你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
目录
摘要

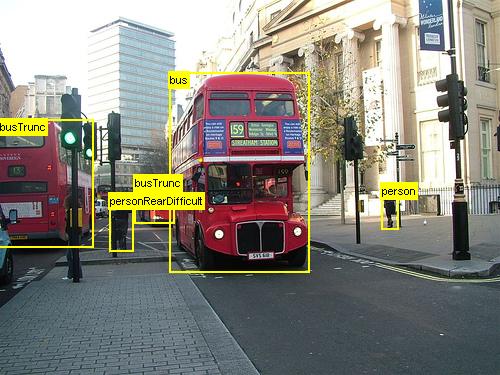
本教程介绍如何在 CNTK Python API 中使用快速 R-CNN。 此处介绍了使用 BrainScript 和 cnkt.exe的快速 R-CNN。
上面的示例图像和对象注释用于杂货数据集 (左侧) ,以及本教程中使用的 pascal VOC 数据集 (右) 。
Fast R-CNN 是 罗斯·吉希克 在 2015 年提出的对象检测算法。 该报已接受ICV 2015年,并存档。https://arxiv.org/abs/1504.08083 快速 R-CNN 基于以前的工作,使用深度卷积网络有效地对对象建议进行分类。 与以前的工作相比,Fast R-CNN 采用 感兴趣的池方案区域 ,该方案允许重复使用卷积层中的计算。
安装
若要运行此示例中的代码,需要 CNTK Python 环境, (此处 获取设置帮助) 。 请在 cntk Python 环境中安装以下附加包
pip install opencv-python easydict pyyaml dlib
用于边界框回归和非最大抑制的预编译二进制文件
该文件夹 Examples\Image\Detection\utils\cython_modules 包含运行 Fast R-CNN 所需的预编译二进制文件。 当前包含在存储库中的版本是 Python 3.5 for Windows 和 Python 3.5、3.6 for Linux,全部为 64 位。 如果需要其他版本,可以按照中所述的步骤编译它
- Linux:https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
将生成的cython_bbox和 (和/或gpu_nms) 二进制文件复制到 $FRCN_ROOT/lib/utils$CNTK_ROOT/Examples/Image/Detection/utils/cython_modules。cpu_nms
示例数据和基线模型
我们使用预先训练的 AlexNet 模型作为 Fast-R-CNN 训练的基础, (用于 VGG 或其他 基本模型,请参阅使用其他基本模型。 可以通过从 FastRCNN 文件夹运行以下 Python 命令,下载示例数据集和预训练的 AlexNet 模型:
python install_data_and_model.py
- 了解如何 使用不同的基本模型
- 了解如何 在 Pascal VOC 数据上运行快速 R-CNN
- 了解如何 在自己的数据上运行快速 R-CNN
运行玩具示例
训练和评估快速 R-CNN 运行
python run_fast_rcnn.py
使用 AlexNet 在杂货上使用 2000 个 ROIS 进行训练的结果应如下所示:
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
可视化从FastRCNN文件夹打开FastRCNN_config.py的图像上的预测边界框和标签并设置
__C.VISUALIZE_RESULTS = True
如果运行python run_fast_rcnn.py,图像将保存到FastRCNN/Output/Grocery/文件夹中。
在 Pascal VOC 上训练
若要下载 Pascal 数据并创建 CNTK 格式的 Pascal 注释文件,请运行以下脚本:
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
Change the dataset_cfg in the get_configuration() method of run_fast_rcnn.py to
from utils.configs.Pascal_config import cfg as dataset_cfg
现在,你已设置为使用 python run_fast_rcnn.pyPascal VOC 2007 数据训练。 请注意,训练可能需要一段时间。
根据自己的数据训练
准备自定义数据集
选项 #1:Visual 对象标记工具 (建议)
Visual 对象标记工具 (VOTT) 是用于标记视频和图像资产的跨平台注释工具。

VOTT 提供以下 功能:
- 使用 Camshift 跟踪算法在视频中对对象进行计算机辅助标记和跟踪。
- 将标记和资产导出到 CNTK Fast-RCNN 格式以训练对象检测模型。
- 在新视频上运行和验证经过训练的 CNTK 对象检测模型,以生成更强大的模型。
如何使用 VOTT 批注:
选项 #2:使用批注脚本
若要在自己的数据集上训练 CNTK Fast R-CNN 模型,我们提供了两个脚本来批注图像上的矩形区域,并将标签分配给这些区域。
脚本将按照运行 Fast R-CNN () A1_GenerateInputROIs.py 的第一步的要求,以正确的格式存储批注。
首先,将图像存储在以下文件夹结构中
<your_image_folder>/negative- 用于训练不包含任何对象的图像<your_image_folder>/positive- 用于训练包含对象的图像<your_image_folder>/testImages- 用于测试包含对象的图像
对于负图像,无需创建任何批注。 对于其他两个文件夹,请使用提供的脚本:
- 运行
C1_DrawBboxesOnImages.py以在图像上绘制边界框。- 在运行之前,
/positive脚本集imgDir = <your_image_folder>(或/testImages) 。 - 使用鼠标光标添加批注。 批注图像中的所有对象后,按键“n”将写入 .bboxes.txt 文件,然后继续下一个图像,“u”撤消 (,即删除最后一个矩形) ,“q”退出批注工具。
- 在运行之前,
- 运行
C2_AssignLabelsToBboxes.py以将标签分配给边界框。- 在脚本集中
imgDir = <your_image_folder>(/positive或/testImages) 运行... - ...并调整脚本中的 类 以反映对象类别,例如
classes = ("dog", "cat", "octopus")。 - 该脚本为每个图像加载这些手动批注矩形,并逐个显示它们,并要求用户通过单击窗口左侧的相应按钮来提供对象类。 标记为“未决定”或“排除”的地面真相注释被完全排除在进一步处理之外。
- 在脚本集中
训练自定义数据集
将图像存储在描述的文件夹结构中并批注后,请运行
python Examples/Image/Detection/utils/annotations/annotations_helper.py
将该脚本中的文件夹更改为数据文件夹后。 最后,按照现有示例在utils\configs文件夹中创建一个MyDataSet_config.py:
__C.CNTK.DATASET == "YourDataSet":
__C.CNTK.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.CNTK.CLASS_MAP_FILE = "class_map.txt"
__C.CNTK.TRAIN_MAP_FILE = "train_img_file.txt"
__C.CNTK.TEST_MAP_FILE = "test_img_file.txt"
__C.CNTK.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.CNTK.TEST_ROI_FILE = "test_roi_file.txt"
__C.CNTK.NUM_TRAIN_IMAGES = 500
__C.CNTK.NUM_TEST_IMAGES = 200
__C.CNTK.PROPOSAL_LAYER_SCALES = [8, 16, 32]
请注意, __C.CNTK.PROPOSAL_LAYER_SCALES 不用于快速 R-CNN,仅适用于更快的 R-CNN。
若要在数据上训练和评估快速 R-CNN,run_fast_rcnn.py请dataset_cfgget_configuration()更改其方法
from utils.configs.MyDataSet_config import cfg as dataset_cfg
并运行 python run_fast_rcnn.py。
技术详细信息
快速 R-CNN 算法在 “算法详细信息 ”部分中进行了说明,并简要概述了如何在 CNTK Python API 中实现该算法。 本部分重点介绍如何配置快速 R-CNN,以及如何使用不同的基本模型。
参数
参数分为三个部分:
- 检测器参数 (请参阅
FastRCNN/FastRCNN_config.py) - 数据集参数 (请参阅示例
utils/configs/Grocery_config.py) - (查看基础模型参数,
utils/configs/AlexNet_config.py例如)
在方法run_fast_rcnn.py中get_configuration()加载和合并这三个部分。 在本部分中,我们将介绍检测器参数。 此处介绍了数据集参数,此处提供了基本模型参数。 在下面,我们将经历最重要的参数。FastRCNN_config.py 文件中还注释掉了所有参数。 配置使用 EasyDict 包,允许轻松访问嵌套字典。
# Number of regions of interest [ROIs] proposals
__C.NUM_ROI_PROPOSALS = 200 # use 2000 or more for good results
# the minimum IoU (overlap) of a proposal to qualify for training regression targets
__C.BBOX_THRESH = 0.5
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
ROI 建议是在使用包中的选择性搜索实现 dlib 的第一个纪元中快速计算的。 生成的建议数由 __C.NUM_ROI_PROPOSALS 参数控制。 我们建议使用大约 2000 项建议。 回归头仅在具有重叠 (IoU) 与至少 __C.BBOX_THRESH一个地面真相框重叠的 ROIS 上训练。
__C.INPUT_ROIS_PER_IMAGE 指定每个图像的最大地面实数批注数。 CNTK 当前需要设置最大数字。 如果批注较少,则它们将在内部填充。 __C.IMAGE_WIDTH 以及 __C.IMAGE_HEIGHT 用于调整大小并填充输入图像的维度。
__C.TRAIN.USE_FLIPPED = True 通过翻转所有其他纪元的所有图像来增强训练数据,即第一个纪元具有所有常规图像,第二个具有翻转的所有图像,依此类推。 __C.TRAIN_CONV_LAYERS 确定卷积层(从输入到卷积特征图)是否会训练或修复。 修复凸层权重意味着从基础模型获取权重,并在训练期间未修改。 (还可以指定要训练的凸层数,请参阅“ 使用不同的基本模型 ”部分) 。
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# If set to True the following two parameters need to point to the corresponding files that contain the proposals:
# __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE
# __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE
__C.USE_PRECOMPUTED_PROPOSALS = False
__C.RESULTS_NMS_THRESHOLD 是用于放弃评估中重叠的预测边界框的 NMS 阈值。 较低的阈值会减少删除,因此在最终输出中预测的边界框越多。 如果设置 __C.USE_PRECOMPUTED_PROPOSALS = True 读取器将从文本文件读取预计算的 RO。 例如,用于对 Pascal VOC 数据进行训练。 文件名 __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE 并在 __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE . 中 Examples/Image/Detection/utils/configs/Pascal_config.py指定。
# The basic segmentation is performed kvals.size() times. The k parameter is set (from, to, step_size)
__C.roi_ss_kvals = (10, 500, 5)
# When doing the basic segmentations prior to any box merging, all
# rectangles that have an area < min_size are discarded. Therefore, all outputs and
# subsequent merged rectangles are built out of rectangles that contain at
# least min_size pixels. Note that setting min_size to a smaller value than
# you might otherwise be interested in using can be useful since it allows a
# larger number of possible merged boxes to be created
__C.roi_ss_min_size = 9
# There are max_merging_iterations rounds of neighboring blob merging.
# Therefore, this parameter has some effect on the number of output rectangles
# you get, with larger values of the parameter giving more output rectangles.
# Hint: set __C.CNTK.DEBUG_OUTPUT=True to see the number of ROIs from selective search
__C.roi_ss_mm_iterations = 30
# image size used for ROI generation
__C.roi_ss_img_size = 200
上述参数正在配置 dlib 的选择性搜索。 有关详细信息,请参阅 dlib 主页。 以下附加参数用于筛选生成的 ROIs w.r.t. 最小值和最大侧长度、面积和纵横比。
# minimum relative width/height of an ROI
__C.roi_min_side_rel = 0.01
# maximum relative width/height of an ROI
__C.roi_max_side_rel = 1.0
# minimum relative area of an ROI
__C.roi_min_area_rel = 0.0001
# maximum relative area of an ROI
__C.roi_max_area_rel = 0.9
# maximum aspect ratio of an ROI vertically and horizontally
__C.roi_max_aspect_ratio = 4.0
# aspect ratios of ROIs for uniform grid ROIs
__C.roi_grid_aspect_ratios = [1.0, 2.0, 0.5]
如果选择性搜索返回的 RO 数高于请求的 RO,则随机采样。 如果使用指定的 __C.roi_grid_aspect_ratios常规网格生成更少的 RO,则返回其他 ROIS。
使用不同的基本模型
若要使用不同的基本模型,需要在方法run_fast_rcnn.py中选择get_configuration()不同的模型配置。 立即支持两种模型:
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
若要下载 VGG16 模型,请使用以下中的 <cntkroot>/PretrainedModels下载脚本:
python download_model.py VGG16_ImageNet_Caffe
如果要使用另一个不同的基本模型,则需要复制,例如,配置文件 utils/configs/VGG16_config.py 并根据基本模型对其进行修改:
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
若要调查基本模型的节点名称,可以使用该方法plot()。cntk.logging.graph 请注意,由于 CNTK 中的 roi 池尚不支持 Roi 平均池,因此目前不支持 ResNet 模型。
算法详细信息
快速 R-CNN
R-CNN for Object Detection 于 2014 年首次由 罗斯·吉尔希克等人提出,并被展示为超越以往最先进的方法,了解了该领域的主要对象识别挑战之一: Pascal VOC。 此后,发表了两篇后续论文,其中包含显著速度改进: 快速 R-CNN 和 更快的 R-CNN。
R-CNN 的基本理念是采用深度神经网络,该神经网络最初使用数百万个批注图像进行图像分类训练,并对其进行修改,以便进行对象检测。 第一篇 R-CNN 论文的基本思路如下图所示, (从论文) 中获取: (1) 给定输入图像,第一步 (2) ,生成大量区域建议。 (3) 这些区域建议或 (RO) 区域,然后通过网络单独发送,从而为每个 ROI 输出一个矢量,例如 4096 个浮点值。 最后,了解分类器 (4) ,该分类器采用 4096 浮点 ROI 表示形式作为输入和输出标签,并为每个 ROI 输出一个标签和置信度。

虽然此方法在准确性方面效果良好,但计算成本很高,因为神经网络必须针对每个 ROI 进行评估。 快速 R-CNN 通过仅评估大多数网络 (特定来解决此问题:卷积层) 每个映像一次。 据作者介绍,这会导致在测试期间加速213次,训练期间速度为9倍,而不会丢失准确性。 这是通过使用 ROI 池层来实现的,该层将 ROI 投影到卷积特征映射上,并执行最大池以生成以下层预期所需的输出大小。
在本教程中使用的 AlexNet 示例中,ROI 池层放置在最后一个卷积层和第一个完全连接层之间。 In the CNTK Python API code shown below this is realized by cloning two parts of the network, the conv_layers and the fc_layers. 然后,首先规范化输入图像,推送到 conv_layers层 roipooling 和 fc_layers 最后预测和回归头,分别预测类标签和每个候选 ROI 的回归系数。
def create_fast_rcnn_model(features, roi_proposals, label_targets, bbox_targets, bbox_inside_weights, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, roi_proposals, fc_layers, cfg)
detection_losses = create_detection_losses(...)
