你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
多个 GPU 和计算机
1.简介
CNTK 目前支持四种并行 SGD 算法:
先决条件
若要运行并行训练,请确保已安装消息传递接口 (MPI) 实现:
在 Windows 上,从 此下载页安装版本 7 (7.0.12437.6) Microsoft MPI (MS-MPI) (消息传递接口标准的 Microsoft 实现),仅标记为页面标题中的“版本 7”。 单击“下载”按钮,然后选择运行时 ()
MSMpiSetup.exe。在 Linux 上,安装 OpenMPI 版本 1.10.x。 请按照 此处 的说明自行生成。
2. 在 Python 中配置 CNTK 中的并行训练
若要在 Python 中使用数据并行PYTHON,用户需要创建分布式学习器并将其传递给训练器:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 32, # non-quantized gradient accumulation
distributed_after = 0) # no warm start
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
对于用户定义的训练循环 (而不是training_session) ,用户在读取示例) 后distributed_after,需要传入num_data_partitions和partition_index访问MinibatchSource.next_minibatch()方法,以便不同的 MPI 节点从不同的数据分区读取数据 (。
请注意, Communicator.finalize() 仅当分布式训练成功完成时,才应调用。 如果分布式辅助角色失败,则不应调用此方法。
有关功能齐全的示例,请参阅 ConvNet 示例。
3. 在 BrainScript 中配置 CNTK 中的并行训练
若要在 CNTK BrainScript 中启用并行训练,首先需要在配置文件或命令行中打开以下开关:
parallelTrain = true
其次, SGD 配置文件中的块应包含以下参数命名 ParallelTrain 的子块:
parallelizationMethod: (强制性) 合法值是DataParallelSGD,BlockMomentumSGD也是ModelAveragingSGD。这指定要使用的并行算法。
distributedMBReading: (可选) 接受布尔值:true或false;默认值为false建议打开分布式迷你包读取,以最大程度地减少每个辅助角色的 I/O 成本。 如果使用 CNTK 文本格式读取器、图像读取器或 复合数据读取器,则应将 distributedMBReading 设置为 true。
parallelizationStartEpoch: (可选) 接受整数值;默认值为 1。这指定从哪个时期开始使用并行训练算法;在此之前,所有辅助角色都执行相同的训练,但只允许一个辅助角色保存模型。 如果并行训练需要一些“暖启动”阶段,则此选项非常有用。
syncPerfStats: (可选) 接受整数值;默认值为 0。这指定输出性能统计信息的频率。这些统计信息包括同步期间用于通信和/或计算的时间,这对于了解并行训练算法的瓶颈非常有用。
0 表示不会打印任何统计信息。其他值指定将输出统计信息的频率。例如,
syncPerfStats=5表示每 5 次同步后都会输出统计信息。一个子块,指定每个并行训练算法的详细信息。 子块的名称应等于
parallelizationMethod。 强制 ()
对于不同的并行化方法,Python 提供了更大的灵活性和用法。
4. 使用 CNTK 运行并行训练
CNTK 中的并行化是通过 MPI 实现的。
4.1 使用 BrainScript 运行并行训练
鉴于上述任何并行训练 BrainScript 配置,可以使用以下命令启动并行 MPI 作业:
使用 Linux 在同一台计算机上进行并行训练:
mpiexec --npernode $num_workers $cntk configFile=$config使用 Windows 在同一台计算机上进行并行训练:
mpiexec -n %num_workers% %cntk% configFile=%config%使用 Linux 跨多个计算节点进行并行训练:
