Power BI 中的 DirectQuery
在 Power BI Desktop 或 Power BI 服务中,可以通过不同的方式连接到许多不同的数据源。 可以将数据导入 Power BI,这是获取数据最常见的方式。 还可以直接连接到其原始源存储库(称为 DirectQuery)中的某些数据。 本文主要讨论 DirectQuery 功能。
本文介绍:
- 不同的 Power BI 数据连接选项。
- 有关何时使用 DirectQuery 而不是导入功能的指导。
- 使用 DirectQuery 的限制和影响。
- 成功使用 DirectQuery 的建议。
- 如何诊断 DirectQuery 性能问题。
本文重点介绍在 Power BI Desktop 中创建报表时的 DirectQuery 工作流,还介绍了如何在 Power BI 服务中通过 DirectQuery 进行连接。
注意
DirectQuery 也是 SQL Server Analysis Services 的一项功能。 此功能与 Power BI 中的 DirectQuery 有很多相同之处,但也存在一些重要的差异。 本文主要介绍 Power BI(而不是 SQL Server Analysis Services)中的 DirectQuery。
有关将 DirectQuery 与 SQL Server Analysis Services 配合使用的详细信息,请参阅在 Power BI Desktop 中使用复合模型。 还可以下载 SQL Server 2016 Analysis Services 中的 DirectQuery PDF。
Power BI 数据连接模式
Power BI 连接大量不同类型的数据源,例如:
- Salesforce 和 Dynamics 365 等联机服务。
- SQL Server、Access 和 Amazon Redshift 等数据库。
- Excel、JSON 和其他格式的简单文件。
- 其他数据源,如 Spark、网站和 Microsoft Exchange。
可以将数据从这些源导入 Power BI。 对于某些源,还可以使用 DirectQuery 进行连接。 有关支持 DirectQuery 的源的摘要,请参阅 Power BI 数据源。 已启用 DirectQuery 的源主要是可提供良好交互式查询性能的源。
应尽可能将数据导入 Power BI。 通过导入操作,可以充分利用 Power BI 的高性能查询引擎,并提供高度交互、功能完善的体验。
如果导入数据无法实现目标(例如,如果数据频繁更改,并且报表必须反映最新数据),请考虑使用 DirectQuery。 仅当基础数据源能够在不到五秒的时间内为典型的聚合查询提供交互式查询结果,并且能够处理生成的查询负载时,DirectQuery 才可行。 请仔细考虑使用 DirectQuery 的限制和影响。
Power BI 导入和 DirectQuery 功能会随时间的推移不断改进。 这些更改在你使用导入的数据时可提供更大的灵活性,从而能够更频繁地进行导入,并可消除使用 DirectQuery 的一些缺点。 无论如何改进,基础数据源的性能都是使用 DirectQuery 时的主要考虑因素。 如果基础数据源速度缓慢,对该数据源使用 DirectQuery 仍然不可行。
以下各节说明了连接数据的三个选项:“导入”、“DirectQuery”和“实时连接”。 本文的其余部分重点介绍 DirectQuery。
导入连接
连接到数据源(如 SQL Server)并在 Power BI Desktop 中导入数据时,会出现以下连接情况:
初次使用“获取数据”时,选择的每组表都会定义返回一组数据的查询。 可以在加载数据之前编辑这些查询,例如应用筛选器、聚合数据或联接不同的表。
加载时,这些查询定义的所有数据都将导入 Power BI 缓存。
在 Power BI Desktop 中生成视觉对象时,会查询缓存的数据。 Power BI 存储可确保查询速度迅速,对视觉对象的所有更改都会立即反映出来。
视觉对象不会反映对数据存储中基础数据的更改。 需要进行重新导入才能刷新数据。
将报表作为 .pbix 文件发布到 Power BI 服务会创建并上传包含导入数据的语义模型。 然后,可以计划数据刷新,例如每天重新导入数据。 可能必须为刷新配置本地数据网关,具体取决于原始数据源的位置。
在 Power BI 服务中打开现有报表或创作新报表时,将再次查询导入的数据,确保交互性。
可以将视觉对象或整个报表页固定为 Power BI 服务中的仪表板磁贴。 当基础语义模型刷新时,磁贴自动刷新。
DirectQuery 连接
在 Power BI Desktop 中使用 DirectQuery 连接到数据源时,会出现以下数据连接情况:
使用“获取数据”来选择源。 对于关系源,你仍然可以选择一组表,这些表定义了逻辑上返回一组数据的查询。 对于 SAP Business Warehouse (SAP BW) 等多维源,只能选择该源。
在加载时,不会将数据导入 Power BI 存储。 而在你生成视觉对象时,Power BI Desktop 会向基础数据源发送查询以检索必要的数据。 刷新视觉对象所花的时间取决于基础数据源的性能。
