ESG 数据资产(预览)
![]() Microsoft Cloud for Sustainability
Microsoft Cloud for Sustainability
重要提示
此功能的部分或全部属于预览版内容。 相关内容和功能可能会发生更改。
ESG 数据资产(预览)功能允许您将各个来源的 ESG 数据组合到一个标准架构中,该架构为环境、社会和治理记录提供数据模型。 然后,您可以使用标准化数据来计算满足披露报告要求的定量指标,如企业可持续发展报告指令 (CSRD)。 您还可以在分析中使用聚合数据集。 外部应用程序可以访问其他场景的聚合数据集,如数据审核和 CSRD 报告生成。
此功能中部署的项目包括笔记本和数据湖,它们将数据从原始形式转换、计算和存储为基于标准化 ESG 数据模型的计算 ESG 指标。
此解决方案部署了这四个数据湖:
引入的原始数据:存储来自外部数据源的原始数据。
已处理的 ESG 数据:存储符合标准化 ESG 数据模型的协调数据。
计算的 ESG 指标:存储计算的 ESG 指标和聚合的分析数据集。
ConfigAndDemoData:存储某些转换库、参考和演示数据。
此解决方案部署的所有资源均已预先构建并部署到您的 Fabric 工作区中。 资源是开放的,您可以进行自定义来满足您的需求。
ESG 数据资产(预览)包括以下功能:
导入和转换 Sustainability Manager 数据
您可以将来自不同数据源的数据引入您的 ESG 数据资产。 此功能会在您的 Fabric 工作区部署 IngestedRawData lakehouse 或数据湖。 此 lakehouse 按原样存储源数据。
源数据与 IngestedRawData lakehouse 集成后,您可以将数据统一到 Microsoft Cloud for Sustainability ESG 数据模型架构并进行协调。
此功能还会将演示数据部署到您的 Fabric 工作区。 此演示数据存在于 ESG 数据模型架构中,因此您可以直接加载演示数据来探索此功能。
这些步骤向您展示如何集成 Sustainability Manager 中的排放、水和废料数据,并将其转换为 ESG 数据模型架构。 然后,您可以使用转换后的数据来计算分析数据集和指标。
先决条件
在 Fabric 工作区中部署 ESG 数据资产(预览)。
您应该在 Dataverse 环境中安装并设置 Microsoft Sustainability Manager。
您应该有 Azure Data Lake Storage Gen2 存储帐户。
您必须具有 Dataverse 系统管理员安全角色。
您必须有 Azure Data Lake Storage Gen2 帐户以及负责人和存储 Blob 数据参与者角色访问权限。 您的存储帐户必须为初始设置和增量同步启用分层命名空间。仅在初始设置时才需要允许存储帐户密钥访问。
第 1 步: 设置Azure Synapse Link
在此步骤中,您为 Sustainability Manager 环境设置一个 Azure Synapse Link,您希望从此环境将数据引入 ESG 数据资产。
打开 Power Apps 门户。 在右上角,选择安装了 Sustainability Manager 的 Dataverse 环境。
从左侧窗格中选择 Azure Synapse Link,然后选择新建链接。 如果它还未出现,选择更多,选择发现全部,选择数据管理,然后选择 Azure Synapse Link。
保持不选中连接到 Azure Synapse Analytics 工作区。 您在 Fabric(而不是 Synapse)上运行集成和转换脚本。
输入您的存储帐户和订阅详细信息,然后选择下一步。 您只能选择与环境位于同一位置的存储帐户。 例如,如果您的环境位于美国西部,您的存储帐户应位于美国西部或美国西部 2。
从列表中选择您的所有 Sustainability Manager 表,然后选择保存。 您可以按 msdyn_ 筛选来查看相关表。
将创建您的存储帐户的 Azure Synapse Link,选定的表将被导出到存储帐户。 您可以添加或删除链接中的表,方法是返回 Azure Synapse Link,选择您创建的链接,然后选择管理表。
打开在前面的步骤中创建链接时提供的 Data Lake Storage Gen2 帐户。 将在您的存储帐户中创建一个以 Dataverse- 开头的新容器,其中包含所有选定的使用文件夹结构以 CSV 格式导出的表,以及包含所有表的架构的 model.json 文件。 您的 Sustainability Manager 数据现在已在您自己的存储帐户中可用。
步骤 2:链接 Data Lake Storage 容器
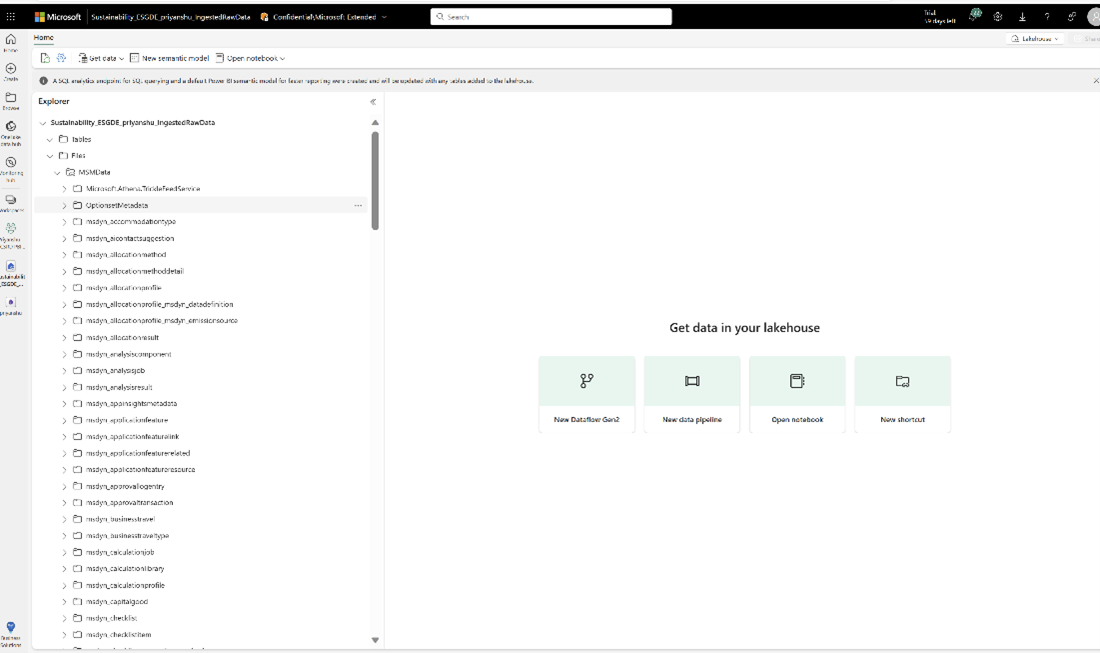
在此步骤中,您使用 Fabric 快捷方式功能将具有 Sustainability Manager 数据的 Data Lake Storage 容器链接到已部署功能的 IngestedRawData lakehouse。
打开 Fabric 中您部署可持续发展解决方案的工作区。 要打开解决方案,从列表视图中选择该解决方案。 从管理已部署功能列表视图中选择 ESG 数据资产(预览)功能,进入托管功能页面。
从 ESG 数据资产托管功能页面,选择 IngestedRawData lakehouse。
从文件省略号菜单中选择新建快捷方式。 在新建快捷方式对话框中,选择 Azure Data Lake Storage Gen2 磁贴,然后提供以下连接详细信息以连接到具有导出的 Sustainability Manager 数据的 Data Lake Storage 容器。
- URL:转到 Data Lake Storage 帐户,从左侧边栏选项卡中选择终结点。 然后复制 Data Lake Storage 的终结点,将其粘贴到 URL 字段中。
- 连接:选择创建新连接。
- 身份验证类型:选择组织帐户,登录您的 Data Lake Storage 帐户,然后选择下一步。
为快捷方式名称输入 MSMData,将子路径设置为包含前缀为 / 的 Sustainability Manager 数据的容器名称,然后选择创建。 Sustainability Manager 数据将成功与文件下的数据湖集成。

步骤 3:转换数据
Sustainability Manager 数据与 IngestedRawData lakehouse 集成后,通过将数据转换为 ESG 数据模型架构来统一和协调数据。 在部署过程中,将在工作区中创建 ProcessedESGData lakehouse,用于存储协调后的数据。
ESG 数据模型架构覆盖 ESG 数据实体。 它们会链接到描述公司其他功能区域(如人力资源、IT 或财务生产)的其他数据实体。
为了将 Sustainability Manager 数据转换为 Cloud for Sustainability ESG 数据模型架构,此功能提供了使用预构建转换技术的笔记本,其以存储在您的工作区的 ConfigAndDemoData lakehouse 中的库的形式提供。
重要提示
不要更改 ConfigAndDemoData 文件夹中的任何文件,因为 Sustainability Manager 数据的转换逻辑可能不起作用。
作为表加载链接的 Sustainability Manager 数据。 转换库需要源数据采用增量表格式。 您可以运行 LoadMSMDataToIngestedRawDataLakehouseTables 笔记本。 此笔记本将链接的 Sustainability Manager 数据加载到 lakehouse 表中。 成功运行笔记本后,您可以验证 IngestedRawData lakehouse 表中的数据。
在 ProcessedESGData lakehouse 表中加载参考数据。 参考数据是指主要为静态的表,如度量单位或国家/地区。
目前,ESG 数据模型架构中的 Sustainability Manager 参考数据作为 ESG 数据资产功能的一部分部署。 您可以从 ConfigAndDemoData lakehouse 中的参考数据文件夹查看参考数据文件。 运行 LoadReferenceTables 笔记本将参考数据加载到 ProcessedESGData lakehouse 表。
将 Sustainability Manager 数据转换为 Cloud for Sustainability ESG 数据模型架构。
按顺序运行以下笔记本。
备注
仅当第一个笔记本成功运行时,才应运行第二个笔记本。
- TransformMSMDataToProcessedESGDataStage1
- TransformMSMDataToProcessedESGDataStage2
备注
此预览版本仅支持 Sustainability Manager 数据的完全快照刷新,不支持增量数据刷新。 部署有此功能的预构建转换笔记本也仅支持完全快照刷新。 我们建议 Azure Synapse link 保持为就地更新模式。 如果您将其他数据更新到上一步中笔记本填充的表,然后运行,数据将被覆盖。 另外,不要修改转换笔记本和基础库的内容。 如果笔记本或基础库被修改,Sustainability Manager 数据到 ESG 数据模型架构的转换可能无法正常工作。
外部数据引入和转换
您可以使用 Fabric 引入功能(如数据管道和数据流)将来自不同来源的数据集成到 IngestedRawData lakehouse 中。
集成数据后,您可以使用 Fabric 数据流将其转换为 ESG 数据模型架构,或构建和运行笔记本。
在构建转换逻辑之前,您可以使用这些项目探索 ESG 数据模型架构,这些项目在 ESG 数据资产部署期间部署在工作区中。
ESGschema.json:此文件提供 Cloud for Sustainability ESG 数据模型中表的架构,包括每个表的列、主键和外键关系的详细信息。 此文件存储在 ConfigAndDemoData lakehouse 的配置文件夹中。
GenerateESGTables:此笔记本提供创建表功能。 您可以使用此表为某个可持续发展方面(如水、废料和温室气体 (GHG) 排放)创建空的 Cloud for Sustainability ESG 数据模型表。
按照以下步骤将 GHG 排放、水量或废料生成的数据转换为 Cloud for Sustainability ESG 数据模型架构。 然后,您可以生成预构建指标生成笔记本支持的指标。
确保您的源数据适用于 ConfigAndDemoData lakehouse 的参考数据文件夹中的参考数据(静态数据,如度量单位、国家/地区或用水类型)。 用于生成分析数据集和指标的预构建笔记本使用参考数据中的值。
将您的源数据映射到以下一组 Cloud for Sustainability ESG 数据模型表。 在此步骤中,您使用 Fabric 功能(如数据流),或构建和运行笔记本。 然后使用 TransformMSMDataToProcessedESGDataStage2 笔记本将数据进一步转换为 Cloud for Sustainability ESG 数据模型表。
方面 表 水能 资产计算算法设施法人位置参与方参与方业务指标参与方组织相关方标准标准版本水风险用水原始数据导入 废物 资产计算算法设施法人位置参与方参与方业务指标参与方组织相关方标准标准版本废料类别废料材料类型废料流 GHG 排放 资产计算算法设施温室气体排放系数法人位置参与方参与方业务指标参与方组织相关方标准标准版本排放原始数据导入 要将社会数据转换为 ESG 数据模型架构,您使用数据流等 Fabric 功能或构建并运行笔记本。 要使用预构建的笔记本生成社会数据的分析数据集和指标,将源数据映射到 Cloud for Sustainability ESG 数据模型架构中的这些表。
方面 表 社交 事件事件类型事件相关方参与方参与方类型参与方业务指标指标用途业务指标参与方参与方类型员工相关方员工性别员工位置位置国家/地区参与方健康安全培训指标健康安全培训指标类型指标用途事件类型参与方类型 此列表可帮助您计算功能中预定义的指标。 如果您想要计算其他指标,您可能需要将其他表映射到 ESG 数据模型架构。 您可以探索 ESG 数据模型架构来找出要映射的其他表。
计算分析数据集和指标
标准化数据后,您可以创建一个 ESG 指标网格,其中包含聚合数据集和计算的 CSRD 指标,可用于分析和报告。 在此预览版本中,跨 ESG 的某些 CSRD 定量指标的计算逻辑是预定义的,并提供 ESG 数据资产功能。 您可以根据需要扩展和更新这些笔记本,来定义其他指标和修改已定义指标的计算逻辑。
备注
聚合数据集是非规范化的聚合数据集,其中包含沿各个维度(如报告年份、设施、国家/地区或部门)存储的实际信息。 在此预览版本中,报告年份定义仅支持日历年份。
先决条件
确保您的数据已转换为您想要计算分析数据集和 CSRD 指标的可持续发展各方面的 ESG 数据模型架构。 如果您想要探索此功能,还可以将演示数据加载到 ProcessedESGData lakehouse,使用它来计算指标。
GHG 排放
运行 CreateEmissionFactTables 笔记本。 此笔记本将 Cloud for Sustainability ESG 数据模型架构中已处理的排放数据聚合为聚合数据集,并将它们作为 parquet 文件存储在 compulatedESGMetrics lakehouse 中。 笔记本成功运行后,EmissionsData 和 NetRevenueData 事实表应出现在 ComputedESGMetrics lakehouse 中文件下的 ESG 事实表文件夹中。
运行 GenerateEmissionsMetricTables 笔记本。 此笔记本从 GHG 排放的聚合数据集生成定量指标,这些数据集是 CSRD 的欧洲可持续性报告标准 (ESRS) E1 标准的一部分。 笔记本成功运行后,计算的指标数据将作为表存储在 ComputedESGMetrics lakehouse 中。
此笔记本计算以下指标:
- 范围 1 GHG 总排放量 (E1_6_41_a)
- 范围 2 GHG 总排放量 (E1_6_41_b)
- 范围 3 GHG 总排放量 (E1_6_41_c)
- 总 GHG 排放量 (E1_6_41_d)
- 每净收入总 GHG 排放量 (E1_6_50)
- 净收入 (E1_6_52)
水能
运行 CreateWaterFactTables 笔记本。 此笔记本将 Cloud for Sustainability ESG 数据模型架构中已处理的用水量数据聚合为聚合数据集,并将它们作为 parquet 文件存储在 compulatedESGMetrics lakehouse 中。 笔记本成功运行后,WaterUtilizationData 和 NetRevenueData 数据集应出现在 ComputedESGMetrics lakehouse 中文件下的 ESG 事实表文件夹中。
运行 GenerateWaterMetricTables 笔记本。 此笔记本从水可持续性方面的聚合数据集生成定量指标,这些数据集是 CSRD 的 ESRS E3 标准的一部分。 笔记本成功运行后,计算的指标数据将作为表存储在 ComputedESGMetrics lakehouse 中。
此笔记本计算以下指标:
- 总耗水量 (E3_4_1_a)
- 重大水风险部分的总用水量 (E3_4_1_b)
- 总回收水量 (E3_4_2_a)
- 用水量收入强度 (E3_4_3)
废物
运行 CreateWasteFactTables 笔记本。 此笔记本将 Cloud for Sustainability ESG 数据模型架构中已处理的废料数据聚合为聚合数据集,并将它们作为 parquet 文件存储在 compulatedESGMetrics lakehouse 中。 笔记本成功运行后,TotalWasteGeneratedData 数据集应出现在 ComputedESGMetrics lakehouse 中文件下的 ESG 事实表文件夹中。
