HDInsight 交互式查询
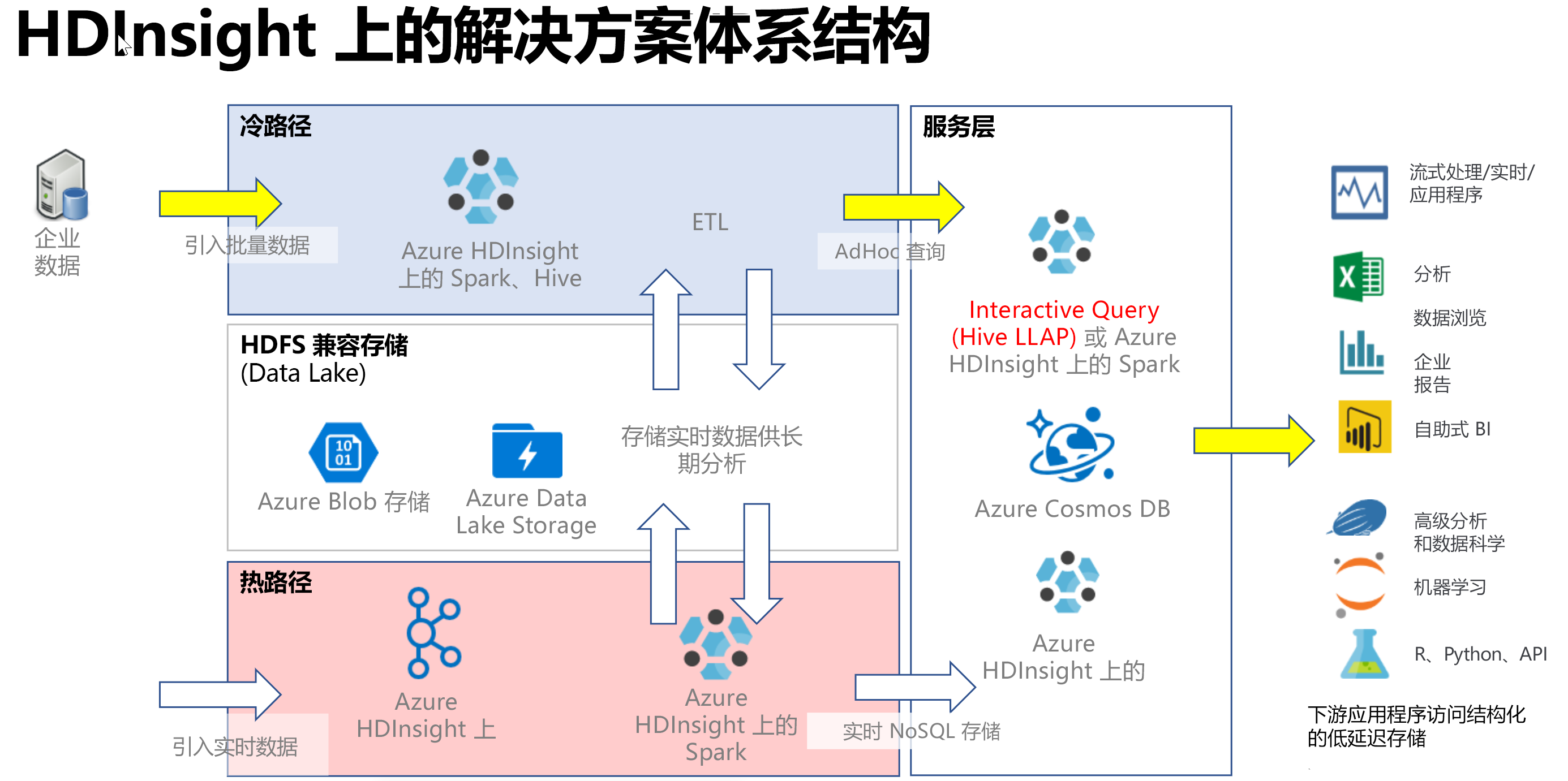
交互式查询通常在冷路径方案中实现,在此方案中,你具有表格格式的数据,并且想要使用 SQL 语法快速提出问题并获得交互式响应。 下图显示了所有 HDInsight 冷路径和热路径解决方案的解决方案体系结构,并说明了通过 Hive LLAP 在服务层中处理交互式查询的方式。 可通过 Hive 引入数据,通过 Hive LLAP 处理交互式查询,并可为下游应用程序(如 Power BI)提供输出。
Interactive Query 体系结构
现在,让我们深入了解 Interactive Query 体系结构。
Interactive Query 用户可以从各种 ODBC 或 JDBC 客户端中进行选择,针对其业务数据运行查询,如 Data Analytics Studio、Zeppelin 笔记本和 Visual Studio Code。 客户端提交 HiveQL 查询后,该查询将到达 HiveServer,后者负责查询规划、优化以及安全修整。 