步骤 1:使用收藏的编辑器创建主机文件$hostfile
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
其中,name_of_node (n) 只是工作节点的 DNS 名称或 IP 地址。
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile $cntk configFile=$config
```
使用 Windows 跨多个计算节点进行并行训练:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... %cntk% configFile=%config%
其中 $cntk 应引用 CNTK 可执行文件的路径 ($x 是 Linux shell 替代环境变量的方式,相当于 %x% 在 Windows shell) 中。
4.2 使用 Python 运行并行训练
有关使用 Python 的 CNTK v2 分布式训练示例,可在此处找到:
给定 CNTK v2 Python 脚本 training.py ,可以使用以下命令启动并行 MPI 作业:
使用 Linux 在同一台计算机上进行并行训练:
mpiexec --npernode $num_workers python training.py使用 Windows 在同一台计算机上进行并行训练:
mpiexec -n %num_workers% python training.py使用 Linux 跨多个计算节点进行并行训练:
步骤 1:使用收藏的编辑器创建主机文件$hostfile
# Comments are allowed after pound sign name_of_node1 slots=4 # we want 4 workers on node1 name_of_node2 slots=2 # we want 2 workers on node2
其中,name_of_node (n) 只是工作节点的 DNS 名称或 IP 地址。
Step 2: Execute your workload
```
mpiexec -hostfile $hostfile python training.py
```
使用 Windows 跨多个计算节点进行并行训练:
mpiexec --hosts %num_nodes% %name_of_node1% %num_workers_on_node1% ... python training.py
5 Data-Parallel 使用 1 位 SGD 进行培训
CNTK 实现 1 位 SDK 技术 [1]。 此技术允许将每个小块分发给 K 辅助角色。 然后,将交换和聚合生成的分部渐变,然后在每个小块之后进行交换和聚合。 “1 位”是指 Microsoft 开发的一种技术,用于将每个渐变值交换的数据量减少到一个位。
5.1“1位SGD”算法
在每个迷你包之后直接交换部分渐变需要禁止的通信带宽。 若要解决此问题,1 位 SGD 会积极量化每个渐变值...到单个位 (!每个值) 。 实际上,这意味着会剪裁较大的渐变值,而小值是人为膨胀的。 令人惊讶的是,如果仅当使用 技巧 时,这不会损害收敛。
诀窍是,对于每个小块,该算法将) 工作器之间交换的量化渐变 (与应交换) 的原始渐变值 (进行比较。 计算并记住两个 (量化错误) 之间的差值作为 残差。 然后将此残差添加到 下一 个迷你包。
因此,尽管具有侵略性的量化,但最终会以完全的准确性交换每个渐变值:只是在延迟。 试验表明,只要此模型与热启动相结合, (在没有并行化) 的一小部分训练数据上训练的种子模型,此方法就表明没有或非常小的准确性损失,同时允许速度离线性 (在计算太小的子批时 GPU 变得效率低下) 。
为了获得最大效率,技术应与 自动迷你Batch缩放相结合,其中,训练器会尝试增加迷你Batch大小。 在评估即将推出的数据时期的一小部分时,训练器将选择不会损害收敛的最大迷你块大小。 在这里,CNTK 以微分大小不可知的方式指定学习速率和动量超参数。
5.2 在 BrainScript 中使用 1 位 SGD
1 位 SGD 本身没有其他参数,除了启用它,之后它应该开始。 此外,应启用自动小块缩放。 通过将以下参数添加到 SGD 块来配置这些参数:
SGD = [
...
ParallelTrain = [
DataParallelSGD = [
gradientBits = 1
]
parallelizationStartEpoch = 2 # warm start: don't use 1-bit SGD for first epoch
]
AutoAdjust = [
autoAdjustMinibatch = true # enable automatic growing of minibatch size
minibatchSizeTuningFrequency = 3 # try to enlarge after this many epochs
]
]
请注意,Data-ParallelData-Parallel,还可以在没有 1 位量子化的情况下使用。 但是,在典型方案中,尤其是每个模型参数仅应用一次(例如源转发 DNN)的方案,由于通信带宽需求高,这不会有效。
下面的第 2.2.3 部分显示语音任务上 1 位的 1 位 SGD 的结果,与接下来介绍的 Block-Momentum SGD 方法相比。 这两种方法在准线性加速时没有或几乎没有丢失准确性。
5.3 在 Python 中使用 1 位 SDK
若要在 Python 中使用数据并行的 SGD(可选)与 1 位 SGD,用户需要创建分布式学习器并将其传递给训练器:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_after = epoch_size # number of samples to warm start with
distributed_learner = distributed.data_parallel_distributed_learner(
learner = learner,
num_quantization_bits = 1, # change to 32 for non-quantized gradient accumulation
distributed_after = distributed_after) # warm start: no parallelization is used for the first 'distributed_after' samples
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
在创建distributed_learner期间将num_quantization_bits更改为 32,使其使用非量化Data-ParallelData-ParallelData-ParallelData-Parallel。 在这种情况下,无需预热启动。
6 Block-Momentum SGD
Block-Momentum SGD 是实现“块模型更新和筛选”,或 BMUF,算法,短 块动量 [2]。
6.1 Block-Momentum SG算法
下图汇总了Block-Momentum算法中的过程。

6.2 在 BrainScript 中配置 Block-Momentum SGD
若要使用 Block-Momentum SGD,需要使用以下选项在SGD块中命名BlockMomentumSGD的子块:
syncPeriod. 这类似于syncPeriodinModelAveragingSGD,它指定执行模型同步的频率。BlockMomentumSGD默认值为 120,000。resetSGDMomentum. 这意味着,在每个同步点之后,本地 SGD 中使用的平滑渐变将设置为 0。 此变量的默认值为 true。useNesterovMomentum. 这意味着在块级别应用 Nesterov 样式的动量更新。 有关详细信息,请参阅 [2]。 此变量的默认值为 true。
块势头和块学习速率通常根据所使用的辅助角色数自动设置,即
block_momentum = 1.0 - 1.0/num_of_workers
block_learning_rate = 1.0
我们的经验表明,这些设置通常产生类似的收敛与标准SGTU算法高达 64 个 GPU,这是我们执行的最大实验。 还可以使用以下选项手动指定这些参数:
blockMomentumAsTimeConstant指定块级模型更新中低传递筛选器的时间常量。 计算结果如下:blockMomentumAsTimeConstant = -syncPeriod / log(block_momentum) # or inversely block_momentum = exp(-syncPeriod/blockMomentumAsTimeConstant)blockLearningRate指定块学习速率。
下面是Block-Momentum SGD 配置部分的示例:
learningRatesPerSample=0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
# Use it for BlockMomentumSGD as well
ParallelTrain = [
parallelizationMethod = BlockMomentumSGD
distributedMBReading = true
syncPerfStats = 5
BlockMomentumSGD=[
syncPeriod = 120000
resetSGDMomentum = true
useNesterovMomentum = true
]
]
6.3 在 BrainScript 中使用 Block-Momentum SGD
1. 重新优化学习参数
若要实现每个辅助角色的类似吞吐量,必须增加与辅助角色数成比例的微型样本数。 可以通过调整
minibatchSize或nbruttsineachrecurrentiter根据是否使用帧模式随机化来实现此目的。无需调整学习速率 (与Model-Averaging) 不同。
建议将 Block-Momentum SGD 与暖启动模型配合使用。 在我们的语音识别任务中,从训练在 24 小时 (860 万个样本的种子模型开始,) 到 120 小时 (4320 万个样本) 使用标准 SDK 的数据,实现合理的收敛。
2. ASR 试验
我们使用Block-Momentum SDK 和 Data-Parallel (1 位) SDK 算法在 2600 小时语音识别任务上训练 DNN 和 LSTM,并将单词识别精度与加速因素进行比较。 下表和图显示了结果 (*) 。

(*) :峰值加速因子:对于 1 位 (,以最高速度系数 (测量,而在一个迷你袋中实现的) 为) :对于块动量,由一个块中实现的最大速度测量:平均加速因子:按观察到的已用时间除以所观测的已用时间的工时的工时。。。 由于 I/O 中的延迟,这两个指标会极大地影响平均加速因子度量,尤其是在在微型批处理级别执行同步时。 同时,最大加速系数相对可靠。
3. 注意事项
建议设置为
resetSGDMomentumtrue;否则,它通常会导致训练条件的分歧。 在每次模型同步后,将 SGD 势头重置为 0,实质上切断了最后一个小盘的贡献。 因此,建议不要使用大型SGD动力。 例如,对于 120,000 个syncPeriod,如果用于 SGD 的势头为 0.99,则我们观察到一个显著的准确度损失。 将 SGD 动力减少到 0.9、0.5,甚至完全禁用它可提供类似的精度,因为标准 SGD 算法可以实现这一点。Block-Momentum SGD 延迟,并在后续块之间从一个块分发模型更新。 因此,必须确保模型同步在训练中执行得足够频繁。 快速检查是要使用的
blockMomentumAsTimeConstant。 建议唯一训练样本N的数量应满足以下公式:N >= blockMomentumAsTimeConstant * num_of_workers ~= syncPeriod * num_of_workers^2
近似源于以下事实: (1) 块动量通常设置为 (1-1/num_of_workers); (2) log(1-1/num_of_workers)~=-num_of_workers。
6.4 在 Python 中使用Block-Momentum
若要在 Python 中启用Block-Momentum,与 1 位 SDK 类似,用户需要创建并传递块动力分布式学习器给教练:
from cntk import distributed
...
learner = cntk.learner.momentum_sgd(...) # create local learner
distributed_learner = cntk.distributed.block_momentum_distributed_learner(learner, block_size=block_size)
...
minibatch_source = MinibatchSource(...)
...
trainer = Trainer(z, ce, pe, distributed_learner)
...
session = training_session(trainer=trainer, mb_source=minibatch_source, ...)
session.train()
...
distributed.Communicator.finalize() # must be called to finalize MPI in case of successful distributed training
有关功能齐全的示例,请参阅 ConvNet 示例。
7 Model-Averaging SGD
模型平均型 SGD 是 [3,4] 中详述的模型平均算法的实现,不使用自然渐变。 此处的想法是让每个辅助角色处理一部分数据,但在指定时间段后对每个辅助角色的模型参数求平均值。
与1位SGD和Block-Momentum SGD相比,Model-Averaging SGD通常收敛得更慢,效果更差,因此不再推荐使用。
若要使用 Model-Averaging SGD,需要使用以下选项在SGD块中命名ModelAveragingSGD的子块:
syncPeriod指定每个辅助角色在执行模型平均值之前需要处理的样本数。 默认值为 40,000。
7.1 在 BrainScript 中使用 Model-Averaging SGD
若要使Model-AveragingModel-AveragingModel-Averaging最有效且高效,用户需要优化一些超参数:
minibatchSize或nbruttsineachrecurrentiter。 假设n辅助角色正在参与 Model-Averaging SGD 配置,当前的分布式读取实现将加载1/n到每个辅助角色中的第 1 个微型包中。 因此,若要确保每个辅助角色生成与标准 SGD 相同的吞吐量,必须放大小块大小n-折叠。 对于使用帧模式随机化训练的模型,可以通过按时间放大minibatchSizen来实现;对于使用序列模式随机化(如RNN)训练的模型,某些读取器需要改为增加nbruttsineachrecurrentitern。learningRatesPerSample. 我们的经验表明,为了与标准SGD类似的收敛,有必要增加learningRatesPerSamplen时间。 可在 [2] 中找到说明。 由于学习率增加,因此需要额外的照顾来确保训练不会分流,这实际上是Model-Averaging SGD的主要注意事项。 如果观察到训练条件的增加,则可以使用AutoAdjust设置重新加载上一个最佳模型。暖开始。 发现,如果从种子模型开始,Model-Averaging (没有并行化) ,则Model-Averaging SGD通常收敛得更好。 在我们的语音识别任务中,从训练在 24 小时 (860 万个样本的种子模型开始,) 到 120 小时 (4320 万个样本) 使用标准 SDK 的数据,实现合理的收敛。
下面是配置部分的示例 ModelAveragingSGD :
