若要创建数据挖掘模型,必须先使用数据挖掘向导基于新的数据源视图创建新的挖掘结构。 在此任务中,将使用向导创建挖掘结构,同时创建基于Microsoft神经网络算法的关联挖掘模型。
由于神经网络非常灵活,可以分析输入和输出的许多组合,因此应尝试多种处理数据方法来获得最佳结果。 例如,你可能想要自定义对服务质量的数字目标进行分箱或分组的方式,以满足特定的业务需求。 为此,需要向挖掘结构添加新列,该挖掘结构以不同的方式对数值数据进行分组,然后创建使用新列的模型。 你将使用这些挖掘模型进行一些探索。
最后,当你从神经网络模型中了解到哪些因素对业务问题产生了最大影响时,你将构建一个单独的预测和评分模型。 将使用Microsoft逻辑回归算法,该算法基于神经网络模型,但已针对基于特定输入查找解决方案进行了优化。
步骤
创建默认呼叫中心结构
在 SQL Server Data Tools(SSDT)的解决方案资源管理器中,右键单击 “挖掘结构 ”并选择“ 新建挖掘结构”。
在“ 欢迎使用数据挖掘向导” 页上,单击“ 下一步”。
在 “选择定义方法 ”页上,验证是否选择了 “从现有关系数据库或数据仓库 ”,然后单击“ 下一步”。
在“ 创建数据挖掘结构 ”页上,验证是否选择了“ 使用挖掘模型创建挖掘结构 ”选项。
单击下拉列表,选择“ 要使用的数据挖掘技术”选项,然后选择 Microsoft神经网络。
由于逻辑回归模型基于神经网络,因此可以重复使用同一结构并添加新的挖掘模型。
单击 “下一步” 。
此时会显示 “选择数据源视图 ”页。
在 “可用数据源视图”下,选择
Call Center并单击“ 下一步”。在“指定表类型”页上,选中 FactCallCenter 表旁边的“案例”复选框。 请勿为 DimDate 选择任何内容。 单击 “下一步” 。
在“指定训练数据”页上,选择列 FactCallCenterID 旁边的键。
选中
Predict和“输入”复选框。选中复选框 Key、Input 和
Predict,如下表所示:表/列 键/输入/预测 AutomaticResponses 输入 每个问题的平均时间 输入/预测 调用 输入 DateKey 请勿使用 DayOfWeek 输入 FactCallCenterID 密钥 提出的问题 输入 LevelOneOperators 输入/预测 LevelTwoOperators 输入 订单 输入/预测 服务等级 输入/预测 转变 输入 TotalOperators 请勿使用 工资类型 输入 请注意,已选择多个可预测列。 神经网络算法的优点之一是可以分析输入和输出属性的所有可能组合。 你不希望对大型数据集执行此作,因为它可能会呈指数级增加处理时间。
在“ 指定列的内容和数据类型 ”页上,验证网格是否包含列、内容类型和数据类型,如下表所示,然后单击“ 下一步”。
列 内容类型 数据类型 AutomaticResponses 连续的 长整型 每个问题的平均时间 连续的 长整型 调用 连续的 长整型 DayOfWeek 离散 文本 FactCallCenterID 密钥 长整型 提出的问题 连续的 长整型 LevelOneOperators 连续的 长整型 LevelTwoOperators 连续的 长整型 订单 连续的 长整型 服务等级 连续的 加倍 转变 离散 文本 工资类型 离散 文本 在 创建测试集 页面上,清空选项中 用于测试的数据百分比 的文本框。 单击 “下一步” 。
在“完成向导”页上,键入“挖掘结构名称
Call Center”。对于 挖掘模型名称,键入
Call Center Default NN,然后单击“ 完成”。禁用 “允许钻取 ”框,因为无法使用神经网络模型钻取到数据。
在解决方案资源管理器中,右键单击刚刚创建的数据挖掘结构的名称,然后选择“ 进程”。
使用离散化将目标列进行分箱
默认情况下,创建具有数值可预测属性的神经网络模型时,Microsoft神经网络算法会将该属性视为连续数。 例如,ServiceGrade 属性是一个数字,理论上从 0.00(所有呼叫都接听)到 1.00(所有呼叫者都挂起)。 在此数据集中,这些值具有以下分布:
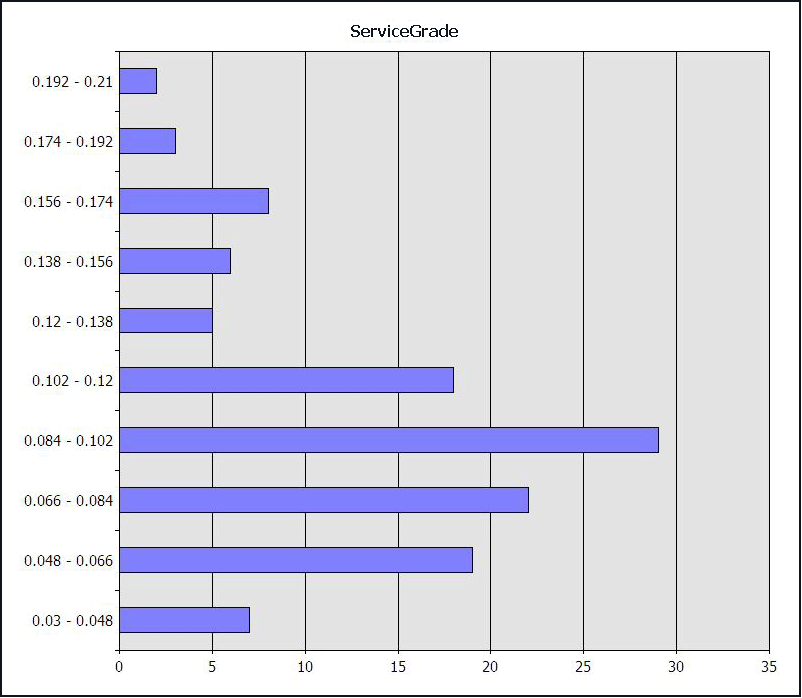
因此,处理模型时,输出的分组方式可能与预期不同。 例如,如果使用聚类分析来标识最佳值组,则算法会将 ServiceGrade 中的值划分为以下范围:0.0748051948 - 0.09716216215。 尽管这种分组在数学上是准确的,但此类范围对业务用户可能没有意义。