对基础数据的任何更改都不会立即反映在现有视觉对象中。 仍然需要刷新。 Power BI Desktop 为每个视觉对象重新发送必要的查询,并根据需要更新视觉对象。
将报表发布到 Power BI 服务会创建并上传语义模型,与导入相同。 但是,该语义模型不含任何数据。
在 Power BI 服务中打开现有报表或创作新报表时,将查询基础数据源以检索必要的数据。 可能必须配置本地数据网关来获取数据,具体取决于原始数据源的位置。
可以将视觉对象或整个报表页固定为仪表板磁贴。 为了确保迅速打开仪表板,磁贴会按计划(例如每小时)自动刷新。 可以根据数据更改的频率和查看最新数据的重要性来控制刷新频率。
在你打开仪表板时,磁贴将反映上次刷新时的数据,而不一定反映对基础源所做的最新更改。 可刷新打开的仪表板,确保它保持最新。
实时连接
连接到 SQL Server Analysis Services 时,你可以选择导入数据,或使用与所选数据模型的实时连接。 使用实时连接类似于 DirectQuery。 不导入数据,查询基础数据源以刷新视觉对象。
例如,使用导入连接到 SQL Server Analysis Services 时,可以针对外部 SQL Server Analysis Services 源定义查询,然后导入数据。 如果进行实时连接,则无需定义查询,并且整个外部模型会显示在字段列表中。
连接到以下源时,此情况也适用,除非没有导入数据的选项:
Power BI 语义模型(例如,连接到已发布到服务的 Power BI 语义模型)用于创作新报表将其覆盖。
Microsoft Dataverse。
发布使用实时连接的 SQL Server Analysis Services 报表时,Power BI 服务中的行为在以下方面与 DirectQuery 报表类似:
在 Power BI 服务中打开现有报表或创作新报表时,将查询基础 SQL Server Analysis Services 源(可能需要一个本地数据网关)。
仪表板磁贴按计划(例如每小时)自动刷新。
实时连接在多个方面也不同于 DirectQuery。 例如,实时连接始终将打开报表的用户的标识传递给基础 SQL Server Analysis Services 源。
DirectQuery 用例
在以下情况下,使用 DirectQuery 进行连接可能很有用。 在其中一些情况下,将数据保留在其原始源位置是必要的或有益的。
Power BI 中的 DirectQuery 在以下情况提供最大的优势:
- 数据频繁更改,且你需要准实时报表。
- 需要处理大型数据,而无需预先聚合。
- 基础源定义并应用安全规则。
- 数据主权限制应用。
- 源是包含度量值(如 SAP BW)的多维度源。
数据频繁更改,且你需要准实时报表
最多每小时可以使用导入的数据刷新一次模型,或者使用 Power BI Pro 或 Power BI Premium 订阅可以更频繁地刷新。 如果数据不断改变且报表必须显示最新数据,使用按计划刷新的导入可能无法满足需求。 可以将数据直接流式传输到 Power BI 中(尽管这种情况下支持的数据量有限制)。
使用 DirectQuery 意味着打开或刷新报表或仪表板始终显示源中最新的数据。 也可以更频繁地(每 15 分钟)更新仪表板磁贴。
数据量非常大
如果数据非常大,则导入所有数据是不可行的。 DirectQuery 不需要大量数据传输,因为它可以就地查询数据。 但是,大数据也可能使对该基础源的查询速度过于缓慢。
你不必始终导入完整的详细数据。 Power Query 编辑器使得在导入期间预聚合数据变得容易。 从技术上讲,可以只导入每个视觉对象所需的聚合数据。 虽然 DirectQuery 是处理大量数据的最简单方法,但如果基础数据源对于 DirectQuery 太慢,那么导入聚合数据也许是一个解决方案。
这些详细信息与单独使用 Power BI 有关。 有关在 Power BI 中使用大型模型的详细信息,请参阅 Power BI Premium 中的大型语义模型。 对于数据刷新频率没有限制。
基础源定义安全规则
导入数据时,Power BI 使用当前用户的 Power BI Desktop 凭据或在 Power BI 服务中为计划刷新配置的凭据连接到数据源。 在发布和共享包含导入数据的报表时,必须注意只与允许查看数据的用户共享,或者必须将行级安全性定义为语义模型的一部分。
DirectQuery 允许报表查看器的凭据传递到应用安全规则的基础源。 DirectQuery 支持对 Azure SQL 数据源的单一登录 (SSO),以及通过数据网关对本地 SQL 服务器的 SSO。 有关详细信息,请参阅 Power BI 中本地数据网关的单一登录 (SSO) 概述。
数据主权限制应用
某些组织对数据主权制定有相应策略,这意味着数据不能离开组织规定的前提。 此数据针对基于数据导入的解决方案提出了问题。 如果使用 DirectQuery,数据保留在基础源位置。 但是,由于磁贴的计划刷新,即使使用 DirectQuery,Power BI 服务也会在视觉对象级别保留某些数据缓存。
基础数据源使用度量值
