练习 - 在 HDInsight Spark 群集上执行查询
本练习介绍如何从 csv 文件创建数据帧,以及如何针对 Azure HDInsight 中的 Apache Spark 群集运行交互式 Spark SQL 查询。 在 Spark 中,数据帧是已组织成命名列的分布式数据集合。 数据帧在概念上相当于关系型数据库中的表,或 R/Python 中的数据帧。
本教程介绍如何执行下列操作:
- 从 csv 文件创建数据帧
- 对数据帧运行查询
从 csv 文件创建数据帧
以下示例 csv 文件包含建筑物的温度信息,并存储在 Spark 群集的文件系统中。
在 Jupyter 笔记本的空单元格中粘贴以下代码,然后按 Shift + Enter 运行这些代码。 这些代码会导入此方案所需的类型
from pyspark.sql import * from pyspark.sql. types import *在 Jupyter 中运行交互式查询时,Web 浏览器窗口或选项卡标题中会显示“(繁忙)”状态和笔记本标题。 右上角“PySpark”文本的旁边还会出现一个实心圆。 作业完成后,实心圆将变成空心圆。
运行以下代码,创建数据帧和临时表 (hvac)。
# Create a dataframe and table from sample data csvFile = spark.read.csv ('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write. saveAsTable("hvac")
对数据帧运行查询
创建表后,可以针对数据运行交互式查询。
在 Notebook 的空单元格中运行以下代码:
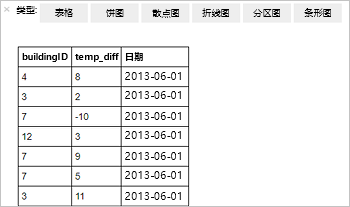
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"以下表格输出随即显示。
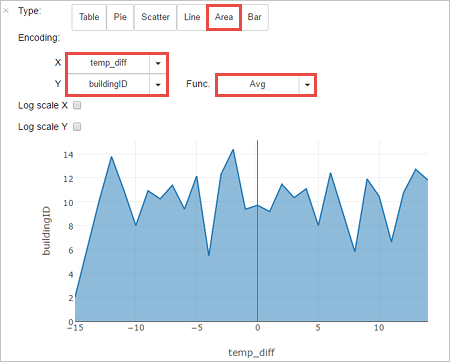
也可以在其他视觉效果中查看结果。 若要查看相同输出的面积图,请选择“面积” ,然后设置其他值,如下所示。
从笔记本菜单栏中,导航到“文件”“保存和检查点”。
请关闭笔记本以释放群集资源:从笔记本菜单栏,导航到“文件”“关闭并停止”。