HDInsight 配置选项
HDInsight 中嵌入了各种 OSS 技术,这些技术可用于处理 Lambda 体系结构中所定义的流数据和批数据方案。 此体系结构模型中存在数据的热路径和数据的冷路径。 数据的热路径由设备、传感器或应用程序实时生成,且数据分析近乎实时执行,这常称为流数据。 冷数据路径是指成批移动数据(通常是从其他数据存储中移出),常称为批数据。
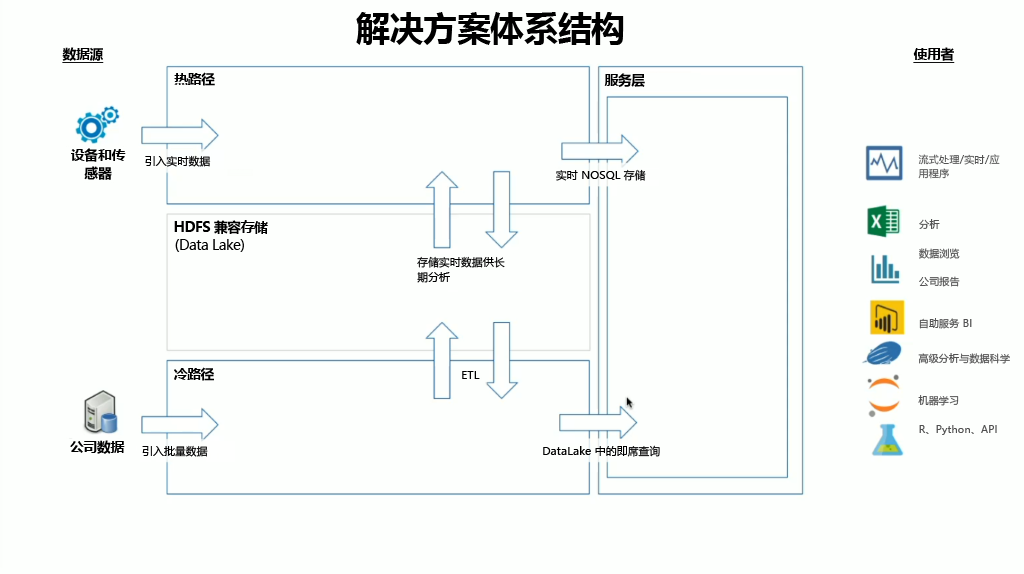
实现 HDInsight 时,数据存储位于兼容的 Hadoop 分布式文件系统 (HDFS) 中。 在 Azure 中,由于 Data Lake Gen2 与 HDFS 兼容,因此通常使用它作为数据存储。 处理后的热路径和冷路径中的数据存储在名为 Data Lake 的集中式数据存储中。 Data lake 本身可划分为多个隔离仓,从而可将数据保存于可按数据状态(登陆区域、转换区域等)、访问要求(热、温和冷)和业务组来定义的各个隔离舱中。 服务层是 data lake 中的最后一个隔离舱,用于将数据保存为各类使用者均可使用的格式。
这里强调一下,HDInsight 的计算功能涉及流数据或批数据的处理,且可能会因你在预配 HDInsight 群集时所选择的群集类型而有所不同。 HDInsight 通过独立的群集选项来提供服务,如下表所示。
| 群集类型 | 描述 |
|---|---|
| Apache Hadoop | 一个框架,使用 HDFS 和简单的 MapReduce 编程模型处理和分析批处理数据。 |
| Apache Spark | 一种开放源代码并行处理框架,支持使用内存中处理来提升大数据分析应用程序的性能。 |
| HBase | 基于 Hadoop 上的 NoSQL 数据库构建,为大量非结构化和半结构化数据(可能为数十亿行乘以数百万列)提供随机访问和高度一致性。 |
| Apache Interactive Query | 更快的交互式 Hive 查询的内存中缓存。 |
| Apache Kafka | 一种开源平台,用于生成流式处理的数据管道和应用程序。 Kafka 还提供了消息队列功能,允许用户发布和订阅数据流。 |
因此,务必选择正确的群集类型,以满足要解决的业务案例的需要。 无论选择哪种群集类型,群集中还会添加其他开源组件,以提供更多功能,包括:
Hadoop 管理
HCatalog - 适用于 Hadoop 的表和存储管理层
Apache Ambari - 有助于管理和监视 Apache Hadoop 群集
Apache Oozie - 工作流计划程序系统,用于管理 Apache Hadoop 作业
Apache Hadoop YARN - 管理资源管理和作业计划/监视
Apache ZooKeeper - 集中式服务,用于维护配置信息、命名、提供分布式同步以及提供组服务。
数据处理
Apache Hadoop MapReduce - 框架,用于轻松编写处理海量数据的应用程序
Apache Tez - 应用程序框架,用于处理数据
Apache Hive - 有助于使用 SQL 管理分布式存储中的大型数据集
数据分析
Apache Pig - 提供 MapReduce 上的抽象层,用于分析大型数据集
Apache Phoenix - 适用于 Hadoop 中的 OLTP 和操作分析
Apache Mahout - 代数框架,用于创建自己的算法
注意
在本文写作之时,Azure Data Lake Gen1 和 Azure Blob 存储都是 HDInsight 支持的数据存储层。 你应该会想要将此数据迁移到 Azure Data Lake Gen2,因为它是 Spark 和 Hadoop 的推荐存储平台,也是 HBase 的默认选择。