Hive 的运行方式是,在群集中的分布式节点之间划分分析任务。 查询被拆分为多个子任务并发送到处理每个子任务的节点,这些子任务甚至会进行进一步拆分,其中每个任务都会从基础业务数据存储层读取数据。 该体系结构得到了优化,因为它不仅使用了“始终启用”LLAP 守护程序,而且还使用了共享的内存中缓存,前者可避免启动时间,后者可存储从存储区中检索到的数据,并可在所有节点之间共享数据。
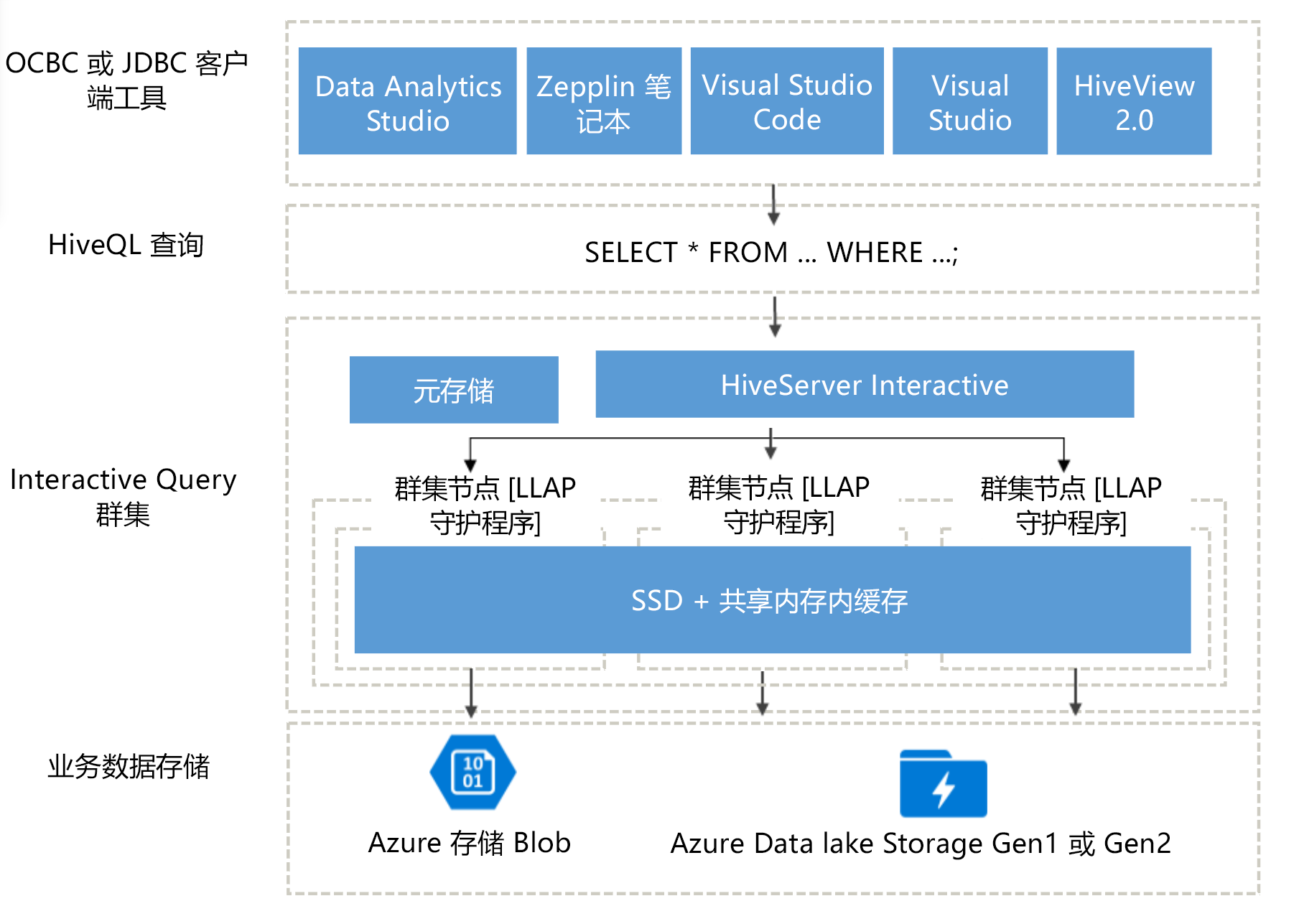
Interactive Query 群集利用的固态硬盘 (SSD) 将 RAM 和 SSD 合并到缓存使用的巨大内存池。 通过这种资源组合,典型的服务器配置文件可以缓存 4 倍以上的数据,因此可处理更大的数据集并支持更多用户。 Interactive Query 缓存可感知远程存储(Azure 存储)中的基础数据更改,因此,如果基础数据发生更改,并且用户发出查询,则更新的数据将加载到内存中,而无需用户执行任何其他步骤。