使用 Spark 运行示例笔记本
适用范围:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
本教程演示如何在 SQL Server 2019 大数据群集上的 Azure Data Studio 中加载和运行笔记本。 数据科学家和数据工程师可针对群集运行 Python、R 或 Scala 代码。
提示
如果需要,可以下载并运行本教程中的命令脚本。 有关说明,请参阅 GitHub 上的 Spark 示例。
先决条件
- 大数据工具
- kubectl
- Azure Data Studio
- SQL Server 2019 扩展
- 将示例数据加载到大数据群集中
下载示例笔记本文件
按照以下说明将示例笔记本文件 spark-sql.ipynb 加载到 Azure Data Studio 中。
打开 bash 命令提示符 (Linux) 或 Windows PowerShell。
导航到要将示例笔记本文件下载到其中的目录。
运行以下 curl 命令,从 GitHub 下载笔记本文件:
curl https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/data-loading/transform-csv-files.ipynb -o transform-csv-files.ipynb
打开笔记本
以下步骤演示如何在 Azure Data Studio 中打开笔记本文件:
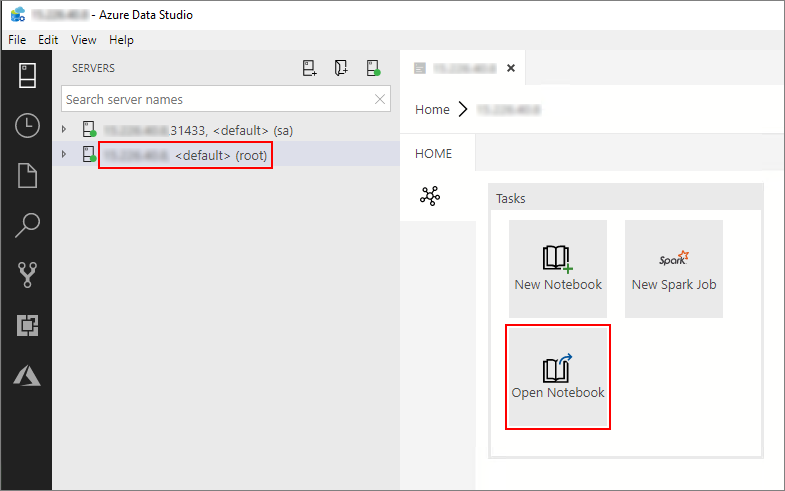
在 Azure Data Studio 中,连接到大数据群集的主实例。 有关详细信息,请参阅连接到大数据群集。
双击“服务器”窗口中的 HDFS/Spark 网关连接。 然后选择“打开笔记本”。
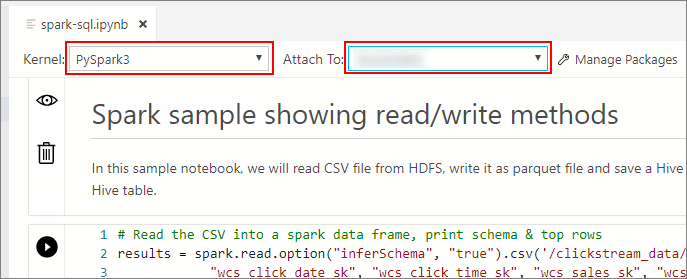
等待要填充的 Kernel 和目标上下文(“附加到”) 。 将 Kernel 设置为 PySpark3,将“附加到”设置为大数据群集终结点的 IP 地址 。
重要
在 Azure Data Studio 中,所有 Spark 笔记本类型(Scala Spark、PySpark 和 SparkR)通常会在第一次执行单元格时定义一些与 Spark 会话相关的重要变量。 这些变量包括:spark、sc 和 sqlContext。 从笔记本中将逻辑复制出来以进行批量提交(例如复制到要使用 azdata bdc spark batch create 运行的 Python 文件中)时,请确保相应地定义变量。
运行笔记本单元格
可以通过按单元格左侧的“播放”按钮来运行每个笔记本单元格。 单元格完成运行后,结果会显示在笔记本中。

连续运行示例笔记本中的每个单元格。 有关结合使用笔记本和 SQL Server 大数据群集 的详细信息,请参阅以下资源:
后续步骤
了解有关笔记本的详细信息:
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