集成 Apache Spark 和 Hive LLAP 查询
在上一个单元中,我们介绍了两种方法来查询存储在 Interactive Query 群集中的静态数据,即使用 Data Analytics Studio 和使用 Zeppelin 笔记本。 但如果你想要使用 Spark 将全新的房地产数据流式传输到群集,然后使用 Hive 对其进行查询,该怎么办? 由于 Hive 和 Spark 具有两个不同的元存储,因此需要在两者之间建立一个连接器,而 Apache Hive Warehouse Connector (HWC) 就是该连接器。 Hive Warehouse Connector 库可让你更轻松地使用 Apache Spark 和 Apache Hive 来为多种任务提供支持,例如,在 Spark 数据帧与 Hive 表之间移动数据,以及将 Spark 流数据定向到 Hive 表中。 我们不会在方案中设置连接器,但请务必了解该选项是存在的。
Apache Spark 具有一个结构化流式处理 API,该 API 可提供 Apache Hive 中无法提供的流式处理功能。 从 HDInsight 4.0 开始,Apache Spark 2.3.1 和 Apache Hive 3.1.0 使用单独的元存储,这可能会增大互操作性的难度。 使用 Hive Warehouse Connector 可以更轻松地将 Spark 和 Hive 结合使用。 Hive Warehouse Connector 库将数据从 LLAP 守护程序并行加载到 Spark 执行器中,这比使用从 Spark 到 Hive 的标准 JDBC 连接更高效、更具可缩放性。
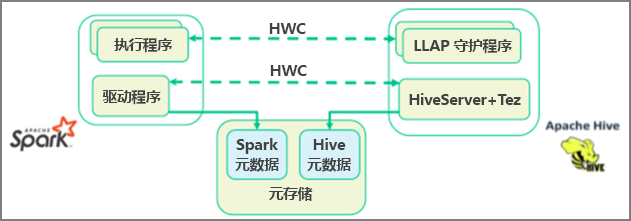
Hive Warehouse Connector 支持的部分操作包括:
- 描述表
- 为 Optimized Row Columnar (ORC) 格式的数据创建表
- 选择 Hive 数据并检索数据帧
- 将数据帧批量写入到 Hive
- 执行 Hive 更新语句
- 从 Hive 读取表数据、在 Spark 中转换数据,然后将数据写入到新的 Hive 表
- 使用 HiveStreaming 将数据帧或 Spark 流写入 Hive
部署 Spark 群集和 Interactive Query 群集后,在基于 Web 的 Ambari 工具中配置 Spark 群集设置,所有 HDInsight 群集中都具有该工具。 若要打开 Ambari,请在 Internet 浏览器中导航到 https://servername.azurehdinsight.net,其中 servername 是 Interactive Query 群集的名称。
若要将 Spark 流数据写入表中,请创建一个 Hive 表,并开始向其中写入数据。 然后可使用以下任一项对流数据运行查询:
- spark-shell
- PySpark
- spark-submit
- Zeppelin
- Livy