重要
对机器学习工作室(经典)的支持将于 2024 年 8 月 31 日结束。 建议在该日期之前转换到 Azure 机器学习。
从 2021 年 12 月 1 日开始,你将无法创建新的机器学习工作室(经典)资源。 在 2024 年 8 月 31 日之前,可继续使用现有的机器学习工作室(经典)资源。
ML 工作室(经典)文档即将停用,将来可能不会更新。
配置和初始化 K 均值聚类分析模型
类别: 机器学习/初始化模型/聚类分析
模块概述
本文介绍如何使用机器学习工作室中的 K-Means 聚类分析模块 (经典) 创建未经训练的 K-means 聚类分析 模型。
K-means 是最简单且最知名的非监督式学习算法之一,可用于各种机器学习任务,例如检测异常数据、聚类分析文本文档,以及在使用其他分类或回归方法之前分析数据集。 若要创建聚类分析模型,请将此模块添加到试验中,连接数据集,并设置所需的群集数、创建群集时使用的距离指标等参数。
配置模块超参数后,将未训练的模型连接到 训练聚类分析模型 或 扫描聚类分析 模块,以根据提供的输入数据训练模型。 由于 K-means 算法是非监督式学习方法,因此有一个可选的标签列。
- 如果数据包含标签,可以使用标签值来指导群集选择并优化模型。
- 如果数据没有标签,则算法会完全基于数据来创建表示各种可能的类别的群集。
提示
如果训练数据具有标签,请考虑使用机器学习中提供的监督 分类 方法之一。 例如,使用多类决策树算法之一时,可以将聚类分析的结果与结果进行比较。
了解 k 均值聚类分析
一般来说,聚类使用迭代技术将数据集中的用例纳入特征类似的聚类中。 这种归组过程有助于浏览数据、标识数据中的异常情况,并最终帮助进行预测。 群集模型还有助于识别数据集中的关系,这些关系可能无法通过浏览或简单观察数据以逻辑推理的方式推导出来。 因此,通常会在机器学习任务的早期阶段使用群集化来探究数据和发现预期之外的相关性。
使用 k-means 方法配置聚类分析模型时,必须指定一个目标数字 k,指示模型中所需的质心数。 质心是代表每个群集的点。 K-means 算法通过最大程度地减少群集内平方和,将每个传入的数据点分配给一个群集。
在处理训练数据时,K 均值算法从一组随机选择的初始质心开始,这些质心用作每个聚类的起点,并应用 Lloyd 算法来迭代优化质心的位置。 当 K-means 算法满足以下一个或多个条件时,会停止构建和优化群集:
质心稳定,这意味着单个点的聚类分配不再更改,并且算法已在解决方案上收敛。
该算法已运行完指定的迭代数。
完成训练阶段后,使用 “将数据分配到群集 ”模块将新事例分配给 k 均值算法找到的一个群集。 通过计算新事例与每个聚类的质心之间的距离来执行群集分配。 将每个新事例分配到质心最近的群集中。
如何配置 K-Means 聚类分析
将 K-Means 聚类分析 模块添加到试验。
通过设置“创建训练器模式”选项来指定如何训练模型。
单个参数:如果知道要在群集模型中使用的确切参数,可以提供一组特定的值作为参数。
参数范围:如果不确定最佳参数,可以通过指定多个值并使用 扫描聚类分析 模块查找最佳配置来查找最佳参数。
训练器循环访问你提供的设置的多个组合,并确定产生最佳聚类分析结果的值组合。
对于“ 质心数”,键入希望算法以开头的聚类数。
无法保证模型生成完全如此数量的群集。 algorithn 从此数量的数据点开始,并循环访问以找到最佳配置,如 技术说明 部分所述。
如果要执行参数扫描,则属性的名称将更改为 质心数的范围。 可以使用 范围生成器 指定范围,也可以键入一系列数字,表示在初始化每个模型时要创建的不同分类数。
扫描的属性 “初始化 ”或“ 初始化 ”用于指定用于定义初始群集配置的算法。
第一个 N:从数据集中选择一些初始数据点,并将其用作初始均值。
也称为 Forgy 方法。
随机:该算法将某个数据点随机放置在某个群集中,然后计算初始平均值作为群集的随机分配点的质心。
也称为 随机分区 方法。
K-Means++ :这是默认的群集初始化方法。
David Arthur 和 Sergei Vassilvitskii 于 2007 年提出 K 均值 ++ 算法,以避免标准 k 均值算法聚类分析差。 K-means ++ 通过使用不同的方法来选择初始群集中心,改进了标准 K-means。
K-Means++Fast:K-means ++ 算法的变体,已针对更快的聚类分析进行优化。
均匀:质心位于 n 个数据点的 d-维空间中彼此等距的位置。
使用标签列:标签列中的值用于指导质心的选择。
对于“随机数种子”,可以选择键入一个值,将其用作群集初始化的种子。 该值可能会极大影响群集选择。
如果使用参数扫描,可以指定创建多个初始种子,以查找最佳初始种子值。 对于 “要扫描的种子数”,键入要用作起点的随机种子值的总数。
对于“指标”,选择用于测量群集矢量之间或新数据点与随机选择的质心之间的距离的函数。 机器学习支持以下群集距离指标:
欧几里得:K-Means 群集化常使用欧几里得距离作为群集散点图的度量值。 常用此指标是因为它最大程度地减少了点与质心之间的平均距离。
余弦:余弦函数用于测量聚类相似性。 余弦相似性在不关心向量的长度(仅关注其角度)的情况下非常有用。
对于 “迭代”,键入算法在最终确定质心选择之前应循环访问训练数据的次数。
可以调整此参数以平衡准确性与训练时间。
对于 “分配标签模式”,请选择一个选项,该选项指定如何处理标签列(如果数据集中存在)。
由于 K-Means 群集化是一种非监督式机器学习方法,因此标签是可选的。 但是,如果数据集已有标签列,则可以使用这些值来指导分类的选择,也可以指定忽略这些值。
忽略标签列:将忽略标签列中的值,构建模型时不会使用这些值。
填充缺失值:将标签列的值作为特征使用,帮助构建群集。 如果任何行缺少标签,则使用其他特征来输入值。
从最接近中心的点开始覆盖:使用最靠近当前质心的点的标签,将标签列值替换为预测的标签值。
定型模型。
结果
完成模型配置和训练后,即可获得可用于生成分数的模型。 然而,训练模型的方式有多种,查看和使用结果的方式也有多种:
捕获工作区中模型的快照
保存的模型将表示保存模型时的训练数据。 如果稍后更新试验中使用的训练数据,则不会更新已保存的模型。
查看模型中群集的可视化表示形式
如果使用了 训练聚类分析模型 模块
- 右键单击模块,然后选择“ 结果数据集”。
- 选择“可视化”。
如果使用了 扫描聚类分析 模块
添加“ 将数据分配到群集” 模块的实例,并使用 “最佳训练模型”生成分数。
右键单击“ 将数据分配到群集” 模块,选择“ 结果数据集”,然后选择“ 可视化”。
图表是使用 主组件分析生成的,这是一种用于压缩模型特征空间的数据科学技术。 该图表显示了一组压缩为两个维度的特征,这些特征最能描述分类之间的差异。 通过直观地查看每个分类的特征空间的一般大小以及分类重叠程度,可以了解模型的性能。
例如,以下 PCA 图表表示使用相同数据训练的两个模型的结果:第一个模型配置为输出两个分类,第二个配置为输出三个分类。 从这些图表中可以看到,增加分类数并不一定能改善类的分离。
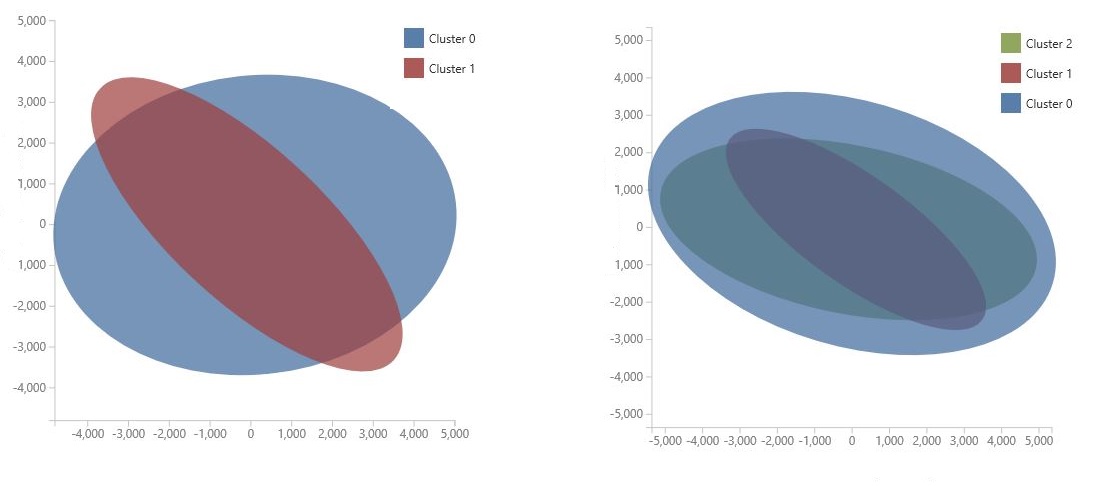
提示
使用 “扫描聚类分析 ”模块选择最佳超参数集,包括随机种子和起始质心数。
查看数据点列表及其所属的群集
有两个选项可用于查看包含结果的数据集,具体取决于训练模型的方式:
如果使用扫描 聚类分析 模块来训练模型
- 使用 “扫描聚类分析 ”模块中的复选框指定是要查看输入数据以及结果,还是只查看结果。
- 训练完成后,右键单击模块,然后选择“ 结果数据集 ” (输出编号 2)
- 单击“ 可视化”。
如果使用了 训练聚类分析模型 模块
- 添加 “将数据分配到群集” 模块,并将训练的模型连接到左侧输入。 将数据集连接到右侧输入。
- 将 “转换为数据集” 模块添加到试验,并将其连接到“ 将数据分配到群集”的输出。
- 使用“ 将数据分配给群集 ”模块中的复选框指定是要查看输入数据和结果,还是只查看结果。
- 运行试验,或仅运行 “转换为数据集” 模块。
- 右键单击“ 转换为数据集”,选择“ 结果数据集”,然后单击“ 可视化”。
如果包含输入数据列,则输出首先包含输入数据列,以及每行输入数据的以下列:
赋值:赋值是介于 1 和 n 之间的值,其中 n 是模型中的分类总数。 每行数据只能分配给一个群集。
DistancesToClusterCenter no.n:此值测量从当前数据点到群集的质心的距离。 训练模型中的每个分类的输出中都有一个单独的列。
分类距离的值基于在“ 测量群集结果的指标”选项中选择的距离指标。 即使对聚类分析模型执行参数扫描,扫描期间也只能应用一个指标。 如果更改指标,可能会获得不同的距离值。
可视化群集内距离
在上一部分的结果数据集中,单击每个分类的距离列。 工作室 (经典) 显示一个直方图,该直方图可视化分类中点的距离分布。
例如,以下直方图使用四个不同的指标显示与同一试验的分类距离的分布。 参数扫描的所有其他设置都是相同的。 更改指标会导致一个模型中出现不同数量的群集。
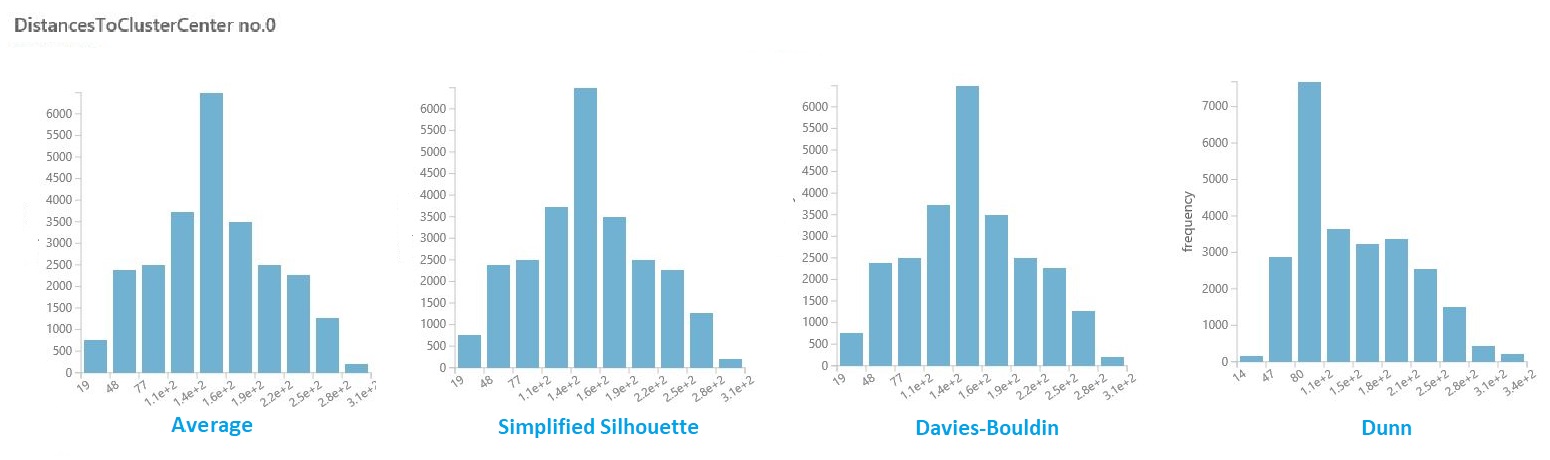
一般情况下,应选择一个指标,用于最大化不同类中数据点之间的距离,并最小化类中的距离。 可以使用“ 统计信息 ”窗格中的预计算方法和其他值来指导你做出此决定。
有关如何生成最佳群集模型的提示
众所周知,在聚类分析期间使用的种子设定过程可能会显著影响模型。 种子设定意味着将点初始放置到有效的质心中。
例如,如果数据集包含许多离群值,并且选择了一个离群值来设定群集种子,则没有其他数据点适合该分类,并且该群集可以是单一实例:即只有一个点的群集。
有多种方法可避免此问题:
使用参数扫描更改质心数并尝试多个种子值。
创建多个模型,使用不同指标或增加循环访问次数。
使用 PCA 等方法查找对聚类分析产生不利影响的变量。 有关此技术的演示,请参阅 查找类似公司 示例。
通常,使用聚类分析模型时,任何给定的配置都可能导致一组本地优化的群集。 换句话说,模型返回的聚类集仅适合当前数据点,不能通用化为其他数据。 如果你使用不同的初始配置,则 K 平均值方法可能会确定不同的配置(或许是高级配置)。
重要
建议始终试验参数,创建多个模型,并比较生成的模型。
示例
有关如何在机器学习中使用 K-means 聚类分析 的示例,请参阅 Azure AI 库中的以下试验:
技术说明
假设有特定数量的聚类 (K) 用于寻找一组 D 维空间数据点(有 N 个),则 K 平均值算法会构建如下聚类:
该模块使用定义找到的 K 群集的最终质心初始化 K-by-D 数组。
默认情况下,模块将第一个 K 数据点分配给 K 群集。
此方法从最初的一组 K 个中心开始,使用 Lloyd 算法以迭代的方式优化中心位置。
当中心稳定或运行完指定次数的迭代后,此算法终止。
相似性指标(默认为欧几里得距离)用于将每个数据点分配到中心最接近的聚类中。
警告
模块参数
| 名称 | 范围 | 类型 | 默认 | 说明 |
|---|---|---|---|---|
| 质心数 | >=2 | Integer | 2 | 质心数 |
| 指标 | 列表(子集) | 指标 | 欧几里得 | 选定的指标 |
| 初始化 | 列出 | 质心初始化方法 | K 平均值++ | 初始化算法 |
| 迭代 | >=1 | Integer | 100 | 迭代数 |
Outputs
| 名称 | 类型 | 说明 |
|---|---|---|
| 未训练的模型 | ICluster 接口 | 未训练的 K 平均值聚类模型 |
例外
有关所有异常的列表,请参阅 机器学习模块错误代码。
| 例外 | 描述 |
|---|---|
| 错误 0003 | 如果一个或多个输入为 NULL 或为空,将出现异常。 |