learningRatesPerSample = 0.002
# increase the learning rate by 4 times for 4-GPU training.
# learningRatesPerSample = 0.0005
# 0.0005 is the optimal learning rate for single-GPU training.
ParallelTrain = [
parallelizationMethod = ModelAveragingSGD
distributedMBReading = true
syncPerfStats = 20
ModelAveragingSGD = [
syncPeriod=40000
]
]
7.2 在 Python 中使用 Model-Averaging SDK
本文正在编写中。
8 Data-Parallel 参数服务器的训练
参数服务器是分布式机器学习 [5][6][7] 中广泛使用的框架。 它带来的最重要的好处是与许多辅助角色进行异步并行训练。 它将参数服务器作为分布式模型存储引入。 参数服务器框架不直接利用 AllReduce 基元在辅助角色之间同步参数更新,而是为用户提供“添加”和“Get”等接口,以便本地辅助角色从参数服务器更新和检索全局参数。 这样,本地工作人员无需在培训过程中互相等待,这可以节省大量时间,尤其是在辅助角色数量很大时。
此外,由于参数服务器是存储模型参数的分布式框架,辅助角色只能在小型批处理训练过程中检索所需的参数,这在设计分布式训练方法方面具有很好的灵活性,并且提高了使用稀疏模型更新进行训练时的效率。 在此版本中,我们将首先重点介绍异步并行训练,稍后我们将详细介绍如何使用稀疏更新利用参数服务器框架进行高效的模型训练。
8.1 使用 Data-Parallel ASGD
- 若要将参数服务器用于异步 SDK (缩写。作为 ASGD) ,应构建支持 Multiverso 的 CNTK,Multiverso 是 Microsoft Research Asia 团队开发的分布式机器学习任务的常规参数服务器框架。
Clone Code:请使用以下命令克隆 CNTK 根文件夹下的代码:
git submodule update --init Source/Multiverso
Linux:请在配置过程中生成--asgd=yes。Windows:请CNTK_ENABLE_ASGD添加到系统环境并将值设置为true
- 暖开始。 在某些情况下,最好从种子模型 (从种子模型开始异步模型训练) 。 从某种意义上说,异步工时,由于辅助角色的异步更新延迟,为培训带来了更多的噪音。 某些模型对开始的此类噪音非常敏感,这可能会导致模型训练的分歧。 在这种情况下,需要一个 温暖的开始 。
8.2 在 BrainScript 中配置 Data-Parallel ASGD
若要在 CNTK 中使用 Data-Parallel ASGD,需要在 SDK 块中使用子块 DataParallelASGD,并使用以下选项
-
syncPeriodPerWorkers. 它指定每个辅助角色在与参数服务器通信之前需要处理的样本数。 默认值为 256。 建议将其用作迷你包的大小。 很明显,频繁同步将导致大量的通信成本。 在我们的测试中,在大多数情况下,不必将值设置为 1。
-
usePipeline. 它指定是否打开模型检索管道和本地计算。 打开管道会显著增加训练的总体吞吐量,因为它会隐藏部分或全部通信成本。 但是,有时它可能会减缓聚合速率,因为添加管道将引入更多的延迟。 总的来说,在大多数情况下,管道将保存时钟时间。
-
AdjustLearningRateAtBeginning. 根据最近发表的论文[5],训练 ASGD 不太稳定,它要求使用更小的学习率,以避免偶尔爆炸的训练损失,因此学习过程变得效率较低。 但是,我们发现并非所有任务都不需要使用较低的学习率。 对于在开始时敏感的任务,我们以小学习率开始训练,并在训练过程的开始阶段逐渐扩大它,直到它达到在正常SGD中使用的初始学习速率。 这样,最终的准确性将匹配SGD,同时与 ASGD 的速度匹配。 因此,我们为 ASGD 用户提供此选项来利用此技巧。 它是 DataParallelASGD 中具有两个参数的子块: adjustCoefficient 和 adjustNBMiniBatch。 逻辑是,学习速率从新元初始学习速率 的 adjustCoefficient 开始,并通过调整新元初始学习速率来增加每 一个adjustNBMiniBatch 迷你批。
下面是配置部分的示例 DataParallelASGD :
learningRatesPerSample = 0.0005
ParallelTrain = [
parallelizationMethod = DataParallelASGD
distributedMBReading = true
syncPerfStats = 20
DataParallelASGD = [
syncPeriodPerWorker=256
usePipeline = true
AdjustLearningRateAtBeginning = [
adjustCoefficient = 0.2
adjustNBMiniBatch = 1024
# Learning rate will be adjusted to original one after ((1 / adjustCoefficient) * adjustNBMiniBatch) samples
# which is 5120 in this case
]
]
]
8.3 在 Python 中配置 Data-Parallel ASGD
本文正在编写中。
8.4 试验
下图显示了使用 CIFAR-10 数据集测试 ASGD 的试验。 此试验中使用的模型是一个 20 层 ResNet。 异步算法可降低等待所有工作器节点的成本。 在本例中,ASGD 明显快于同步算法,如 MA 和 SSGD。 *在试验中,所有并行模式都会同步每个迭代 (小型批处理更新) 的参数。 对于 SSGD,我们使用了 32 位参数更新。 异步算法在样本处理速度测量的训练吞吐量方面具有显著优势,尤其是在工作节点数达到 16 时。
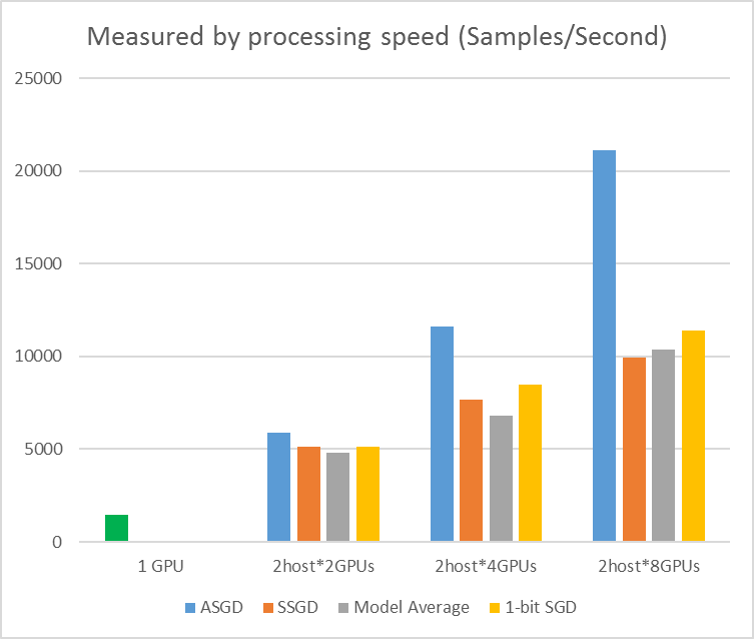 图 2.4 不同训练方法的速度
图 2.4 不同训练方法的速度
参考
[1] F. Seide、Hao Fu、Jasha Droppo、Gang Li 和董宇,“1 位随机渐变下降及其应用于语音 DNN 的数据并行分布式训练”,在 2014 年 Interspeech 的《程序》中。
[2] 2016 年 ICASSP 的《ICASSP 程序》中的“通过增量块并行优化和块式模型更新筛选对深度学习计算机进行可缩放训练” [2] K. Chen 和 Q. Huo。
[3] M. Zinkevich, M. Weimer, L. Li, and A. J. Smola, “并行随机渐变下降” , 在 NIPS, 2010 年, pp. 2595 – 2603。
[4] D. Povey, X. 张, 和 S. Khudanpur, “与自然渐变和参数平均的 DNN 并行训练”, 在 2014 年国际会议上。
[5]陈 J、蒙加 R、Bengio S 等人重新访问分布式同步 SSD。 ICLR, 2016.
[6]迪恩·杰弗里、格雷格·科拉多、拉贾特·蒙加、凯晨、马蒂乌·德文、马克·毛、安德鲁·高级等人。大规模分布式深度网络。 在神经信息处理系统的推进中,pp. 1223-1231。 2012.
[7]李穆、李周、齐昭杨、亚伦·李、费霞、大卫·安德森和亚历山大·斯莫拉。 “分布式机器学习的参数服务器。在大学习NIPS研讨会上,第6卷,p.2。 2013.