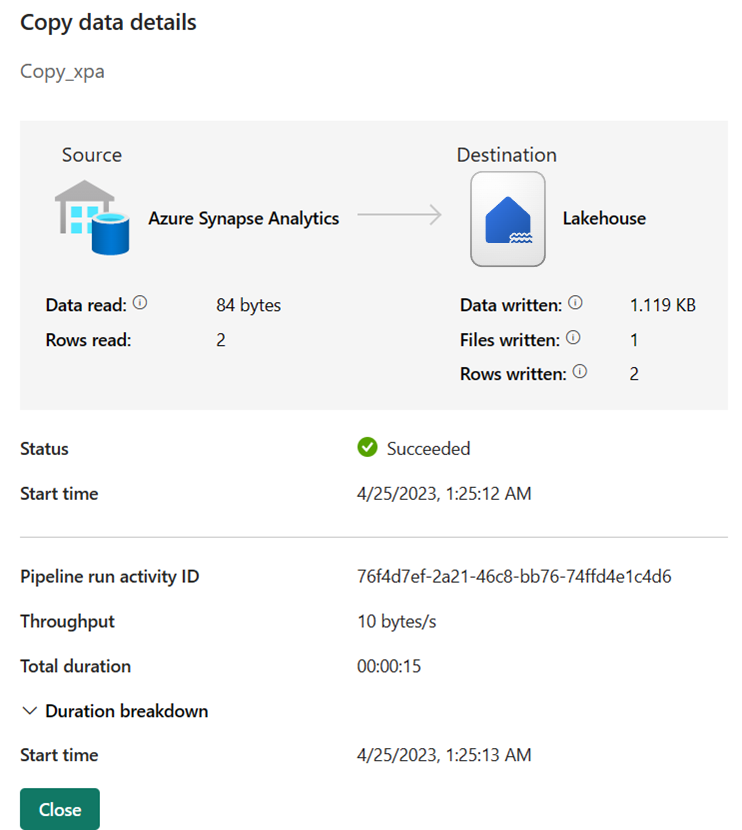
管道成功运行后,可以查看详细信息以获取详细信息。 选择包含复制活动名称的链接,以查看其运行详细信息。

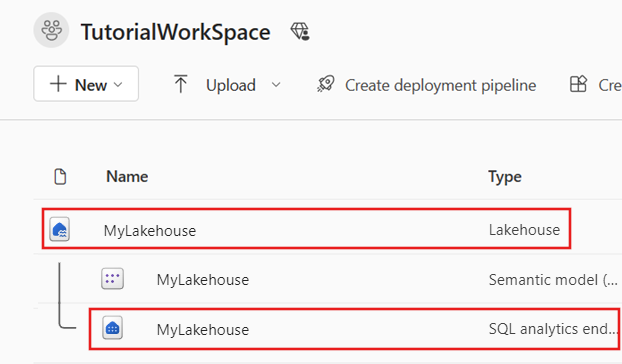
切换到工作区,然后找到创建的 Lakehouse。 选择其下方的“SQL 分析终结点”,以检查结果。
选择表 SynapseNamesTable 以查看加载到湖屋的数据。




相关内容
此示例演示如何在将结果加载到湖屋之前使用存储过程预处理数据。 你已了解如何执行以下操作:
- 创建包含脚本活动的数据管道,以运行存储过程。
- 使用管道活动将预处理的表数据加载到湖屋
- 执行管道活动以加载数据。
接下来,请继续了解有关监视管道运行的详细信息。
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