基础数据源(例如 SAP HANA 或 SAP BW)包含度量值。 度量值意味着导入的数据已处于查询定义的特定聚合级别。 请求更高级别聚合的数据的视觉对象(例如按“年份”划分的 TotalSales)会进一步聚合该聚合值。 此聚合对于累加性度量值(如 Sum 和 Min)没有问题,但对非累加性度量值(如 Average 和 DistinctCount)会产生问题。
直接从源轻松获取视觉对象所需的正确聚合数据需要按视觉对象发送查询,就像在 DirectQuery 中一样。 连接到 SAP BW 时,选择 DirectQuery 允许对度量值进行这种处理。 有关详细信息,请参阅 DirectQuery 和 SAP BW。
当前 SAP HANA 上的 DirectQuery 将数据视为关系源对待,并产生与导入类似的行为。 有关详细信息,请参阅 DirectQuery 和 SAP HANA。
DirectQuery 限制
使用 DirectQuery 有一些潜在的负面影响。 其中一些限制略有不同,具体取决于使用的确切源。 以下各节列出了使用 DirectQuery 的常规影响,以及与性能、安全性、转换、建模和报告相关的限制。
常规影响
使用 DirectQuery 的一些常规影响和限制如下:
如果数据发生更改,则必须刷新以显示最新数据。 考虑到缓存的使用,无法确保视觉对象始终显示最新数据。 例如,视觉对象可能显示过去一天的事务。 切片器更改可能会刷新视觉对象以显示过去两天的事务,包括最近新到达的事务。 但是将切片器返回到其原始值可能会导致再次显示缓存的先前值。 选择“刷新”以清除所有缓存,并刷新页面上的所有视觉对象以显示最新数据。
如果数据发生更改,则不能保证视觉对象之间的一致性。 不同的视觉对象(无论是在相同页面还是在不同页面上),可能会在不同的时间刷新。 如果基础源中的数据已更改,则不能保证每个视觉对象都在相同的时间点显示数据。
鉴于单个视觉对象可能需要多个查询(例如,获取详细信息和总计),因此,即使在单个视觉对象中也不能保证一致性。 若要确保此一致性,每当刷新任何视觉对象时,都需要刷新所有视觉对象的开销,同时使用昂贵的功能,如基础数据源中的“快照隔离”。
可以选择“刷新”来刷新页面上的所有视觉效果,从而在很大程度上缓解此问题。 即使对于导入模式,从多个表导入数据时,也存在类似的保持一致性的问题。
必须在 Power BI Desktop 中进行刷新才能反映架构更改。 发布报表后,Power BI 服务中的“刷新”会刷新报表中的视觉对象。 但是,如果基础源架构发生更改,Power BI 服务不会自动更新可用字段列表。 如果从基础源中删除表或列,则可能导致刷新时查询失败。 若要更新模型中的字段以反映更改,必须在 Power BI Desktop 中打开报表,然后选择“刷新”。
可对任何查询返回的行数限制为 100 万行。 在对基础源的任何单个查询中,可以返回的行数限制为固定的 100 万行。 此限制通常没有实际影响,视觉对象不会显示那么多行。 但如果 Power BI 未完全优化发送的查询,并请求一些超出限制的中间结果,则可能会受此限制。
在生成达到更合理最终状态的视觉对象的过程中,也可能会受此限制。 例如,如果有超过一百万的客户,则在应用某些筛选器之前,包括“客户”和“TotalSalesQuantity”将达到此限制。 返回的错误:外部数据源的查询结果集超过了允许的最大行数 "1000000" 行。
注意
高级容量允许超过 100 万行限制。 有关详细信息,请参阅最大中间行集计数。
无法将模型从导入模式更改为 DirectQuery 模式。 如果导入所有必要的数据,则可以将模型从 DirectQuery 模式切换到导入模式。 无法切换回 DirectQuery 模式,这主要是由于 DirectQuery 模式不支持的功能集造成的。 由于外部度量值的处理方式不同,对于像 SAP BW 这样的多维源,也不能从 DirectQuery 切换到导入模式。
性能和负载影响
使用 DirectQuery 时,整体体验取决于基础数据源的性能。 如果刷新每个视觉对象(例如在更改切片器值之后)花费的时间少于五秒,则体验是合理的,尽管与导入数据的即时响应相比可能会感到迟钝。 如果源速度慢而导致各个视觉对象刷新所花的时间超过数十秒,则体验就会变得非常糟糕。 查询甚至可能会超时。
除了基础源的性能之外,源上的负载也会影响性能。 每个打开共享报表的用户和每个刷新的仪表板磁贴,都会针对每个可视对象向基础源发送至少一个查询。 源必须能够处理此类查询负载,同时保持良好的性能。
安全隐患
除非基础数据源使用 SSO,否则 DirectQuery 报表在发布到 Power BI 服务后将始终使用相同的固定凭据连接到源。 发布 DirectQuery 报表后,必须立即配置要使用的用户的凭据。 在配置凭据之前,尝试在 Power BI 服务中打开报表将导致错误。
提供用户凭据后,Power BI 会将这些凭据用于打开报表的用户,这与导入的数据相同。 除非将行级安全性定义为报表的一部分,否则每个用户都会看到相同的数据。 即使基础源中定义了安全规则,也必须像共享导入的数据一样注意共享报表。
在 DirectQuery 模式下连接到 Power BI 语义模型和 Analysis Services 将始终使用 SSO,因此安全性类似于与 Analysis Services 的实时连接。
将 DirectQuery 从 Power BI Desktop 连接到 SQL Server 时,不支持使用备用凭据。 可使用当前的 Windows 凭据或数据库凭据。
可以使用复合模型在 DirectQuery 模型中使用多个数据源。 当你使用多个数据源时,很重要的一点是,要了解数据如何在基础数据源之间来回移动的安全影响。
数据转换限制
DirectQuery 限制可在 Power Query 编辑器内应用的数据转换。 使用导入的数据,可以轻松地应用一组复杂的转换来清理和重塑数据,然后再使用它来创建视觉对象。 例如,可以分析 JSON 文档,或将数据从列转换为行形式。 这些转换在 DirectQuery 中受到更多限制。
连接到联机分析处理 (OLAP) 源(如 SAP BW)时,无法定义任何转换,整个外部模型都取自源。 对于类似 SQL Server 的关系数据源,每个查询仍可以定义一组转换,但是出于性能原因,这些转换将受到限制。
必须对基础源的每个查询应用任何转换,而不是在数据刷新时应用一次。 转换必须能够合理地转换为单个本机查询。 如果你使用的转换过于复杂,你会得到一个错误,指示必须删除该转换或必须将连接模型切换为导入。
此外,“获取数据”对话框或 Power Query 编辑器在其生成和发送的查询中使用子选择来检索视觉对象的数据。 在 Power Query 编辑器中定义的查询必须在此上下文中有效。 具体而言,不能使用包含公用表表达式或调用存储过程的查询。
建模限制
术语“建模”在此上下文中表示完善和丰富原始数据(在使用这些数据创作报表期间)。 建模示例包括:
- 定义表之间的关系。
- 添加新计算(如计算列和度量值)。
- 重命名和隐藏列和度量值。
- 定义层次结构。
- 定义列的格式设置、默认汇总以及排序顺序。
- 分组或聚类值。
仍可在使用 DirectQuery 时进行其中许多模型扩充,并使用扩充原始数据的原则来改进以后的使用。 但是,某些建模功能在 DirectQuery 中不可用或受到限制。 应用限制的目的是避免性能问题。
以下限制对所有 DirectQuery 源通用。 更多限制可能适用于单个源。
无内置日期层次结构:对于导入的数据,每个日期/日期时间列也有一个默认可用的内置日期层次结构。 例如,如果导入包含 OrderDate 列的销售订单表,并在视觉对象中使用 OrderDate,则可以选择要使用的相应日期级别,例如年、月或日。 此内置日期层次结构在 DirectQuery 中不可用。 如果基础源中存在可用的“日期”表(如许多数据仓库中常见的那样),则可以照常使用数据分析表达式 (DAX) 时间智能函数。
日期/时间仅支持秒级别:对于使用时间列的语义模型,Power BI 向基础 DirectQuery 源发出的查询最多只能达到秒级细节级别,而不是毫秒级。 从源列中删除毫秒数据。
在计算列中的限制:计算列仅限于行内,即只能引用同一表中其他列的值,不能使用任何聚合函数。 此外,允许使用的 DAX 标量函数(如
LEFT())仅限于那些可推送到基础源的函数。 函数因源的确切功能而异。 创建计算列的 DAX 查询时,不支持的函数不会在自动完成中列出,如果使用则会导致错误。不支持父-子 DAX 函数:在 DirectQuery 模式中,不能使用 系列函数,这类函数通常处理父-子结构,如帐户图表或员工层次结构图表。
DAX PATH()无聚类分析:使用 DirectQuery 时,不能使用聚类分析功能自动查找组。
报表限制
几乎所有的报表功能都支持 DirectQuery 模型。 只要基础数据源提供了合适的性能水平,就可以使用与导入数据相同的一组可视化效果。
一个常规限制是 DirectQuery 语义模型的文本列中数据的最大长度为 32,764 个字符。 报告较长的文本会导致错误。
以下 Power BI 报告功能可能会导致基于 DirectQuery 的报表出现性能问题:
度量值筛选器:使用度量值或列聚合的视觉对象可以包含这些度量值中的筛选器。 例如,下图按“类别”显示“SalesAmount”,但仅适用于销量超过两千万的类别。
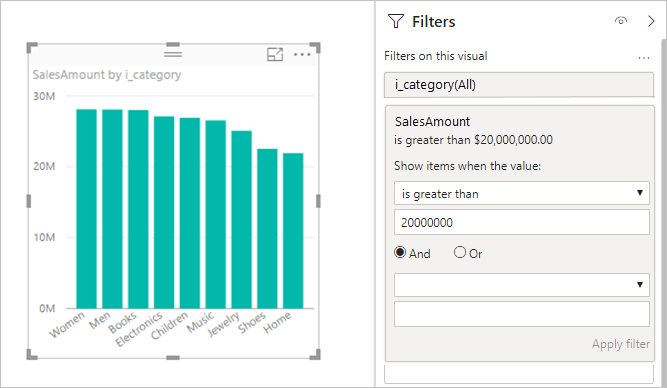
此方法导致两个查询被发送到基础源:
- 第一个查询检索符合条件(SalesAmount 大于两千万)的类别。
- 第二个查询检索视觉对象必需的数据,包括满足
WHERE条件的类别。
如果有数百或数千个类别,此方法通常很有效,如本例所示。 如果类别数太大,性能可能会降低。 如果类别超过 100 万个,则查询将失败。
TopN 筛选器:你可定义高级筛选器,仅筛选按某些度量值排名的前(后) 个值。
N例如,筛选器可以包含前 10 个类别。 此方法会再次向基础源发送两个查询。 但是,第一个查询会从基础数据源返回所有类别,然后TopN基于返回的结果确定。 根据涉及的列的基数,此方法可能会导致性能问题或查询失败,因为查询结果行限制为一百万。中值:任何聚合(例如 或
Sum)都会被推送到基础源。Count Distinct但是,基础源通常不支持median聚合。 对于median,会先从基础源中检索详细数据,然后从返回的结果中计算中值。 对于针对相对较少的结果计算中值,此方法是合理的。如果基数很大(因为行限制为一百万),则可能会出现性能问题或查询失败。 例如,查询“国家/地区人口的中值”可能是合理的,但查询“销售价格的中值”可能不合理。
