创建 HDInsight 群集
创建 HDInsight 群集有多种方法,从使用 Azure 门户实现简便的用户界面,到使用脚本设置帮助进行自动部署。 下表显示了可用于设置 HDInsight 群集的各种方法。
| 群集创建方法 | Web 浏览器 | 命令行 | REST API | SDK |
|---|---|---|---|---|
| Azure 门户 | ✔ | |||
| Azure 数据工厂 | ✔ | ✔ | ✔ | ✔ |
| Azure CLI | ✔ | |||
| Azure PowerShell | ✔ | |||
| cURL | ✔ | ✔ | ||
| .NET SDK | ✔ | |||
| Azure 资源管理器模板 | ✔ |
所有 HDInsight 设置都需要以下基本信息,其中包括:
“基本信息”选项卡
项目详细信息
订阅
根据将对 HDInsight 进行的计费和管理定义 Azure 订阅。
资源组名称
资源组是通常与同一应用程序或应用程序生命周期相关的 Azure 技术和服务的逻辑分组。 在相同资源组中对服务进行分组可以简化管理维护。
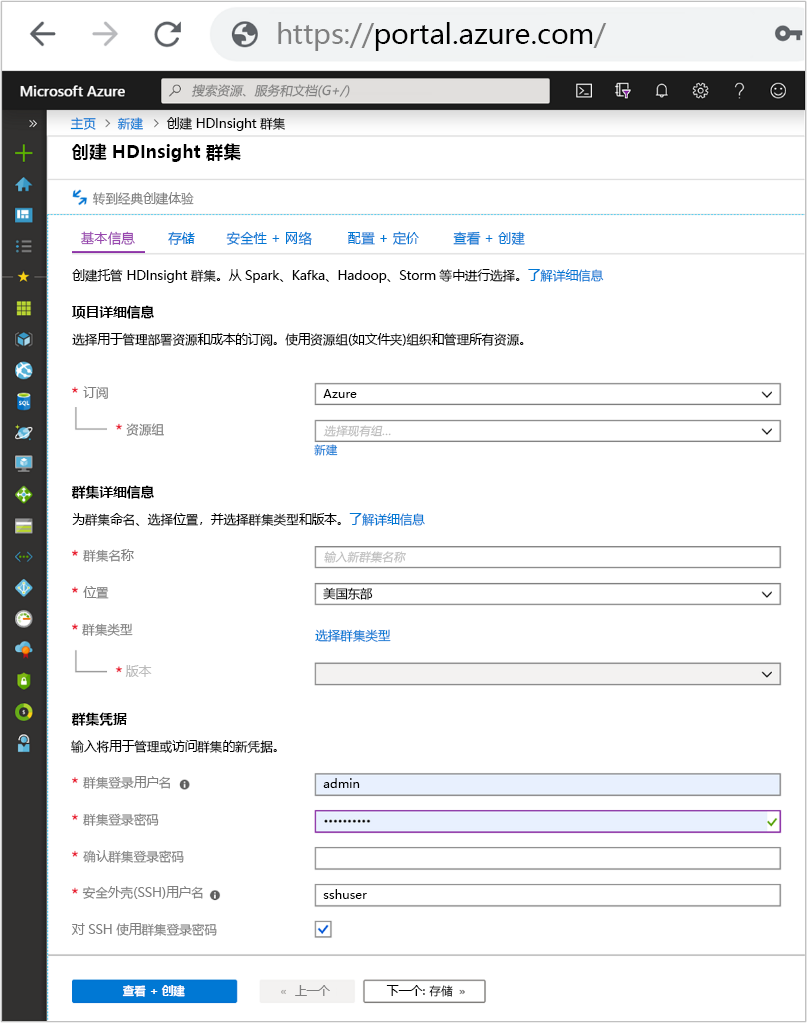
群集详细信息
群集名称
HDInsight 群集名称具有以下限制:
- 允许的字符:a-z、0-9、A-Z
- 最大长度:59
- 保留的名称:apps
- 群集命名范围适用于所有订阅中的所有 Azure。 因此,群集名称在全球范围内必须是唯一的。
- 前六个字符在 VNET 中必须是唯一的
位置
指定群集类型的存储位置。 如果未定义任何位置,则群集与默认存储并置于同一位置。 此位置应尽可能接近用户,以减少延迟。
群集类型
定义在资源群集上预配的技术堆栈。 根据所拥有的数据类型和方案所需的处理类型选择群集类型。 下表中显示了可用的群集类型。
| 群集类型 | 说明 |
|---|---|
| Apache Hadoop | 一个框架,使用 HDFS 和简单的 MapReduce 编程模型处理和分析批处理数据。 |
| Apache Spark | 一种开放源代码并行处理框架,支持使用内存中处理来提升大数据分析应用程序的性能。 |
| HBase | 基于 Hadoop 上的 NoSQL 数据库构建,为大量非结构化和半结构化数据(可能为数十亿行乘以数百万列)提供随机访问和高度一致性。 |
| Apache Interactive Query | 更快的交互式 Hive 查询的内存中缓存。 |
| Apache Kafka | 一种开源平台,用于生成流式处理的数据管道和应用程序。 Kafka 还提供了消息队列功能,允许用户发布和订阅数据流。 |
版本
定义此群集的 HDInsight 版本。 HDInsight 4.0 是最新的版本,它为群集提供了最新的框架。
群集凭据
使用 HDInsight 群集时,可以在群集创建期间配置两个用户帐户。
群集登录名和密码
默认的用户名为 admin。它使用 Azure 门户上的基本配置。 有时称为“群集用户”。
SSH 用户名和密码
用于通过 SSH 连接到群集。
注意
企业安全数据包允许将 HDInsight 与 Active Directory 和 Apache Ranger 集成。 可使用企业安全数据包创建多个用户。
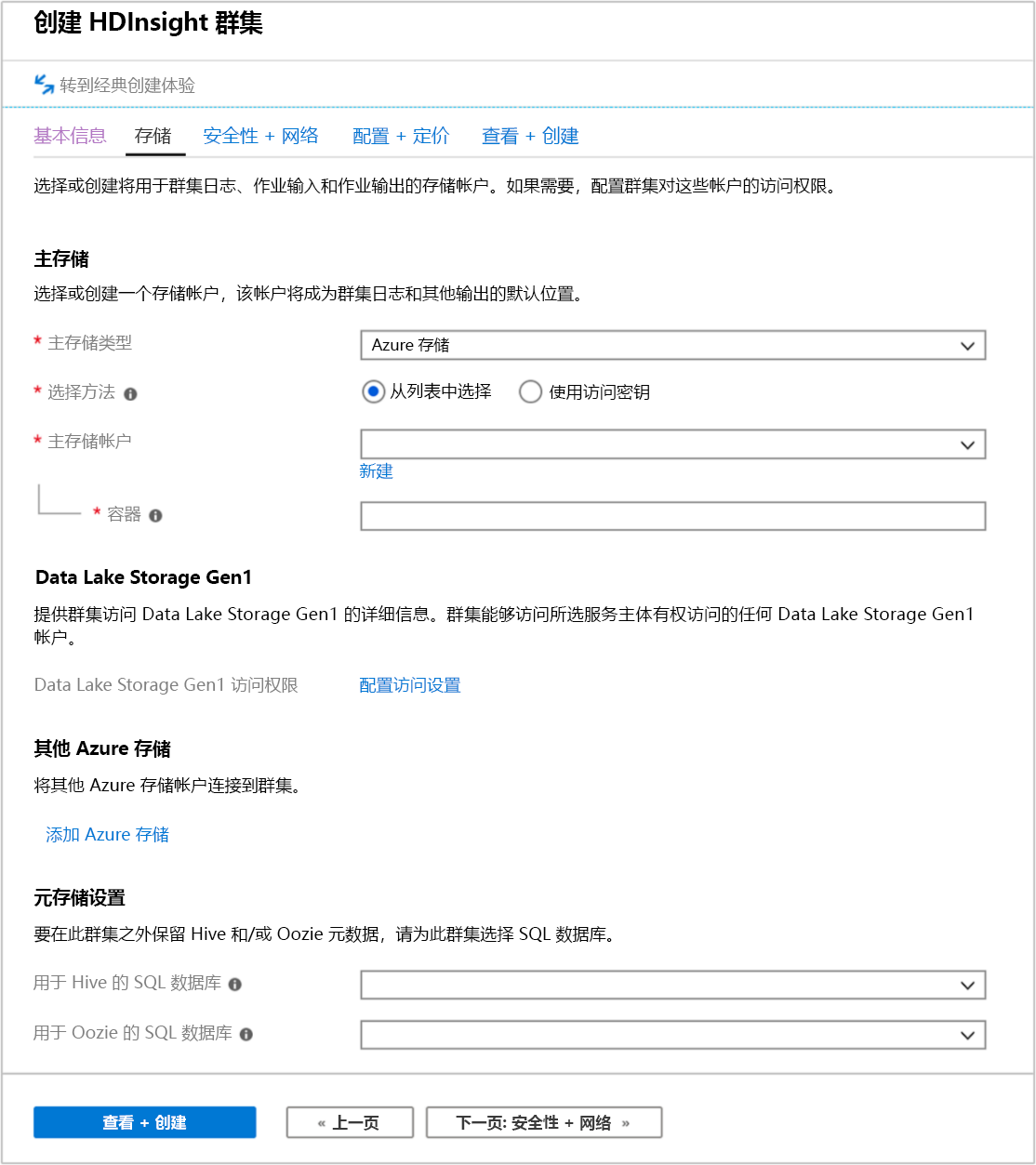
存储选项卡
HDInsight 群集可以使用存储屏幕中显示的以下存储选项:
- Azure Data Lake Storage Gen2
- Azure Data Lake Storage Gen1
- Azure 存储常规用途 v2
- Azure 存储常规用途 v1
- Azure 存储块 blob(仅支持作为辅助存储)
存储屏幕允许你定义主存储帐户和默认容器。 还可以将其他 Azure 存储链接到群集。 在删除群集之后,可以通过元存储设置定义外部 SQL 数据库来存储 Hive 表,并通过在外部存储中存储元数据来提高 Oozie 的性能。
安全性和网络
对于 Hadoop、Spark、HBase、Kafka 和 Interactive Query 群集类型,可选择启用“企业安全性套餐”。 启用此套餐,可通过使用 Apache Ranger 并与 Microsoft Entra ID 集成来实现更安全的群集设置。
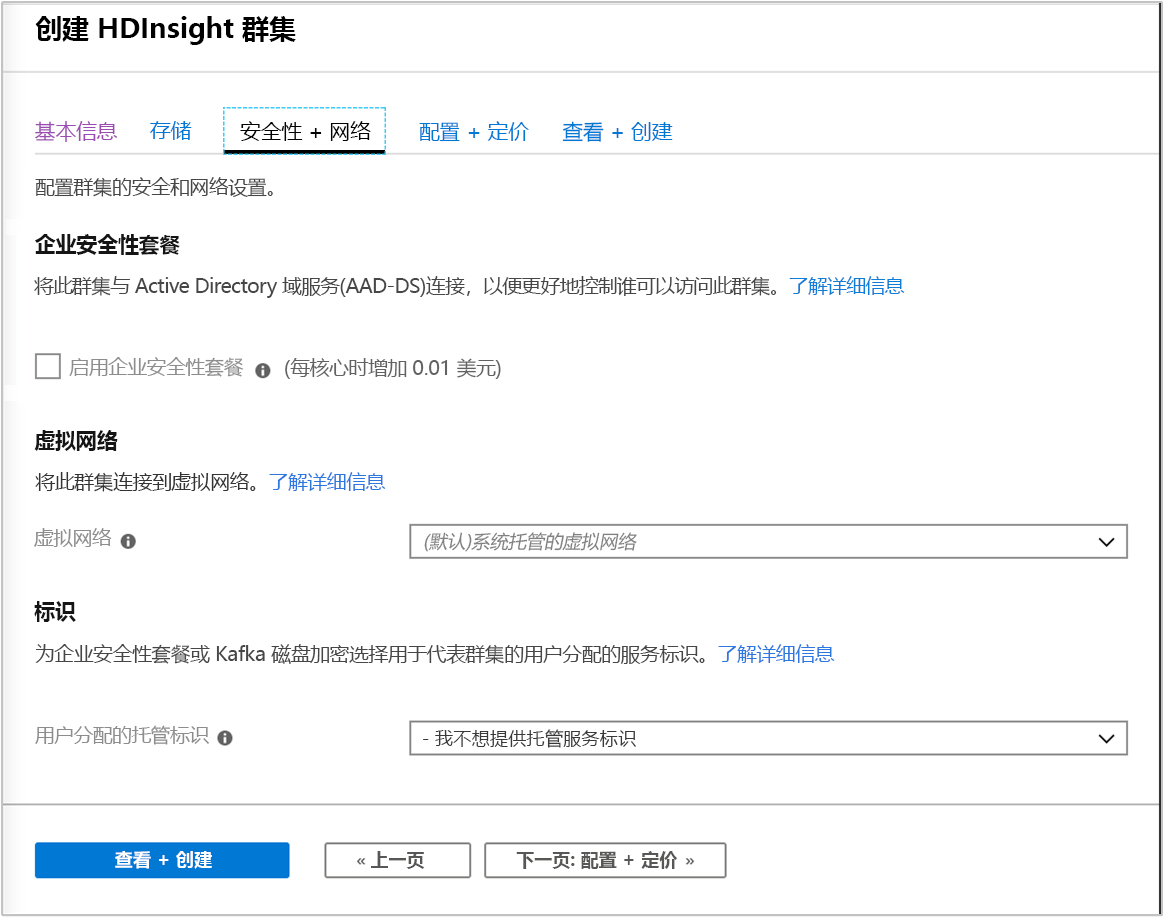
此外,始终建议在 VNet 中部署 HDInsight 群集,你可以在此屏幕中定义和设置虚拟网络。 如果解决方案需要分布在多种 HDInsight 群集类型上的技术,Azure 虚拟网络可以连接所需的群集类型。 此配置允许群集以及部署到群集的任何代码直接相互通信。
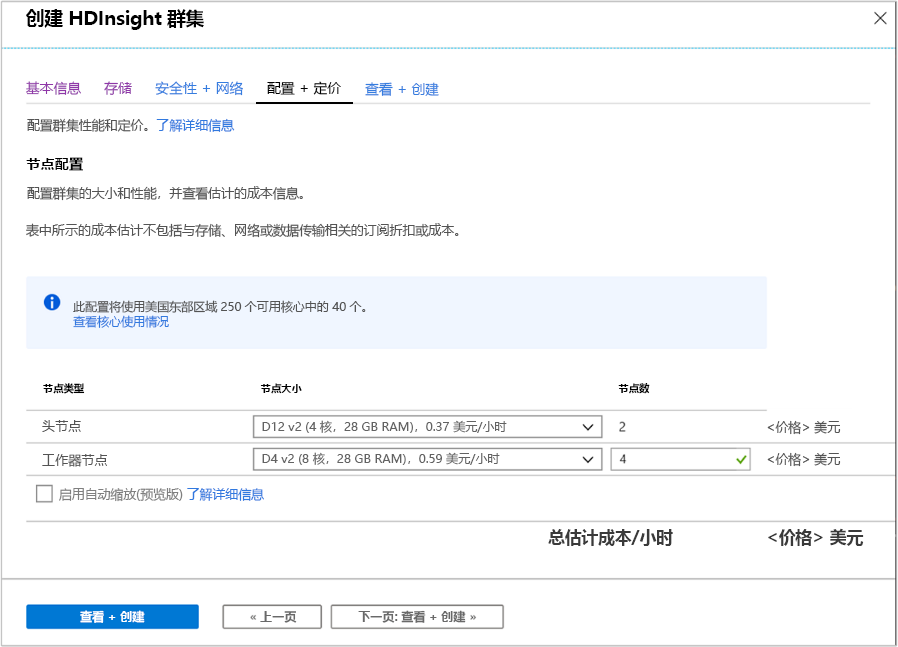
配置和定价
此页使你可以配置群集的大小和性能,并查看估计的成本信息。 在此屏幕中,你可以定义将用于头节点(主节点)和工作器节点的虚拟机。