在此步骤中,为了使结果更加直观,你将以不同的方式对数值进行分组,从而创建数值数据列的副本。
离散化的工作原理
Analysis Services 提供了各种用于分箱处理或处理数值数据的方法。 下表说明了当输出属性 ServiceGrade 已处理三种不同的方法时结果之间的差异:
将其视为连续数。
让算法使用聚类分析来识别值的最佳排列方式。
指定按等面积法对数字进行分箱。
默认模型(连续)
| 值 | Support |
|---|---|
| 失踪 | 0 |
| 0.09875 | 120 |
通过聚类进行分箱
| 值 | Support |
|---|---|
| < 0.0748051948 | 34 |
| 0.0748051948 - 0.09716216215 | 二十七 |
| 0.09716216215 - 0.13297297295 | 39 |
| 0.13297297295 - 0.167499999975 | 10 |
| >= 0.1674999999975 | 10 |
按面积相等分组
| 值 | Support |
|---|---|
| < 0.07 | 26 |
| 0.07 - 0.00 | 22 |
| 0.09 - 0.11 | 36 |
| >= 0.12 | 36 |
注释
处理所有数据后,可以从模型的边际统计信息节点获取这些统计信息。 有关边际统计信息节点的详细信息,请参阅 神经网络模型(Analysis Services - 数据挖掘)的挖掘模型内容。
在本表中,VALUE 列显示了 ServiceGrade 数值的处理情况。 SUPPORT 列显示具有该值或在该范围内的案例数量。
使用连续数字(默认值)
如果使用默认方法,则算法将计算 120 个非重复值的结果,其平均值为 0.09875。 还可以查看缺失值的数目。
通过聚类进行分组
当让Microsoft聚类分析算法确定值的可选分组时,该算法会将 ServiceGrade 的值分组为五(5)个范围。 每个范围中的事例数未均匀分布,如支持列中所示。
按相等区域分箱
选择此方法时,该算法会将值强制转换为大小相等的存储桶,进而更改每个范围的上限和下限。 可以指定存储桶数,但希望避免在任何存储桶中具有两个值。
有关分箱选项的详细信息,请参阅离散化方法(数据挖掘)。
或者,可以添加一个单独的派生列,将服务等级分类为预定义的目标范围,例如 Best(ServiceGrade <= 0.05)、可接受的(0.10 > ServiceGrade 0.05)和 Poor(ServiceGrade >> = 0.10)。
创建列的副本并更改离散化方法
你将创建包含目标属性 ServiceGrade 的挖掘列的副本,并更改数字的分组方式。 可以在挖掘结构中创建任意列的多个副本,包括可预测属性。
在本教程中,将使用离散化相等区域方法,并指定四个存储桶。 此方法产生的分组与业务用户感兴趣的目标值相当接近。
在挖掘结构中创建列的自定义副本
在解决方案资源管理器中,双击刚刚创建的挖掘结构。
在“挖掘结构”选项卡中,单击添加挖掘结构列。
在 “选择列 ”对话框中,从 “源”列中列表中选择 ServiceGrade,然后单击“ 确定”。
将新列添加到挖掘结构列列表中。 默认情况下,新的挖掘列的名称与现有列相同,并带有数字后缀:例如 ServiceGrade 1。 可以将此列的名称更改为更具描述性。
你还将指定离散化方法。
右键单击 ServiceGrade 1 并选择“ 属性”。
在 “属性” 窗口中,找到 Name 属性,并将名称更改为 Service Grade Binned 。
此时会出现一个对话框,询问是否要对所有相关挖掘模型列的名称进行相同的更改。 单击 “否”。
在 “属性” 窗口中,找到 “数据类型 ”部分,并根据需要展开它。
将属性
Content的值从Continuous更改为Discretized。以下属性现已可用。 更改属性的值,如下表所示:
资产 默认值 新值 DiscretizationMethodContinuousEqualAreasDiscretizationBucketCount没有值 4 注释
默认值 DiscretizationBucketCount 实际上为 0,这意味着算法会自动确定最佳存储桶数。 因此,如果要将此属性的值重置为其默认值,请键入 0。
在数据挖掘设计器中,单击“ 挖掘模型 ”选项卡。
请注意,添加挖掘结构列的副本时,副本的使用标志将自动设置为