高级文本筛选器(如“contains”):对文本列进行高级筛选允许使用 和
contains等筛选器。begins with对于某些数据源,这些筛选器会导致性能下降。 特别是,如果需要完全匹配,请不要使用默认contains筛选器。 尽管结果可能相同(具体取决于实际数据),但由于使用索引不同,性能可能也会完全不同。多选切片器:默认情况下,切片器仅允许单选。 允许筛选器采用多选形式会导致性能问题。 例如,如果用户选择了所需的 10 种产品,每个新选择都会导致将查询发送到源。 尽管用户可以在查询完成之前选择下一项,但此方法会对基础源产生额外的负载。
对表视觉对象的总计:表格和矩阵默认显示总计和小计。 在许多情况下,获取此类总计的值需要向基础源发送单独的查询。 每当使用
DistinctCount聚合时,或在任何对 SAP BW 或 SAP HANA 使用 DirectQuery 情况下,此要求都适用。 可以使用“格式”窗格关闭此类总计。
DirectQuery 建议
鉴于 DirectQuery 的影响,本节提供有关如何成功使用 DirectQuery 的大致指导。
基础数据源性能
验证简单视觉对象是否在五秒内刷新,以提供合理的交互式体验。 如果视觉对象刷新时间超过 30 秒,则报表发布后出现的进一步问题可能会使解决方案不可行。
如果查询速度慢,请检查发送到基础源的查询以及性能较低的原因。 有关详细信息,请参阅性能诊断。
本文不涉及各种在完整的一组潜在基础源中优化数据库的建议。 以下标准数据库做法适用于大多数情况:
为了获得更好的性能,使关系基于整数列,而不是联接其他数据类型的列。
创建相应索引。 创建索引通常意味着在支持列存储索引的源(如 SQL Server)中使用它们。
更新源中的任何必要统计信息。
模型设计
定义模型时,请遵循以下指南:
避免在 Power Query 编辑器中定义复杂的查询。 Power Query 编辑器将复杂的查询转换为单个 SQL 查询。 此查询显示在发送到该表的每个查询的子选项中。 如果查询很复杂,则可能导致所发送的每个查询出现性能问题。 可以获取一组步骤的实际 SQL 查询,方法是右键单击 Power Query 编辑器中“已应用的步骤”下的最后一个步骤,然后选择“查看本机查询”。
简化度量值。 至少在开始时,将度量值限制为简单聚合。 如果度量值以符合要求的方式运行,则可以定义更复杂的度量值,但请注意性能。
避免在计算列上建立关系。 在需要执行多列联接的数据库中,Power BI 不允许将多列上的关系作为主键或外键。 常见的解决方法是使用计算列来连接列,然后基于该列进行联接。
此解决方法对于导入的数据是合理的,但对于 DirectQuery,这会导致表达式上出现联接。 这种结果通常会阻止使用任何索引,并导致性能不佳。 唯一的解决方法是,在基础数据源中将多列具体化为单列。
避免在“uniqueidentifier”列上建立关系。 Power BI 在本机上不支持
uniqueidentifier数据类型。 定义uniqueidentifier列之间的关系将导致涉及强制转换的联接的查询。 同样,此方法通常会导致性能不佳。 唯一的解决方法是在基础数据源中具体化替代类型的列。隐藏关系中的“to”列。 关系中的
to列通常是to表的主键。 该列应处于隐藏状态,但如果将其隐藏,则不会显示在字段列表中,并且不能在视觉对象中使用。 通常,关系所在的列实际上是系统列(例如数据仓库中的代理键)。 最好还是隐藏此类列。如果该列有意义,则引入一个可见并且具有等于主键的简单表达式的计算列,例如:
ProductKey_PK (Destination of a relationship, hidden) ProductKey (= [ProductKey_PK], visible) ProductName ...检查所有计算列和数据类型更改。 将 DirectQuery 与复合模型配合使用时,可以使用计算表。 这些功能不一定有害,但它们会导致包含表达式的查询,而不是对列的简单引用。 这些查询可能会导致无法使用索引。
避免对关系进行双向交叉筛选。 使用双向交叉筛选可能导致查询语句应用效果不佳。 有关双向交叉筛选的详细信息,请参阅在 Power BI Desktop 中为 DirectQuery 启用双向交叉筛选,或下载双向交叉筛选白皮书。 本文中的示例适用于 SQL Server Analysis Services,但基本要点也适用于 Power BI。
设置“假设引用完整性”实验。 关系的“假设引用完整性”设置使查询能够使用 语句,而不是
INNER JOIN语句。OUTER JOIN本指南通常可以提高查询性能,但具体取决于数据源的详细情况。请勿在 Power Query 编辑器中使用相对日期筛选。 在 Power Query 编辑器中可以定义相对日期筛选。 例如,可以筛选日期是过去 14 天内的行。
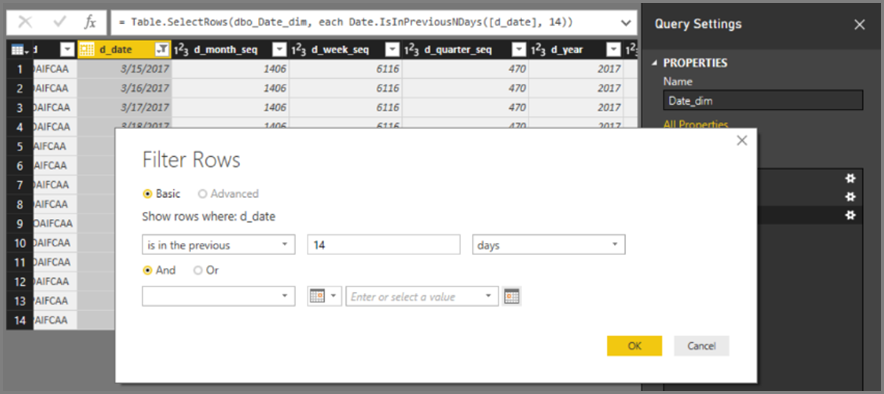
但是,此筛选器会转换为基于固定日期(例如创作查询的时间)的筛选器,如本机查询中所示。

此数据可能不是你想要的数据。 要确保根据报表运行时的日期应用筛选器,请在报表中应用日期筛选器。 可以使用
DAX DATE()函数创建一个计算前几天天数的计算列,并在筛选器中使用该计算列。
报表设计
创建使用 DirectQuery 连接的报表时,请遵循以下指南:
考虑使用“查询缩减”选项:Power BI 提供报表选项以发送更少的查询,并在生成的查询需要较长的运行时间时禁用可能导致体验不佳的某些交互。 在 Power BI Desktop 中与报表进行交互时,这些选项适用,并且当用户在 Power BI 服务中使用报表时,这些选项也适用。
若要访问 Power BI Desktop 中的这些选项,请转到“文件”“选项和设置”>“选项”,然后选择“查询缩减” 。
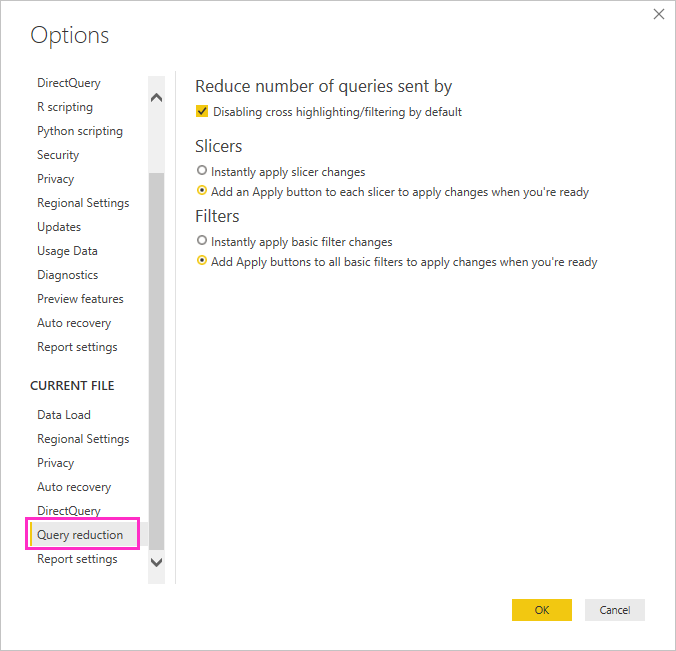
通过“查询缩减”屏幕上的选择,可以显示切片器或筛选器选择的“应用”按钮。 在你选择筛选器或切片器上的“应用”按钮之前,不会发送任何查询。 然后,查询使用所选内容来筛选数据。 可通过此按钮在应用切片器和筛选器之前进行多个切片器和筛选器选择。
先应用筛选器: 始终在开始生成视觉对象时应用任何适用的筛选器。 例如,与其在“TotalSalesAmount”和“ProductName”拖动,然后筛选到特定年份,不如一开始就应用“年份”筛选器。
生成视觉对象的每个步骤都会发送查询。 虽然在第一个查询完成之前可能会进行其他更改,但此方法仍然会对基础源造成不必要的负担。 尽早应用筛选器通常会降低中间查询成本。 如果未能尽早应用筛选器,可能导致达到一百万行的限制。
限制页面上的视觉对象的数目:打开页面或更改页面级切片器或筛选器时,将刷新页面上的所有视觉对象。 并行查询的数量有限制。 随着视觉对象数量的增加,某些视觉对象会串行刷新,这会增加刷新页面所需的时间。 因此,最好限制单个页面中的视觉对象数量,改为包含更多更简单的页面。
考虑关闭视觉对象之间的交互:默认情况下,报表页上的可视化组件可用于交叉筛选和交叉突出显示页面上的其他可视化组件。 例如,如果选择饼图上的“1999”,柱形图交叉突出显示“1999”类别的销售额。
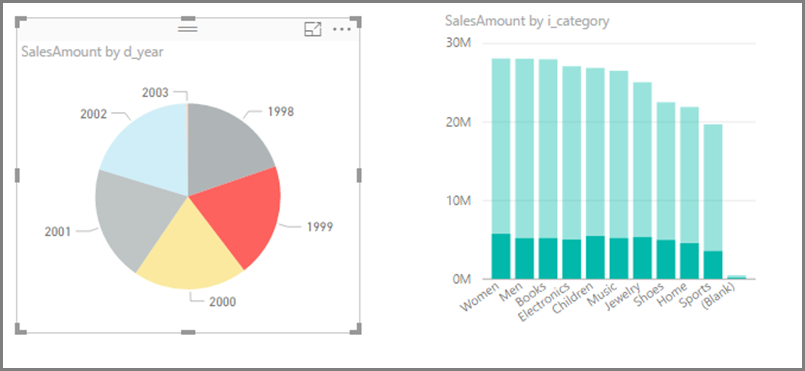
DirectQuery 中的交叉筛选和交叉突出显示要求向基础源提交查询。 如果响应用户选择所用的时间过长,则应关闭此交互。
可以使用“查询缩减”设置在整个报表中或根据具体情况禁用交叉突出显示。 有关详细信息,请参阅视觉对象如何在 Power BI 报表中彼此交叉筛选。
最大连接数
你可以设置 DirectQuery 为每个基础数据源打开的最大连接数,这会控制同时发送到每个数据源的查询数。
默认情况下,DirectQuery 可打开最多 10 个并发连接。 若要更改 Power BI Desktop 中当前文件的最大数目,请转到“文件”“选项和设置”>“选项”,然后在左窗格的“当前文件”部分选择“DirectQuery”。
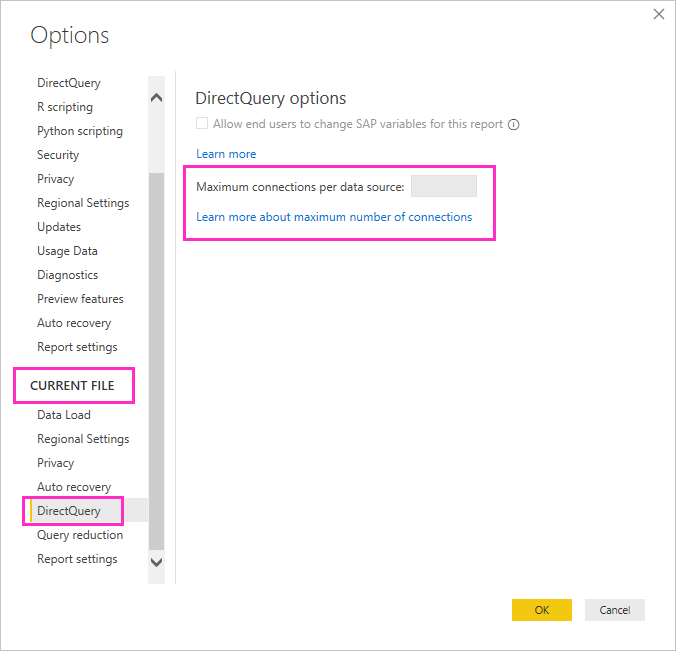
此设置仅在当前报表中至少有一个 DirectQuery 源时启用。 该值适用于所有 DirectQuery 源,以及添加到该报表中的任何新的 DirectQuery 源。
通过增加“每个数据源的最大连接数”,可将更多查询(以指定的最大数量为限)发送到基础数据源。 当多个视觉对象位于一个页面上,或者许多用户同时访问报表时,此方法非常有用。 达到最大连接数后,超出的查询就会排队,直到连接可用。 较高的限制会导致基础源上的负载增加,因此该设置不保证提高总体性能。
将报表发布到 Power BI 服务后,并发查询的最大数量还取决于在发布报表的目标环境上设置的固定限制。 Power BI、Power BI Premium 和 Power BI 报表服务器可以施加不同限制。 下表列出了适用于每个 Power BI 环境的每个数据源的活动连接上限。 这些限制适用于云数据源和本地数据源,例如 SQL Server、Oracle 和 Teradata。
| 环境 | 每个数据源的上限 |
|---|---|
| Power BI Pro | 10 个活动连接 |
| Power BI Premium | 取决于语义模型 SKU 限制 |
| Power BI 报表服务器 | 10 个活动连接 |
注意
启用增强元数据后,DirectQuery 连接设置的最大大小会应用于所有 DirectQuery 源;“增强元数据”是在 Power BI Desktop 中创建的所有模型的默认设置。
Power BI 服务中的 DirectQuery
Power BI Desktop 支持所有 DirectQuery 数据源,并且某些源也可直接从 Power BI 服务中获取。 例如,企业用户可以使用 Power BI 连接其 Salesforce 中的数据并立即获得仪表板,而无需使用 Power BI Desktop。
只有以下两个已启用 DirectQuery 的源可直接在 Power BI 服务中使用:
- Spark
- Azure Synapse Analytics(以前称为 SQL 数据仓库)
即使对于这两个源,最好还是在 Power BI Desktop 内开始使用 DirectQuery。 虽然最初在 Power BI 服务中建立连接很容易,但进一步增强生成的报表存在限制。 例如,在服务中,无法创建任何计算,或使用许多分析功能,或刷新元数据以反映对基础架构所做的更改。