运行 GenerateWasteMetricTables 笔记本。 此笔记本从废料可持续性方面的聚合数据集生成定量指标,这些数据集是 CSRD 的 ESRS E5 标准的一部分。 笔记本成功运行后,计算的指标数据将作为表存储在 ComputedESGMetrics lakehouse 中。
此笔记本计算以下指标:
- 产生的废料总量 (E5_5_3_a)
- 废料(按数据流) (E5_5_4_a)
- 危险废料和放射性废料总量 (E5_5_5)
- 不可回收废料总量 (E_5_3_d)
社会和治理
运行 CreateSocialGovernanceFactTables 笔记本。 此笔记本将 Cloud for Sustainability ESG 数据模型架构中已处理的社会数据聚合为事实表,并将它们作为 parquet 文件存储在 compulatedESGMetrics lakehouse 中。 笔记本成功运行后,将在 ComputedESGMetrics lakehouse 中文件下的 ESG 事实表文件夹中创建所需的聚合数据集。
运行 GenerateSocialGovernanceMetricTables 笔记本。 此笔记本从社会和治理可持续性方面的聚合数据集生成定量指标,这些数据集是 CSRD 的 ESRS 2 和 ESRS S1 标准的一部分。 笔记本成功运行后,计算的指标数据将作为表存储在 ComputedESGMetrics lakehouse 中。
此笔记本计算以下指标:
- 董事会的性别多样性 (ESRS2_GOV_1_19_d)
- 独立董事会成员百分比 (ESRS2_GOV_1_19_e)
- 死亡人数 (S1_14_84_b)
- 工伤事故发生率 (S1_14_84_c)
- 因受伤、事故、死亡或疾病而损失的天数 (S1_14_84_e)
- 性别工资差距 (S1_16_92_a)
- CEO 薪酬比例过高 (S1_16_92_b)
- 歧视事件 (S1_17_98_a)
- 违反联合国全球契约 (UNGC) 原则和 OECD (S1_17_99_a)
- 参与定期绩效和职业发展评审的员工百分比 (S1_13_80_a)
- 员工每人平均培训时数 (S1_13_80_b)
- 员工总数 (S1_6_51_a)
备注
此预览版本仅支持 Sustainability Manager 数据的完全快照刷新,不支持增量数据刷新。 部署有此功能的预构建转换笔记本也仅支持完全快照刷新。 此外,如果您将其他数据更新到这些笔记本填充的表,然后运行,数据将被覆盖。
可视化数据和分析
计算指标并将其存储为表后,您可以使用预构建的 Power BI 仪表板来探索 CSRD 指标、执行向下钻取或查看较上年同期比较。 这些操作可帮助您验证数据是否可用于报告。
从您的工作区或 ESG 数据资产功能详细信息页面打开 CSRDMetricsReportDataset 语义模型。
在左上角,选择您的文件,然后选择设置。 在数据源凭据部分,选择编辑凭据。
在对话框中提供您的 Fabric 凭据,来验证 ComputedESGMetrics lakehouse 数据源。 选择以下值:
- 身份验证方法:OAuth2
- 此数据源的隐私级别设置:组织
选择登录。
成功登录后,返回语义模型主页,从刷新菜单选项选择立即刷新。 刷新完成后,数据集将使用 ComputedESGMetrics lakehouse 中的数据刷新。
如果刷新出现错误,您可以通过查看刷新菜单下的刷新历史记录选项来查找错误详细信息。
从 ESG 数据资产功能页面或您的工作区打开 CSRDMetricsReport。 此报告应包含各个选项卡,如排放、废料、废料和社会。
备注
将仅为 CompulatedESGMetrics lakehouse 中具有数据的指标显示数据。
发布下游应用程序消耗的指标数据
您可以筛选、聚合 ComputedESGMetrics lakehouse 表中的指标数据,并将所需的子集或指标提取发布为 JSON 文件。 然后,下游应用程序可以访问这些指标提取以用于各个场景,如 ESG 数据审核和使用 Microsoft OneLake API 生成 CSRD 报告。 例如,合规性管理器可以访问它们来审核 CSRD 披露的指标。
先决条件:对于此步骤,确保指标数据在 ComputedESGMetrics lakehouse 中作为表提供。
作为功能部署的一部分,这些笔记本可在您的工作区中用于生成指标提取以及此功能支持的预构建指标所需的元数据:
CreateEmissionsMetricsForSpecificReportingYear_INTB:运行此笔记本以生成预构建 GHG 排放指标的指标提取和元数据。 指定筛选指定年份的指标数据的报告年份,并指定聚合指定部门的指标数据的部门。
要指定部门,您需要提供 PartyOrganizationPartyId。 您可以从在 CompulatedESGMetrics lakehouse 的文件部分创建的 PartyOrganizationData 数据集访问此信息,同时计算 GHG 排放方面的其他聚合数据集。 此数据集存储部门名称和 PartyOrganizationPartyId 映射。
CreateWaterMetricsForSpecificReportingYear_INTB:运行此笔记本以生成预构建水指标的指标提取和元数据。 此笔记本筛选并发布特定报告年份的水指标提取。
CreateWasteMetricsForSpecificReportingYear notebook_INTB:运行此笔记本以生成预构建废料指标的指标提取和元数据。 此笔记本筛选并发布特定报告年份的水指标提取。
CreateSocialGovernanceMetricsForSpecificReportingYear_INTB:运行此笔记本以生成预构建社会和治理指标的指标提取和元数据。 此笔记本筛选并发布特定报告年份的社会和治理指标提取。
备注
在此预览版本中,报告年份定义仅支持日历年份。 此外,默认情况下,指标提取会作为比较年份数据筛选指定报告年份和两个之前报告年份的数据。 metadata.json 文件是一个单个元数据文件,其中包含所有指标提取的元数据。 元数据文件捕获通过连接器根据合规性管理器的 CSRD 评估中的披露要求(或改进操作)访问和映射指示数据所需的详细信息。 元数据文件捕获每个指标提取的以下详细信息。
| 元数据 | 说明 |
|---|---|
| 列 | 列名称与列显示名称的映射。 |
| disclosureRequirements | 将指标提取映射到合规性管理器中 CSRD 模板(预览)中的披露要求或改进操作名称。 如果需要根据改进操作更新某一指标提取的数据,您可以将多个改进操作映射到该指标提取。 |
| generatedTimestamp | 生成指标提取的时间戳。 |
| metricExtractDataPath | 报告年份文件夹中指标提取文件的文件路径。 |
| metricExtractName | 指标提取文件的名称。 |
要为自定义指标生成指标提取,请执行以下步骤:
确保生成指标数据并将其作为表存储在 computedESGMetrics lakehouse 中。
按照预构建笔记本中指定的模式(如 CreateEmissionsMetricsForSpecificReportingYear_INTB 或 CreateWaterMetricsForSpecificReportingYear_INTB)生成指标提取 JSON 文件,并将指标提取的元数据添加到 metadata.json 文件中。
要将指标提取映射到 CSRD 披露要求,转到合规性管理器中的 CSRD 模板(预览),从 CSRD 模板映射相关的有效改进操作名称。
生成指标提取后,执行以下步骤,允许通过合规性管理器审核 CSRD 披露的指标数据:
在 Purview 中创建可持续发展数据解决方案(预览)连接器实例。 连接器实例通过 OneLake API 从 Microsoft Fabric 中的可持续发展数据解决方案(预览)的 lakehouse 拉取指标数据。
在合规性管理器中创建 CSRD 评估。 将连接器实例链接到评估,以使用连接器实例从 Fabric 中的可持续发展数据解决方案(预览)中拉取的指标提取数据更新披露要求(改进操作)。