将 OneLake 与 Azure Synapse Analytics 集成
Azure Synapse 是一项无限分析服务,集企业数据仓库和大数据分析于一体。 本教程演示如何使用 Azure Synapse Analytics 连接到 OneLake。
使用 Apache Spark 从 Synapse 写入数据
按照以下步骤使用 Apache Spark 将示例数据从 Azure Synapse Analytics 写入 OneLake。
打开 Synapse 工作区,并使用首选参数创建 Apache Spark 池。
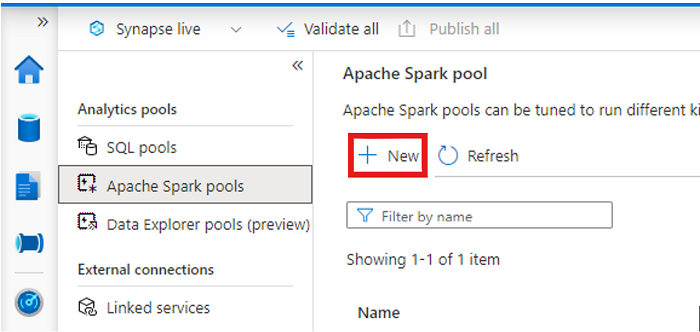
创建新的 Apache Spark 笔记本。
打开笔记本,将语言设置为“PySpark (Python)”,并将其连接到新创建的 Spark 池。
在单独的选项卡中,导航到 Microsoft Fabric Lakehouse 并找到顶级 Tables 文件夹。
右键单击“表”文件夹,然后选择“属性”。
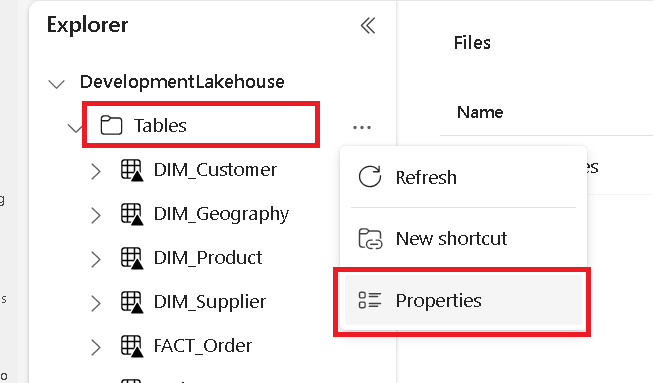
从“属性”窗格复制 ABFS 路径。
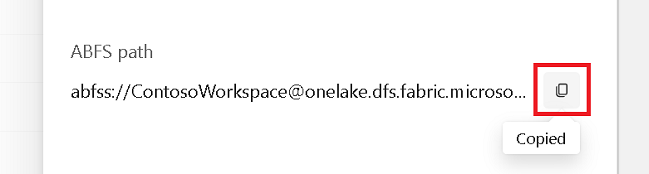
返回 Azure Synapse 笔记本中的第一个新代码单元中,提供 Lakehouse 路径。 此湖屋是稍后要将数据写入到的位置。 运行该单元。
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'在新的代码单元中,将数据从 Azure 开放数据集加载到数据帧中。 此数据集是要加载到湖屋中的数据集。 运行该单元。
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))在新代码单元中,筛选、转换或准备数据。 对于此方案,可以剪裁数据集以加快加载速度、与其他数据集联接或筛选到特定结果。 运行该单元。
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))在新的代码单元中,使用 OneLake 路径将筛选的数据帧写入 Fabric Lakehouse 中的新 Delta-Parquet 表。 运行该单元。
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')最后,在新的代码单元中,通过从 OneLake 读取新加载的文件来测试数据是否已成功写入。 运行该单元。
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
祝贺。 现在,可以使用 Azure Synapse Analytics 中的 Apache Spark 在 OneLake 中读取和写入数据。
使用 SQL 从 Synapse 读取数据
按照以下步骤使用 SQL 无服务器从 Azure Synapse Analytics 读取 OneLake 中的数据。
打开 Fabric Lakehouse,确定要从 Synapse 查询的表。
右键单击该表,然后选择“属性”。
复制表的 ABFS 路径。
在 Synapse Studio 中打开 Synapse 工作区。
创建一个新的 SQL 脚本。
在 SQL 查询编辑器中,输入以下查询,并将
ABFS_PATH_HERE替换为前面复制的路径。SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;运行查询以查看表的前 10 行。
祝贺。 现在可以在 Azure Synapse Analytics 中使用 SQL 无服务器从 OneLake 读取数据。