SQL Server 大数据群集中的应用部署简介
适用范围:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
应用程序部署通过提供用于创建、管理和运行应用程序的界面,允许在 SQL Server 大数据群集上部署应用程序。 部署在大数据群集上的应用程序可以受益于群集的计算能力,并且可以访问群集上可用的数据。 这会提高应用程序的可伸缩性和性能,同时管理数据所在的应用程序。 SQL Server 大数据群集上支持的应用程序运行时:R、Python、dtexec 和 MLeap。
以下部分介绍了应用程序部署的体系结构和功能。
应用程序部署体系结构
应用程序部署由控制器和应用运行时处理程序组成。 创建应用程序时,会提供规范文件 (spec.yaml)。 此 spec.yaml 文件包含控制器成功部署应用程序所需知道的一切。 下面是 spec.yaml 的内容示例:
#spec.yaml
name: add-app #name of your python script
version: v1 #version of the app
runtime: Python #the language this app uses (R or Python)
src: ./add.py #full path to the location of the app
entrypoint: add #the function that will be called upon execution
replicas: 1 #number of replicas needed
poolsize: 1 #the pool size that you need your app to scale
inputs: #input parameters that the app expects and the type
x: int
y: int
output: #output parameter the app expects and the type
result: int
控制器会检查 spec.yaml 文件中指定的 runtime,并调用相应的运行时处理程序。 运行时处理程序会创建应用程序。 首先,会创建包含一个或多个 pod 的 Kubernetes ReplicaSet,其中每个 pod 都包含要部署的应用程序。 pod 的数量由应用程序的 spec.yaml 文件中设置的 replicas 参数定义。 每个 pod 可以有一个或多个池。 池的数量由 spec.yaml 文件中设置的 poolsize 参数定义。
这些设置决定部署可以并行处理的请求数量。 一个给定时间的最大请求数等于 replicas 乘以 poolsize。 如果有 5 个副本,每个副本有 2 个池,则部署可以并行处理 10 个请求。 有关 replicas 和 poolsize 的图形表示方式,请参阅下图:
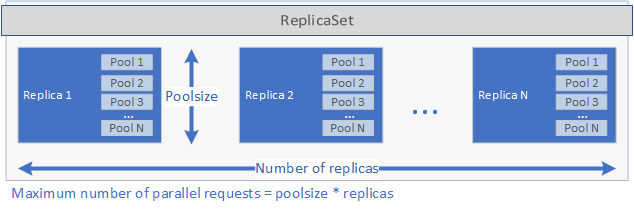
如果在 spec.yaml 文件中设置了 schedule,那么,在创建 ReplicaSet 并启动 pod 后,会创建一个 cron 作业。 最后,会创建一个可用于管理和运行应用程序的 Kubernetes 服务(请参阅下文)。
执行应用程序时,应用程序的 Kubernetes 服务会将请求代理给副本并返回结果。
OpenShift 上的应用程序部署的安全注意事项
SQL Server 2019 CU5 支持在 Red Hat OpenShift 上部署 BDC,并且支持 BDC 的更新安全模型,因此不再需要特权容器。 对于使用 SQL Server 2019 CU5 的所有新部署,容器除了是非特权容器之外,还默认以非根用户身份运行。
在 CU5 版本中,使用应用部署接口部署的应用程序的安装步骤仍将以根用户身份运行。 这是必需的,因为在安装期间会安装应用程序将使用的其他包。 作为应用程序的一部分部署的其他用户代码将以低特权用户身份运行。
此外,CAP_AUDIT_WRITE 功能是允许使用 cron 作业计划 SQL Server Integration Services (SSIS) 应用程序所必需的一项可选功能。 当应用程序的 yaml 规范文件指定计划时,应用程序将通过 cron 作业触发,而这需要其他功能。 或者,可以通过 Web 服务调用使用 azdata app run 按需触发应用程序,而这不需要 CAP_AUDIT_WRITE 功能。 请注意,从 SQL Server 2019 CU8 版开始,cronjob 不再需要 CAP_AUDIT_WRITE 功能。
注意
OpenShift 部署项目中的自定义 SCC 不包括此功能,因为 BDC 的默认部署不需要此功能。 若要启用此功能,必须首先更新自定义 SCC yaml 文件,以添加 CAP_AUDIT_WRITE 功能。
...
allowedCapabilities:
- SETUID
- SETGID
- CHOWN
- SYS_PTRACE
- AUDIT_WRITE
...
如何在大数据群集中进行应用部署
应用程序部署的两个主要接口如下:
还可以使用 RESTful Web 服务执行应用程序。 有关详细信息,请参阅在大数据群集上使用应用程序。
应用部署方案
应用程序部署通过提供用于创建、管理和运行应用程序的界面,允许在 SQL Server BDC 上部署应用程序。
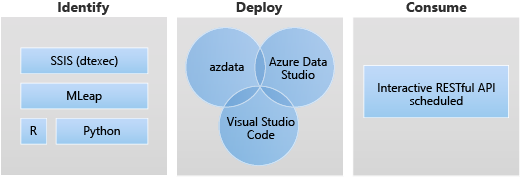
以下是应用部署的目标方案:
- 在大数据群集内部署 Python 或 R Web服务以应对各种用例,例如机器学习推理、API 服务等。
- 使用 MLeap 引擎创建机器学习推理终结点。
- 使用 dtexec 实用工具从 DTSX 文件计划和运行包,以进行数据转换和移动。
使用应用部署 Python 运行时
在应用部署中,借助 BDC python 运行时,大数据群集中的 Python 应用程序可以应对各种用例,例如机器学习推理、API 服务等。
应用部署 Python 运行时在 SQL Server 大数据群集 CU10+ 上使用 Python 3.8。
在应用部署中,spec.yaml 是提供控制器部署应用程序所需了解的信息的位置。 以下是可指定的字段:
name:应用程序名称version:应用程序版本,例如v1runtime:应用部署运行时,需要将其指定为Pythonsrc:Python 应用程序的路径entry point:要针对此 Python 应用程序执行的 src 脚本中的入口点函数。
除了上述内容外,还需要指定 Python 应用程序的输入和输出。 这将生成一个 spec.yaml 文件,该文件类似于以下内容:
#spec.yaml
name: add-app
version: v1
runtime: Python
src: ./add.py
entrypoint: add
replicas: 1
poolsize: 1
inputs:
x: int
y: int
output:
result: int
你可以创建部署在大数据群集上运行的 Python 应用所需的基本文件夹和文件结构:
azdata app init --template python --name hello-py --version v1
有关后续步骤,请参阅如何在 SQL Server 大数据群集上部署应用。
应用部署 Python 运行时的限制
应用部署 Python 运行时不支持计划方案。 部署 Python 应用,然后在 BDC 中运行后,就会将 RESTful 终结点配置为侦听传入的请求。
使用应用部署 R 运行时
在应用部署中,借助 BDC Python 运行时,大数据群集中的 R 应用程序可以应对各种用例,例如机器学习推理、API 服务等。
应用部署 R 运行时在 SQL Server 大数据群集 CU10+ 上使用 Microsoft R Open (MRO) 版本 3.5.2。
如何使用?