pred_error = classification_error(cls_score, label_targets, axis=1)
return detection_losses, pred_error
def create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg):
# RCNN
roi_out = roipooling(conv_out, rois, cntk.MAX_POOLING, (6, 6), spatial_scale=1/16.0)
fc_out = fc_layers(roi_out)
# prediction head
cls_score = plus(times(fc_out, W_pred), b_pred, name='cls_score')
# regression head
bbox_pred = plus(times(fc_out, W_regr), b_regr, name='bbox_regr')
return cls_score, bbox_pred
可以在 GitHub 中找到 R-CNN 论文中使用的原始 Caffe 实现: RCNN、 快速 R-CNN 和 更快的 R-CNN。
SVM 与 NN 训练
帕特里克·布勒提供有关如何使用上一个完全连接的层中的 4096 功能 () 以及 此处的优缺点来训练 CNTK Fast R-CNN 输出上的 SVM 的说明。
选择性搜索
选择性搜索 是用于在图像中查找大量可能的对象位置的方法,独立于实际对象的类。 它的工作原理是将图像像素聚类化为段,然后执行分层聚类分析,将同一对象中的段合并到对象建议中。



为了补充选择性搜索中检测到的 RO,我们添加了统一覆盖图像的不同缩放比例和纵横比的 ROIS。 左侧的图像显示了选择性搜索的示例输出,其中每个可能的对象位置都由绿色矩形可视化。 太小、太大等的 ROIS 被丢弃 (中间) ,最后统一覆盖图像的 RO 被添加到右侧) (。 然后,这些矩形用作 R-CNN 管道中 (ROIS) 的区域兴趣区域。
ROI 生成的目标是找到一小组 ROI,这些 URI 在图像中尽可能紧密地覆盖了尽可能多的对象。 此计算必须足够快,同时查找不同比例和纵横比的对象位置。 已显示选择性搜索可很好地执行此任务,并具有良好的准确性来加快权衡。
NMS (非最大抑制)
对象检测方法通常输出多个检测,这些检测完全或部分覆盖图像中的同一对象。
需要合并这些 ROIS 才能对对象进行计数并获取图像中的确切位置。
这传统上是使用称为“非最大抑制” (NMS) 的技术完成的。 我们使用 (的 NMS 版本,在 R-CNN 出版物中也使用了该版本,) 不会合并 ROIS,而是尝试确定哪些 ROIS 最能涵盖对象的实际位置,并丢弃所有其他 ROIS。 这是通过迭代地选择具有最高置信度 ROI 的 ROI 来实现的,并删除了其他所有显著重叠此 ROI 且分类为同一类的 ROI。 可以在 (详细信息) 中PARAMETERS.py设置重叠的阈值。
(左) 和右 (后) 非最大抑制之前检测结果:


mAP (平均精度)
训练后,可以使用不同的标准测量模型的质量,例如精度、召回率、准确性、曲线下面积等。用于 Pascal VOC 对象识别质询的常见指标是测量每个类的平均精度 (AP) 。 以下平均精度说明摘自 Everingham et. al. 平均平均精度 (mAP) 通过获取所有类的 AP 的平均值来计算。
对于给定的任务和类,精度/召回曲线是从方法的排名输出中计算的。 召回率定义为排名高于给定排名的所有正示例的比例。 精度是高于正类的所有示例的比例。 AP 总结精度/召回曲线的形状,定义为一组相同间距的召回级别 [0,0.1] 的平均值精度。 . . ,1]:
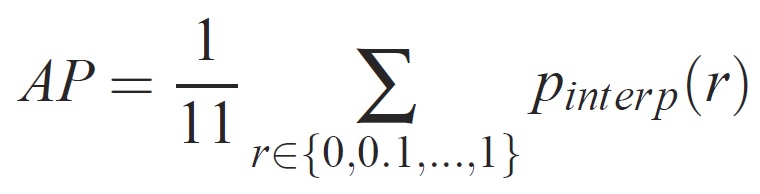
每个召回级别 r 的精度通过为相应召回率超过 r 的方法测量的最大精度进行内插:
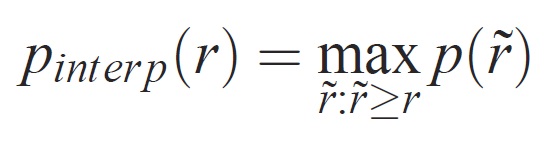
其中 p (̃r) 是召回 ̃r 的测量精度。 以这种方式内插精度/召回曲线的意图是减少精度/召回曲线中“摇摆”的影响,这与示例排名的细微变化所致。 应指出,要获得高分,方法必须具有各级召回率的精度 -- 这惩罚方法只检索一部分具有高精度 (的示例,例如汽车) 的侧视图。