Ignore。 通常,当您将某列的副本添加到挖掘结构中时,不会与原始列一起使用进行分析,否则算法将发现这两列之间的强烈相关性,从而可能会掩盖其他关系。
向挖掘结构添加新的挖掘模型
现在,你已经为目标属性创建了一个新的分组,接下来需要添加新的挖掘模型,该挖掘模型使用离散化列。 完成后,CallCenter 挖掘结构将具有两个挖掘模型:
挖掘模型 Call Center Default NN 将 ServiceGrade 值作为连续范围进行处理。
你将创建一个新的挖掘模型“呼叫中心 Binned NN”,该模型以 ServiceGrade 列的值作为目标结果,并将这些值分布到大小相等的四个组中。
添加基于新的离散化列的挖掘模型
在解决方案资源管理器中,右键单击刚刚创建的挖掘结构,然后选择“ 打开”。
单击“ 挖掘模型 ”选项卡。
单击“ 创建相关挖掘模型”。
在“ 新建挖掘模型 ”对话框中,对于 “模型名称”,请键入
Call Center Binned NN。 在 “算法名称 ”下拉列表中,选择 Microsoft神经网络。在新挖掘模型中包含的列列表中,找到 ServiceGrade,并将使用情况从
Predict此更改为Ignore。同样,找到 ServiceGrade Binned,并将使用情况从
Ignore更改为Predict。
为目标列创建别名
通常,不能比较使用不同可预测属性的挖掘模型。 但是,您可以为挖掘模型列创建别名。 也就是说,可以在挖掘模型中重命名列 ServiceGrade Binned,使其名称与原始列相同。 然后,可以直接在准确性图表中比较这两个模型,即使数据以不同的方式离散化。
在挖掘模型中为挖掘结构列添加别名
在“ 挖掘模型 ”选项卡的“ 结构”下,选择“ServiceGrade Binned”。
请注意,“属性” 窗口显示对象的属性,即 ScalarMiningStructure 列。
在列为“ServiceGrade Binned NN”的挖掘模型下,单击与“ServiceGrade Binned”对应的单元格。
请注意,现在“ 属性” 窗口显示对象(MiningModelColumn)的属性。
找到 Name 属性,并将值更改为
ServiceGrade。找到 Description 属性并键入 临时列别名。
“属性”窗口应包含以下信息:
资产 价值 说明 临时列别名 ID ServiceGrade Binned 模型标签 名称 服务等级 SourceColumn ID 服务级别 1 用法 预测 单击“ 挖掘模型 ”选项卡中的任意位置。
网格将更新,以显示新的临时列别名,
ServiceGrade以及列用法。 包含挖掘结构和两个挖掘模型的网格应如下所示:结构 呼叫中心默认 NN 呼叫中心分组 NN Microsoft神经网络 Microsoft神经网络 AutomaticResponses 输入 输入 每个问题的平均时间 预测 预测 调用 输入 输入 DayOfWeek 输入 输入 FactCallCenterID 密钥 密钥 提出的问题 输入 输入 LevelOneOperators 输入 输入 LevelTwoOperators 输入 输入 订单 输入 输入 ServceGrade Binned 忽略 Predict (ServiceGrade) 服务等级 预测 忽略 转变 输入 输入 运算符总数 输入 输入 工资类型 输入 输入
处理所有模型
最后,为了确保您已创建的模型可以轻松比较,您将为默认模型和分箱模型设置种子参数。 设置种子值可确保每个模型都从同一点开始处理数据。
注释
如果未为种子参数指定数值,SQL Server Analysis Services 将基于模型的名称生成种子。 由于模型始终具有不同的名称,因此必须设置种子值以确保它们按相同的顺序处理数据。
指定种子并处理模型
在 “挖掘模型 ”选项卡中,右键单击名为“呼叫中心 - LR”的模型的列,然后选择“ 设置算法参数”。
在HOLDOUT_SEED参数的行中,单击 值下的空单元格,然后键入
1。 单击 “确定” 。 对与结构关联的每个模型重复此步骤。注释
你选择哪个值作为种子无关紧要,只要在所有相关模型中使用相同的种子即可。
在 “挖掘模型 ”菜单中,选择“ 进程挖掘结构”和“所有模型”。 单击 “是 ”将更新的数据挖掘项目部署到服务器。
在“ 进程挖掘模型 ”对话框中,单击“ 运行”。
单击“关闭”以关闭“进程进度”对话框,然后在“进程挖掘模型”对话框中再次单击“关闭”。
创建两个相关的挖掘模型后,将浏览数据以发现数据中的关系。