Power BI 服务中 DirectQuery 报表的性能取决于基础数据源上的负载程度。 负载取决于:
- 共享报表和仪表板的用户数。
- 报表的复杂性。
- 报表是否定义行级安全性。
Power BI 服务中的报表行为
在 Power BI 服务中打开报表时,当前可见页上的所有视觉对象都会刷新。 每个视觉对象需要至少一个对基础数据源的查询。 某些视觉对象可能需要多个查询。 例如,视觉对象可能会显示来自两个不同事实数据表的聚合值、包含更复杂的度量值或包含非附加式度量值的总和(如 Count Distinct)。 移动到新页面会刷新这些视觉对象。 刷新将向基础源发送一组新查询。
报表上的所有用户交互都可能导致刷新视觉对象。 例如,选择切片器上的不同值需要发送一组新查询以刷新所有受影响的视觉对象。 选择视觉对象以交叉突出显示其他视觉对象或更改筛选器也是如此。 类似地,创建或编辑报表需要为过程中的每个步骤发送查询,以产生最终视觉对象。
存在一些包含结果的缓存。 如果获得完全相同的最新结果,将即时刷新视觉对象。 如果定义了行级安全性,则不会跨用户共享这些缓存。
使用 DirectQuery 会对 Power BI 服务为已发布报表提供的某些功能施加一些重要限制:
不支持快速见解:Power BI 快速见解功能可搜索语义模型的不同子集,同时应用一组复杂的算法来发现潜在相关的见解。 由于快速见解需要高性能查询,所以此功能对使用 DirectQuery 的语义模型不可用。
使用“在 Excel 中浏览”会导致性能不佳:可以使用“在 Excel 中浏览”功能来浏览语义模型,该功能允许在 Excel 中创建数据透视表和数据透视图。 使用 DirectQuery 的语义模型支持此功能,但性能比在 Power BI 中创建视觉对象差。 如果使用 Excel 对于你的场景很重要,请在决定是否使用 DirectQuery 时考虑此问题。
Excel 不显示层次结构:例如,使用“在 Excel 中分析”时,Excel 不会显示在使用 DirectQuery 的 Azure Analysis Services 模型或 Power BI 语义模型中定义的任何层次结构。
仪表板刷新
在 Power BI 服务中,可以将单个视觉对象或整个页面作为磁贴固定到仪表板。 基于 DirectQuery 语义模型的磁贴通过按计划将查询发送到基础数据源自动进行刷新。 默认情况下,语义模型每小时刷新一次,但可以在语义模型设置中将刷新计划间隔配置为每周或每 15 分钟刷新一次。
如果模型中未定义行级安全性,每个磁贴将刷新一次,并在所有用户之间共享结果。 如果使用行级安全性,每个磁贴都需要将每个用户的单独查询发送到基础源。
可能会产生巨大的乘数效应。 如果某个仪表板有 10 个磁贴、与 100 个用户共享、是在使用具有行级安全性的 DirectQuery 语义模型上创建的,则每次刷新向基础数据源发送至少 1000 个查询。 仔细考虑使用行级安全性和刷新计划配置。
查询超时
四分钟的超时时间适用于 Power BI 服务中的单个查询。 超过四分钟的查询将失败。 此限制旨在防止因执行时间过长引起的问题。 应仅对可提供交互式查询性能的源使用 DirectQuery。
达到超时限制后,视觉对象无法加载并出现以下错误:The query has exceeded the available resources. Try filtering to decrease the amount of data requested. The XML for Analysis request timed out before it was completed. Timeout value: 225 sec。
性能诊断
本节介绍如何诊断性能问题,或如何获取更详细的信息以优化报表。
在 Power BI Desktop 而不是 Power BI 服务中开始诊断性能问题。 性能问题通常基于基础源的性能。 在隔离性更佳的 Power BI Desktop 环境中,你可以更轻松地识别和诊断问题。
此方法一开始便可排除某些组件,如 Power BI 网关。 如果 Power BI Desktop 不存在性能问题,可以调查 Power BI 服务中报表的具体内容。
Power BI Desktop 性能分析器是用于标识问题的有用工具。 尝试将任何问题隔离到一个页面的一个视觉对象(而不是多个视觉对象)上。 如果 Power BI Desktop 页面上的单个视觉对象运行缓慢,请使用性能分析器分析 Power BI Desktop 发送到基础源的查询。
还可以查看某些基础数据源发出的跟踪和诊断信息。 即使源中没有跟踪,跟踪文件也可能包含有关查询运行方式以及查询改进方式的有用详细信息。 可以使用以下过程查看 Power BI 发送的查询及其执行时间。
使用 SQL Server Profiler 查看查询
默认情况下,Power BI Desktop 会在给定会话期间将事件记录到名为 FlightRecorderCurrent.trc 的跟踪文件中。 跟踪文件位于当前用户的 Power BI Desktop 文件夹中名为 AnalysisServicesWorkspaces 的文件夹中。
对于某些 DirectQuery 源,此跟踪文件包括发送到基础数据源的所有查询。 以下数据源将查询发送到日志:
- SQL Server
- Azure SQL 数据库
- Azure Synapse Analytics(以前称为 SQL 数据仓库)
- Oracle
- Teradata
- SAP HANA
可以使用 SQL Server Profiler(免费下载 SQL Server Management Studio 的一部分)读取跟踪文件。
打开当前会话的跟踪文件:
在 Power BI Desktop 会话期间,选择“文件”“选项和设置”>“选项”,然后选择“诊断”。>
在“故障转储收集”下,选择“打开故障转储/跟踪文件夹”。
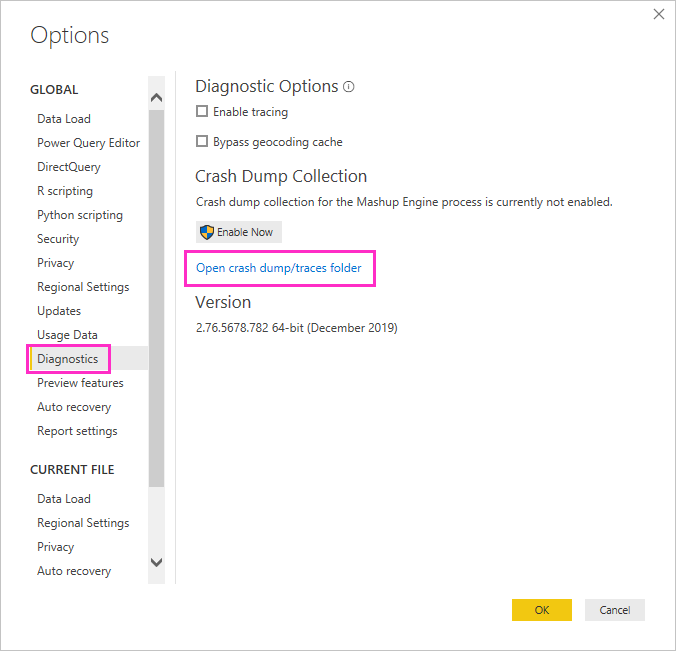
此时会打开 Power BI Desktop\Traces 文件夹。
导航到父文件夹,然后导航到 AnalysisServicesWorkspaces 文件夹,该文件夹包含每个打开的 Power BI Desktop 实例的一个工作区文件夹。 这些文件夹名称中带有整数后缀,例如 AnalysisServicesWorkspace2058279583。 相关联的 Power BI Desktop 会话结束时,将删除工作区文件夹。
在当前 Power BI 会话的工作区文件夹中,\Data 文件夹包含 FlightRecorderCurrent.trc 跟踪文件。 记下位置。
打开 SQL Server Profiler,选择“文件”“打开”>“跟踪文件”。>
导航到或输入当前 Power BI 会话的跟踪文件的路径,然后打开 FlightRecorderCurrent.trc。
SQL Server Profiler 显示当前会话中的所有事件。 以下屏幕截图突出显示了一组查询事件。 每个查询组具有以下事件:
Query Begin和Query End事件,表示通过更改 Power BI UI 中的视觉对象或筛选器,或筛选或转换 Power Query 编辑器中的数据生成的 DAX 查询的开始和结束。一对或多对
DirectQuery Begin和DirectQuery End事件,表示在评估 DAX 查询的过程中发送到基础数据源的查询。

多个 DAX 查询可以并行运行,因此来自不同组的事件可能互相交错。 可以使用 ActivityID 值确定哪些事件属于同一组。
以下各列也相关:
- TextData: 事件的文本详细信息。 对于
Query Begin和Query End事件,详细信息为 DAX 查询。 对于DirectQuery Begin和DirectQuery End事件,详细信息是发送到基础源的 SQL 查询。 当前所选事件的 TextData 也会显示在屏幕底部的窗格中。 - EndTime:事件完成的时间。
- Duration:运行 DAX 或 SQL 查询的持续时间,以毫秒为单位。
- Error:是否发生了错误(发生错误时,该事件也显示为红色)。
捕获跟踪以帮助诊断潜在的性能问题:
打开单个 Power BI Desktop 会话,以避免多个工作区的文件夹产生混淆。
在 Power BI Desktop 执行一组意向操作。 再执行一些操作,确保将意向操作事件刷新到跟踪文件中。
打开 SQL Server Profiler 并检查跟踪。 请记住,关闭 Power BI Desktop 会删除跟踪文件。 此外,Power BI Desktop 中的其他操作不会立即显示。 必须关闭并重新打开跟踪文件才能看到新事件。
使各个会话保持在合理的范围内(可能是 10 秒而非数百秒的操作)。 此方法可以更轻松地解释跟踪文件。 跟踪文件的大小也有限制。 对于长会话,可能会删除早期事件。
了解查询的格式
Power BI Desktop 查询的一般格式为其引用的每个表使用子选择。 Power Query 编辑器查询定义子选择查询。 例如,假设 SQL Server 中有以下 TPC-DS 表:
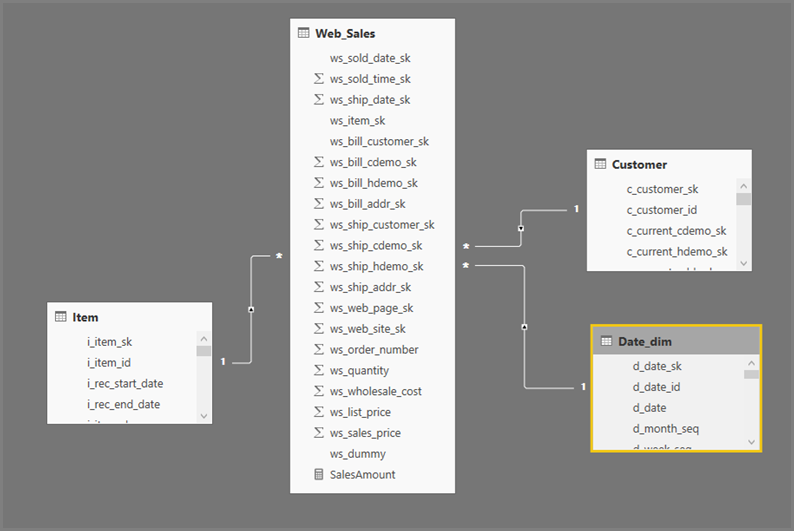
运行以下查询:
SalesAmount (SUMX(Web_Sales, [ws_sales_price]*[ws_quantity]))
by Item[i_category]
for Date_dim[d_year] = 2000
在 Power BI 中生成以下视觉对象:
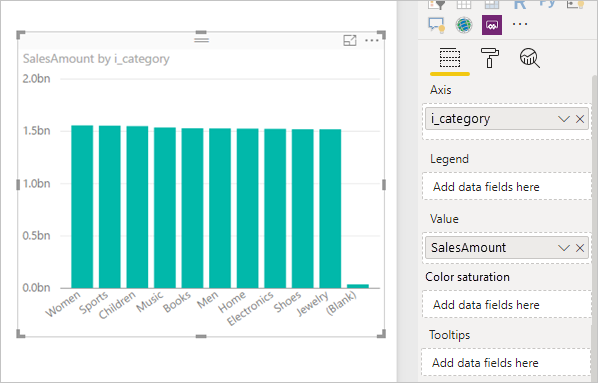
刷新该视觉对象会生成下图中的 SQL 查询。 有三个针对 Web_Sales、Item 和 Date_dim 的子选择查询,每个查询返回相应表上的所有列(即使视觉对象仅引用四列)。
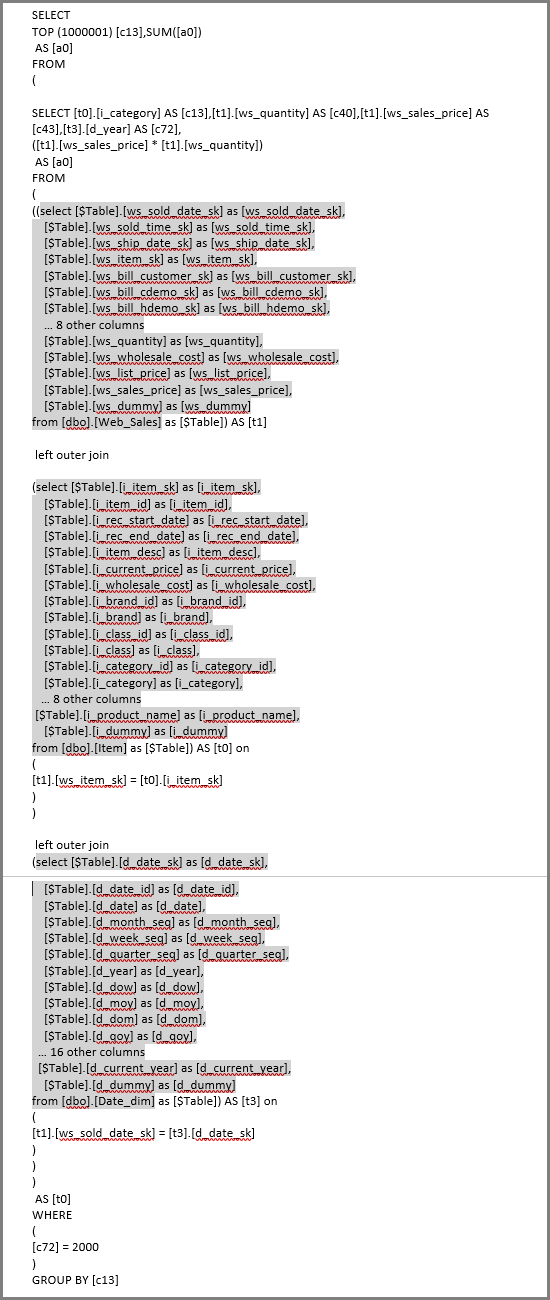
Power Query 编辑器定义确切的子选择查询。 尚未显示这样使用子选择查询会影响 DirectQuery 支持的数据源的性能。 SQL Server 等数据源优化了对其他列的引用。
Power BI 使用此模式,因为分析师直接提供 SQL 查询。 Power BI 按提供时的原样使用查询,而无需尝试重写它。
相关内容
有关 Power BI 中 DirectQuery 的详细信息,请参阅:
本文介绍了所有数据源中常见的 DirectQuery 的各个方面。 有关特定源的详细信息,请参阅以下文章: