部署高可用性 SQL Server 大数据群集
适用范围:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
由于 SQL Server 大数据群集是作为容器化应用程序位于 Kubernetes 上,并且使用有状态集和持久存储等功能,因此,此基础结构具有内置的运行状况监视、故障检测和故障转移机制,群集组件可利用这些机制来维护服务运行状况。 为了提高可靠性,还可以将 SQL Server 主实例和/或 HDFS 名称节点和 Spark 共享服务配置为在高可用性配置中与其他副本一起部署。 监视、故障检测和自动故障转移由大数据群集管理服务(即控制服务)进行管理。 无需用户干预即可提供此服务:从设置可用性组、配置数据库镜像终结点到将数据库添加到可用性组或故障转移和升级协调等等。
下图表示在 SQL Server 大数据群集中部署可用性组的方式:
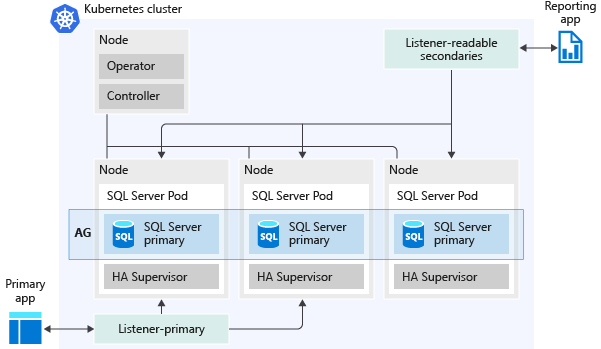
下面是可用性组启用的一些功能:
如果在部署配置文件中指定了高可用性设置,则将创建名为
containedag的单个可用性组。 默认情况下,containedag有三个副本,其中包括主要副本。 可用性组的所有 CRUD 操作都在内部进行管理,包括创建可用性组或将副本联接到创建的可用性组。 在大数据群集的 SQL Server 主实例中无法创建其他可用性组。所有数据库都将自动添加到可用性组,包括所有用户和系统数据库(如
master和msdb)。 此功能提供跨可用性组副本的单系统视图。 其他模型数据库(model_replicatedmaster和model_msdb)用于设定系统数据库复制部分的种子。 如果直接连接到实例,除了这些数据库,还将看到containedag_master和containedag_msdb数据库。containedag数据库表示可用性组中的master和msdb。重要
通过执行工作流在实例上创建的数据库(如附加数据库)不会自动添加到可用性组。 SQL Server 大数据群集管理员必须手动完成此操作。 若要了解如何为 SQL Server 实例 master 数据库启用临时终结点,请参阅连接到 SQL Server 实例。 在低于 SQL Server 2019 CU2 的版本中,因还原语句而创建的数据库具有相同行为,必须手动将数据库添加到包含的可用性组。
PolyBase 配置数据库不包括在可用性组中,因为它们包括特定于每个副本的实例级元数据。
系统会自动预配外部终结点,以便与可用性组中的数据库建立连接。 此终结点
master-svc-external扮演可用性组侦听器的角色。系统还会预配另一个外部终结点,以便与用于横向扩展读取工作负荷的次要副本建立只读连接。
部署
在可用性组中部署 SQL Server 主实例:
- 启用
hadr功能 - 指定 AG 的副本数(最小值为 3)
- 为创建用于连接到只读次要副本的第二个外部终结点配置详细信息
可以使用 aks-dev-test-ha 或 kubeadm-prod 内置配置文件来开始自定义大数据群集。 这些配置文件包括配置其他高可用性资源所需的设置。 例如,下面是 bdc.json 配置文件中与启用 SQL Server 主实例可用性组相关的部分。
{
...
"spec": {
"type": "Master",
"replicas": 3,
"endpoints": [
{
"name": "Master",
"serviceType": "LoadBalancer",
"port": 31433
},
{
"name": "MasterSecondary",
"serviceType": "LoadBalancer",
"port": 31436
}
],
"settings": {
"sql": {
"hadr.enabled": "true"
}
}
}
...
}
以下步骤通过示例演示了如何从 aks-dev-test-ha 配置文件开始,自定义大数据群集部署配置。 对于 kubeadm 群集上的部署将应用类似的步骤,但请确保对 endpoints 部分中的 serviceType 使用 NodePort。
克隆目标配置文件
azdata bdc config init --source aks-dev-test-ha --target custom-aks-ha根据需要对自定义配置文件进行编辑。
使用上面创建的群集配置文件开始群集部署
azdata bdc create --config-profile custom-aks-ha --accept-eula yes
连接到可用性组中的 SQL Server 数据库
可以连接到主要副本以获取读写工作负荷,也可以连接到次要副本中的数据库以获取只读类型的工作负荷,具体取决于你要针对 SQL Server 主实例运行的工作负荷的类型。 下面概括介绍了每种连接类型:
连接到主要副本上的数据库
若要连接到主要副本,请使用 sql-server-master 终结点。 此终结点也是 AG 的侦听器。 使用此终结点时,所有连接都在可用性组中的数据库的上下文中。 例如,使用此终结点将默认连接到可用性组中的 master 数据库,而不是 SQL Server 实例 master 数据库。 运行以下命令查找终结点:
azdata bdc endpoint list -e sql-server-master -o table
Description Endpoint Name Protocol
------------------------------------ ------------------- ----------------- ----------
SQL Server Master Instance Front-End 11.11.111.111,11111 sql-server-master tds
注意
在从 HDFS 或数据池等远程数据源访问数据的分布式查询执行过程中,可能会发生故障转移事件。 最佳做法是,将应用程序设计为在故障转移导致断开连接时具有连接重试逻辑。
连接到次要副本上的数据库
若要与次要副本中数据库建立只读连接,请使用 sql-server-master-readonly 终结点。 此终结点的作用类似于所有次要副本上的负载均衡器。 使用此终结点时,所有连接都在可用性组中的数据库的上下文中。 例如,使用此终结点将默认连接到可用性组中的 master 数据库,而不是 SQL Server 实例 master 数据库。
azdata bdc endpoint list -e sql-server-master-readonly -o table
Description Endpoint Name Protocol
--------------------------------------------- ------------------ -------------------------- ----------
SQL Server Master Readable Secondary Replicas 11.11.111.11,11111 sql-server-master-readonly tds
连接到 SQL Server 实例
对于某些操作(例如设置服务器级别配置或手动将数据库添加到可用性组),则必须连接到 SQL Server 实例。 在低于 SQL Server 2019 CU2 的版本中,诸如 sp_configure、RESTORE DATABASE 或任何可用性组 DDL 之类的操作都需要此类型的连接。 默认情况下,大数据群集不包括启用实例连接的终结点,因此必须手动公开此终结点。
重要
为连接 SQL Server 实例而公开的终结点仅支持 SQL 身份验证,即使在启用了 Active Directory 的群集中也是如此。 默认情况下,在大数据群集部署过程中,将禁用 sa 登录名,并根据在部署时为 AZDATA_USERNAME 和 AZDATA_PASSWORD 环境变量提供的值预配新的 sysadmin 登录名。
重要
包含的可用性组 DDL 在 BDC 中以独占方式进行自我托管。 不支持尝试删除包含的可用性或数据库镜像端点的任何操作(外部用户),这些操作可能会导致 BDC 的状态无法恢复。
下面的示例演示如何公开此终结点,然后将通过还原工作流创建的数据库添加到可用性组。 当希望使用 sp_configure 更改服务器配置时,可以参考与 SQL Server 主实例建立连接的类似说明。
备注
自 SQL Server 2019 CU2 起,因还原工作流而创建的数据库会自动添加到包含的可用性组。
确定通过连接到
sql-server-master终结点来托管主要副本的 Pod,并运行以下命令:SELECT @@SERVERNAME通过创建新的 Kubernetes 服务来公开外部终结点
对于
kubeadm群集,请运行以下命令。 将podName替换为在上一步骤中返回的服务器的名称,将serviceName替换为创建的 Kubernetes 服务的首选名称,并将namespaceName* 替换为你的大数据群集的名称。kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePort对于 aks 群集,请运行相同的命令,但创建的服务的类型将为
LoadBalancer。 例如:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancer下面是针对 aks 运行此命令的示例,其中托管主副本的 Pod 为
master-0:kubectl -n mssql-cluster expose pod master-0 --port=1533 --name=master-sql-0 --type=LoadBalancer获取创建的 Kubernetes 服务的 IP:
kubectl get services -n <namespaceName>
重要
最佳做法是,通过运行以下命令删除上面创建的 Kubernetes 服务进行清理:
kubectl delete svc master-sql-0 -n mssql-cluster
将数据库添加到可用性组。
对于要添加到 AG 的数据库,则必须在完整恢复模式下运行,并且必须执行日志备份。 使用上面创建的 Kubernetes 服务中的 IP 并连接到 SQL Server 实例,然后运行 T-SQL 语句,如下所示。
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>以下示例添加了一个名为
sales的数据库,该数据库在实例上已还原:ALTER DATABASE sales SET RECOVERY FULL; BACKUP DATABASE sales TO DISK='/var/opt/mssql/data/sales.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE sales
已知的限制
关于包含的适于大数据群集中 SQL Server 主实例的可用性组,下面是已知问题和限制:
- 部署大数据群集时,必须创建高可用性配置。 部署后,无法通过可用性组启用高可用性配置。 目前,只有启用的配置才适用于同步提交副本。
警告
将同步模式更新为仲裁提交中的任何副本的异步提交将导致配置无效,无法实现高可用性。 在此配置中运行涉及数据丢失风险,因为如果失败事件影响主副本,不会触发自动故障转移,并且用户必须接受在发出手动故障转移时数据丢失的风险。
- 要从另一台服务器上创建的备份中成功还原启用了 TDE 的数据库,必须确保在 SQL Server 主实例以及所包含的 AG 主实例上都还原了所需的证书。 有关如何备份和还原证书的示例,请参阅此处。
- 某些操作(如通过
sp_configure运行服务器配置设置)需要连接到 SQL Server 实例master数据库,而不是可用性组master。 不能使用相应的主要终结点。 按照说明公开终结点,然后连接到 SQL Server 实例并运行sp_configure。 当手动公开终结点以连接到 SQL Server 实例master数据库时,只能使用 SQL 身份验证。 - 虽然包含的 msdb 数据库包含在可用性组中,并且 SQL 代理作业在其中进行复制,但作业只会按计划在主副本上运行。
- 包含的可用性组不支持复制功能。 包含的 AG 的 SQL Server 实例部分不能作为分发服务器或发布服务器在实例级别或包含的 AG 级别运行。
- 不支持在创建数据库时添加文件组。 作为一种解决方法,你可以先创建数据库,然后发出 ALTER DATABASE 语句来添加任何文件组。
- 在低于 SQL Server 2019 CU2 的版本中,除
CREATE DATABASE和RESTORE DATABASE(如CREATE DATABASE FROM SNAPSHOT)之外,因工作流而创建的数据库不会自动添加到可用性组。 连接到实例 ,并手动将数据库添加到可用性组。 - 通过高可用性部署的大数据群集目前不支持 Service Broker 和数据库邮件。
后续步骤
- 有关在大数据群集部署中使用配置文件的详细信息,请参阅如何在 Kubernetes 上部署 SQL Server 大数据群集。
- 有关 SQL Server 的可用性组功能的详细信息,请参阅 Always On 可用性组概述 (SQL Server)。