在应用部署中,spec.yaml 是提供控制器部署应用程序所需了解的信息的位置。 以下是可指定的字段:
name:应用程序名称version:应用程序版本,例如v1runtime:应用部署运行时,需要将其指定为Rsrc:R 应用程序的路径entry point:用于执行此 R 应用程序的入口点
除了上述内容外,还需指定 R 应用程序的输入和输出。 这将生成一个 spec.yaml 文件,该文件类似于以下内容:
#spec.yaml
name: roll-dice
version: v1
runtime: R
src: ./roll-dice.R
entrypoint: rollEm
replicas: 1
poolsize: 1
inputs:
x: integer
output:
result: data.fram
你可以使用以下命令创建部署新 R 应用程序所需的基本文件夹和文件结构:
azdata app init --template r --name hello-r --version v1
有关后续步骤,请参阅如何在 SQL Server 大数据群集上部署应用。
R 运行时的限制
这些限制与 2023 年 7 月 1 日停用的 Microsoft R 应用程序网络保持一致。 有关详细信息和解决方法,请参阅 Microsoft R 应用程序网络停用。
使用应用部署 dtexec 运行时
在应用部署中,大数据群集运行时集成了 dtexec 实用工具,该实用工具来自 Linux 上的 SSIS (mssql-server-is)。 应用部署使用 dtexec 实用工具从*.dtsx 文件加载包。 它支持按 cron 样式的计划或通过 Web 服务请求按需运行 SSIS 包。
此功能使用 Linux 上 SQL Server 2019 集成服务中的 /opt/ssis/bin/dtexec /FILE。 它支持针对 Linux 上的 SQL Server 2019 集成服务 (mssql-server-is 15.0.2) 使用 dtsx 格式。 要了解有关 dtexec 实用工具的详细信息,请参阅 dtexec 实用工具。
在应用部署中,spec.yaml 是提供控制器部署应用程序所需了解的信息的位置。 以下是可指定的字段:
name:应用程序nameversion:应用程序版本,例如v1runtime:应用部署运行时(为运行 dtexec 实用工具),需将其指定为SSISentrypoint:指定入口点,这通常是我们的案例中的 .dtsx 文件。options:为/opt/ssis/bin/dtexec /FILE指定其他选项,例如,使用连接字符串连接到数据库时,它将遵循以下模式:/REP V /CONN "sqldatabasename"\;"\"Data Source=xx;User ID=xx;Password=xx\""有关语法的详细信息,请参阅 Dtexec 实用工具。
schedule:指定需要执行作业的频率,例如,使用 cron 表达式指定此值时,将指定为“*/1 * * * *”,表示每分钟执行一次作业。
你可以使用以下命令创建部署新的 SSIS 应用程序所需的基本文件夹和文件结构:
azdata app init --name hello-is –version v1 --template ssis
这会生成如下 spec.yaml 文件:
#spec.yaml
entrypoint: ./hello.dtsx
name: hello-is
options: /REP V
poolsize: 2
replicas: 2
runtime: SSIS
schedule: '*/2 * * * *'
version: v1
该示例还创建了一个示例 hello.dtsx 包。
所有应用文件都与 spec.yaml 位于同一目录中。 spec.yaml 必须位于应用源代码目录(包括 dtsx 文件)的根级别。
有关后续步骤,请参阅如何在 SQL Server 大数据群集上部署应用。
Dtexec 实用工具运行时的限制
Linux 上 SQL Server Integration Services (SSIS) 的所有限制和已知问题在 SQL Server 大数据群集中都适用。 你可以从 Linux 上的 SSIS 的限制和已知问题中了解详细信息。
使用应用部署 MLeap 运行时
应用部署 MLeap 运行时支持 MLeap 服务 v0.13.0。
在应用部署中,spec.yaml 是提供控制器部署应用程序所需了解的信息的位置。 以下是可指定的字段:
name:应用程序名称version:应用程序版本,例如v1runtime:应用部署运行时,需要将其指定为Mleap
除了上述内容外,还需指定 MLeap 应用程序的 bundleFileName。 这将生成一个 spec.yaml 文件,该文件类似于以下内容:
#spec.yaml
name: mleap-census
version: v1
runtime: Mleap
bundleFileName: census-bundle.zip
replicas: 1
你可以使用以下命令创建部署新的 MLeap 应用程序所需的基本文件夹和文件结构:
azdata app init --template mleap --name hello-mleap --version v1
有关后续步骤,请参阅如何在 SQL Server 大数据群集上部署应用。
MLeap 运行时的限制
这些限制与来自 GitHub 上的 Combust 的 MLeap 开源项目的愿景一致。
后续步骤
若要了解有关如何在 SQL Server 大数据群集上创建和运行应用程序的详细信息,请参阅以下内容:
若要了解有关 SQL Server 大数据群集 的详细信息,请参阅以下概述: